Best AI tools for< Manage Evaluations >
20 - AI tool Sites
Store Status Notification
The website is currently unavailable, indicating that the store is temporarily closed and awaiting restoration by the store owner. It seems to be a simple message informing visitors that the store is not operational at the moment.
Vellum AI
Vellum AI is an AI platform that supports using Microsoft Azure hosted OpenAI models. It offers tools for prompt engineering, semantic search, prompt chaining, evaluations, and monitoring. Vellum enables users to build AI systems with features like workflow automation, document analysis, fine-tuning, Q&A over documents, intent classification, summarization, vector search, chatbots, blog generation, sentiment analysis, and more. The platform is backed by top VCs and founders of well-known companies, providing a complete solution for building LLM-powered applications.

FinetuneDB
FinetuneDB is an AI fine-tuning platform that allows users to easily create and manage datasets to fine-tune LLMs, evaluate outputs, and iterate on production data. It integrates with open-source and proprietary foundation models, and provides a collaborative editor for building datasets. FinetuneDB also offers a variety of features for evaluating model performance, including human and AI feedback, automated evaluations, and model metrics tracking.
Entry Point AI
Entry Point AI is a modern AI optimization platform for fine-tuning proprietary and open-source language models. It provides a user-friendly interface to manage prompts, fine-tunes, and evaluations in one place. The platform enables users to optimize models from leading providers, train across providers, work collaboratively, write templates, import/export data, share models, and avoid common pitfalls associated with fine-tuning. Entry Point AI simplifies the fine-tuning process, making it accessible to users without the need for extensive data, infrastructure, or insider knowledge.
Agenta.ai
Agenta.ai is a platform designed to provide prompt management, evaluation, and observability for LLM (Large Language Model) applications. It aims to address the challenges faced by AI development teams in managing prompts, collaborating effectively, and ensuring reliable product outcomes. By centralizing prompts, evaluations, and traces, Agenta.ai helps teams streamline their workflows and follow best practices in LLMOps. The platform offers features such as unified playground for prompt comparison, automated evaluation processes, human evaluation integration, observability tools for debugging AI systems, and collaborative workflows for PMs, experts, and developers.
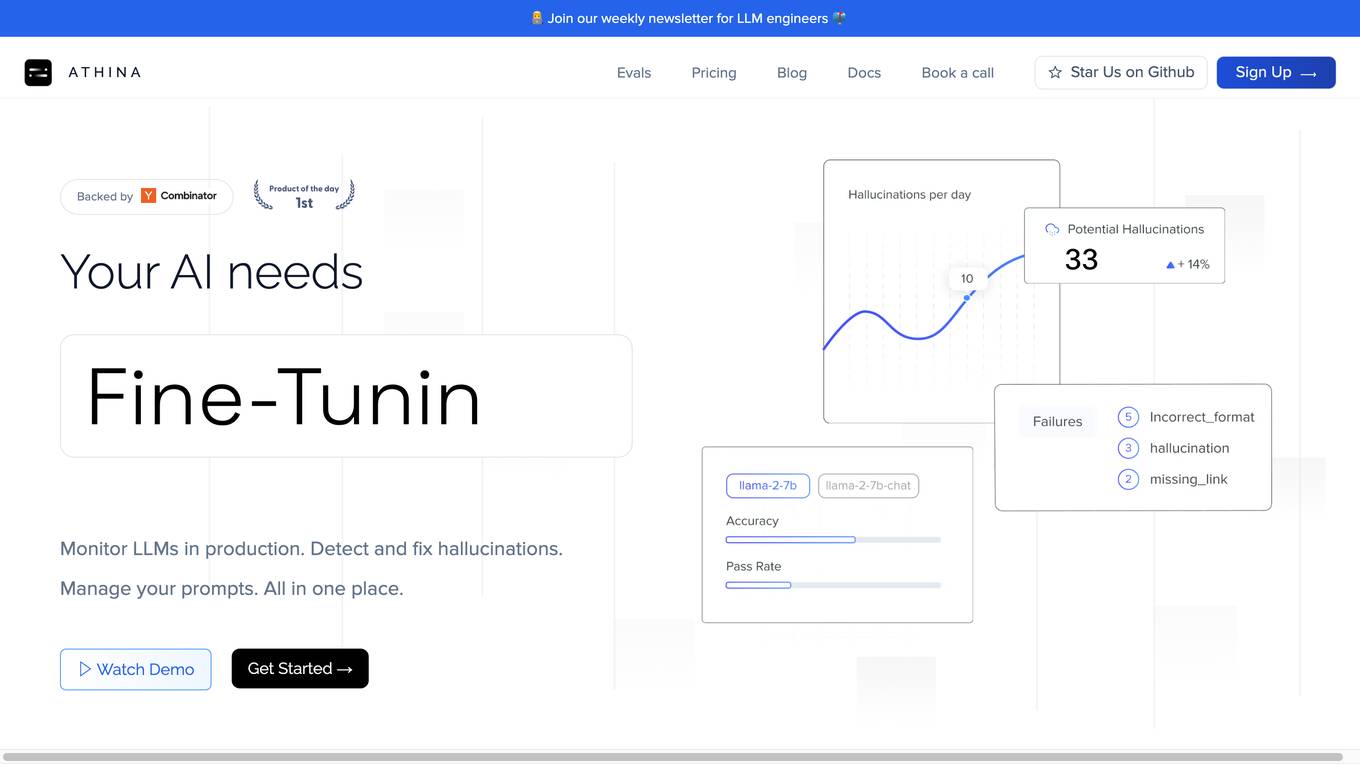
Athina AI
Athina AI is a comprehensive platform designed to monitor, debug, analyze, and improve the performance of Large Language Models (LLMs) in production environments. It provides a suite of tools and features that enable users to detect and fix hallucinations, evaluate output quality, analyze usage patterns, and optimize prompt management. Athina AI supports integration with various LLMs and offers a range of evaluation metrics, including context relevancy, harmfulness, summarization accuracy, and custom evaluations. It also provides a self-hosted solution for complete privacy and control, a GraphQL API for programmatic access to logs and evaluations, and support for multiple users and teams. Athina AI's mission is to empower organizations to harness the full potential of LLMs by ensuring their reliability, accuracy, and alignment with business objectives.
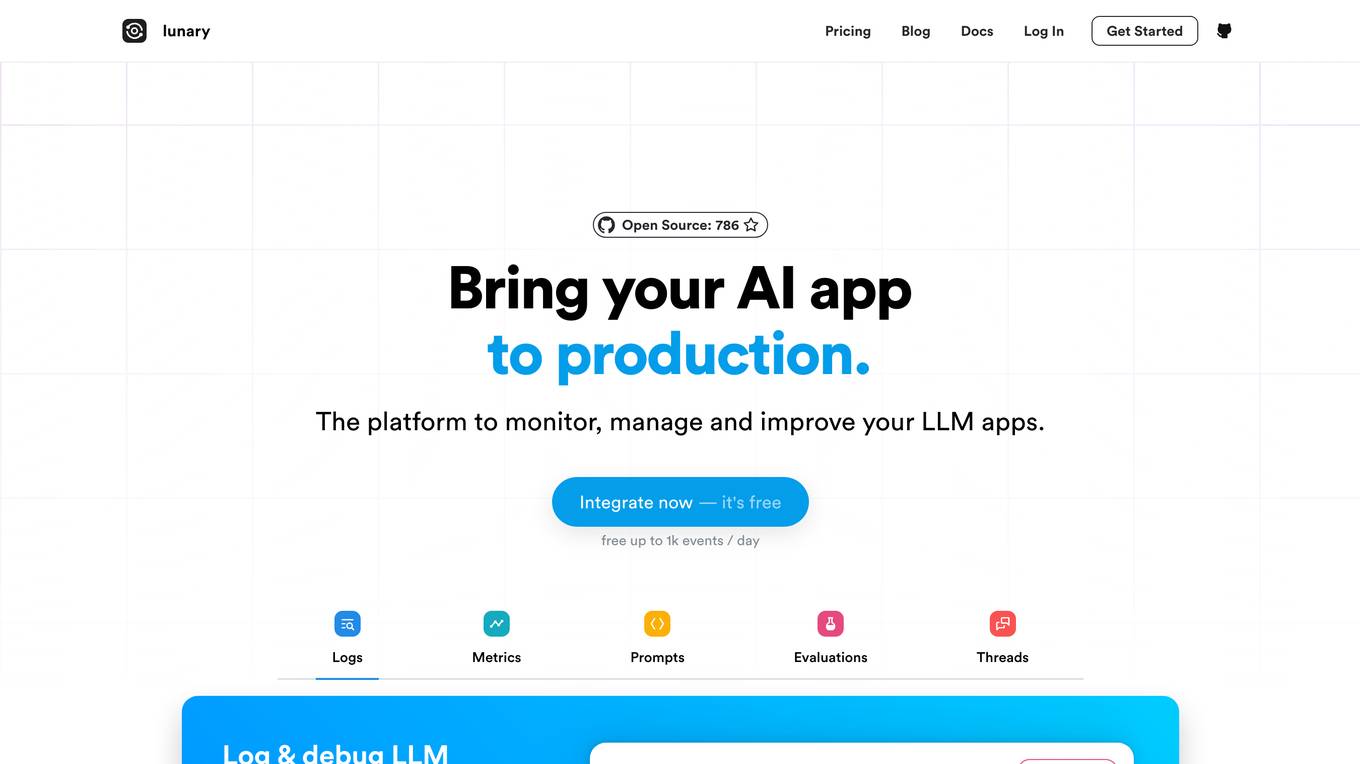
Lunary
Lunary is an AI developer platform designed to bring AI applications to production. It offers a comprehensive set of tools to manage, improve, and protect LLM apps. With features like Logs, Metrics, Prompts, Evaluations, and Threads, Lunary empowers users to monitor and optimize their AI agents effectively. The platform supports tasks such as tracing errors, labeling data for fine-tuning, optimizing costs, running benchmarks, and testing open-source models. Lunary also facilitates collaboration with non-technical teammates through features like A/B testing, versioning, and clean source-code management.
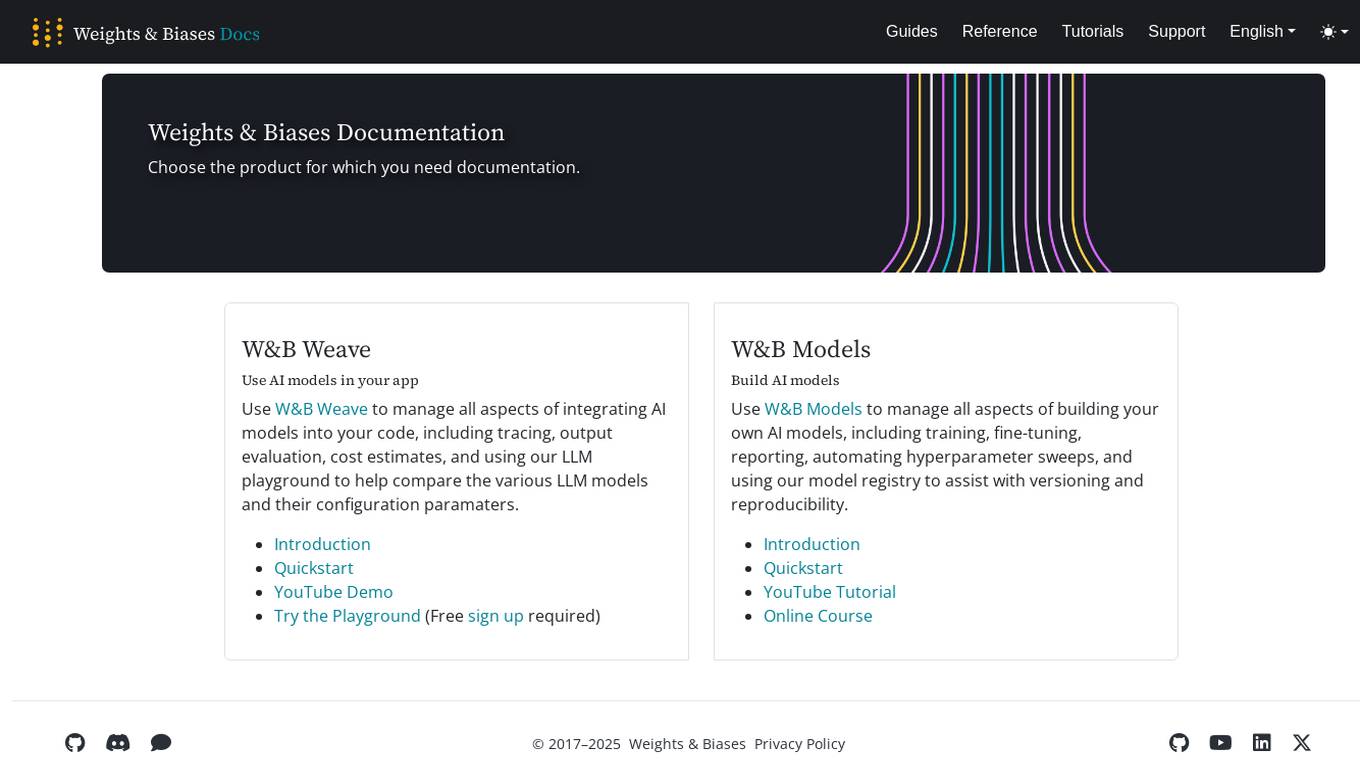
Weights & Biases
Weights & Biases is an AI tool that offers documentation, guides, tutorials, and support for using AI models in applications. The platform provides two main products: W&B Weave for integrating AI models into code and W&B Models for building custom AI models. Users can access features such as tracing, output evaluation, cost estimates, hyperparameter sweeps, model registry, and more. Weights & Biases aims to simplify the process of working with AI models and improving model reproducibility.
Autoblocks AI
Autoblocks AI is an AI application designed to help users build safe AI apps efficiently. It allows users to ship AI agents in minutes, speeding up the development process significantly. With Autoblocks AI, users can prototype quickly, test at a faster rate, and deploy with confidence. The application is trusted by leading AI teams and focuses on making AI agent development more predictable by addressing the unpredictability of user inputs and non-deterministic models.
Career Copilot
Career Copilot is an AI-powered hiring tool that helps recruiters and hiring managers find the best candidates for their open positions. The tool uses machine learning to analyze candidate profiles and identify those who are most qualified for the job. Career Copilot also provides a number of features to help recruiters streamline the hiring process, such as candidate screening, interview scheduling, and offer management.
MTestHub
MTestHub is an all-in-one recruiting and assessment automation solution that streamlines the hiring process for organizations. It harnesses AI technology to identify top talent, provides an authentic online examination platform, and offers features such as auto screening, shortlisting, efficient interviews, and post-shortlisting actions. The platform aims to enhance recruitment efficiency, improve candidate experience, and reduce administrative burdens through automation and data-driven insights.
AI Elections Accord
AI Elections Accord is a tech accord aimed at combating the deceptive use of AI in the 2024 elections. It sets expectations for managing risks related to deceptive AI election content on large-scale platforms. The accord focuses on prevention, provenance, detection, responsive protection, evaluation, public awareness, and resilience to safeguard the democratic process. It emphasizes collective efforts, education, and the development of defensive tools to protect public debate and build societal resilience against deceptive AI content.
Adminer
Adminer is a comprehensive platform designed to assist e-commerce entrepreneurs in identifying, analyzing, and validating profitable products. It leverages artificial intelligence to provide users with data-driven insights, enabling them to make informed decisions and optimize their product offerings. Adminer's suite of features includes product research, market analysis, supplier evaluation, and automated copywriting, empowering users to streamline their operations and maximize their sales potential.
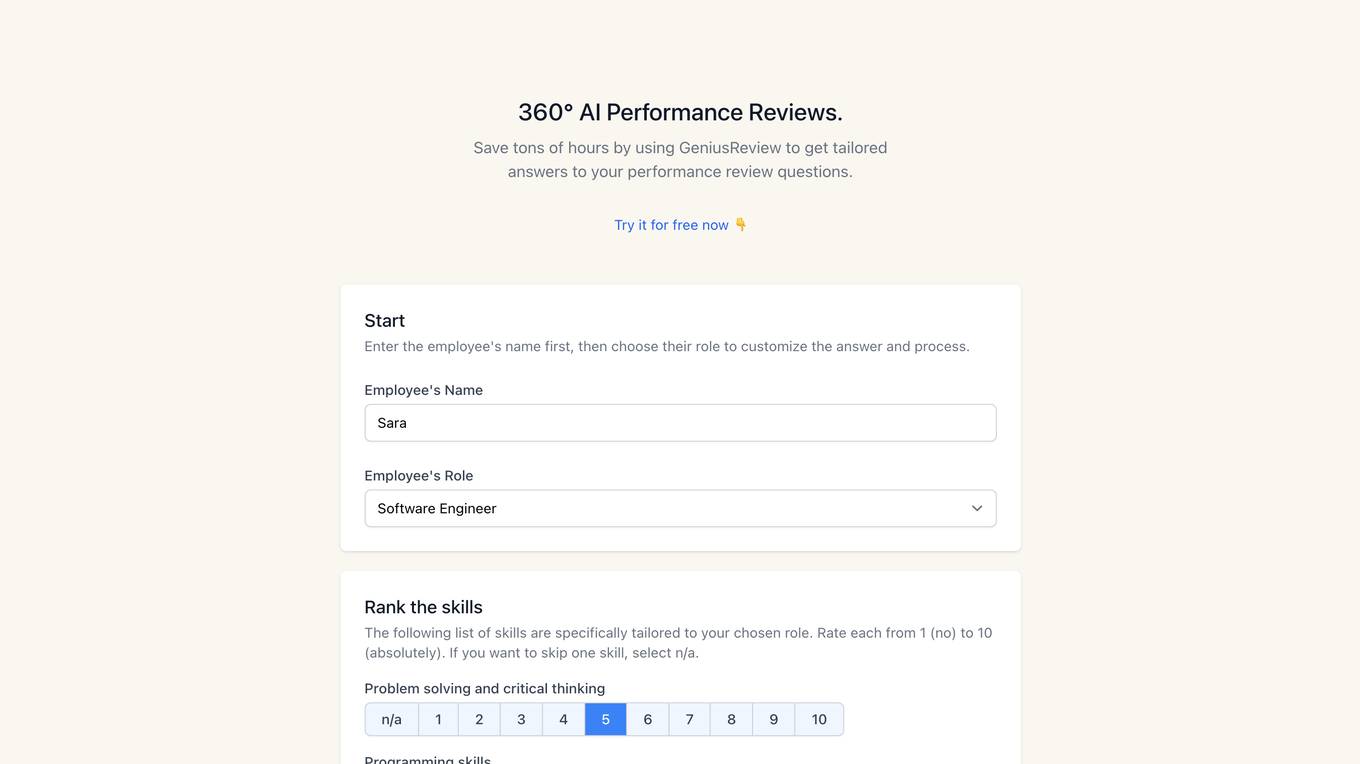
GeniusReview
GeniusReview is a 360° AI-powered performance review tool that helps users save time by providing tailored answers to performance review questions. Users can input employee names and roles to customize the review process, rank skills, add questions, and generate reviews with a chosen tone. The tool aims to streamline the performance review process and enhance feedback quality.

Graphio
Graphio is an AI-driven employee scoring and scenario builder tool that leverages continuous, real-time scoring with AI agents to assess potential, predict flight risks, and identify future leaders. It replaces subjective evaluations with AI-driven insights to ensure accurate, unbiased decisions in talent management. Graphio uses AI to remove bias in talent management, providing real-time, data-driven insights for fair decisions in promotions, layoffs, and succession planning. It offers compliance features and rules that users can control, ensuring accurate and secure assessments aligned with legal and regulatory requirements. The platform focuses on security, privacy, and personalized coaching to enhance employee engagement and reduce turnover.
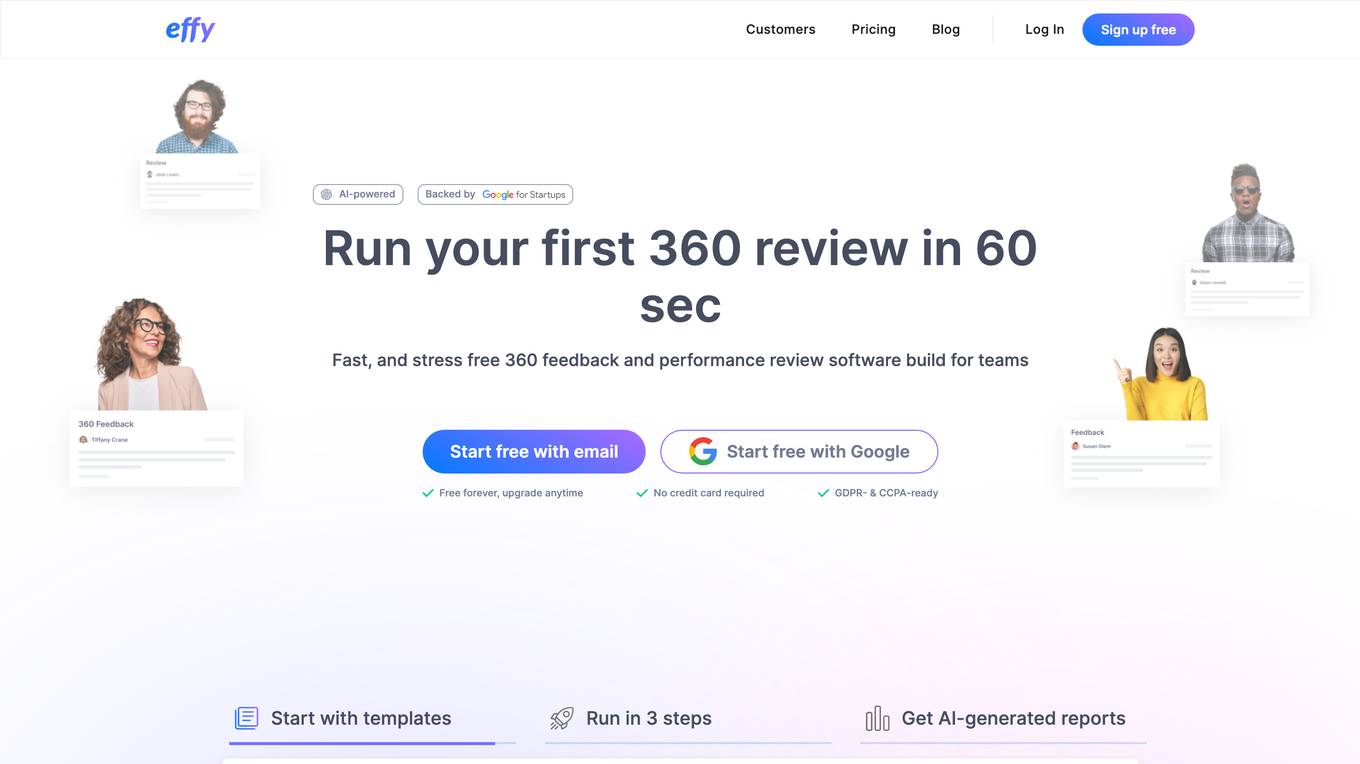
Effy AI
Effy AI is a free performance management software for teams. It is AI-powered and backed by Run your first 360 review in 60 sec. Fast, and stress-free 360 feedback and performance review software build for teams. With Effy AI, you can collect reviews from different sources such as self, peer, manager, and subordinate evaluations. The platform goes even further by allowing employees to suggest particular peers and seek approval from their manager, giving them a voice in their reviews. Effy AI uses cutting-edge artificial intelligence to carefully process reviewers' answers and generate comprehensive reports for each employee based on the review responses.
1st things 1st
1st things 1st is an online tool that helps users prioritize tasks and make decisions. It offers two prioritization tools: intuitive and smart. The intuitive tool allows users to compare options in pairs and organize them based on personal preferences. The smart tool uses AI-powered autosuggestion and fast evaluations to help users make confident and informed decisions. 1st things 1st also provides customizable templates and allows users to export their priorities to their favorite productivity apps. The tool is designed to help users clarify their goals, make complex decisions, and achieve their objectives.
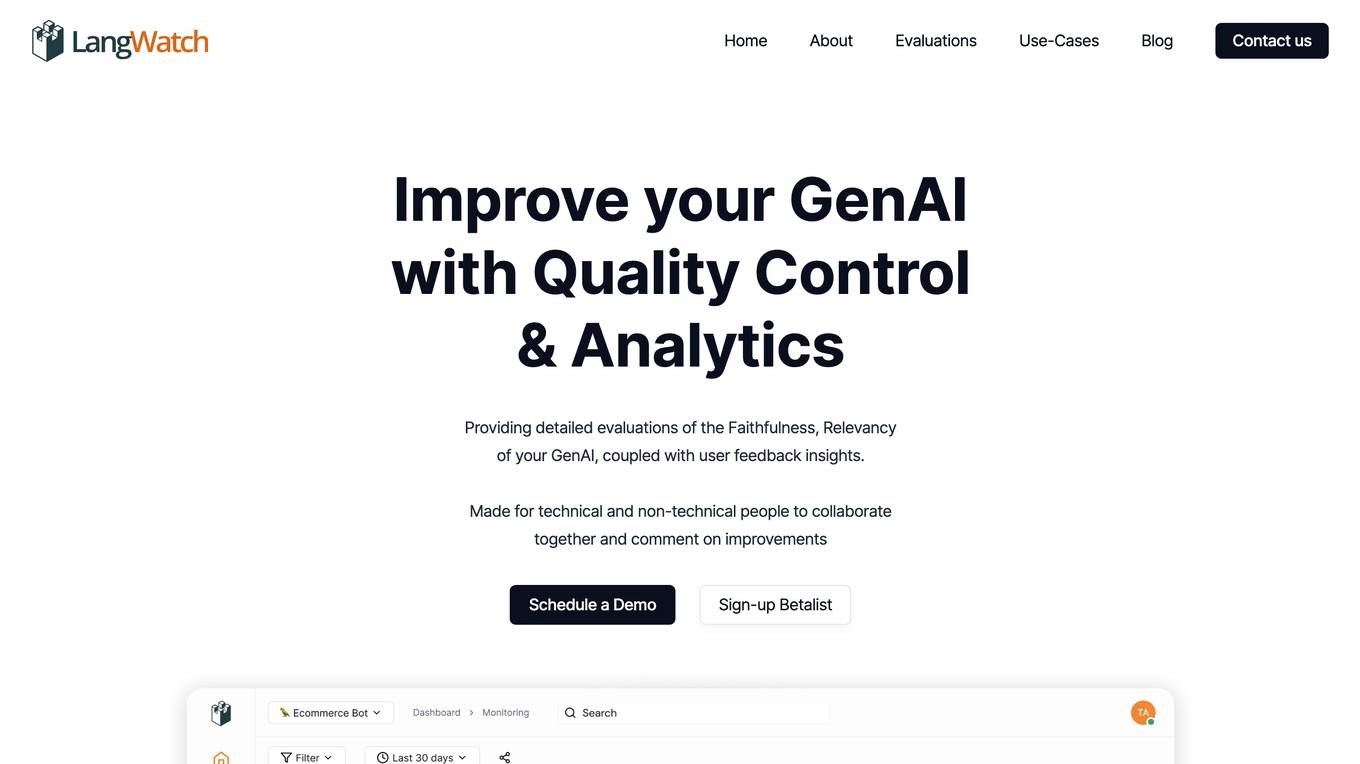
LangWatch
LangWatch is a monitoring and analytics tool for Generative AI (GenAI) solutions. It provides detailed evaluations of the faithfulness and relevancy of GenAI responses, coupled with user feedback insights. LangWatch is designed for both technical and non-technical users to collaborate and comment on improvements. With LangWatch, you can understand your users, detect issues, and improve your GenAI products.
Vervoe
Vervoe is an AI-powered recruitment platform and hiring solution that revolutionizes the hiring process by offering skills-based screening through AI job simulations and assessments. It streamlines interviews, provides standardized templates, and facilitates team collaboration. Vervoe enables data-backed decisions by ranking applicants based on performance and offering detailed reports. The platform focuses on task-based evaluations of job-specific skills, enhancing the accuracy of hiring decisions. Employers can create customized tests or choose from a library of scientifically mapped assessments. Vervoe uses AI for recruiting, grading, and ranking candidates efficiently. The platform enhances employer branding, offers candidate feedback, and ensures a seamless candidate experience. Vervoe caters to various industries and company types, making it a versatile tool for modern recruitment processes.
UpTrain
UpTrain is a full-stack LLMOps platform designed to help users confidently scale AI by providing a comprehensive solution for all production needs, from evaluation to experimentation to improvement. It offers diverse evaluations, automated regression testing, enriched datasets, and innovative techniques to generate high-quality scores. UpTrain is built for developers, compliant to data governance needs, cost-efficient, remarkably reliable, and open-source. It provides precision metrics, task understanding, safeguard systems, and covers a wide range of language features and quality aspects. The platform is suitable for developers, product managers, and business leaders looking to enhance their LLM applications.
1 - Open Source AI Tools

bocoel
BoCoEL is a tool that leverages Bayesian Optimization to efficiently evaluate large language models by selecting a subset of the corpus for evaluation. It encodes individual entries into embeddings, uses Bayesian optimization to select queries, retrieves from the corpus, and provides easily managed evaluations. The tool aims to reduce computation costs during evaluation with a dynamic budget, supporting models like GPT2, Pythia, and LLAMA through integration with Hugging Face transformers and datasets. BoCoEL offers a modular design and efficient representation of the corpus to enhance evaluation quality.
20 - OpenAI Gpts
Engineering Manager Coach
Guiding engineering managers with insights on team dynamics, development, and evaluations.
Project Post-Project Evaluation Advisor
Optimizes project outcomes through comprehensive post-project evaluations.

Supplier Evaluation Advisor
Assesses and recommends potential suppliers for organizational needs.


Agile Consultant
Expert in Agile SDLC, helping the teams to get familiar with best practices and provide audit and evaluation services

Valves Cardio Echo Consultant
Consultant GPT pour cardiologues, expert en évaluation échocardiographique des valves cardiaques et des prothèses valvulaires.
Acquisition Criteria Creator
Use me to help you decide what type of business to acquire. Let's go!
Evaluation Criteria Creator
Simply write any topic (anything superheroes, vacuums, Pokémon’, diamonds…) and I’ll provide the evaluation criteria you can use.

B2B Startup Ideal Customer Co-pilot
Guides B2B startups in a structured customer segment evaluation process. Stop guessing! Ideate, Evaluate & Make data-driven decision.
OKR Coach
AI OKR Coach is a tool designed to assist users in the process of creating and assessing OKR (Objectives and Key Results). It provides a structured and flexible approach to OKR setting and evaluation.

Startup Advisor
Startup advisor guiding founders through detailed idea evaluation, product-market-fit, business model, GTM, and scaling.


Vorstellungsgespräch Simulator Bewerbung Training
Wertet Lebenslauf und Stellenanzeige aus und simuliert ein Vorstellungsgespräch mit anschließender Auswertung: Lebenslauf und Anzeige einfach hochladen und starten.

Rate My {{Startup}}
I will score your Mind Blowing Startup Ideas, helping your to evaluate faster.