Best AI tools for< Manage Data Indexing >
20 - AI tool Sites
Encord
Encord is a leading data development platform designed for computer vision and multimodal AI teams. It offers a comprehensive suite of tools to manage, clean, and curate data, streamline labeling and workflow management, and evaluate AI model performance. With features like data indexing, annotation, and active model evaluation, Encord empowers users to accelerate their AI data workflows and build robust models efficiently.
Bloomfire
Bloomfire is an AI-based knowledge management software system that revolutionizes knowledge management within organizations. It offers AI-powered features such as enterprise search, authoring tools, data security, and collective knowledge engine. The platform enhances team collaboration, boosts efficiency, and empowers users to access and share knowledge seamlessly. Bloomfire's comprehensive solutions cater to various industries and team roles, providing valuable insights, customer support, and efficient knowledge sharing. With generative AI capabilities and deep indexing, Bloomfire ensures data readiness for AI initiatives, enabling users to make data-driven decisions and streamline processes.
Ranked
Ranked is an affordable SEO service that offers white label solutions for businesses and agencies. They provide human-written blog content, managed optimization, genuine backlinks, and leading SEO software. Their services are fully managed and structured for intent and engagement. Ranked utilizes AI engines for analysis, research, and outreach to deliver data-driven work and improve in-house productivity. However, they do not use AI for writing content due to inconsistent indexing on Google.
Ragie
Ragie is a fully managed RAG-as-a-Service platform designed for developers. It offers easy-to-use APIs and SDKs to help developers get started quickly, with advanced features like LLM re-ranking, summary index, entity extraction, flexible filtering, and hybrid semantic and keyword search. Ragie allows users to connect directly to popular data sources like Google Drive, Notion, Confluence, and more, ensuring accurate and reliable information delivery. The platform is led by Craft Ventures and offers seamless data connectivity through connectors. Ragie simplifies the process of data ingestion, chunking, indexing, and retrieval, making it a valuable tool for AI applications.
KERV Solutions
KERV is an AI-powered video and creative technology company that offers ad performance solutions, publisher revenue opportunities, in-show monetization solutions, and data and measurement services. Their patented image recognition and product correlation technology enable deeper relationships between publishers, brands, and consumers. KERV's AI technology makes any video explorable and shoppable with unrivaled speed and precision, delivering real business outcomes. They provide intelligent video solutions, active attention indexing, greater speed and precision, 1st party data insights, and brand safety measures.
Keepi
Keepi is a personal knowledge AI tool that operates over WhatsApp, allowing users to effortlessly capture, organize, and retrieve their knowledge. It enables users to forward texts, links, images, and voice messages to Keepi on WhatsApp, where everything is saved instantly. Keepi understands and transcribes voice notes, reads articles, and extracts key information, automatically organizing and indexing knowledge for quick retrieval. Users can ask Keepi anything and receive instant answers based on their saved content, creating a personalized knowledge base accessible within WhatsApp. Keepi simplifies information management and retrieval, enhancing productivity and efficiency in daily tasks.
500 supabaseUrl
500 supabaseUrl is a cloud-based database service that provides a fully managed, scalable, and secure way to store and manage data. It is designed to be easy to use, with a simple and intuitive interface that makes it easy to create, manage, and query databases. 500 supabaseUrl is also highly scalable, so it can handle even the most demanding workloads. And because it is fully managed, you don't have to worry about the underlying infrastructure or maintenance tasks.
One Data
One Data is an AI-powered data product builder that offers a comprehensive solution for building, managing, and sharing data products. It bridges the gap between IT and business by providing AI-powered workflows, lifecycle management, data quality assurance, and data governance features. The platform enables users to easily create, access, and share data products with automated processes and quality alerts. One Data is trusted by enterprises and aims to streamline data product management and accessibility through Data Mesh or Data Fabric approaches, enhancing efficiency in logistics and supply chains. The application is designed to accelerate business impact with reliable data products and support cost reduction initiatives with advanced analytics and collaboration for innovative business models.
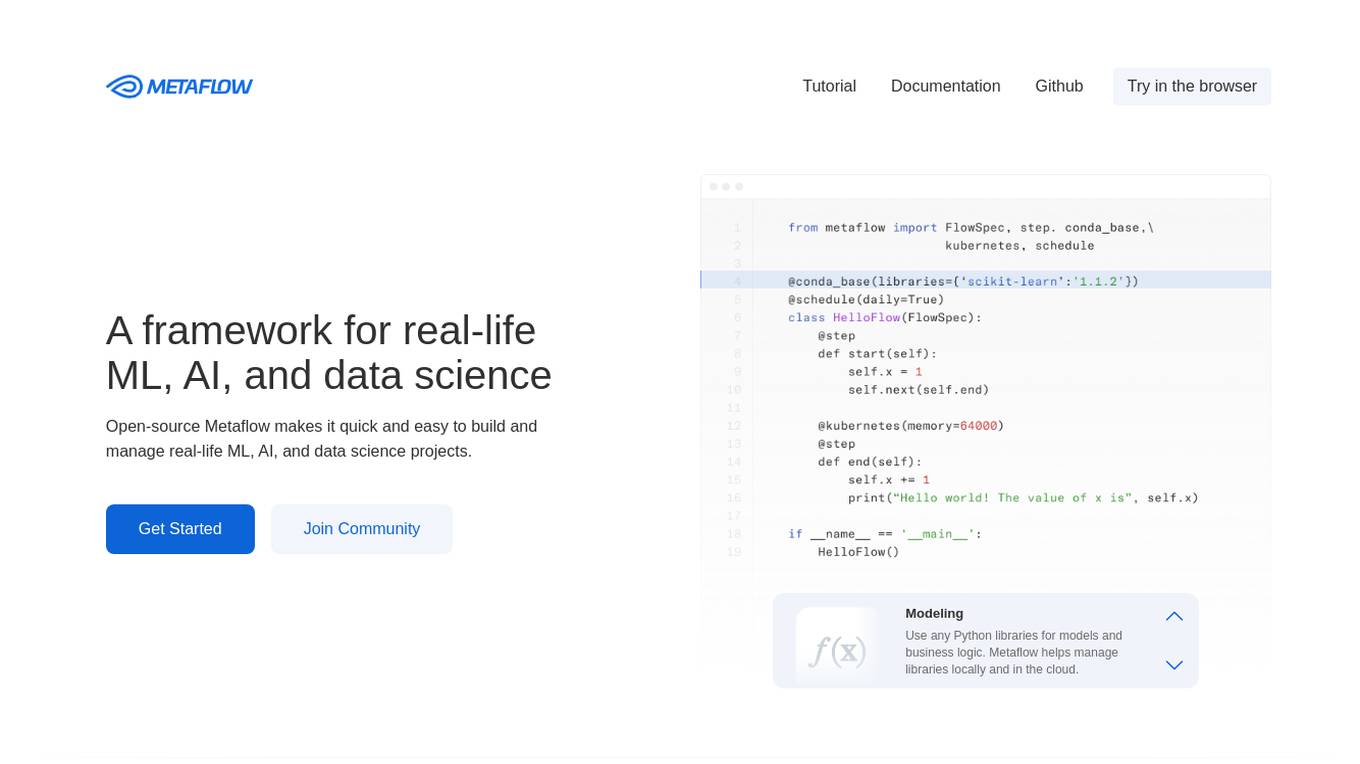
Metaflow
Metaflow is an open-source framework for building and managing real-life ML, AI, and data science projects. It makes it easy to use any Python libraries for models and business logic, deploy workflows to production with a single command, track and store variables inside the flow automatically for easy experiment tracking and debugging, and create robust workflows in plain Python. Metaflow is used by hundreds of companies, including Netflix, 23andMe, and Realtor.com.
Dot Group Data Advisory
Dot Group is an AI-powered data advisory and solutions platform that specializes in effective data management. They offer services to help businesses maximize the potential of their data estate, turning complex challenges into profitable opportunities using AI technologies. With a focus on data strategy, data engineering, and data transport, Dot Group provides innovative solutions to drive better profitability for their clients.

Columns AI
Columns AI is a powerful platform that automates data storytelling through AI technology. It offers seamless data integration, transformation, and professional storytelling capabilities. Users can connect various data sources, transform data into compelling visual narratives, and effortlessly build stunning content with AI-enhanced tools. The platform allows users to share visual stories, schedule automatic updates, and collaborate on data visualization projects. Columns AI simplifies the complexity of data storytelling and empowers users to communicate insights effectively.
Walter Shields Data Academy
Walter Shields Data Academy is an AI-powered platform offering premium training in SQL, Python, and Excel. With over 200,000 learners, it provides curated courses from bestselling books and LinkedIn Learning. The academy aims to revolutionize data expertise and empower individuals to excel in data analysis and AI technologies.
MineOS
MineOS is an automation-driven platform that focuses on privacy, security, and compliance. It offers a comprehensive suite of tools and solutions to help businesses manage their data privacy needs efficiently. By leveraging AI and special discovery methods, MineOS adapts unique data processes to universal privacy standards seamlessly. The platform provides features such as data mapping, AI governance, DSR automations, consent management, and security & compliance solutions to ensure data visibility and governance. MineOS is recognized as the industry's #1 rated data governance platform, offering cost-effective control of data systems and centralizing data subject request handling.

DVC
DVC is an open-source platform for managing machine learning data and experiments. It provides a unified interface for working with data from various sources, including local files, cloud storage, and databases. DVC also includes tools for versioning data and experiments, tracking metrics, and automating compute resources. DVC is designed to make it easy for data scientists and machine learning engineers to collaborate on projects and share their work with others.

RIDO Protocol
RIDO Protocol is a decentralized data protocol that allows users to extract value from their personal data in Web2 and Web3. It provides users with a variety of features, including programmable data generation, programmable access control, and cross-application data sharing. RIDO also has a data marketplace where users can list or offer their data information and ownership. Additionally, RIDO has a DataFi protocol which promotes the flowing of data information and value.
Velotix
Velotix is an AI-powered data security platform that offers groundbreaking visual data security solutions to help organizations discover, visualize, and use their data securely and compliantly. The platform provides features such as data discovery, permission discovery, self-serve data access, policy-based access control, AI recommendations, and automated policy management. Velotix aims to empower enterprises with smart and compliant data access controls, ensuring data integrity and compliance. The platform helps organizations gain data visibility, control access, and enforce policy compliance, ultimately enhancing data security and governance.
OneTrust
OneTrust is a Trust Intelligence Cloud Solutions platform that leverages data and artificial intelligence to drive trusted innovation across privacy, security, and ethics initiatives. It offers a comprehensive suite of solutions for privacy management, data discovery, security, consent and preferences, AI governance, technology risk and compliance, compliance automation, third-party risk, and ethics program management. With over 14,000 customers worldwide, OneTrust helps organizations manage risk, ensure compliance, and build trust through responsible data and AI usage.
DataBahn
DataBahn is an AI-powered data pipeline management platform that empowers global enterprises with intelligent tools to gather, manage, and move data reliably and quickly. It offers a comprehensive solution for data integration, management, and optimization, helping users save costs and time. The platform ensures real-time insights, agility, and value by automating data processes and providing complete data ownership and governance. DataBahn is trusted by ambitious companies and partners worldwide for its efficiency and effectiveness in handling data workflows.

Superjoin
Superjoin is an AI-powered tool that allows users to automatically pull data from various tools into Google Sheets without the need for writing any code. It offers features like one-click connectors, auto-refresh schedules, data preview, and the ability to send report screenshots to Slack and Email. Superjoin is loved by thousands of users across hundreds of companies for its efficiency in automating workflows and data management.

SID
SID is a data ingestion, storage, and retrieval pipeline that provides real-time context for AI applications. It connects to various data sources, handles authentication and permission flows, and keeps information up-to-date. SID's API allows developers to retrieve the right piece of data for a given task, enabling them to build AI apps that are fast, accurate, and scalable. With SID, developers can focus on building their products and leave the data management to SID.
0 - Open Source AI Tools
20 - OpenAI Gpts
👑 Data Privacy for PI & Security Firms 👑
Private Investigators and Security Firms, given the nature of their work, handle highly sensitive information and must maintain strict confidentiality and data privacy standards.
👑 Data Privacy for Watch & Jewelry Designers 👑
Watchmakers and Jewelry Designers, high-end businesses dealing with valuable items and personal details of clients, making data privacy and security paramount.
👑 Data Privacy for Event Management 👑
Data Privacy for Event Management and Ticketing Services handle personal data such as names, contact details, and payment information for event registrations and ticket purchases.

DataKitchen DataOps and Data Observability GPT
A specialist in DataOps and Data Observability, aiding in data management and monitoring.
Data Governance Advisor
Ensures data accuracy, consistency, and security across organization.

👑 Data Privacy for Home Inspection & Appraisal 👑
Home Inspection and Appraisal Services have access to personal property and related information, requiring them to be vigilant about data privacy.
👑 Data Privacy for Freelancers & Independents 👑
Freelancers and Independent Consultants, individuals in these roles often handle client data, project specifics, and personal contact information, requiring them to be vigilant about data privacy.
👑 Data Privacy for Architecture & Construction 👑
Architecture and Construction Firms handle sensitive project data, client information, and architectural plans, necessitating strict data privacy measures.
👑 Data Privacy for Real Estate Agencies 👑
Real Estate Agencies and Brokers deal with personal data of clients, including financial information and preferences, requiring careful handling and protection of such data.
👑 Data Privacy for Spa & Beauty Salons 👑
Spa and Beauty Salons collect Customer inforation, including personal details and treatment records, necessitating a high level of confidentiality and data protection.
Data Engineer Consultant
Guides in data engineering tasks with a focus on practical solutions.

Data Architect
Database Developer assisting with SQL/NoSQL, architecture, and optimization.

Snowflake Copilot
Your personal Snowflake assistant and copilot with a focus on efficient, secure, and scalable data warehousing. Trained with the latest knowledge and docs.