Best AI tools for< Make Audio Versions >
20 - AI tool Sites
imagetomp3.com
imagetomp3.com is a website that allows users to convert images to MP3 files. Users can upload an image, and the website will convert it into an audio file. The site provides a simple and convenient way to create audio files from images, which can be useful for various purposes such as creating audio versions of visual content or generating unique sound effects. imagetomp3.com offers a user-friendly interface and quick conversion process, making it a handy tool for those looking to convert images to audio effortlessly.
Vocalremover.org
Vocalremover.org is a website that offers a tool to remove vocals from music tracks. Users can upload their audio files and the tool will process them to create a version with the vocals removed. The site aims to provide a simple and efficient solution for users looking to create karaoke tracks or instrumental versions of songs. Vocalremover.org ensures security by verifying user connections and requires enabling JavaScript and cookies for smooth operation.
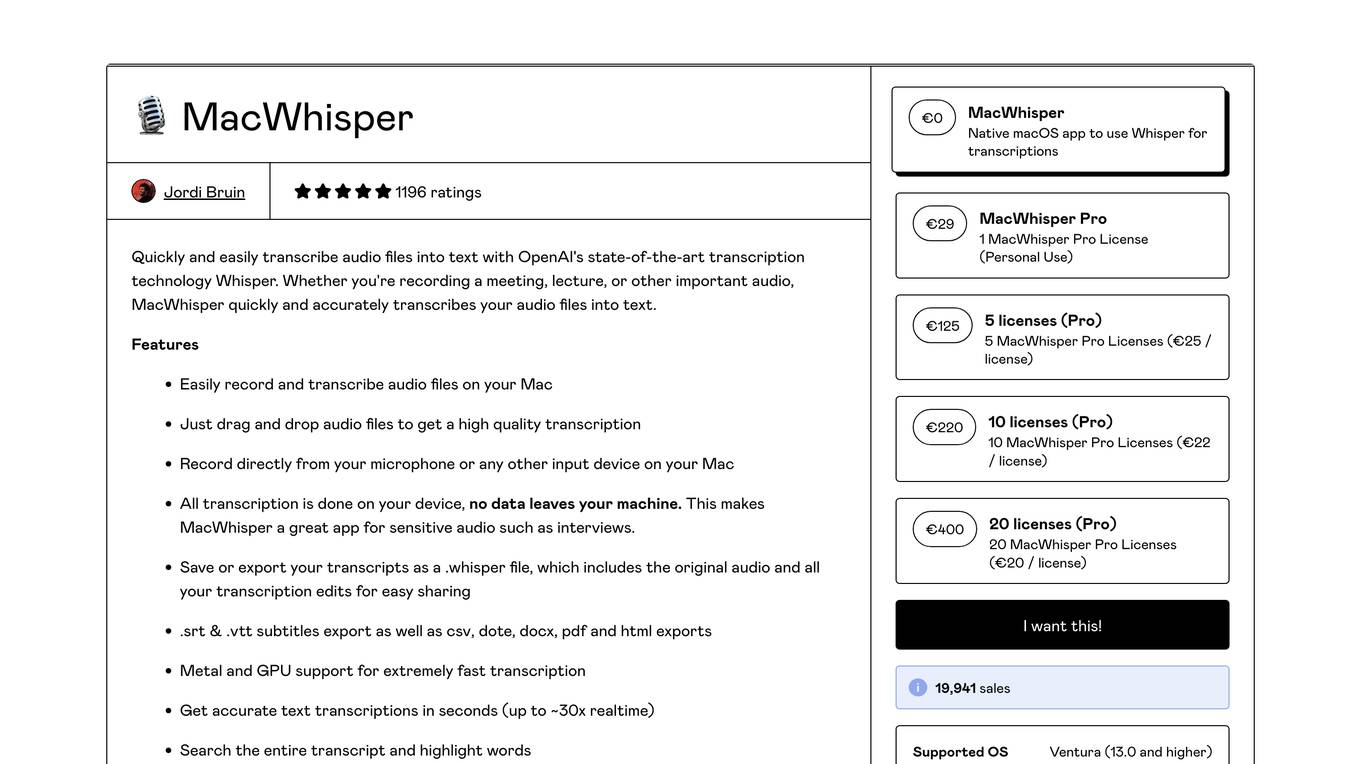
MacWhisper
MacWhisper is a native macOS application that utilizes OpenAI's Whisper technology for transcribing audio files into text. It offers a user-friendly interface for recording, transcribing, and editing audio, making it suitable for various use cases such as transcribing meetings, lectures, interviews, and podcasts. The application is designed to protect user privacy by performing all transcriptions locally on the device, ensuring that no data leaves the user's machine.
AudioShake
AudioShake is a cloud-based audio processing platform that uses artificial intelligence (AI) to separate audio into its component parts, such as vocals, music, and effects. This technology can be used for a variety of applications, including mixing and mastering, localization and captioning, interactive audio, and sync licensing.
Article to Audio Converter
This AI-powered tool allows you to effortlessly convert written articles into engaging, podcast-quality audio. With just a click, you can transform your content into captivating audio experiences, making it accessible to a wider audience and enhancing its impact.
Samplab
Samplab is an AI-powered audio editing tool that allows users to manipulate audio samples with advanced features such as note editing, chord detection, stem separation, audio to MIDI conversion, and audio warping. It offers a seamless integration with digital audio workstations (DAWs) as a plugin or desktop app, enabling producers to enhance their music production workflow. Samplab's AI technology revolutionizes the way users interact with audio samples, providing unprecedented control over notes, chords, and melodies.

Koolio.ai
Koolio.ai is an AI-powered storytelling platform that helps you create engaging and personalized stories. With Koolio.ai, you can easily generate story ideas, develop characters, and write compelling narratives. Whether you're a professional writer, a student, or just someone who loves to tell stories, Koolio.ai can help you take your storytelling to the next level.
Stable Audio
Stable Audio is a generative AI tool that allows users to create high-quality music and sound effects. It is powered by the latest audio diffusion models and offers a range of features that make it easy to create custom music. With Stable Audio, users can generate music of any length, style, or genre, and they can even use their own voice or instruments to create unique tracks. The generated audio can be downloaded in 44.1 kHz stereo and used in commercial projects.
Otter.ai
Otter.ai is an AI-powered meeting note-taking and real-time transcription solution designed to enhance productivity and collaboration in business settings. It offers a range of features, including automatic note-taking, live summaries, action item tracking, and AI-powered chat assistance. Otter.ai integrates with popular video conferencing platforms such as Zoom, Google Meet, and Microsoft Teams, allowing users to capture and transcribe meeting content effortlessly. The platform also provides customizable templates, collaboration tools, and integrations with other business applications to streamline workflows and improve team efficiency.
Amped Studio
Amped Studio is an online music sequencer and sound editor that provides users with the tools and resources they need to create music. The platform offers a variety of features, including a built-in drum machine, sequencer tracks, and a rich sample library. Amped Studio also allows users to connect third-party instruments and effects using VST technology. The platform is designed to be easy to use, even for beginners, and it offers a variety of tutorials and articles to help users get started.
GPT4Audio
GPT4Audio is an AI-based desktop application that offers speech-to-text and text-to-speech capabilities. It allows users to transcribe and translate audio files from multiple languages, as well as dictate text and generate audio recordings in real time. The application also includes an Article Wizard feature that can help users create homework essays, marketing content, articles, or blogs quickly and easily.

Paper Pilot
Paper Pilot is the ultimate AI tool for concise research paper summaries, key insights, and audio guides. It uses cutting-edge AI to enhance research by providing quick, precise summaries of research papers, organizing research boards, and offering an interactive chat for AI-specific questions. Trusted by top researchers, Paper Pilot simplifies and accelerates the study process, saving valuable time and effort.
SpeechEasy
SpeechEasy is a high-quality text-to-speech tool that harnesses the power of AI and machine learning to convert text into natural-sounding audio. With SpeechEasy, you can generate studio-grade synthetic voices that are easy to understand and consume, making it perfect for on-the-go listening, home or office use, and e-learning content.
Podcastle
Podcastle is an all-in-one podcasting software that empowers creators of all backgrounds and experience levels with an intuitive, AI-powered platform. It offers a wide range of features, including a recording studio, audio editor, video editor, AI-generated voices, and hosting hub, making it easy to create, edit, and publish high-quality podcasts and videos. Podcastle is designed to be user-friendly and accessible, with no prior experience or technical expertise required.
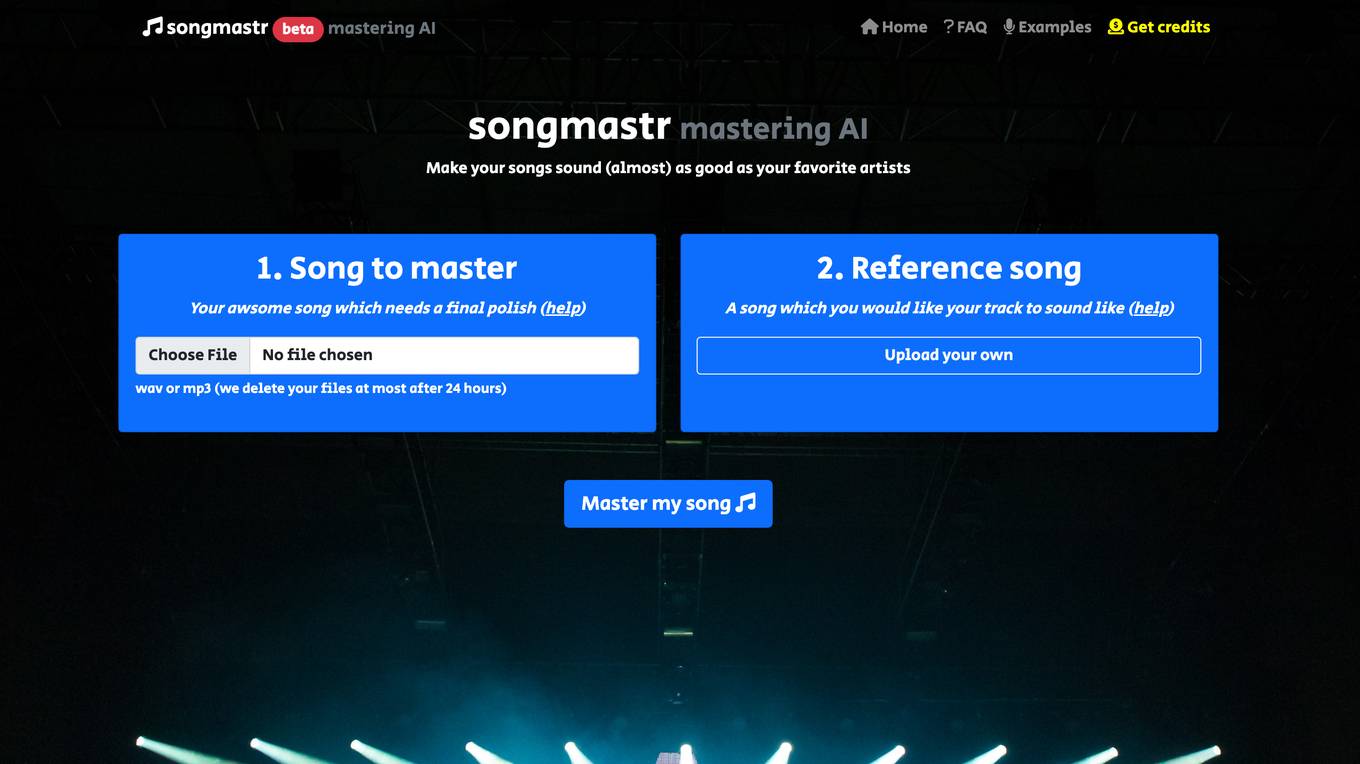
Songmastr
Songmastr is an automatic song mastering tool that uses artificial intelligence to master your songs to sound like a reference track. It's free to use for up to 7 songs per week, and you can master songs up to 10 minutes in length and 80MB in size. Songmastr is based on the open source library Matchering, and it uses the same RMS, FR, peak amplitude, and stereo width as the reference song you choose.
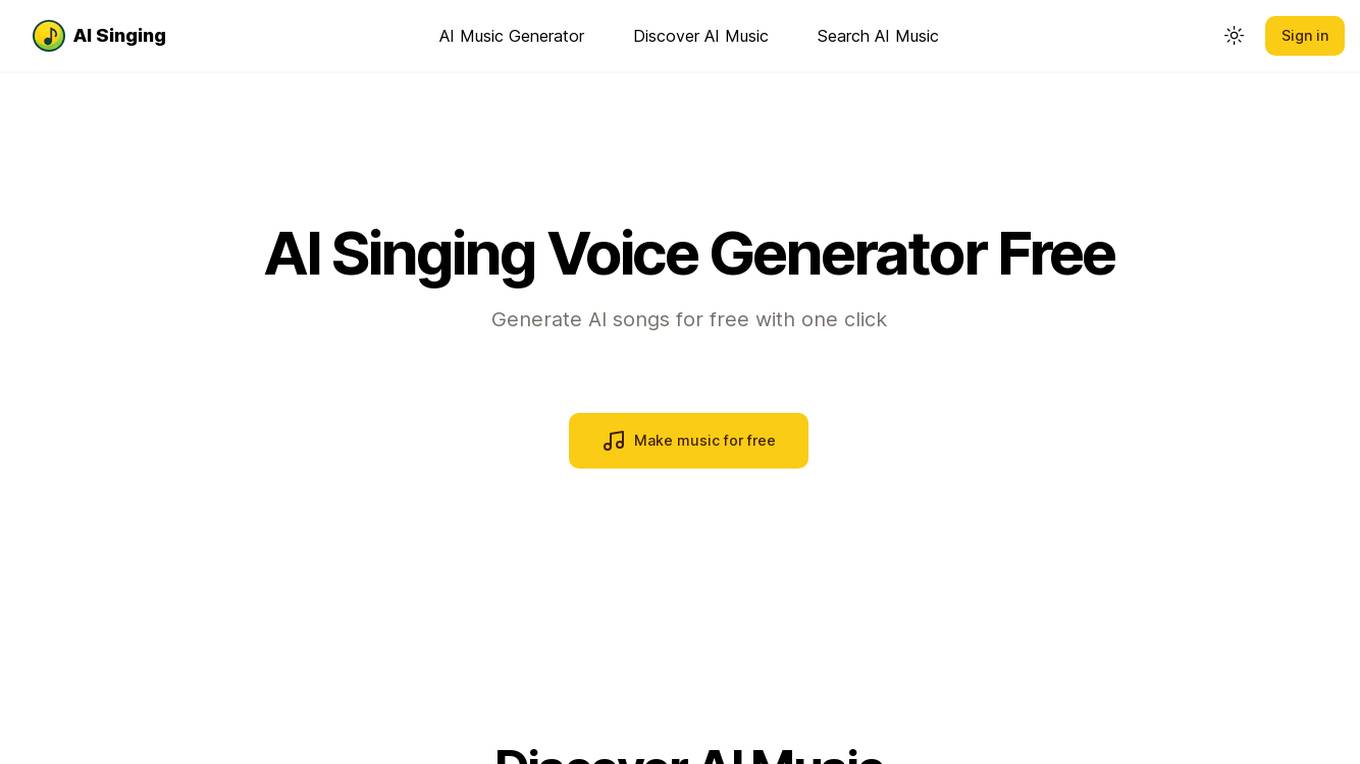
AI Singing
AI Singing is an AI-powered tool that allows users to generate music and singing voices from text. With AI Singing, you can quickly and easily create songs by simply entering your lyrics. The tool uses advanced artificial intelligence algorithms to convert your text into realistic and expressive singing voices. AI Singing is perfect for musicians, singers, songwriters, and anyone who wants to create music without having to spend hours learning complex music production software.
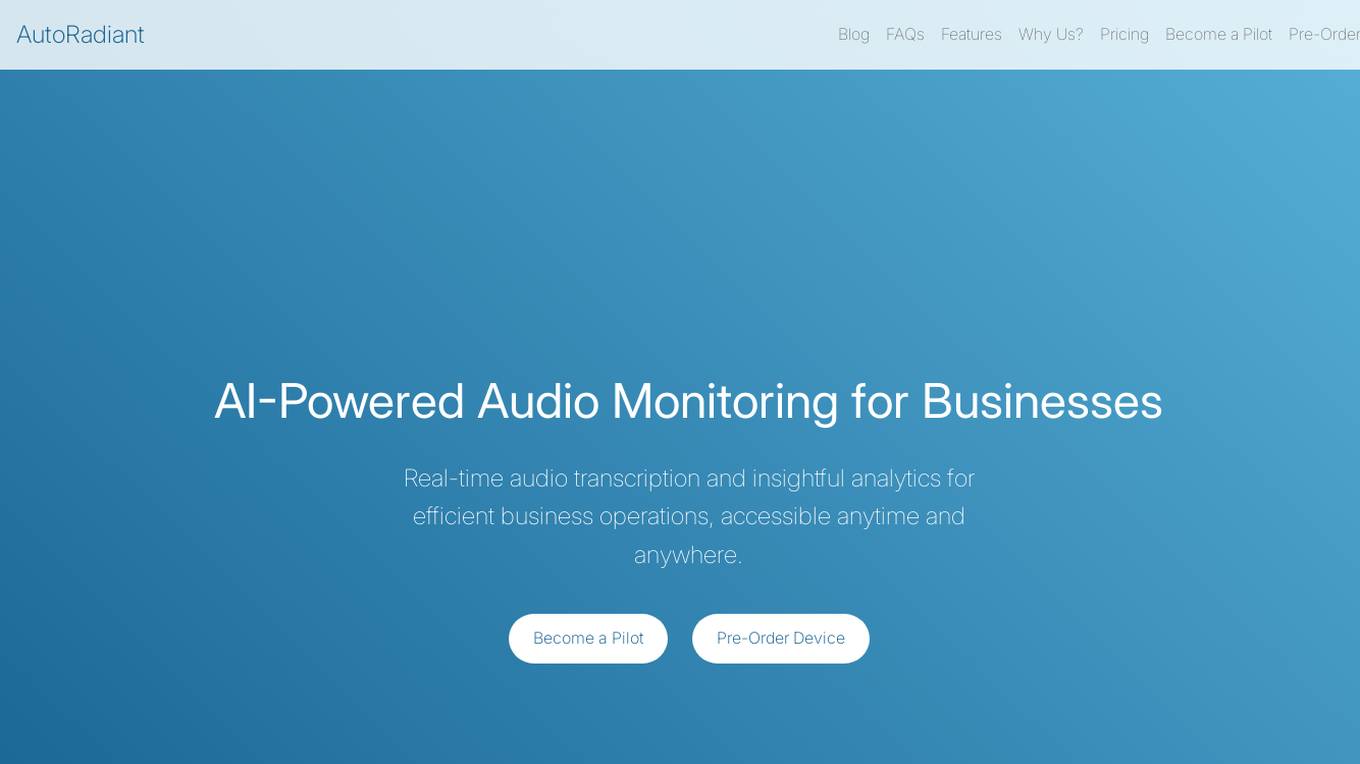
AutoRadiant
AutoRadiant is an AI-powered audio monitoring tool designed for businesses to enhance customer experience and optimize operations. It provides real-time audio transcription and insightful analytics, enabling efficient business operations accessible anytime and anywhere. With features like AI noise reduction, daily transcription summaries, and instant alerts, AutoRadiant helps businesses focus on meaningful customer interactions, turn conversations into actionable insights, and make data-driven decisions. The tool ensures top-notch security measures, strict privacy protocols, and full legal compliance to protect business and customer data.
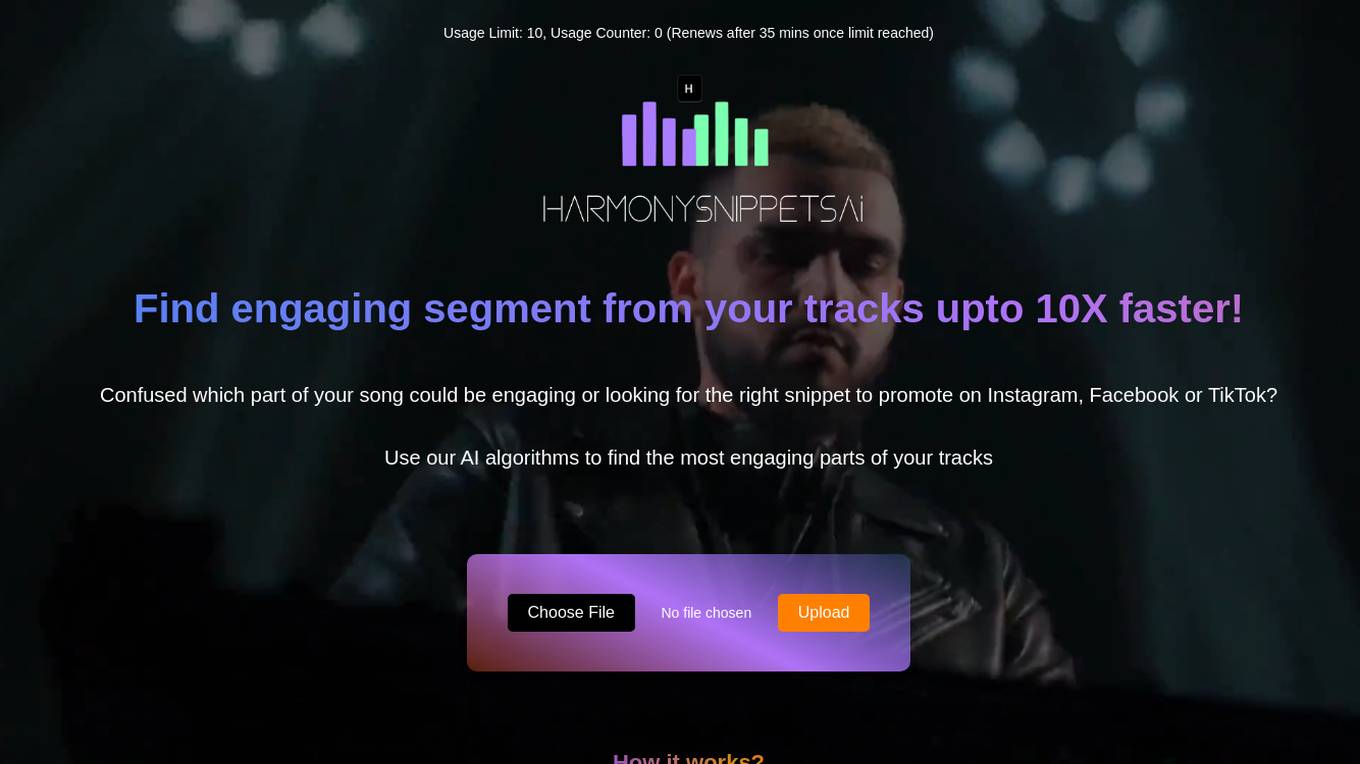
HarmonySnippetsAI
HarmonySnippetsAI is an AI application designed to help music creators and content producers identify engaging segments within their tracks quickly and efficiently. By leveraging AI algorithms, users can upload audio files and receive results that highlight the most captivating parts of their music. This tool is ideal for musicians looking to promote their work on social media platforms like Instagram, Facebook, and TikTok, enhancing audience engagement and expanding their reach.
Transkribieren.xyz
Transkribieren.xyz is an all-in-one AI workspace that brings together the best AI tools for a more efficient workday. It offers a variety of features including transcription, text chat, and image creation. Transkribieren.xyz is trusted by people worldwide and is the go-to transcription solution for those who value speed, accuracy, and simplicity.
3Play Media
3Play Media is a leading provider of AI-powered media accessibility solutions. Our mission is to make the world's media accessible to everyone, regardless of their abilities. We offer a suite of products and services that make it easy to add captions, transcripts, audio descriptions, and other accessibility features to your videos and audio content.
0 - Open Source AI Tools
20 - OpenAI Gpts

Make your words bad
Hi! I'll convert your words into poor language. first, try to type "hamburger"
Make poke
Make custom Pokémon from camera. Download and battle them verses real ones! (beta)
Make Money with Chat G P T
Satirical take on the ridiculous secondary marketing of AI's early days.
Make My NDA
Generates precise and friendly NDAs. Ensures all important clauses are covered.
PosterPal | Make your own posters! 🎨
I'll turn your crazy artwork ideas into posters, shipped straight to your door.

Roast My Outfit and Make It Better
Unleashes extreme humor and sarcasm in fashion critiques.
100 Remote Ways to Make Money
Expert on online freelancing, digital marketing, and e-commerce
How to Make Money Online
AI Money Insights Tool delivers expert guidance on topics like How to Make Money Online and Ways to Make Money Online, empowering you with smart strategies to Earn Money Online effectively. Explore AI-driven insights for your financial success.
How To Make Your Computer Faster: Speed Up Your PC
A Guide To Speed Up Your Computer from Geeks On Command Computer Repair Company

Biophilia Sage
I'll help you to make decisions that are imbued with Biophilia - the human tendency to be drawn towards life and life-like processes.