Best AI tools for< Generate Audio Files >
20 - AI tool Sites
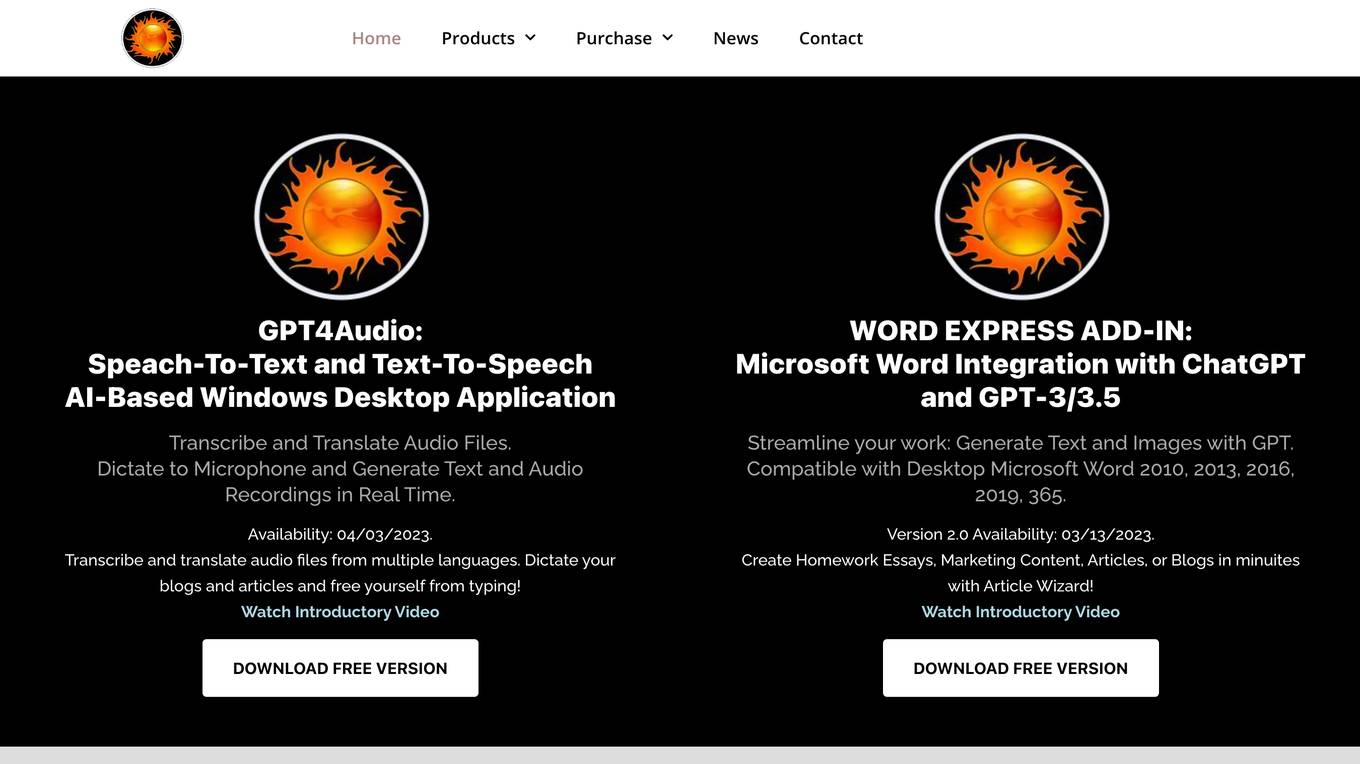
GPT4Audio
GPT4Audio is an AI-based desktop application that offers speech-to-text and text-to-speech capabilities. It allows users to transcribe and translate audio files from multiple languages, as well as dictate text and generate audio recordings in real time. The application also includes an Article Wizard feature that can help users create homework essays, marketing content, articles, or blogs quickly and easily.
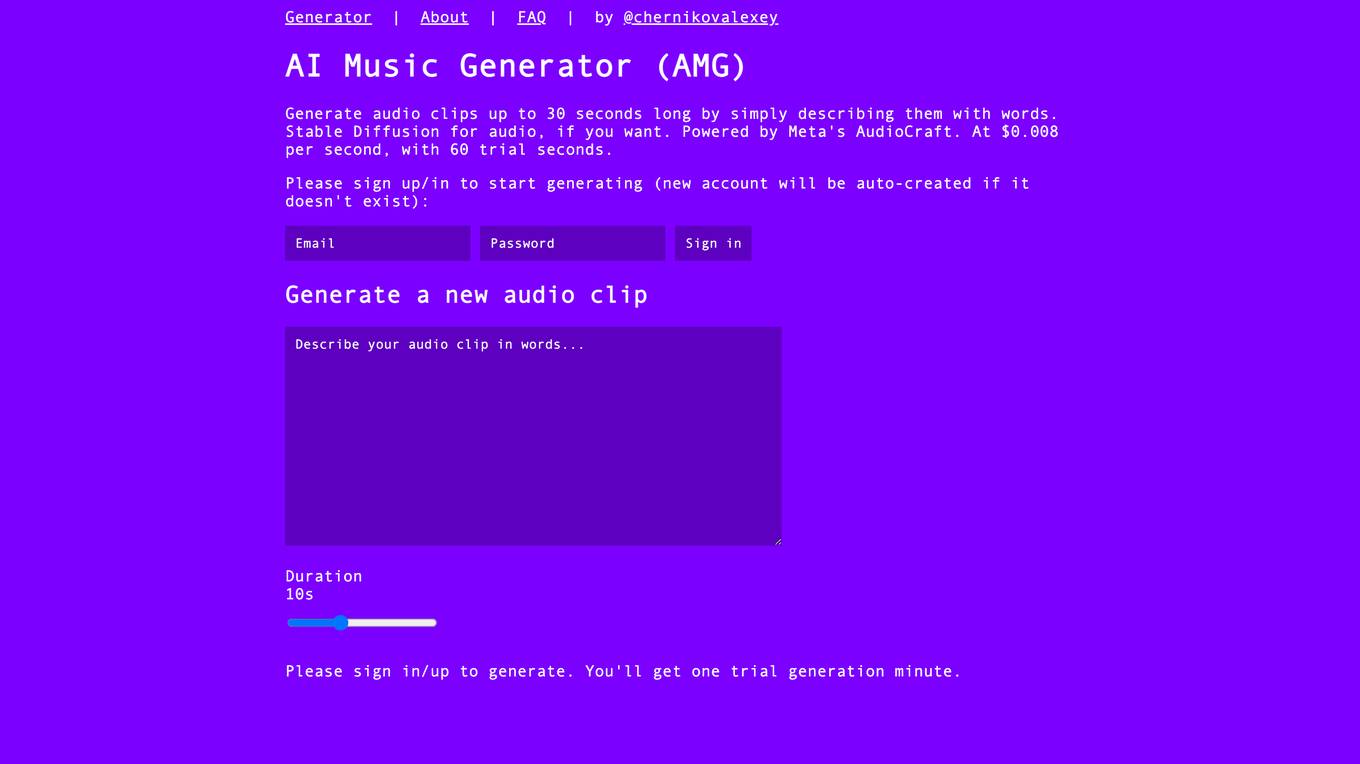
AI Music Generator (AMG)
AI Music Generator (AMG) is an AI tool that allows users to generate audio clips up to 30 seconds long by describing them with words. It utilizes Stable Diffusion for audio generation and is powered by Meta's AudioCraft. Users can create new audio clips at a cost of $0.008 per second, with a trial period of 60 seconds. Signing up or logging in is required to start generating, with new accounts being auto-created if necessary.
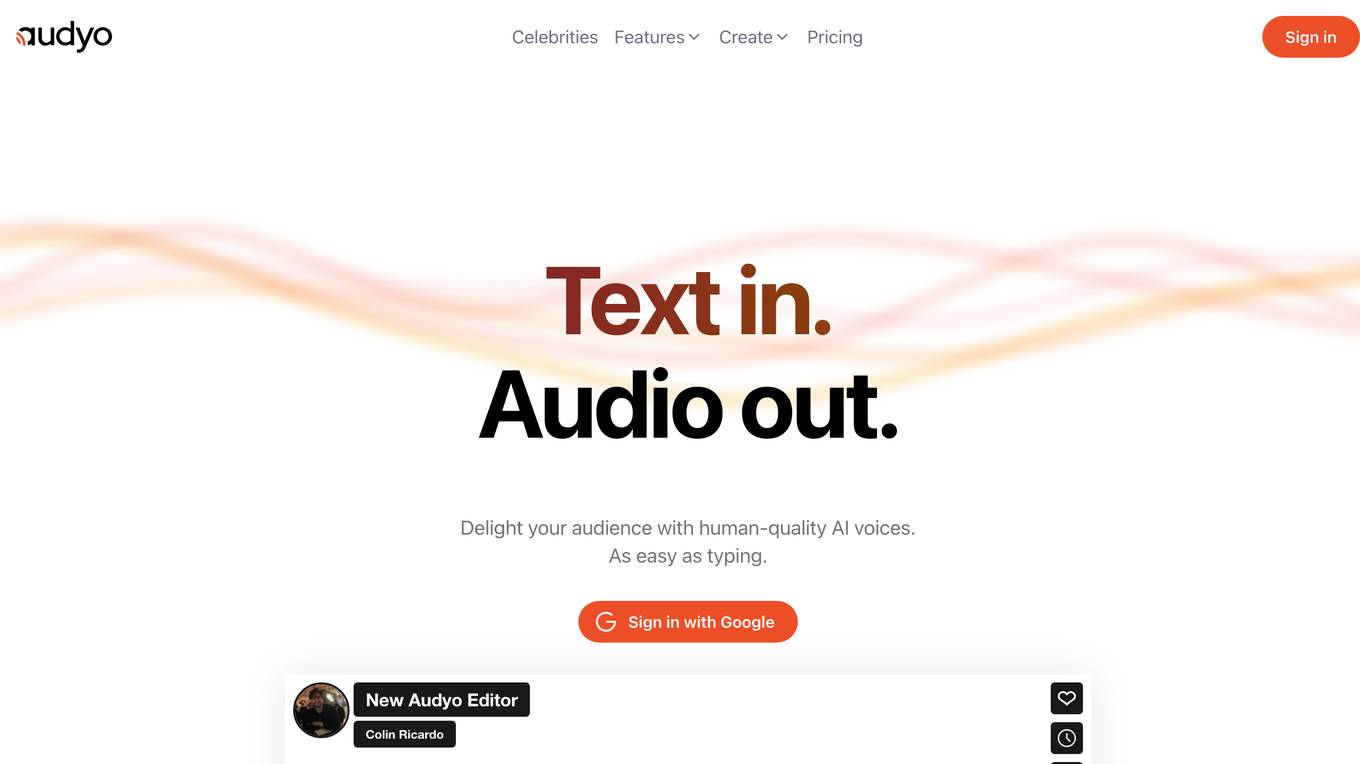
Audyo
Audyo is a text-to-speech tool that allows users to create realistic-sounding audio from text. With over 100 voices to choose from, users can create audio in a variety of languages and accents. Audyo is easy to use, simply type in your text and select a voice. You can then download your audio file or embed it on your website or blog. Audyo is a great tool for creating voiceovers for videos, podcasts, audiobooks, and more.
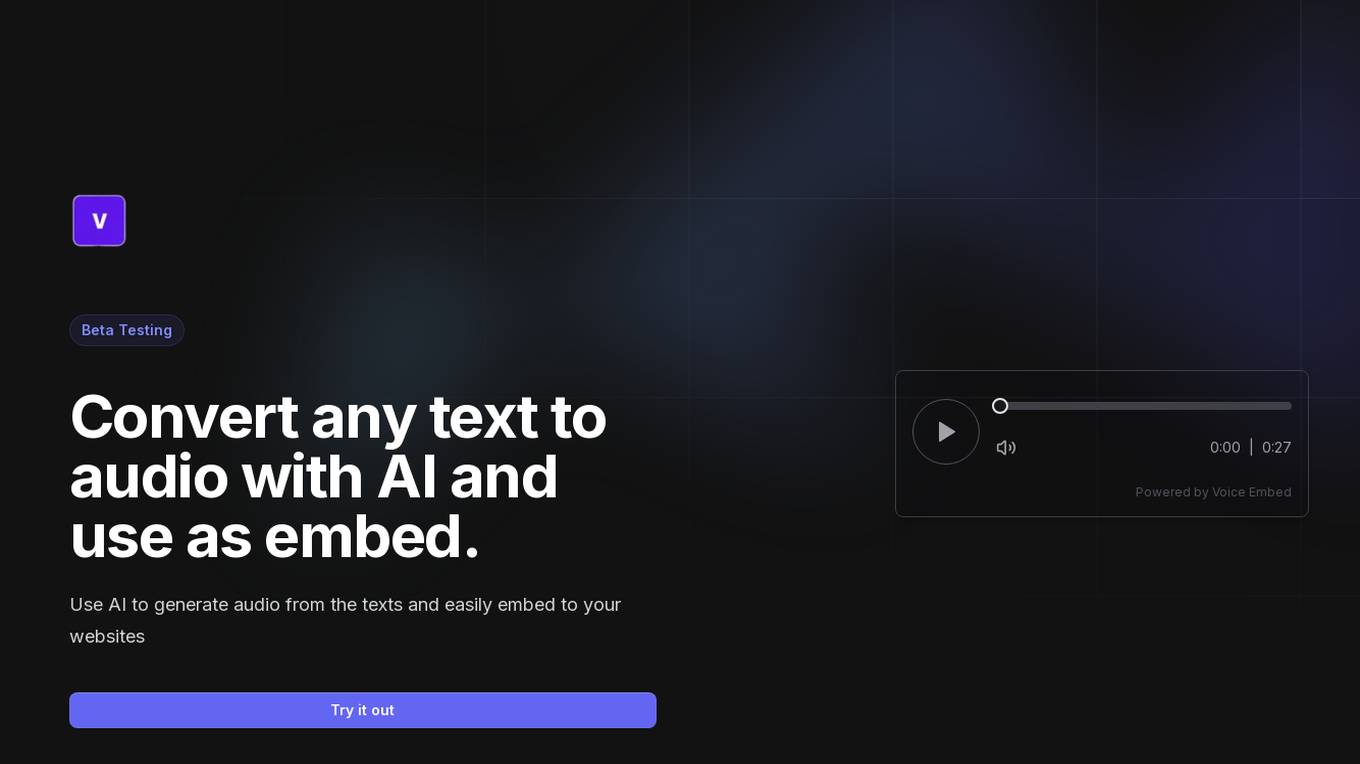
Voice Embed
Voice Embed is an AI tool that allows users to convert any text into audio using AI technology. Users can easily embed the generated audio into their websites, making the content more engaging and interactive. Voice Embed provides a one-click solution to create and share audio from articles, with free cloud storage for all generated audio files. The tool simplifies the process of adding audio to blogs and websites, offering a user-friendly experience for content creators.
CloneMyVoice
CloneMyVoice is an AI tool that specializes in creating AI audio voiceovers for long-form content such as podcasts, presentations, and social media. Users can save up to 80% compared to competitors and 99% compared to human voice actors. The platform allows users to upload source audio files and text, provide voice samples, and receive processed audio files within one hour. CloneMyVoice offers the ability to create audio presentations, social media content, podcasts, and audio books effortlessly. The AI can generate flawless English voices with British or American accents, capturing the tone and essence of the original voice.
FakeYou
FakeYou is a free online tool that allows you to create realistic text-to-speech audio files. With FakeYou, you can choose from a variety of voices, languages, and accents to create custom audio files that sound like real people. FakeYou is perfect for creating voiceovers for videos, presentations, or other projects.
EZClone
EZClone is a voice cloning service powered by advanced AI technology that allows users to effortlessly clone any voice by uploading an audio file. Users can access a growing library of high-quality voices or create custom voice clones for content creation, storytelling, or personalization. The application offers different pricing plans with varying features and benefits, including audio enhancement, voice cloning, and access to premium voices. Users can easily generate high-quality audio files by selecting a voice, entering text, and clicking to generate the audio. Additionally, EZClone provides technical support based on the user's subscription plan, ensuring a seamless experience for voice synthesis enthusiasts.
Good Tape
Good Tape is a secure transcription service that allows users to upload audio files and receive instant transcriptions. It is designed to be easy to use and provides a number of features to help users get the most out of their transcriptions.
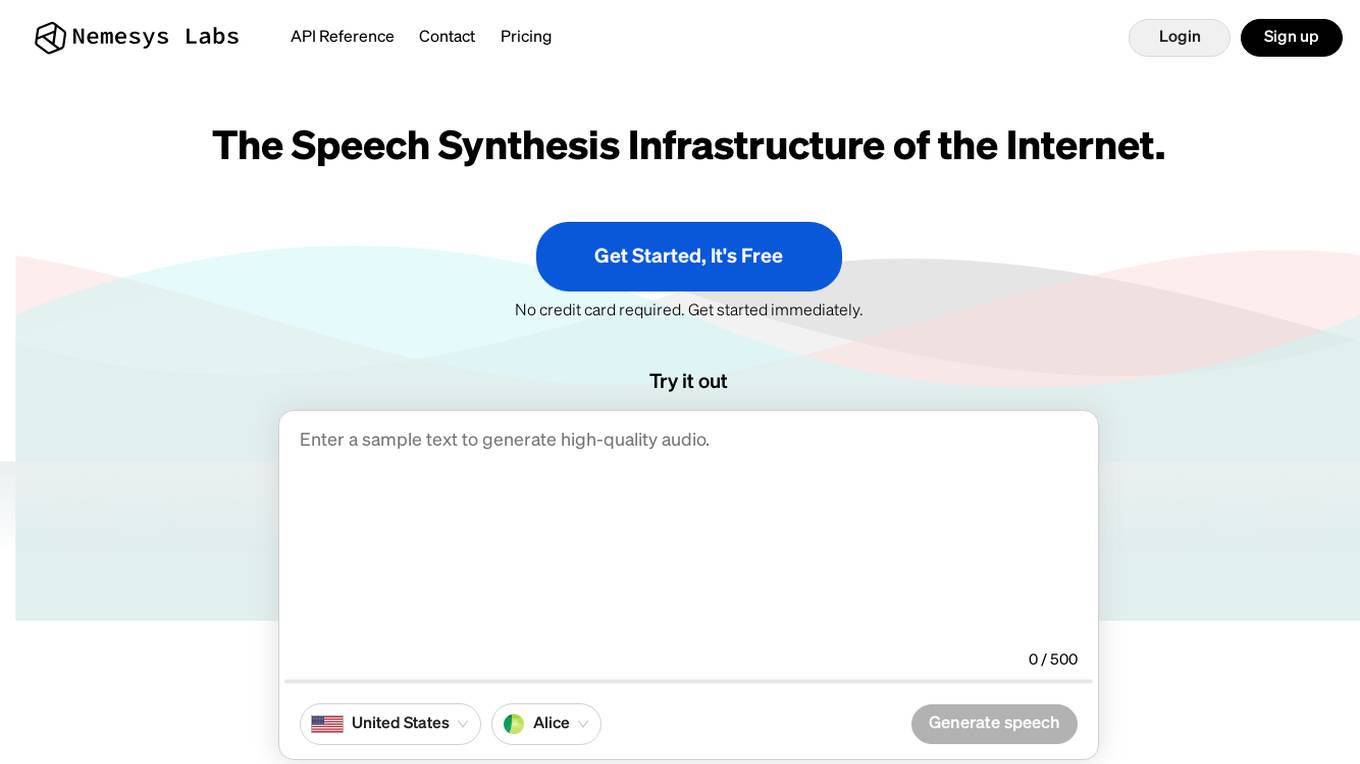
Nemesys Labs
Nemesys Labs is a free AI-powered text-to-speech platform that utilizes artificial intelligence technology to convert written text into spoken words. Users can easily generate high-quality audio files from any text input, making it a valuable tool for content creators, educators, and individuals seeking accessible content. The platform offers a user-friendly interface and a range of customization options to tailor the voice, tone, and speed of the generated speech. Nemesys Labs aims to enhance communication and accessibility by providing a seamless text-to-speech solution for various applications.
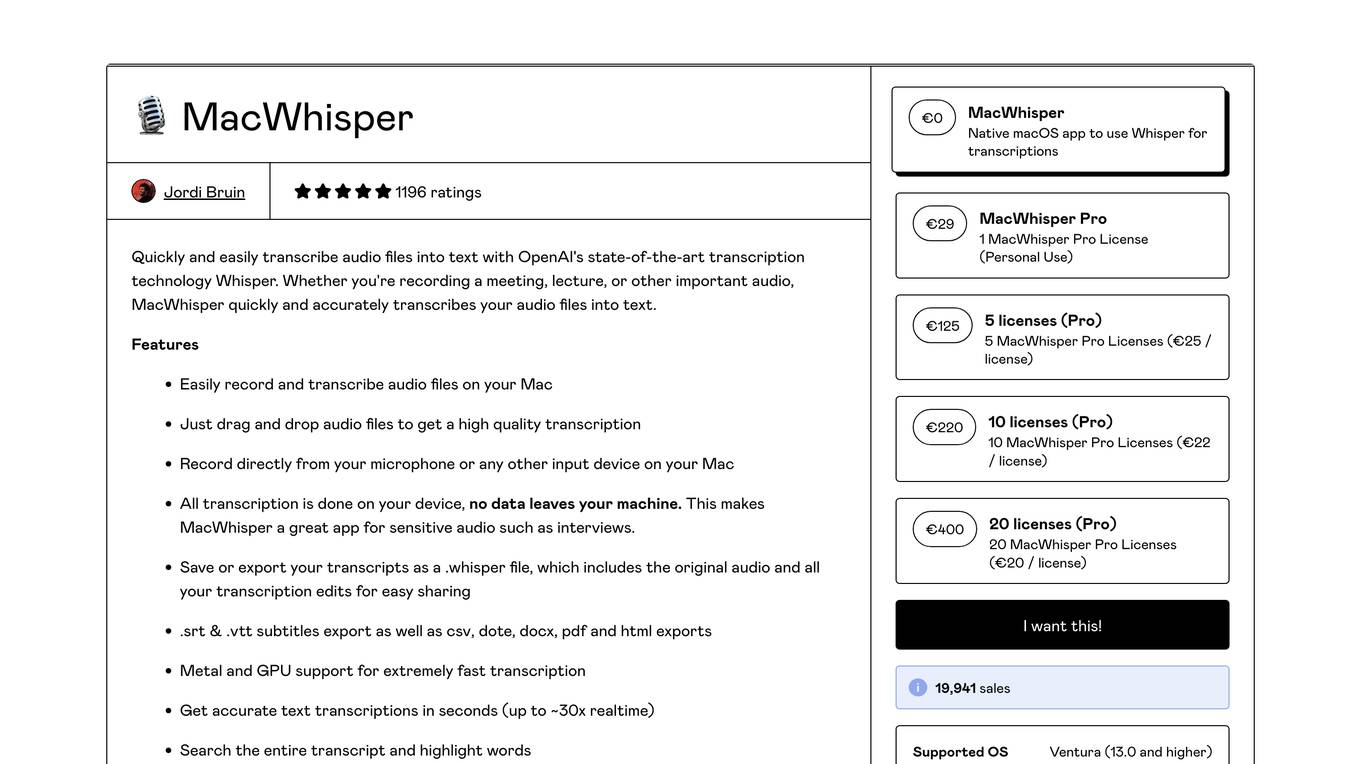
MacWhisper
MacWhisper is a native macOS application that utilizes OpenAI's Whisper technology for transcribing audio files into text. It offers a user-friendly interface for recording, transcribing, and editing audio, making it suitable for various use cases such as transcribing meetings, lectures, interviews, and podcasts. The application is designed to protect user privacy by performing all transcriptions locally on the device, ensuring that no data leaves the user's machine.
SpeechText.AI
SpeechText.AI is a powerful artificial intelligence software for speech to text conversion and audio transcription. It offers accurate transcriptions of audio and video files using domain-specific speech recognition technology. The application provides various features to transcribe, edit, and export audio content in different formats. With state-of-the-art deep neural network models, SpeechText.AI achieves close to human accuracy in converting audio to text. The tool is widely used for transcription of interviews, medical data, conference calls, podcasts, and more, catering to various industries such as finance, healthcare, legal, and HR.
Trint
Trint is an AI transcription software that converts video, audio, and speech to text in over 40 languages with up to 99% accuracy. It allows users to transcribe, translate, edit, and collaborate seamlessly in a single workflow. Trint is trusted by professionals in various industries for its efficiency and accuracy in transcription tasks.
Podcastle
Podcastle is an all-in-one podcasting software that empowers creators of all backgrounds and experience levels with an intuitive, AI-powered platform. It offers a wide range of features, including a recording studio, audio editor, video editor, AI-generated voices, and hosting hub, making it easy to create, edit, and publish high-quality podcasts and videos. Podcastle is designed to be user-friendly and accessible, with no prior experience or technical expertise required.
Free Audio to Text Converter
The Free Audio to Text Converter is an AI-powered tool that allows users to quickly and accurately transcribe audio files into text. It supports various audio formats and offers features like multi-speaker identification, multiple export formats, and precise timestamps. The tool is designed to enhance productivity by providing high-quality transcriptions for a wide range of needs, from content creation to academic research and sales analysis. Users can trust the tool's accuracy and efficiency to save time and improve workflow.
Scribewave
Scribewave is an AI-powered online transcription tool that allows users to automatically transcribe audio and video files into text. It supports over 90 languages and dialects, offers accurate transcription with speaker recognition, and provides features like subtitles generation, audio-to-video conversion, and translations to multiple languages. Scribewave is designed to simplify content conversion, saving users time and enabling them to focus on more critical tasks.
TTSMaker
TTSMaker is a free online text-to-speech tool that allows users to convert text into natural-sounding speech. It supports multiple languages and voices, and the resulting audio files can be downloaded for free and used for commercial purposes. TTSMaker is a valuable tool for creating audiobooks, dubbing videos, and other projects that require high-quality voiceovers.
Free Text to Speech Online Converter Tools
This website provides a free text-to-speech converter tool that utilizes Microsoft's AI speech library to synthesize realistic-sounding speech from text. It offers customizable voice options, fine-tuned speech controls, and multilingual support with over 330 neural network voices across 129 languages. The tool is accessible on various browsers, including Chrome, Firefox, and Edge, and can be used for a range of applications, such as text readers and voice-enabled assistants.
SpeechGen.io
SpeechGen.io is a realistic text-to-speech converter and AI voice generator that allows users to convert text into speech using cutting-edge AI voices with an American English accent. With SpeechGen.io, users can create realistic voiceovers for videos, e-learning materials, advertising, public announcements, podcasts, mobile apps, presentations, and more. The platform offers a wide range of features, including the ability to download converted audio files in MP3, WAV, and OGG formats, support for long texts, commercial use of generated audio, multi-voice editing, custom voice settings, SSML support, and more. SpeechGen.io is accessible in any browser and offers an intuitive interface suitable for beginners. The platform also provides powerful support and is compatible with various editing programs.
AI Writa
AI Writa is an AI-powered writing platform that helps marketers and professionals create unique, engaging marketing material and content. It offers a range of features including document generation, chatbots, transcriptions, and media creation. AI Writa is designed to save time, increase conversions, and boost sales.
Jamorphosia
Jamorphosia is an AI-powered application that allows users to remove instruments from a song. With advanced technology and audio separation capabilities, users can easily extract vocals, isolate specific instruments, and create custom backing tracks. The tool transforms audio files into personalized songs, suitable for practice or performance. Jamorphosia enhances the music experience by providing a platform for musicians to engage with original tracks in a more immersive way.
0 - Open Source AI Tools
20 - OpenAI Gpts
Video Insights: Summaries/Transcription/Vision
Chat with any video or audio. High-quality search, summarization, insights, multi-language transcriptions, and more. We currently support Youtube and files uploaded on our website.
AI Song Idea Generator 🎵✍️
Generate complete song concept, with story, theme, mood, lyrics, key, chords, and instrument suggestions.

Transcript GPT
Give me an audio transcript and I'll give you summarization, insights and actionable plan.
CliniType EHR
Voice-to-text, Vision-to-text transcription, Transcript-to-‘Clinical format’ integrated with CDS. Writes clinical notes, referral letter, generate PDF,prepare discharge summary. (Ultimate aid for clinicians)

SpeechGPT User Guide
A guide for using SpeechGPT, focusing on its features, setup, and usage.
Multilingual Subtitle Assistant
Subtitles in multiple languages with dialect and colloquial options
Lieferkettengesetz Auditor
Compares suppliers' practices with LkSG requirements by BAFA in audit reports
Cyber Audit and Pentest RFP Builder
Generates cybersecurity audit and penetration test specifications.
Technical SEO Audit by MTS
I analyze websites and blog posts for technical SEO compliance and provide detailed reports.
Securia
AI-powered audit ally. Enhance cybersecurity effortlessly with intelligent, automated security analysis. Safe, swift, and smart.
Otto the AuditBot
An expert in audit and compliance, providing precise accounting guidance.