Best AI tools for< Generate Audio Content >
20 - AI tool Sites
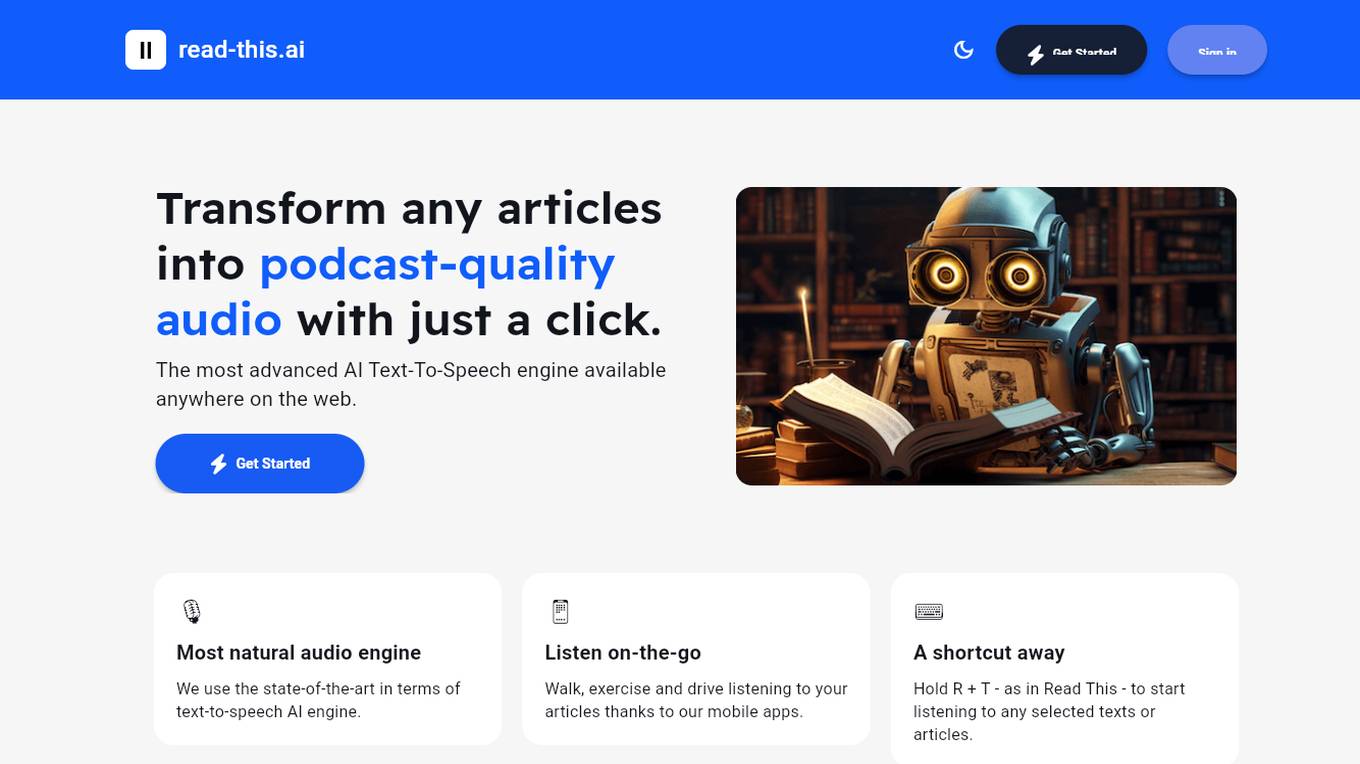
Article to Audio Converter
This AI-powered tool allows you to effortlessly convert written articles into engaging, podcast-quality audio. With just a click, you can transform your content into captivating audio experiences, making it accessible to a wider audience and enhancing its impact.
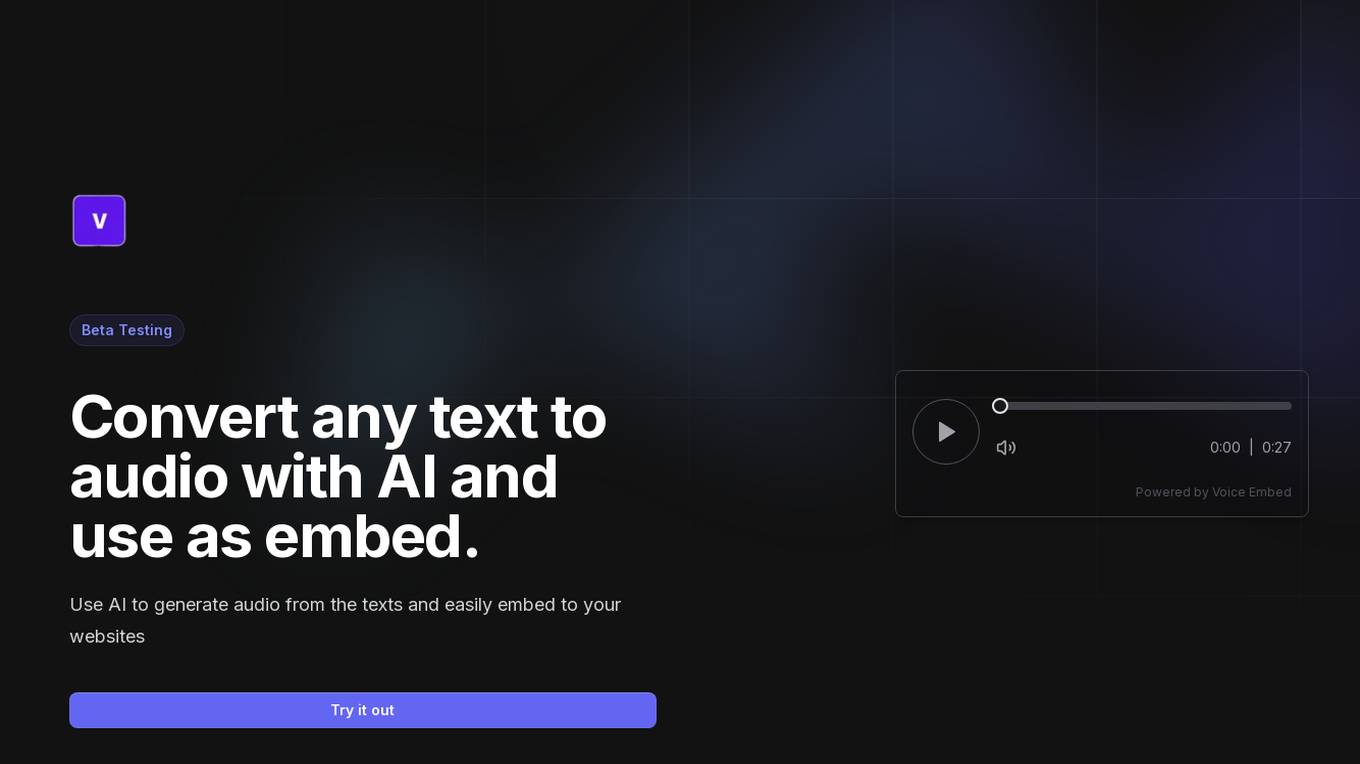
Voice Embed
Voice Embed is an AI tool that allows users to convert any text into audio using AI technology. Users can easily embed the generated audio into their websites, making the content more engaging and interactive. Voice Embed provides a one-click solution to create and share audio from articles, with free cloud storage for all generated audio files. The tool simplifies the process of adding audio to blogs and websites, offering a user-friendly experience for content creators.
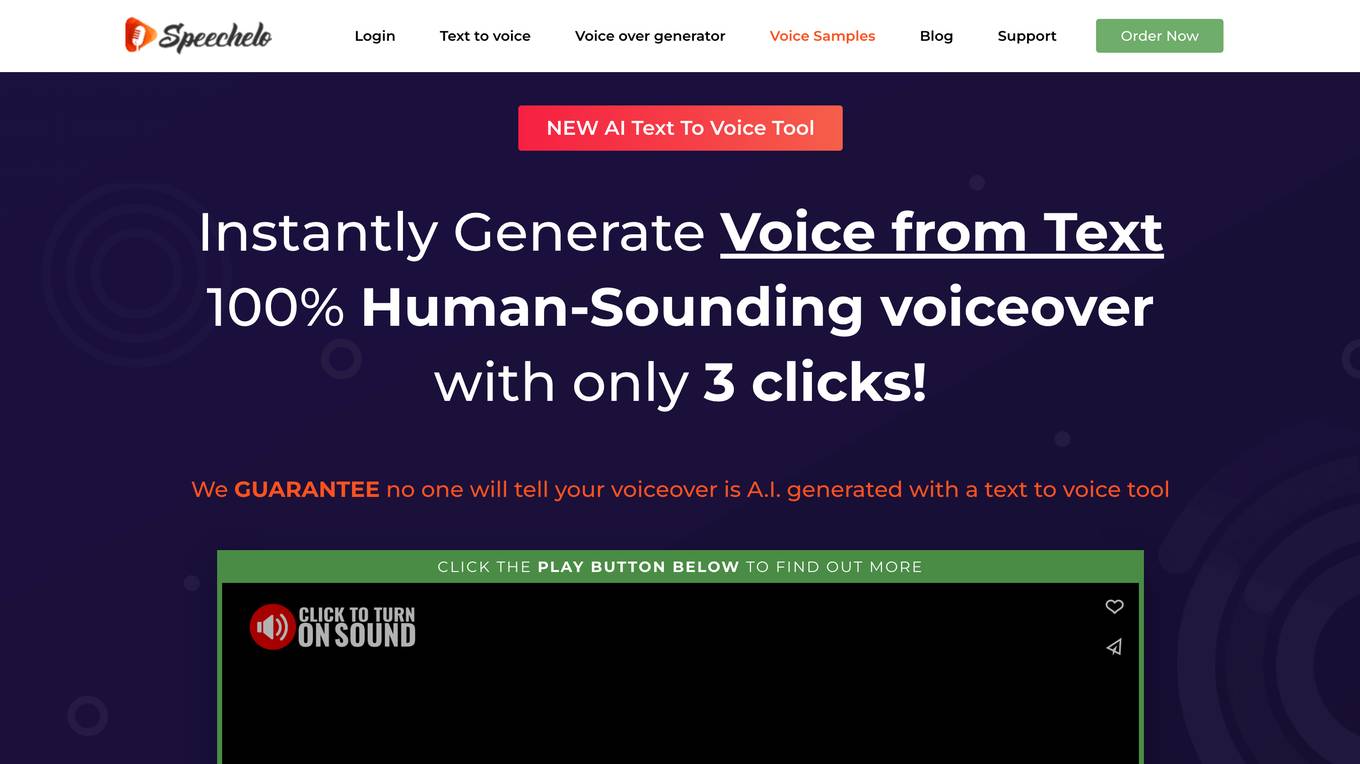
Speechelo
Speechelo is a text-to-speech software that allows users to instantly generate human-sounding voiceovers from text. It offers a wide range of features, including over 30 human-sounding voices, the ability to add breathing sounds and pauses, and the ability to generate voiceovers in over 23 languages. Speechelo is easy to use and can be integrated with any video creation software. It is a great tool for creating voiceovers for sales videos, training videos, educational videos, and more.
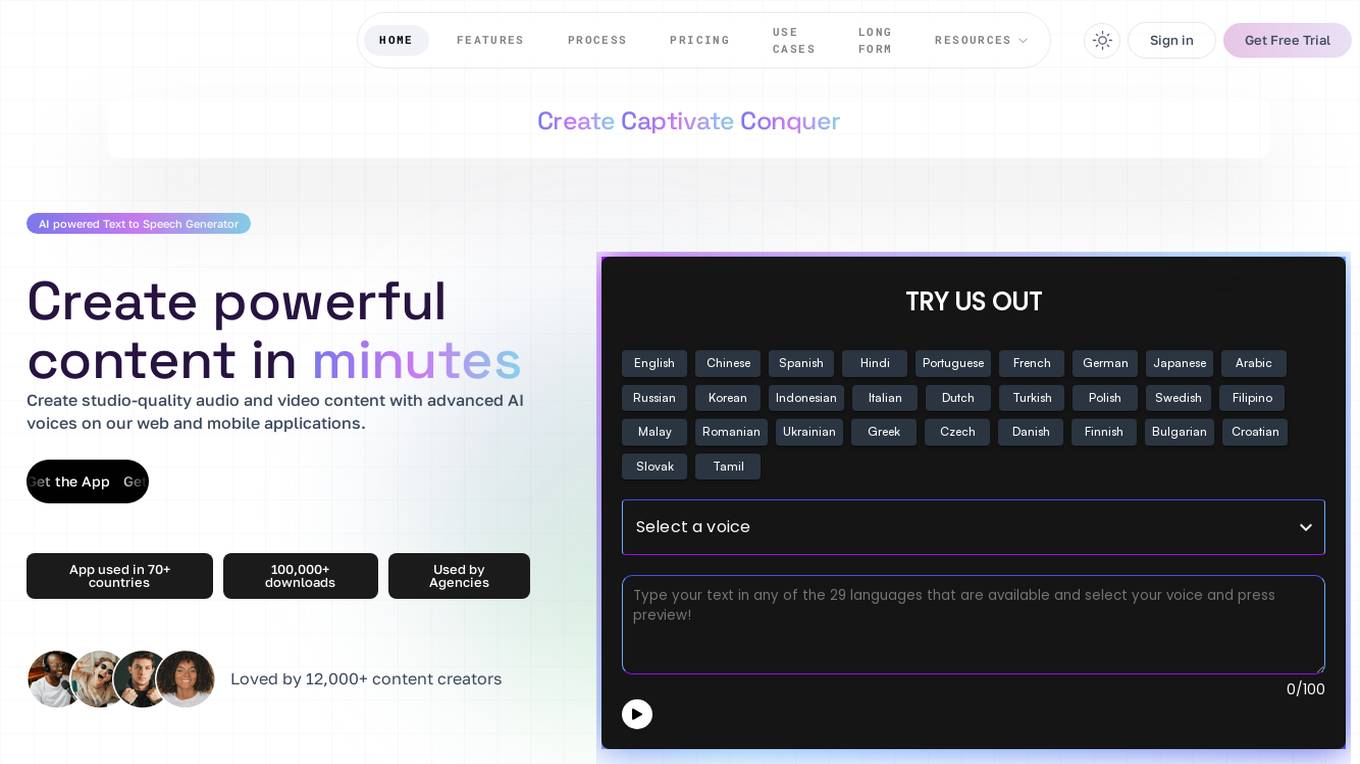
Voice Air
Voice Air is an AI-powered Text to Speech Generator that allows users to create studio-quality audio and video content with advanced AI voices on web and mobile applications. It offers cutting-edge features to enhance content creation, such as human-like voiceovers, award-winning music library, and AI features for content scaling. Voice Air is used in 70+ countries, with 100,000+ downloads and is loved by 12,000+ content creators. The application aims to revolutionize content creation by providing high-quality, natural-sounding voices and innovative features.
Covers AI
Covers AI is a website that provides AI-powered tools for generating voiceovers and songs. With Covers AI, you can create realistic voiceovers and songs from text using advanced AI algorithms. The website is easy to use and offers a variety of features to help you create high-quality audio content.
CloneMyVoice
CloneMyVoice is an AI tool that specializes in creating AI audio voiceovers for long-form content such as podcasts, presentations, and social media. Users can save up to 80% compared to competitors and 99% compared to human voice actors. The platform allows users to upload source audio files and text, provide voice samples, and receive processed audio files within one hour. CloneMyVoice offers the ability to create audio presentations, social media content, podcasts, and audio books effortlessly. The AI can generate flawless English voices with British or American accents, capturing the tone and essence of the original voice.
Free Text to Speech Online Converter Tools
This website provides a free text-to-speech converter tool that utilizes Microsoft's AI speech library to synthesize realistic-sounding speech from text. It offers customizable voice options, fine-tuned speech controls, and multilingual support with over 330 neural network voices across 129 languages. The tool is accessible on various browsers, including Chrome, Firefox, and Edge, and can be used for a range of applications, such as text readers and voice-enabled assistants.
Revoicer
Revoicer is an emotion-based AI text-to-speech generator that provides realistic voiceovers for various purposes. It offers over 80 AI voices in multiple languages, allowing users to customize voice type, pitch, and speed. With its unique emotion engine, Revoicer enables users to add emotions to the AI voice tone, making it suitable for creating engaging content. The web-based app is easy to use, requiring only pasting the text, choosing a voice, and generating the voiceover. Revoicer is a cost-effective alternative to traditional voiceovers, providing scalable and time-saving solutions for marketers, educators, authors, customer support teams, product developers, podcasters, and more.

11Cast
11Cast is an AI-powered podcast generation platform that empowers you to create professional-quality podcasts with just a few clicks. Our advanced AI technology analyzes your text, audio, or video content and automatically generates a polished, engaging podcast that sounds like it was recorded in a professional studio. With 11Cast, you can easily create podcasts for marketing, education, thought leadership, and more.
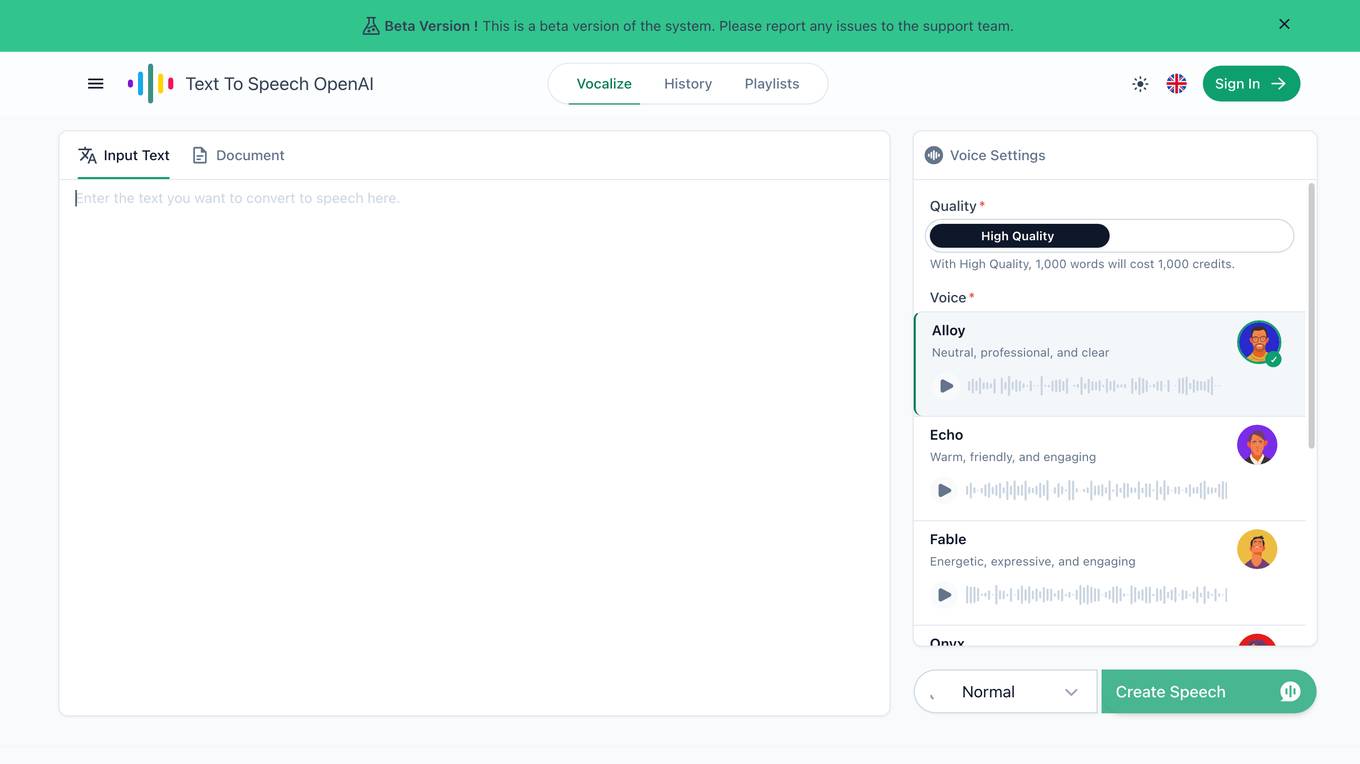
Text-To-Speech OpenAI
Text-To-Speech OpenAI is a professional AI voice generator that allows users to convert text into natural-sounding speech. With advanced AI technology, it offers a wide range of voices, languages, and customization options to create realistic and engaging audio content. Whether you need to create voiceovers for videos, podcasts, e-learning courses, or any other project, Text-To-Speech OpenAI provides a powerful and user-friendly solution.
Create AI Voiceovers
Create AI Voiceovers is an online text-to-speech generator that allows users to convert text into realistic-sounding AI voices. With over 530 AI voices available in 220+ languages and dialects, users can create voiceovers for various purposes, including marketing, eLearning, explainer videos, and animations. The platform offers a range of features, including the ability to adjust voice attributes such as pitch, emphasis, and speed, as well as add background music and sound effects. Create AI Voiceovers also provides a library of pre-recorded sound effects and music that users can incorporate into their voiceovers.

Narration Box
Narration Box is a text-to-speech tool that uses artificial intelligence to generate realistic voiceovers in over 70 languages. It offers a variety of features, including the ability to create multi-speaker content, fine-tune the voice's output, and generate speech in real-time. Narration Box is used by a variety of professionals, including authors, educators, product managers, marketing teams, founders, podcasters, content creators, media houses, and agencies.
Clip.audio
Clip.audio is an AI-powered audio search engine that allows users to search for and discover audio clips from a variety of sources, including podcasts, music, and sound effects. The platform uses advanced machine learning algorithms to analyze and index audio content, making it easy for users to find the specific audio clips they are looking for.
Wan 2.5.AI
Wan 2.5.AI is a revolutionary native multimodal video generation platform that offers synchronized audio-visual generation with cinematic quality output. It features a unified framework for text, image, video, and audio processing, advanced image editing capabilities, and human preference alignment through RLHF. Wan 2.5.AI is designed to transform creative challenges, support AI research and development, enhance interactive education, and facilitate creative prototyping.
Alphy
Alphy is an AI-powered tool that helps users transcribe, summarize, and generate content from audio and video files. It offers a range of features such as high-accuracy transcription, multiple export options, language translation, and the ability to create custom AI agents. Alphy is designed to save users time and effort by automating tasks and providing valuable insights from audio content.

AudioStack
AudioStack is an AI-powered audio production solution that revolutionizes the way companies create professional audio content. It offers cost and time efficiencies by seamlessly integrating AI technology into audio production workflows, enabling users to generate high-quality audio at scale in seconds. With features like text-to-speech conversion, voice cloning, and speech generation, AudioStack empowers users to create studio-quality audio content with ease. The platform caters to various industries, including advertising, media, and content creation, by providing innovative solutions for audio production needs.
Nemesys Labs
Nemesys Labs is a free AI-powered text-to-speech platform that utilizes artificial intelligence technology to convert written text into spoken words. Users can easily generate high-quality audio files from any text input, making it a valuable tool for content creators, educators, and individuals seeking accessible content. The platform offers a user-friendly interface and a range of customization options to tailor the voice, tone, and speed of the generated speech. Nemesys Labs aims to enhance communication and accessibility by providing a seamless text-to-speech solution for various applications.

Wavflow
Wavflow is an AI text-to-speech tool that converts written text into natural-sounding speech. It utilizes advanced artificial intelligence algorithms to generate high-quality audio output, making it ideal for various applications such as creating podcasts, voiceovers, audiobooks, and more. With a user-friendly interface and customizable options, Wavflow offers a seamless experience for users looking to transform text into speech effortlessly.
LimeWire Search
LimeWire Search is an AI-powered platform that offers a range of creative tools for users to generate visual and audio content. Users can create abstract images, convert text to beautiful visuals, edit images, remove backgrounds, outpaint and inpaint images, upscale image quality, and create music from text or images. LimeWire Search aims to empower users with AI technology to unleash their creativity and enhance their content creation process.
GPT4Audio
GPT4Audio is an AI-based desktop application that offers speech-to-text and text-to-speech capabilities. It allows users to transcribe and translate audio files from multiple languages, as well as dictate text and generate audio recordings in real time. The application also includes an Article Wizard feature that can help users create homework essays, marketing content, articles, or blogs quickly and easily.
0 - Open Source AI Tools
20 - OpenAI Gpts
Video Insights: Summaries/Transcription/Vision
Chat with any video or audio. High-quality search, summarization, insights, multi-language transcriptions, and more. We currently support Youtube and files uploaded on our website.
SpeechGPT User Guide
A guide for using SpeechGPT, focusing on its features, setup, and usage.
Multilingual Subtitle Assistant
Subtitles in multiple languages with dialect and colloquial options
Technical SEO Audit by MTS
I analyze websites and blog posts for technical SEO compliance and provide detailed reports.
AI Song Idea Generator 🎵✍️
Generate complete song concept, with story, theme, mood, lyrics, key, chords, and instrument suggestions.

Transcript GPT
Give me an audio transcript and I'll give you summarization, insights and actionable plan.
CliniType EHR
Voice-to-text, Vision-to-text transcription, Transcript-to-‘Clinical format’ integrated with CDS. Writes clinical notes, referral letter, generate PDF,prepare discharge summary. (Ultimate aid for clinicians)

Lieferkettengesetz Auditor
Compares suppliers' practices with LkSG requirements by BAFA in audit reports
Cyber Audit and Pentest RFP Builder
Generates cybersecurity audit and penetration test specifications.
Securia
AI-powered audit ally. Enhance cybersecurity effortlessly with intelligent, automated security analysis. Safe, swift, and smart.
Otto the AuditBot
An expert in audit and compliance, providing precise accounting guidance.