Best AI tools for< Format Json >
20 - AI tool Sites

jsonAI
jsonAI is an AI tool that allows users to easily transform data into structured JSON format. Users can define their schema, add custom prompts, and receive AI-structured JSON responses. The tool enables users to create complex schemas with nested objects, control the response JSON on the fly, and test their JSON data in real-time. jsonAI offers a free trial plan, seamless integration with existing apps, and ensures data security by not storing user data on their servers.
Kiln
Kiln is an AI tool designed for fine-tuning LLM models, generating synthetic data, and facilitating collaboration on datasets. It offers intuitive desktop apps, zero-code fine-tuning for various models, interactive visual tools for data generation, Git-based version control for datasets, and the ability to generate various prompts from data. Kiln supports a wide range of models and providers, provides an open-source library and API, prioritizes privacy, and allows structured data tasks in JSON format. The tool is free to use and focuses on rapid AI prototyping and dataset collaboration.
Monkt
Monkt is a powerful document processing platform that transforms various document formats into AI-ready Markdown or structured JSON. It offers features like instant conversion of PDF, Word, PowerPoint, Excel, CSV, web pages, and raw HTML into clean markdown format optimized for AI/LLM systems. Monkt enables users to create intelligent applications, custom AI chatbots, knowledge bases, and training datasets. It supports batch processing, image understanding, LLM optimization, and API integration for seamless document processing. The platform is designed to handle document transformation at scale, with support for multiple file formats and custom JSON schemas.
AI Bank Statement Converter
The AI Bank Statement Converter is an industry-leading tool designed for accountants and bookkeepers to extract data from financial documents using artificial intelligence technology. It offers features such as automated data extraction, integration with accounting software, enhanced security, streamlined workflow, and multi-format conversion capabilities. The tool revolutionizes financial document processing by providing high-precision data extraction, tailored for accounting businesses, and ensuring data security through bank-level encryption. It also offers Intelligent Document Processing (IDP) using AI and machine learning techniques to process structured, semi-structured, and unstructured documents.
PDFMerse
PDFMerse is an AI-powered data extraction tool that revolutionizes how users handle document data. It allows users to effortlessly extract information from PDFs with precision, saving time and enhancing workflow. With cutting-edge AI technology, PDFMerse automates data extraction, ensures data accuracy, and offers versatile output formats like CSV, JSON, and Excel. The tool is designed to dramatically reduce processing time and operational costs, enabling users to focus on higher-value tasks.
Tablize
Tablize is a powerful data extraction tool that helps you turn unstructured data into structured, tabular format. With Tablize, you can easily extract data from PDFs, images, and websites, and export it to Excel, CSV, or JSON. Tablize uses artificial intelligence to automate the data extraction process, making it fast and easy to get the data you need.

Rocket Statement
Rocket Statement is a leading bank statement conversion tool that helps users convert their PDF bank statements into Excel, CSV, or JSON formats quickly, securely, and easily. It supports over 100 major banks worldwide and can handle multilingual statements. The tool is trusted by professionals worldwide and offers a range of features, including bulk processing, clean data formatting, multiple export options, and an AI Copilot for smooth and flawless conversions.
Tablepad
Tablepad is an AI-powered data analytics tool that allows users to upload, view, and query data effortlessly. With Tablepad, users can generate insights and create charts without the need for coding skills. The tool supports various file formats and offers automated visual insights by generating graphs and charts based on plain English questions. Tablepad simplifies data exploration and visualization, making it easy for users to uncover valuable insights from their data.
Listen411
Listen411 is a podcast transcription and summarization tool that uses AI to quickly and cheaply transcribe audio files. It supports multiple file formats and languages, and offers a pay-as-you-go pricing model. The transcripts are available in multiple file formats, including plain text, SRT, VTT, and JSON.
Vizly
Vizly is an AI-powered data analysis tool that empowers users to make the most of their data. It allows users to chat with their data, visualize insights, and perform complex analysis. Vizly supports various file formats like CSV, Excel, and JSON, making it versatile for different data sources. The tool is free to use for up to 10 messages per month and offers a student discount of 50%. Vizly is suitable for individuals, students, academics, and organizations looking to gain actionable insights from their data.
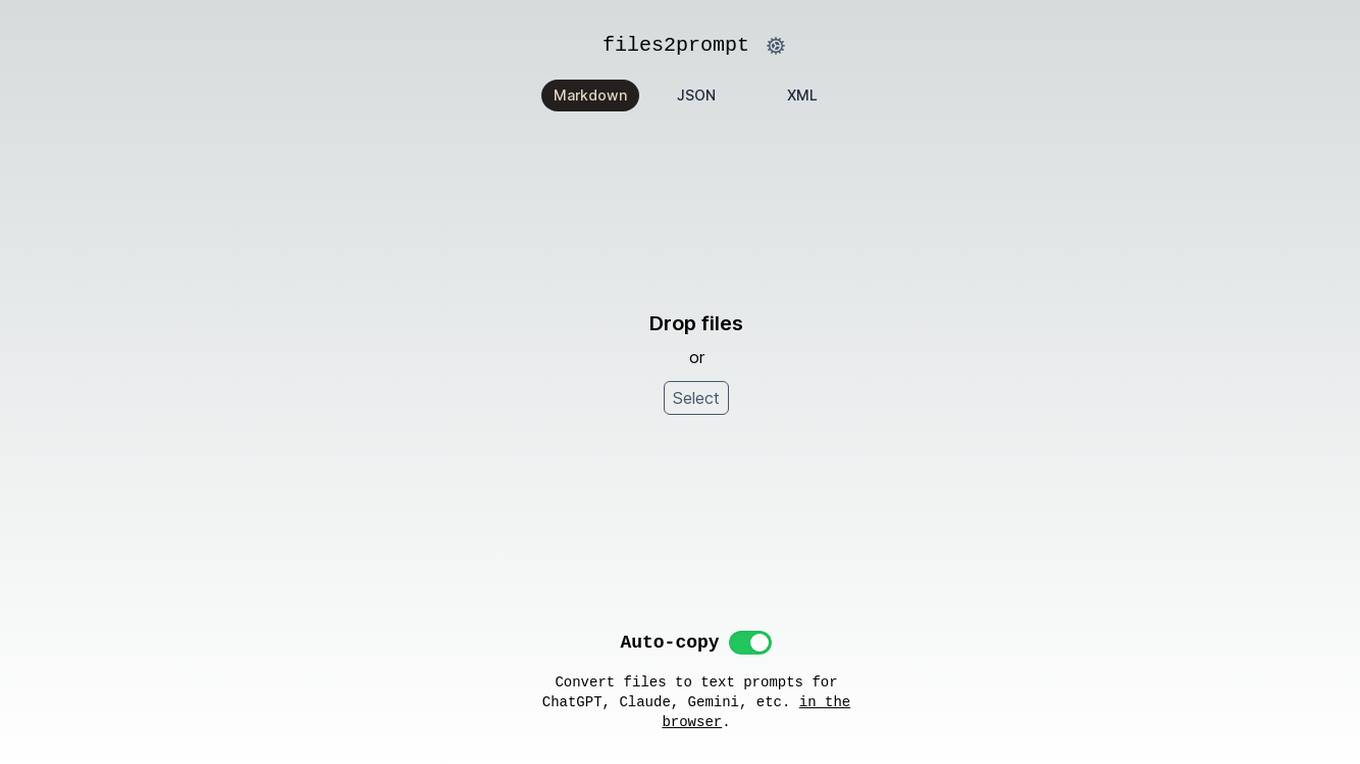
Files2Prompt
Files2Prompt is a free online tool that allows you to convert files to text prompts for large language models (LLMs) like ChatGPT, Claude, and Gemini. With Files2Prompt, you can easily generate prompts from various file formats, including Markdown, JSON, and XML. The converted prompts can be used to ask questions, generate text, translate languages, write different kinds of creative content, and more.
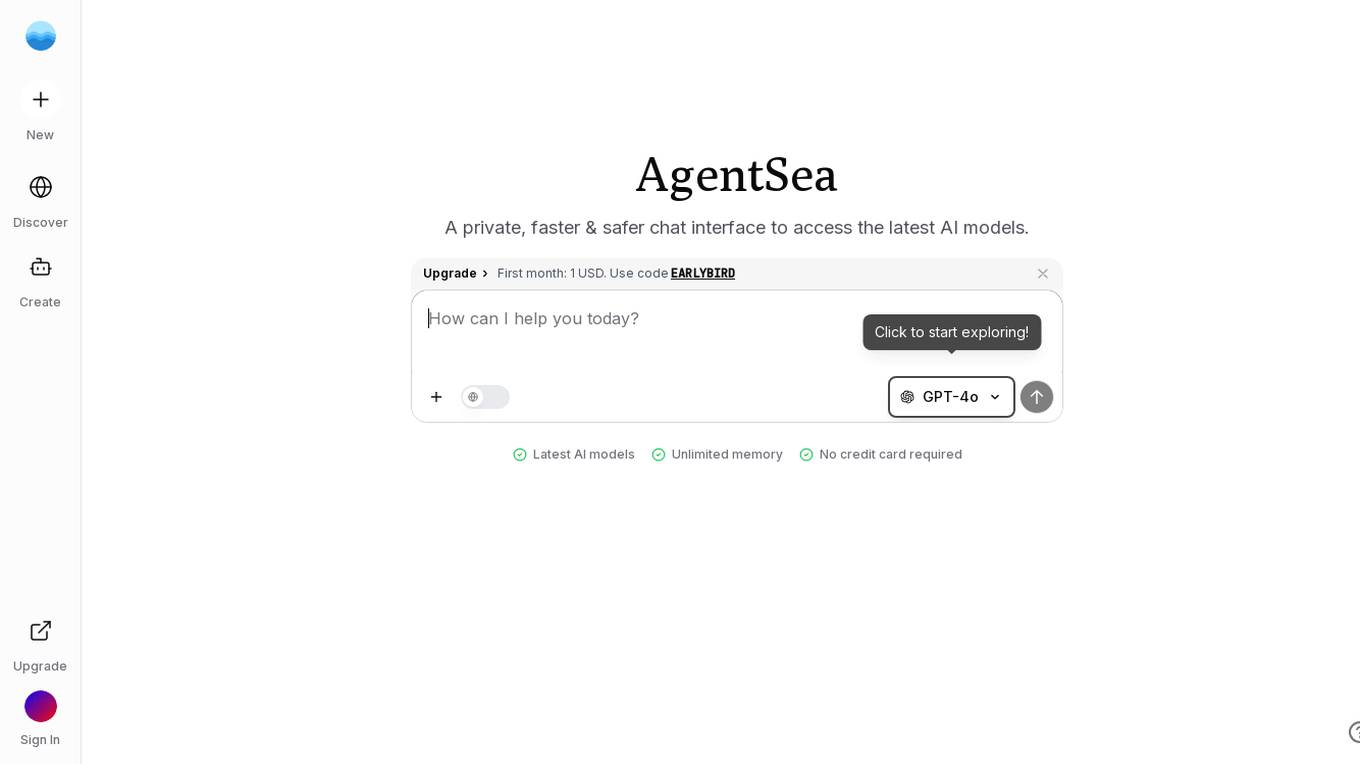
AgentSea
AgentSea is a private AI chat application that provides users with a faster and safer chat interface to access the latest AI models. Users can upload files by dragging and dropping or pasting images from the clipboard. The application supports various file formats such as Images (JPEG, PNG), Documents (PDF, DOCX, DOC, TXT, MD), Spreadsheets (CSV, XLSX, XLS), and JSON files with a maximum size limit of 5MB. AgentSea utilizes the GPT-4o AI model, offering unlimited memory and does not require a credit card for access.
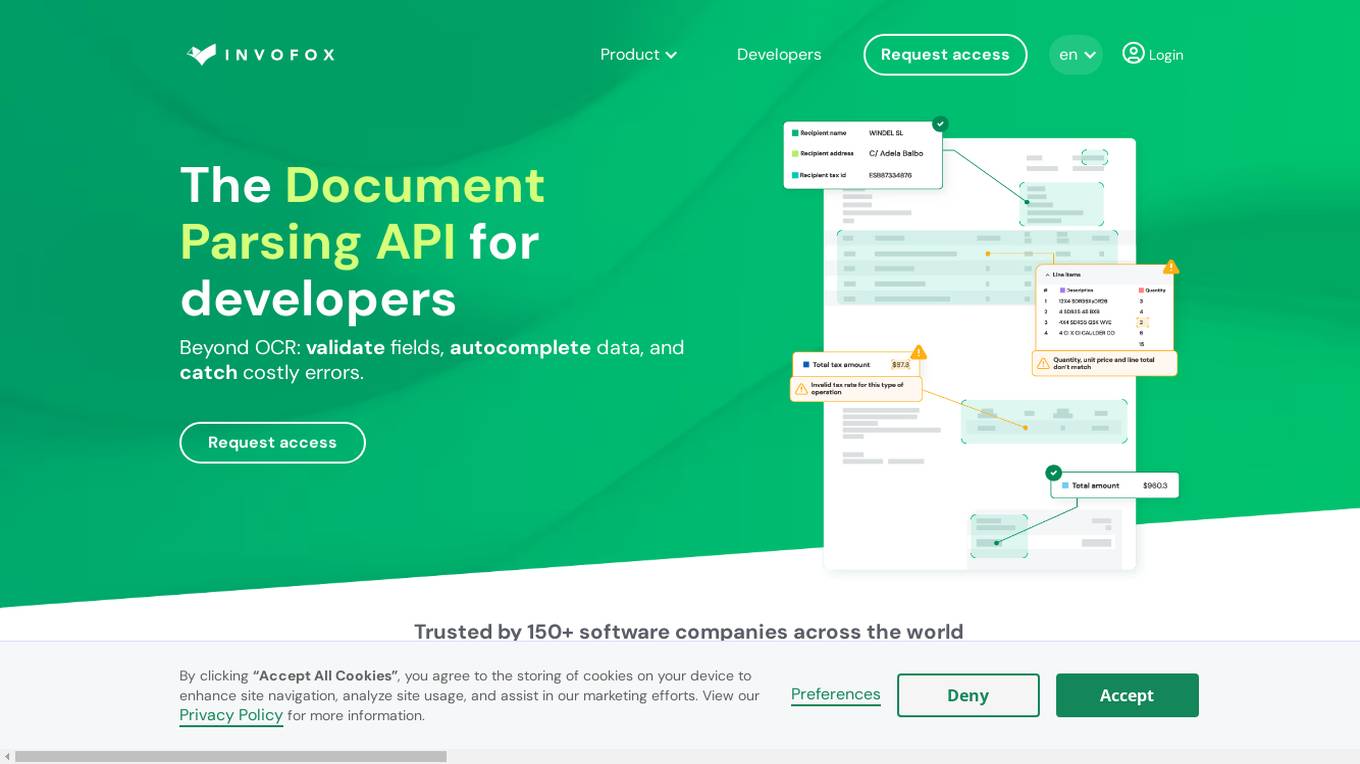
Invofox API
Invofox API is a Document Parsing API designed for developers to validate fields, autocomplete data, and catch errors beyond OCR. It turns unstructured documents into clean JSON using advanced AI models and proprietary algorithms. The API provides built-in schemas for major documents and supports custom formats, allowing users to parse any document with a single API call without templates or post-processing. Invofox is used for expense management, accounts payable, logistics & supply chain, HR automation, sustainability & consumption tracking, and custom document parsing.
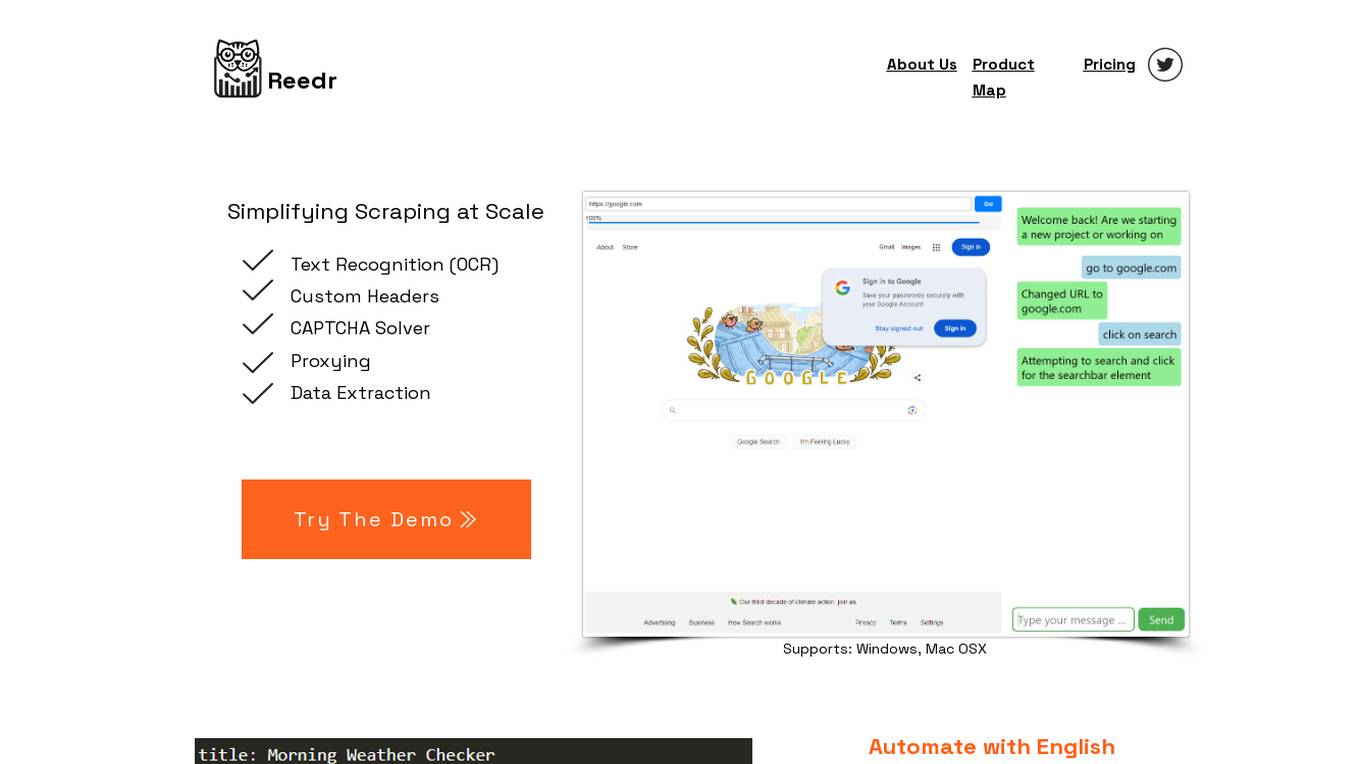
Reedr
Reedr is an AI-powered browser automation tool that simplifies scraping at scale. It offers features such as text recognition (OCR), custom headers, CAPTCHA solver, and proxying for efficient data extraction. With Reedr, users can automate tasks, generate reports, and monitor running tasks in real-time. The tool utilizes AI capabilities to convert visible text and images on web pages into formatted data, supporting various data processing needs. Additionally, Reedr provides customized real-time reporting with API endpoints for different reporting teams, enabling data export in formats like CSV, XLSX, JSON, and YAML. The tool prioritizes industry-leading compliance, adhering to data protection laws and privacy regulations like GDPR.
Multilingual.top
Multilingual.top is an advanced translation platform that enables users to translate text into multiple languages at once. It leverages artificial intelligence, specifically OpenAI's technology, to provide accurate and authentic translations. With Multilingual.top, users can break away from the traditional one-to-one translation limits and get multilingual results in one go, saving time and effort. The platform supports a wide range of languages, including Arabic, Chinese, Danish, Dutch, English, French, German, Indonesian, Italian, Japanese, Korean, Norwegian, Polish, Portuguese, Russian, Spanish, Thai, Turkish, and more. Multilingual.top offers a free translation service with some limits to prevent misuse and ensure everyone has fair access. Users can also upload documents in JSON, PDF, DOCX, and DOC formats for translation, making it especially useful for office workers and professionals dealing with documentation. The platform is continuously updated to improve translation accuracy and target language breadth.
Format Magic
Format Magic is a one-click formatting platform powered by AI that transforms plain text into beautifully formatted documents within seconds. Users can select a template, paste their text, and let the AI automatically apply headings and styles to create professional resumes or documents effortlessly. The platform offers easy-to-use tools for quick and efficient formatting, making it a valuable resource for individuals looking to enhance the visual appeal of their written content.
Resumy
Resumy is an AI-powered resume builder that uses OpenAI's GPT-4 natural language processing model to generate polished and effective resumes. It analyzes a user's work experience, skills, and achievements to create a professional-looking resume in minutes. Resumy also offers proven templates and personalized help from resume writing experts.
AI Image Translator
AI Image Translator is an advanced tool that utilizes AI-powered OCR technology to translate images while retaining original text formats. It supports over 130 languages and offers features such as format preservation, background restoration, multi-language translation, intelligent text placement, and high-quality image export. The tool is ideal for tasks like e-commerce product image translation, app and software screenshot translation, marketing and advertisement translation, technical document translation, and educational content translation.
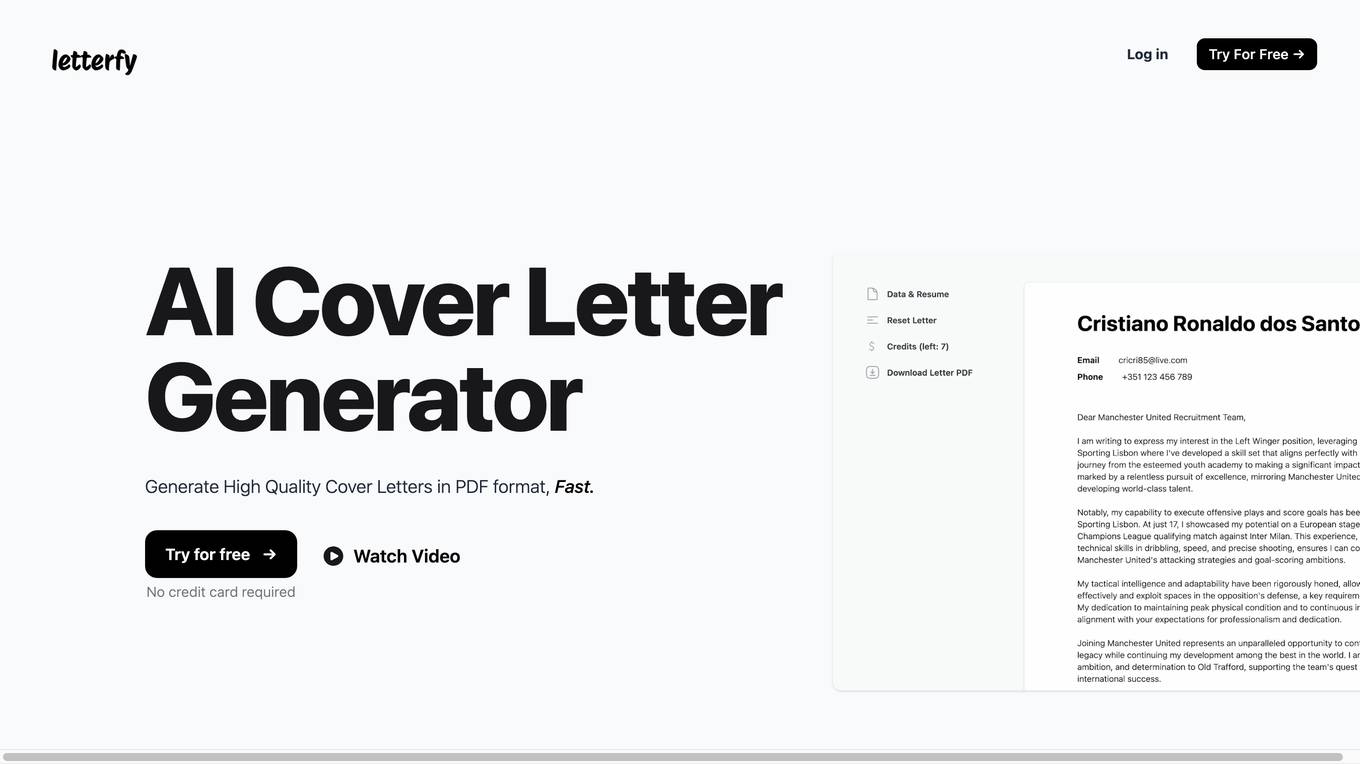
Letterfy
Letterfy is an AI-powered cover letter generator that helps job seekers create high-quality cover letters quickly and easily. With Letterfy, you can generate a professional cover letter in minutes, tailored to the specific job you're applying for. Letterfy's AI technology analyzes your resume and LinkedIn profile to identify your skills and experience, and then generates a cover letter that highlights your most relevant qualifications. You can also customize your cover letter with your own personal touch, and download it in PDF format.
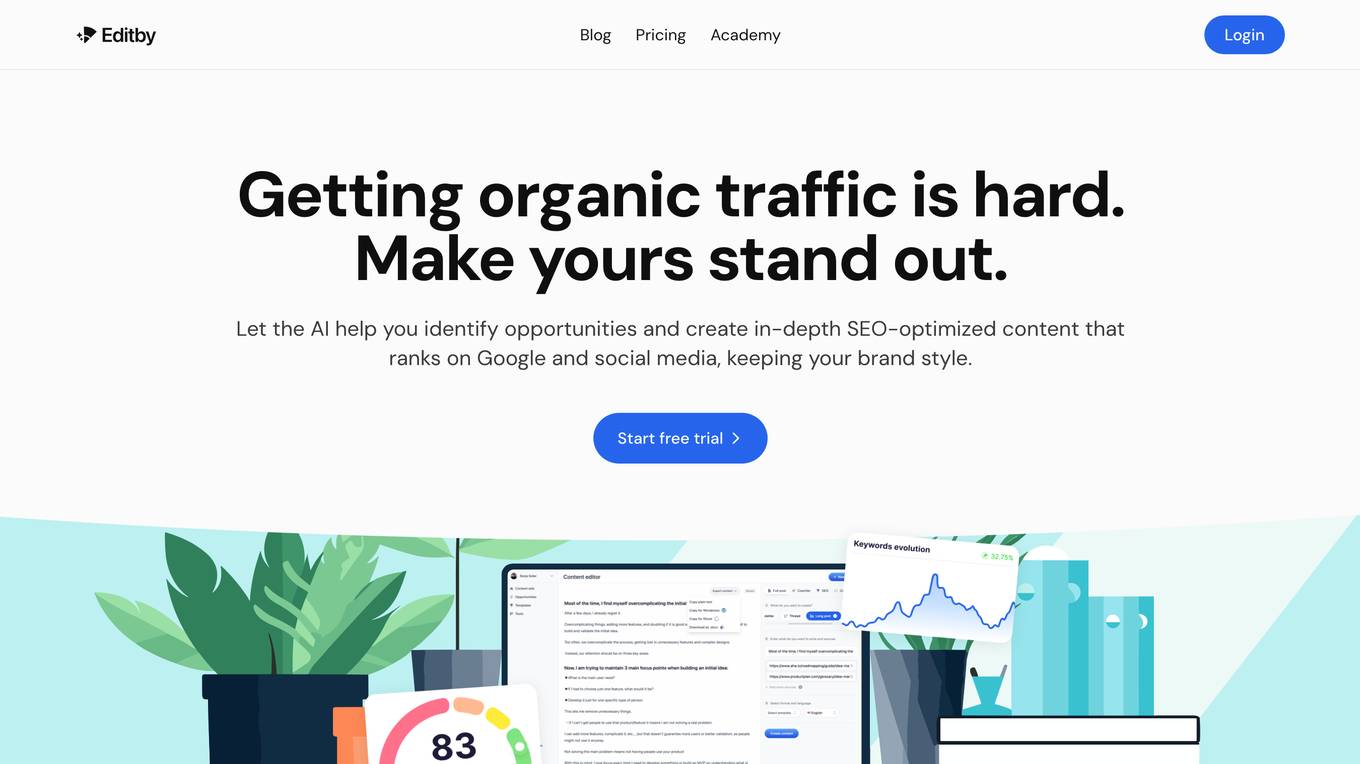
Editby
Editby is an AI-powered content creation tool that helps users create SEO-optimized content that ranks on Google and social media. It offers a range of features to help users create high-quality content, including AI-powered recommendations, trending content suggestions, and plagiarism detection. Editby also integrates with a variety of platforms, making it easy to publish content anywhere you need it.
0 - Open Source AI Tools
20 - OpenAI Gpts


JSON Outputter
Takes all input into consideration and creates a JSON-appropriate response. Also useful for creating templates.

OpenAPI Schema Builder
Assists with OpenAPI Schemas by providing JSON Schema format examples, debugging tips, and best practices.
All Purpose Audio Format Converter
Expert in audio format conversion, guiding through simple steps.
Your Personal Professional Translator
Translator adept at format-preserved translations and cultural nuances.
QuickSilver AI - Natural Language R.A.G DocuMaster
Easily format and optimize your documents, create NLRAG (Natural Language Retrieval Augmented Generation) indexes and more!
