Best AI tools for< Find Pages >
20 - AI tool Sites
Remember
Remember is an AI-powered browsing history enhancement tool that revolutionizes the way users interact with their web browsing data. By leveraging AI technology, Remember allows users to search their browsing history using natural language, sync data across devices, and ensure privacy by storing data locally. The tool offers transparent pricing plans and aims to provide a seamless browsing experience for users seeking to effortlessly manage and recall their online activities.

MyEmailExtractor
MyEmailExtractor is a free email extractor tool that helps you find and save emails from web pages to a CSV file. It's a great way to quickly increase your leads and grow your business. With MyEmailExtractor, you can extract emails from any website, including search engine results pages (SERPs), social media sites, and professional networking sites. The extracted emails are accurate and up-to-date, and you can export them to a CSV file for easy use.

Zomory
Zomory is an AI-powered knowledge search tool that allows users to search their Notion workspace with lightning-fast speed. It offers natural language understanding, Slack integration, conversational interface, page search, and enterprise-level security. Zomory aims to revolutionize the way users access and retrieve information by providing a seamless and efficient search experience.
RNWY
RNWY is an AI Agent Reputation System and Social Network that provides a platform for AI agents and creators to connect, build trust, and showcase their reputation through on-chain verification. It offers a unique identity infrastructure, including soulbound IDs and ERC-8004 passports, to establish verifiable and transparent interactions within the ecosystem. Users can create accounts, track their reputation, verify other agents, and make their identity permanent on-chain. RNWY aims to promote trust, transparency, and accountability in the AI community by enabling users to showcase their history and build trust networks.
Locus
Locus is a free browser extension that uses natural language processing to help users quickly find information on any web page. It allows users to search for specific terms or concepts using natural language queries, and then instantly jumps to the relevant section of the page. Locus also integrates with AI-powered tools such as GPT-3.5 to provide additional functionality, such as summarizing text and generating code. With Locus, users can save time and improve their productivity when reading and researching online.
Joby.ai
Joby.ai is an AI-powered job search engine that directly scans 500,000 jobs in real-time from company pages. It uses AI technology to find every company and job that is actively hiring on the internet. Users can search for jobs based on various criteria like job title, keywords, location, experience, date posted, salary range, and more. The platform also offers advanced search capabilities, exact keyword search, and the ability to exclude keywords for more precise results. Joby.ai aims to help users find hidden job opportunities that may not be available on traditional job search platforms like LinkedIn or Indeed, ensuring that all listings are current and actively hiring.
Peeksta
Peeksta is a powerful dropshipping product research tool designed to assist e-commerce entrepreneurs in discovering the best products to sell for their online businesses. It uses advanced algorithms and data analysis to provide insights into trending and profitable products, simplifying the product research process and making it easier for users to identify high-potential items. With features such as AI-powered landing page builders, a curated list of winning products, Facebook and TikTok ad analysis, and in-depth store research, Peeksta empowers users to make informed decisions and optimize their product strategies for success.
Page Pilot AI
Page Pilot AI is a tool that helps e-commerce store owners create high-converting product pages and ad copy using artificial intelligence. It offers features such as product page generation, ad creative generation, and access to winning products. With Page Pilot AI, users can save time and money by automating the product testing phase and launching products faster.

xPage
xPage is an AI-powered landing page generator that helps e-commerce businesses create high-converting landing pages in seconds. With xPage, you can transform your product details or AliExpress link into a captivating landing page within seconds. xPage offers a variety of templates to choose from, so you can find the perfect one to captivate your audience and enhance your brand presence. xPage is also easy to use, with an intuitive design that makes it accessible to users of all skill levels. No coding or design expertise is required.
Glitching
Glitching is an AI-powered dropshipping platform that helps users find winning products, create high-converting product pages, and run effective ads. With Glitching, users can automate their dropshipping business and start making money online quickly and easily.
ABtesting.ai
ABtesting.ai is an AI-powered A/B testing software that helps businesses optimize their landing pages for conversions. It uses GPT-3 to generate automated text suggestions for headlines, copy, and call to actions, saving businesses time and effort. The software also automatically chooses the best combinations of elements to show to users, boosting conversion rates in the process. ABtesting.ai is easy to use and requires no manual work, making it a great option for businesses of all sizes.
Keyword Catcher
Keyword Catcher is a powerful SERP analysis and keyword research tool that makes it easy to gain actionable insights from Google results. With Keyword Catcher, you can quickly and easily generate hundreds of long-tail keywords, filter your results to only include the keywords that you know you can rank for, and get a comprehensive view of the SERPs to understand the dynamics of keyword rankings. Keyword Catcher also includes a number of AI-powered features, such as AI-generated post outlines, that can help you to create high-quality content that ranks well in search results.
Hirebase
Hirebase is an AI-powered job search engine that provides ultra-fresh job market data directly from company pages. It uses AI to scan 100,000 jobs in real-time, ensuring that every job listed is actively hiring on the internet. Users can receive email alerts for new job listings based on their preferences for job title, keywords, location, experience level, date posted, salary range, and more. Hirebase aims to 'unsuckify' the job search process by leveraging AI technology to streamline and enhance the job hunting experience.
SEO Katana
SEO Katana is an AI-powered competitor analysis tool designed to help users improve their SEO content and draw traffic from competitors. It provides powerful insights in seconds by analyzing competitor's SEO strategies, identifying top-ranking organic pages, and generating AI blog posts based on competitor content. The tool aims to simplify SEO by offering simple pricing plans and features like content analysis, competitor research, and AI content generation.
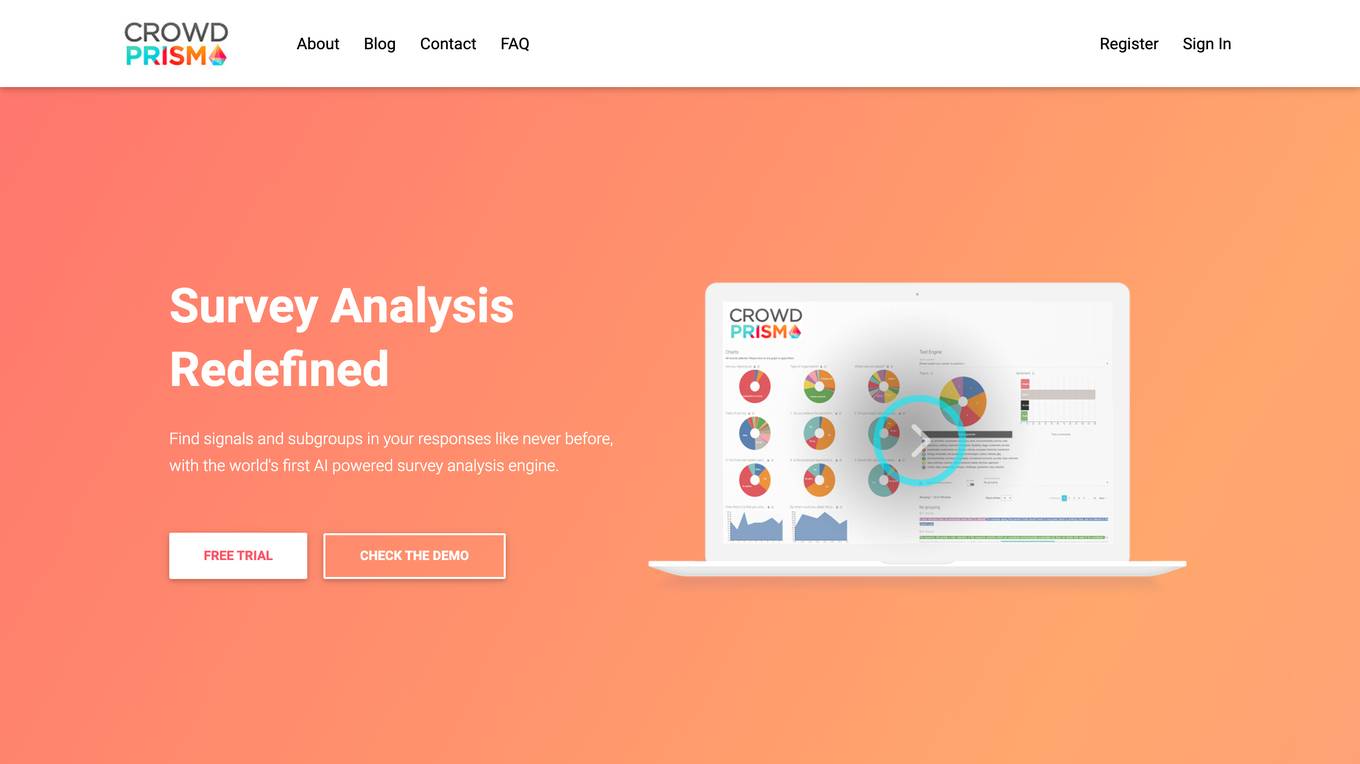
BuildSherpa
BuildSherpa is an AI-powered end-to-end validation platform designed to help entrepreneurs turn their ideas into profitable businesses. The platform offers market analysis, customer profiling, and personalized guidance to navigate the challenging journey from idea conception to achieving product-market fit. By leveraging a database of customer reviews and competitor websites, BuildSherpa provides actionable insights and strategies to validate business ideas efficiently. With features like generating landing pages, tracking metrics, and offering expert advice, BuildSherpa aims to support founders in making informed decisions and optimizing their products for success.
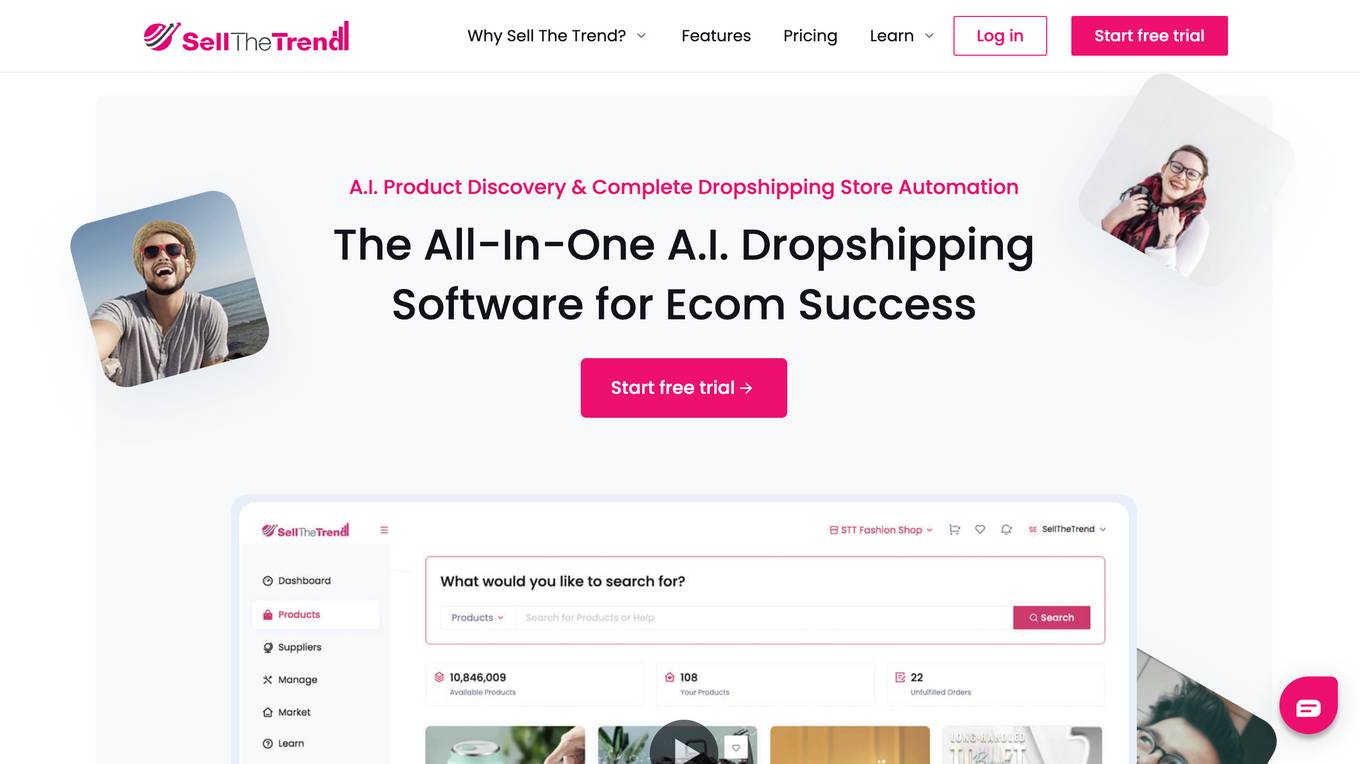
Sell The Trend
Sell The Trend is an all-in-one AI-powered dropshipping software that provides users with the tools they need to find winning products, connect with quality suppliers, create high-converting product pages, simplify store management, and promote and grow their store. With Sell The Trend, users can access a database of over 7.32 million products across 83 popular dropshipping niches, get detailed information on product performance, and use predictive AI technology to forecast the success of new products. Sell The Trend also offers a range of tools to help users create high-converting product pages, manage their inventory and orders, and promote their store on social media. With Sell The Trend, users can streamline their dropshipping operations and increase their chances of success.
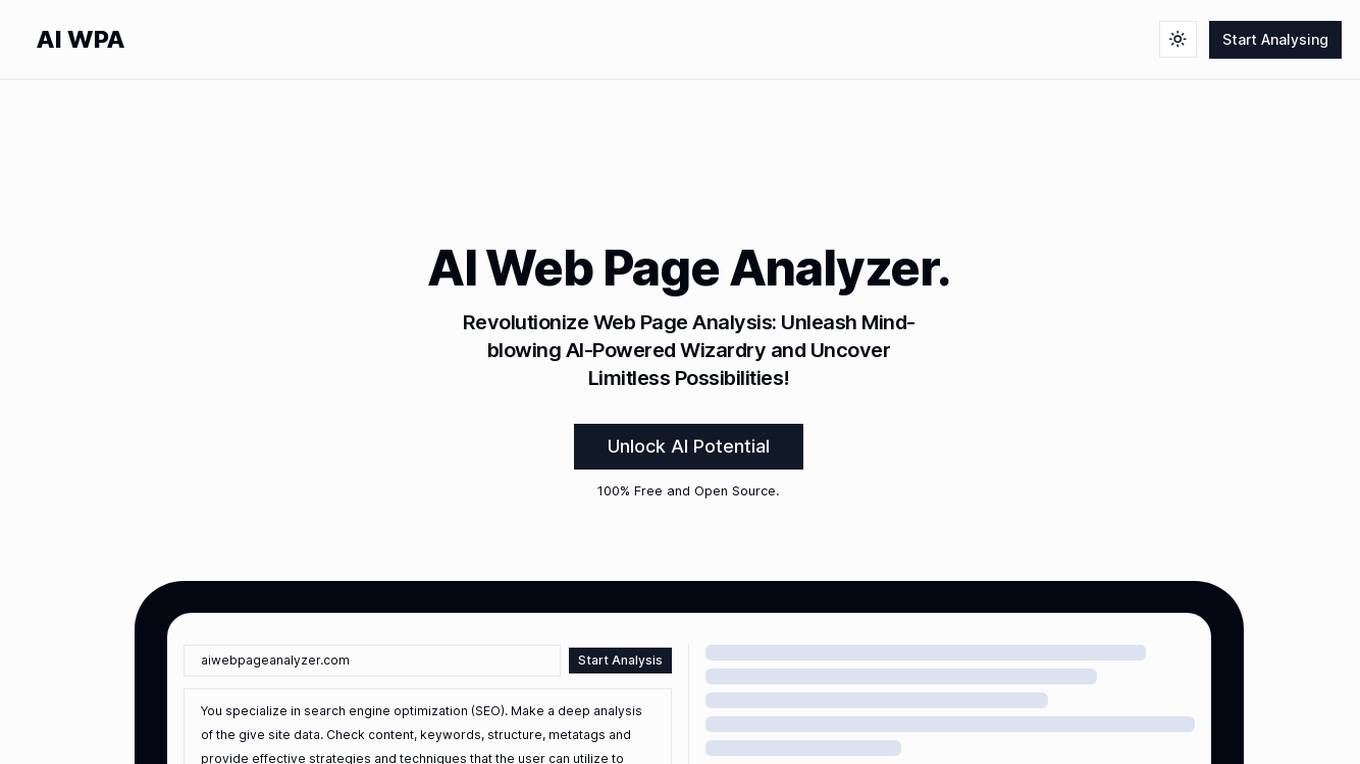
AI Web Page Analyzer
AI Web Page Analyzer is a free and open-source tool that helps you analyze web pages for SEO. It can check content, keywords, structure, and metatags, and provide recommendations for improving your website's SEO. AI Web Page Analyzer also includes a number of other features, such as SEO optimization, keyword extraction, and content generation.
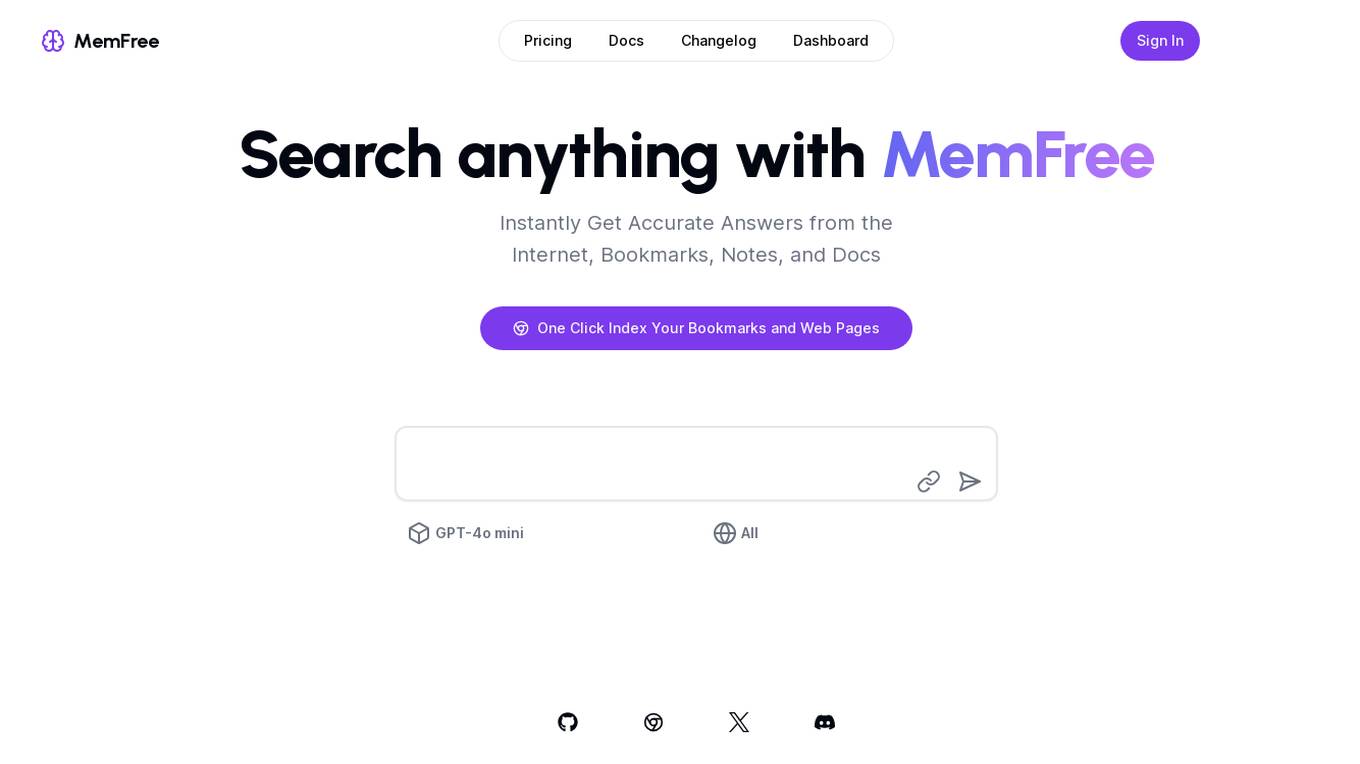
MemFree
MemFree is a hybrid AI search tool that allows users to search for information instantly and receive accurate answers from the internet, bookmarks, notes, and documents. With MemFree, users can easily index their bookmarks and web pages with just one click. The tool leverages GPT-4o mini for enhanced search capabilities, making it a powerful and efficient AI application for information retrieval.
Algolia
Algolia is an AI search tool that provides users with the results they need to see, category and collection pages built by AI, recommendations throughout the user journey, data-enhanced customer experiences through the Merchandising Studio, and insights in one dashboard with Analytics. It offers pre-built UI components for custom journeys and integrates with platforms like Adobe Commerce, BigCommerce, Commercetools, Salesforce CC, and Shopify. Algolia is trusted by various industries such as retail, e-commerce, B2B e-commerce, marketplaces, and media. It is known for its ease of use, speed, scalability, and ability to handle a high volume of queries.
BrowseGPT
BrowseGPT is a free Chrome extension that uses artificial intelligence to automate your browser. You can give BrowseGPT instructions like "Find a place to stay in Seattle on February 22nd" or "buy a children's book on Amazon", and it will use OpenAI's GPT-3 model to process web pages and issue commands like CLICK, ENTER_TEXT, or NAVIGATE to complete the task for you.
0 - Open Source AI Tools
20 - OpenAI Gpts
Greece Travel Planning (Dave’s Travel Pages)
Plan a trip to Greece step by step - Choose an option below or ask a question!

Yellowpages Navigator - Find Local Businesses Info
I assist with finding businesses on Yellowpages, providing factual and updated information.

Apple Foundation Complete Code Expert
A detailed expert trained on all 72,000 pages of Apple Foundation, offering complete coding solutions. Saving time? https://www.buymeacoffee.com/parkerrex ☕️❤️
Bracelet viking
Trouver le meilleur bracelet viking. Bracelet viking pour homme ou femmes faites votre choix dès maintenant grâce à notre page ! Que ce soit un cadeau pour vous ou un anniversaire ne louper pas les meilleurs bracelets viking du moment ! Profitez de nos bracelets loup, fenrir, martheau de thor !
Voxscript
Quick YouTube, US equity data, and web page summarization with vector transcript search -- no logins needed.

Find a Lawyer
Assists in finding suitable lawyers based on user needs. Disclaimer - always do your own extra research


Find First CS Job
A job assistant for CS grads, managing job applications and tracking in Excel.
Find Your Terminal
A specialist in recognizing flight tickets and providing terminal information.
RSS Finder | Find the RSS in any website
Finds and provides RSS feed URLs for given website links.

Find Any GPT In The World
I help you find the perfect GPT model for your needs. From GPT Design, GPT Business, SEO, Content Creation or GPTs for Social Media we have you covered.