Best AI tools for< Find Libraries >
20 - AI tool Sites
Trendshift
The website Trendshift is an AI tool that analyzes activity across a curated collection of open-source repositories to surface relevant, rising projects. It provides an alternative to GitHub Trending, using a consistent scoring algorithm informed by daily engagement metrics. Users can explore GitHub Trending Stats, repositories with rising engagement, and discover new projects. Trendshift offers a platform for developers to stay updated on the latest open-source projects and trends in the software development community.
Fork.ai
Fork.ai is a tool that helps businesses identify technologies used in mobile apps. With Fork.ai, businesses can gain insights into their competitors' tech stacks, identify potential partners, and generate leads. Fork.ai's key features include: - Technology identification: Fork.ai can identify over 1,000 technologies used in mobile apps, including programming languages, frameworks, libraries, and SDKs. - Competitor analysis: Fork.ai provides insights into the technologies used by your competitors, allowing you to identify areas where you can gain a competitive advantage. - Lead generation: Fork.ai can help you generate leads by identifying potential customers who are using specific technologies. - Partnership discovery: Fork.ai can help you identify potential partners who are using complementary technologies.
Intel Gaudi AI Accelerator Developer
The Intel Gaudi AI accelerator developer website provides resources, guidance, tools, and support for building, migrating, and optimizing AI models. It offers software, model references, libraries, containers, and tools for training and deploying Generative AI and Large Language Models. The site focuses on the Intel Gaudi accelerators, including tutorials, documentation, and support for developers to enhance AI model performance.
UpCodes
UpCodes is a searchable platform that provides access to building codes, assemblies, and building products libraries. It offers a comprehensive database of regulations and standards for construction projects, enabling users to easily search and reference relevant information. With UpCodes, architects, engineers, contractors, and other industry professionals can streamline their workflow, ensure compliance with codes, and enhance the quality of their designs. The platform is designed to simplify the process of accessing and interpreting building codes, saving time and reducing errors in construction projects.
The Librarian
The Librarian is an AI personal assistant application designed to supercharge your day by helping you manage your schedule, emails, and documents efficiently. It offers features such as effortless email drafting, smart scheduling, document retrieval, and integration with various tools like Gmail and Google Drive. The application prioritizes user privacy and security, with data encryption and strict privacy governance. The Librarian aims to unlock greater productivity for busy professionals, allowing them to focus on what truly matters.
Find your next book
Find your next book is an AI-powered librarian that provides personalized book recommendations based on your preferences. It uses advanced algorithms to analyze your reading history, interests, and other factors to suggest books that you're likely to enjoy. The platform offers a wide range of genres and authors to choose from, making it easy to find your next favorite read.
AI Bookstore
AI Bookstore is a website that uses AI to help users find books that they want to read. Users can ask the AI questions about what they are looking for, and the AI will recommend books that match their criteria. The AI can also generate personalized recommendations based on a user's reading history.
Connected Papers
Connected Papers is a search engine for academic papers that uses artificial intelligence to help users find and explore relevant research. It allows users to search for papers by keyword, author, or title, and then explore the connections between them. Connected Papers also provides a variety of tools to help users organize and manage their research, including the ability to create custom collections of papers, add notes and annotations, and share their research with others.
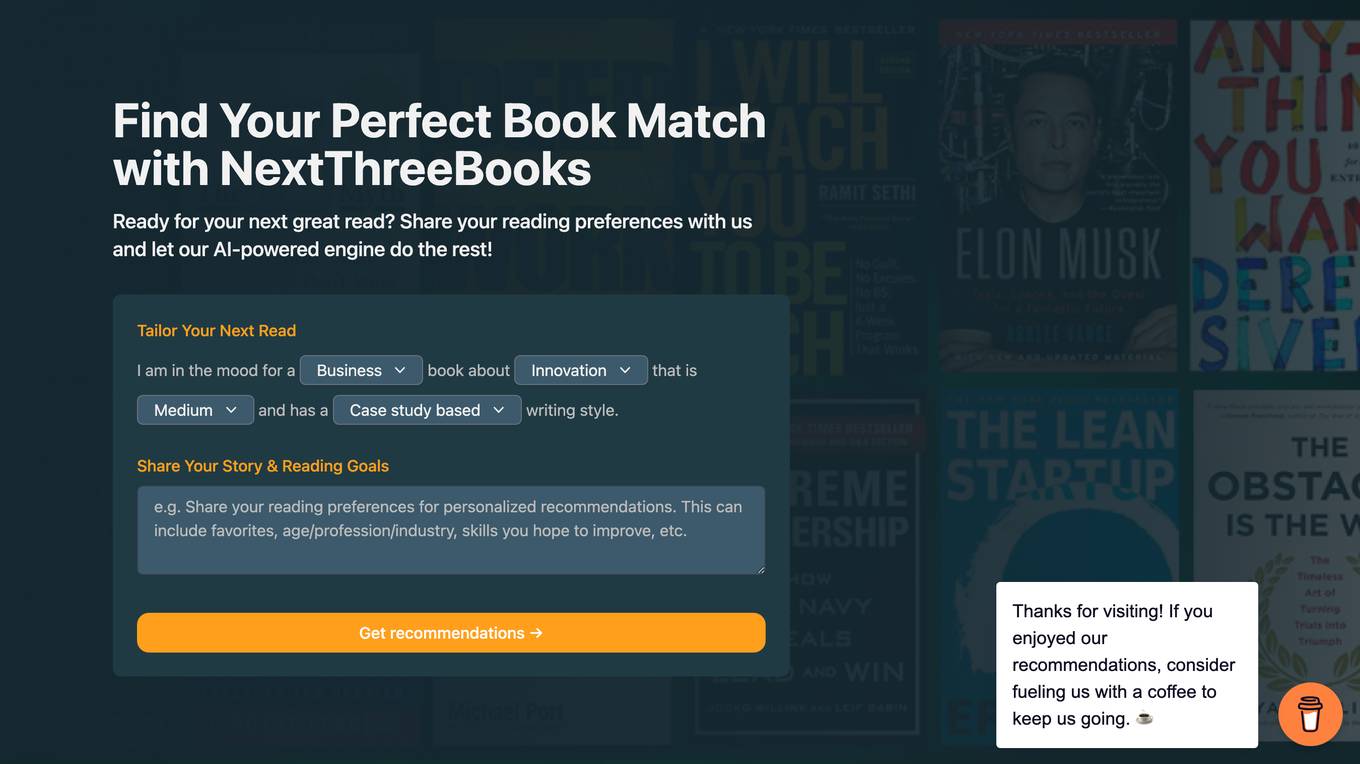
NextThreeBooks.com
NextThreeBooks.com is an AI-powered book recommendation service that provides personalized suggestions based on your reading preferences. Share your preferences, tell us about yourself, and receive three carefully curated book suggestions with detailed explanations. We use GPT-3 to provide personalized book suggestions tailored to your reading preferences. Find your next favorite read with ease!
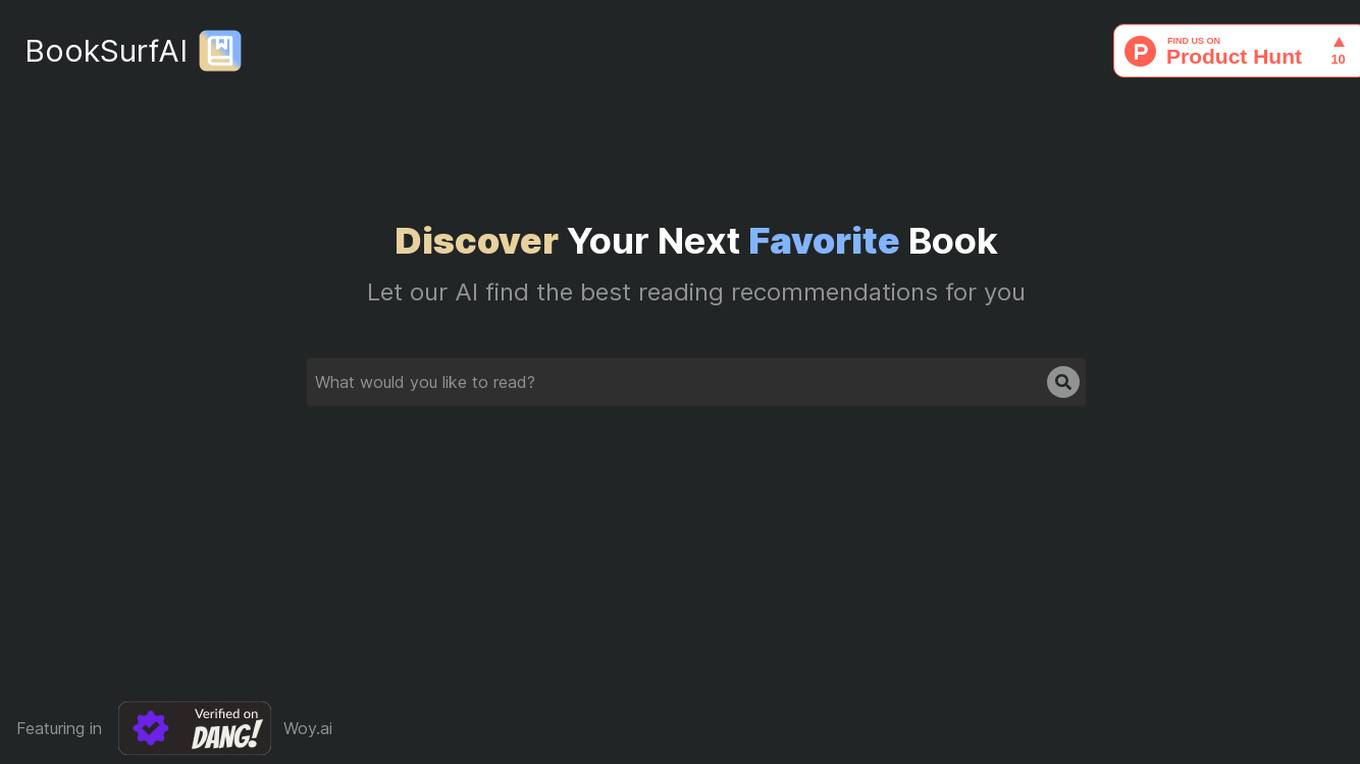
BookSurfAi
BookSurfAi is an AI-powered book recommendation tool that helps users discover their next favorite book. By leveraging artificial intelligence technology, the application provides personalized reading suggestions based on individual preferences and reading habits. BookSurfAi aims to enhance the reading experience by offering tailored recommendations that cater to each user's unique tastes and interests. With a user-friendly interface, BookSurfAi makes it easy for book lovers to explore new literary works and expand their reading horizons.

BooksAI
BooksAI is an AI-powered tool that provides book summaries, recommendations, and more. With over 40 million book summaries available, BooksAI makes it easy to discover new books and learn about your favorites. BooksAI's summaries are concise and easy to understand, making them perfect for busy professionals, students, and anyone who wants to learn more about the world's greatest books.

BookAbout
BookAbout is an AI-powered application that helps users discover their next favorite book. By leveraging artificial intelligence technology, BookAbout provides personalized book recommendations based on users' preferences and reading history. Users can be as specific as they like in their search for a new book, ensuring that they find the perfect read every time. As an Amazon Associate, BookAbout may earn a commission from qualifying purchases made through Amazon store links.
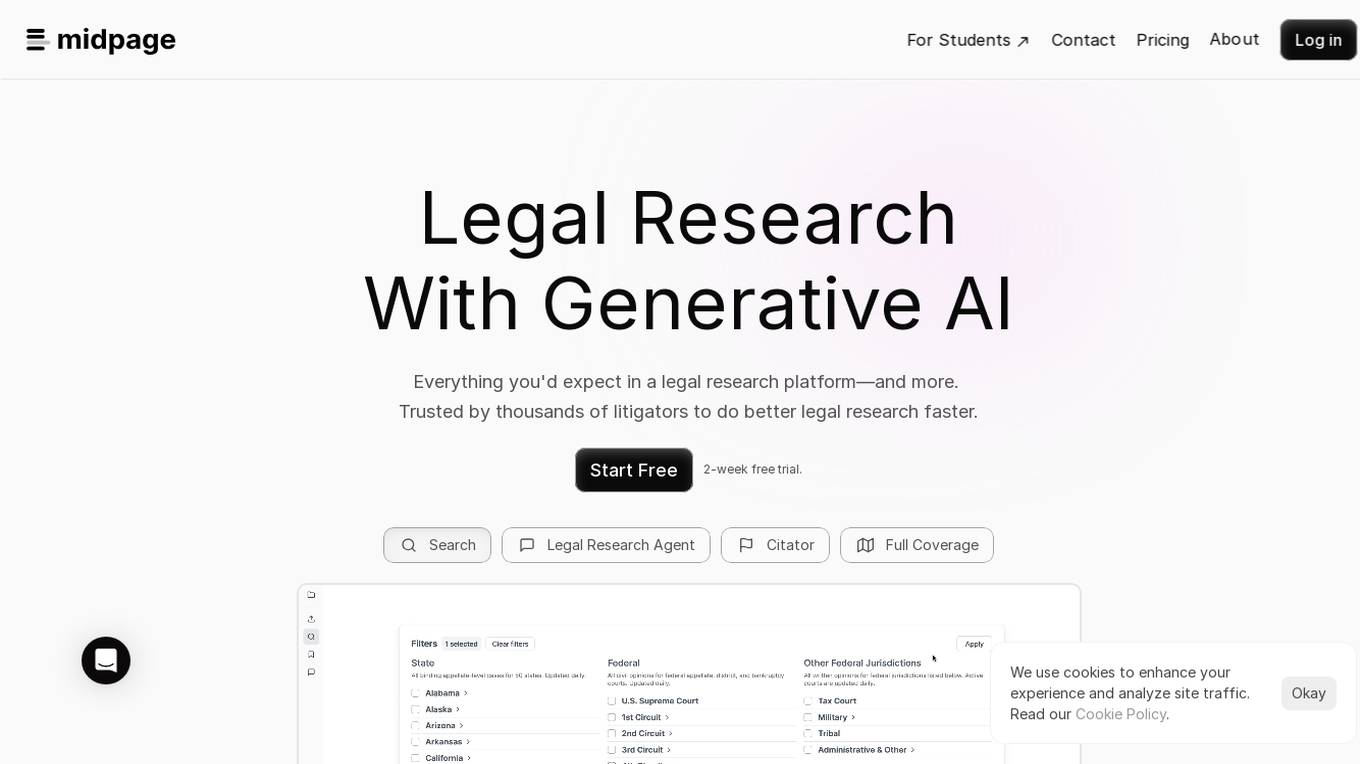
Midpage
Midpage is a legal research platform powered by Generative AI, designed to provide comprehensive legal research capabilities to students and professionals. The platform offers advanced features such as grid-based search, case filtering with AI, proactive annotations, and seamless integration of research into documents. Midpage aims to streamline the legal research process by leveraging AI technology to enhance efficiency and accuracy in analyzing legal cases and statutes.
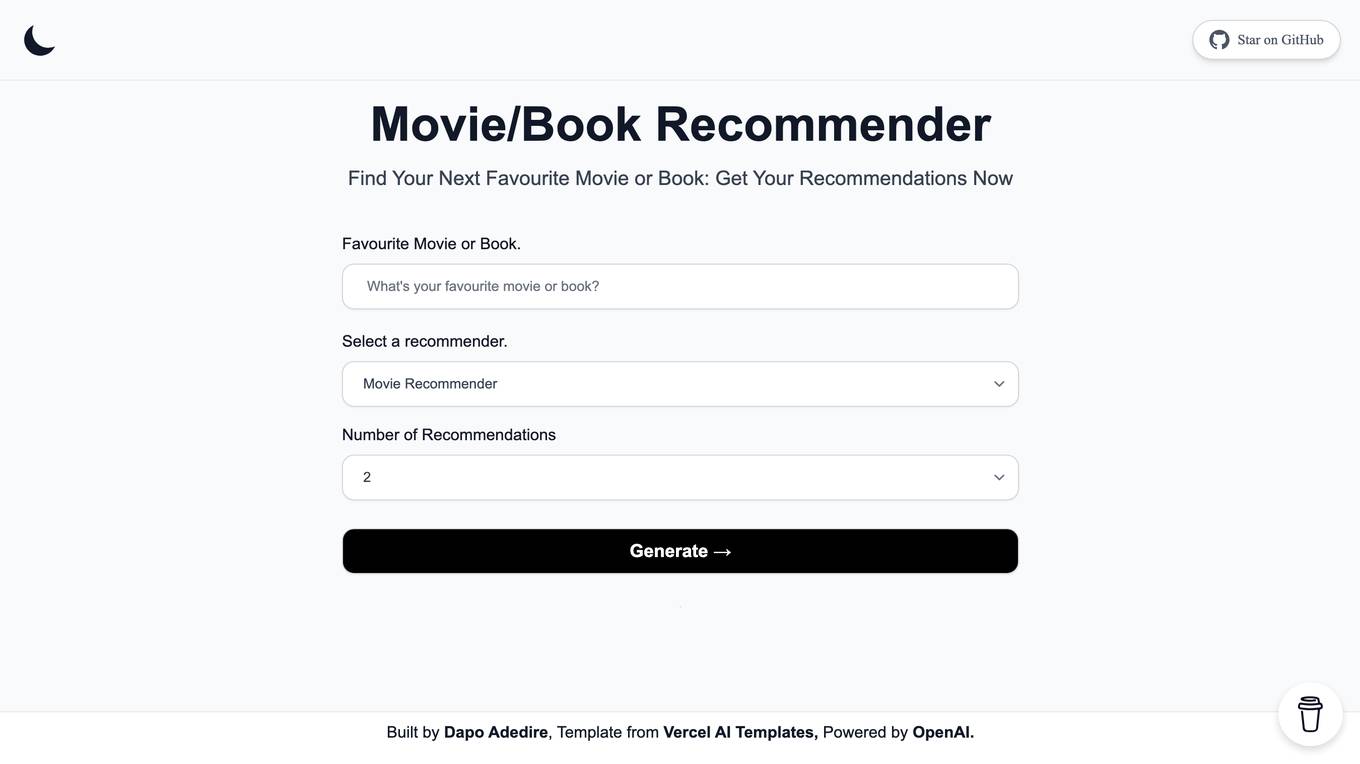
Create Next App
The website 'Create Next App' is a platform that provides personalized recommendations for books and movies based on the user's preferences. Users can input their favorite books, and the platform will suggest similar ones to explore. It aims to help users discover new content that aligns with their interests in an easy and convenient way.
Open Knowledge Maps
Open Knowledge Maps is the world's largest AI-based search engine for scientific knowledge. It aims to revolutionize discovery by increasing the visibility of research findings for science and society. The platform is open and nonprofit, based on the principles of open science, with a mission to create an inclusive, sustainable, and equitable infrastructure for all users. Users can map research topics with AI, find documents, and identify concepts to enhance their literature search experience.
Read This Twice
Read This Twice is an AI-driven book recommendation platform that helps users discover books worth reading twice. The platform offers a curated selection of book recommendations from renowned personalities like Barack Obama, Bill Gates, Oprah Winfrey, Elon Musk, and more. Each recommendation is thoroughly verified for authenticity and includes a direct link to the source. Users can explore various reading lists, including recommendations from popular figures and updated lists on different genres. The platform's AI assistant, 'Sona,' provides personalized book suggestions based on user preferences, ensuring a seamless and tailored book-finding experience.
NextThreeBooks
NextThreeBooks.com is an AI-powered book recommendation platform that helps users find their perfect book match based on their reading preferences. Users can share their reading preferences with the AI-powered engine, which then provides personalized book suggestions tailored to their preferences. The platform uses GPT-3 to offer three carefully curated book recommendations with detailed explanations, making it easier for users to discover their next favorite read. NextThreeBooks.com has recommended books to users in over 80 countries and has been featured in various newsletters, building a growing community of readers.
arXiv
arXiv.org is a free distribution service and an open-access archive for nearly 2.4 million scholarly articles in the fields of physics, mathematics, computer science, quantitative biology, quantitative finance, statistics, electrical engineering and systems science, and economics. Materials on this site are not peer-reviewed by arXiv.
Wikidata
Wikidata is a free and open knowledge base that can be read and edited by both humans and machines. It acts as central storage for the structured data of its Wikimedia sister projects including Wikipedia, Wikivoyage, Wiktionary, Wikisource, and others. Wikidata also provides support to many other sites and services beyond just Wikimedia projects!
The StoryGraph
The StoryGraph is a book tracking and recommendation app that uses machine learning to help users find books they'll enjoy. It offers a variety of features, including personalized recommendations, mood-based browsing, and social features like book clubs and reading buddies. The StoryGraph is a great tool for anyone who loves to read and wants to discover new books.
0 - Open Source AI Tools
20 - OpenAI Gpts
PHP Mentor
Elevate your PHP programming with AI-guided support. Need expert insights, bug resolutions, code optimizations, or upgrades? PHP Mentor delivers custom assistance for developers across all expertise levels, making coding simpler.

Rust
Powerful Rust coding assistant. Trained on a vast array of the best up-to-date Rust resources, libraries and frameworks. Start with a quest! 🥷 (V1.7)
Galactic Librarian
Enthusiastic sci-fi book guide, helps find sci-fi books & avoid spoilers.
Book Finder
This AI tool by Learning Revolution and Hepler Consulting helps you find a good book to read, as well as its corresponding record on WorldCat.org.

The Librarian
A digital librarian who identifies books from photos and provides detailed information.
Linguist Librarian
I translate books into various languages, focusing on specific chapters.

Public Domain PDF Books Finder📚
Public Domain PDF Books Finder GPT offers an expansive library of PDFs for easy search and download. It now specializes in finding public domain books from trusted sources.
LOC Authority Record Finder
This Assistant assists library catalogers in selecting authority records. It advises librarians in creating queries and selecting the most relevant Name and Subject Heading Authority Records.
Film & Séries FR
Votre assistant pour trouver films et séries en streaming et téléchargement gratuit

Scholarly Gap Finder
SGF identifies research gaps using scholarly sources. It creates proposals with abstracts, literature reviews, and a reference list tailored for academic research.