Best AI tools for< Extract Text Pdf >
20 - AI tool Sites
ToolLab
ToolLab is a professional online AI tool that specializes in removing watermarks from PDF files and images. It offers instant and high-quality removal of watermarks while maintaining document integrity. The tool is user-friendly, secure, and does not require any installation or registration. With its AI-powered technology, ToolLab ensures efficient and effective watermark removal, making it a reliable choice for individuals and businesses seeking professional results.
FileDrop
FileDrop is a file or document manager that allows you to drag and drop files into a document with automatic linking and save them to Google Drive. It also offers features like OCR, translation, and AI integration. With FileDrop, you can easily insert, save, and link files in Google Sheets cells, Docs, and Slides.
Scanner Go
Scanner Go is a free PDF tool that offers easy-to-use features for high-quality scanning and conversion of various documents into PDF format. With powerful OCR technology, it allows users to extract text from PDFs and images, making it convenient to edit and share documents. The tool also provides options for managing, editing, printing, and sharing documents, enhancing productivity. Additionally, Scanner Go offers a range of popular tools for converting, optimizing, and securing PDF files, catering to diverse user needs.
Chat PDF AI Online
Chat PDF AI Online is an advanced AI tool that revolutionizes the way users interact with PDF documents. It offers cutting-edge AI features to enhance the PDF experience, providing seamless solutions for reading, summarizing, analyzing, and translating PDF files. With features like longer context support, powerful tabular data analysis, and advanced LLM support, Chat PDF AI Online ensures smarter and faster document processing. Users can securely upload and process large PDF files, benefiting from high accuracy and efficiency in document handling.
Picture to Text Converter
Picture to Text Converter is an online tool that uses Optical Character Recognition (OCR) technology to extract text from images. It can process various image formats like JPG, PNG, GIF, scanned documents (PDFs), and even photos taken with your phone's camera. The extracted text can be copied to the clipboard or downloaded as a TXT file. Picture to Text Converter is free to use and does not require any registration or installation. It is a convenient and efficient way to convert images into editable text.
GetSearchablePDF
GetSearchablePDF is an online tool that allows users to convert scanned or image-based PDF documents into searchable PDFs. With its advanced OCR (Optical Character Recognition) technology, the tool accurately extracts text from images, making the resulting PDFs easy to search, edit, and share. The process is simple and straightforward: users simply connect their Dropbox or OneDrive account, drag and drop their PDF files into the designated folder, and the tool automatically converts them into searchable PDFs.
GrabText
GrabText is an online OCR tool that allows users to convert handwritten or printed text from photos, graphics, or documents into editable text. It uses ChatGPT to automatically correct spelling, grammar, and other illegal writings. The tool also supports math equations and offers flexible output options such as txt, latex, doc, and pdf.
Swiftask
Swiftask is an all-in-one AI Assistant designed to enhance individual and team productivity and creativity. It integrates a range of AI technologies, chatbots, and productivity tools into a cohesive chat interface. Swiftask offers features such as generating text, language translation, creative content writing, answering questions, extracting text from images and PDFs, table and form extraction, audio transcription, speech-to-text conversion, AI-based image generation, and project management capabilities. Users can benefit from Swiftask's comprehensive AI solutions to work smarter and achieve more.
ImageTextify
ImageTextify is a free, AI-powered OCR tool that enables users to extract text from images, PDFs, and handwritten notes with high accuracy and efficiency. The tool offers a wide range of features, including multi-format support, batch processing, and a mobile-friendly interface. ImageTextify is designed to cater to both personal and professional needs, providing a seamless solution for converting images to text. With a focus on privacy, speed, and support for multiple languages and formats, ImageTextify stands out as a reliable and user-friendly OCR tool.
Docubase.ai
Docubase.ai is a powerful document analysis tool that uses advanced natural language processing and machine learning to extract information and provide relevant answers to your queries. It can automatically extract text content from uploaded documents, generate relevant questions, and extract answers from the document content. Docubase.ai supports a wide range of document formats, including PDF, Word, Excel, PowerPoint, and text documents. It also allows users to ask their own questions and provides options to export answers in different formats for easy sharing and documentation.
ChatPDF
ChatPDF is an AI-powered tool that allows users to interact with PDF documents in a conversational manner. It uses natural language processing (NLP) to understand user queries and provide relevant information or perform actions on the PDF. With ChatPDF, users can ask questions about the content of the PDF, search for specific information, extract data, translate text, and more, all through a simple chat-like interface.
EaseUS ChatPDF
EaseUS ChatPDF is an AI-powered PDF summarizer tool that allows users to understand, summarize, and chat with PDF files efficiently. It simplifies PDF reading by providing automatic summarization, analysis, and chat features. The tool is designed to help users save time and effort in extracting key insights from PDF documents. With integrated AI models and OCR capabilities, EaseUS ChatPDF offers a secure and reliable platform for interacting with PDF content.
AI Bank Statement Converter
The AI Bank Statement Converter is an industry-leading tool designed for accountants and bookkeepers to extract data from financial documents using artificial intelligence technology. It offers features such as automated data extraction, integration with accounting software, enhanced security, streamlined workflow, and multi-format conversion capabilities. The tool revolutionizes financial document processing by providing high-precision data extraction, tailored for accounting businesses, and ensuring data security through bank-level encryption. It also offers Intelligent Document Processing (IDP) using AI and machine learning techniques to process structured, semi-structured, and unstructured documents.
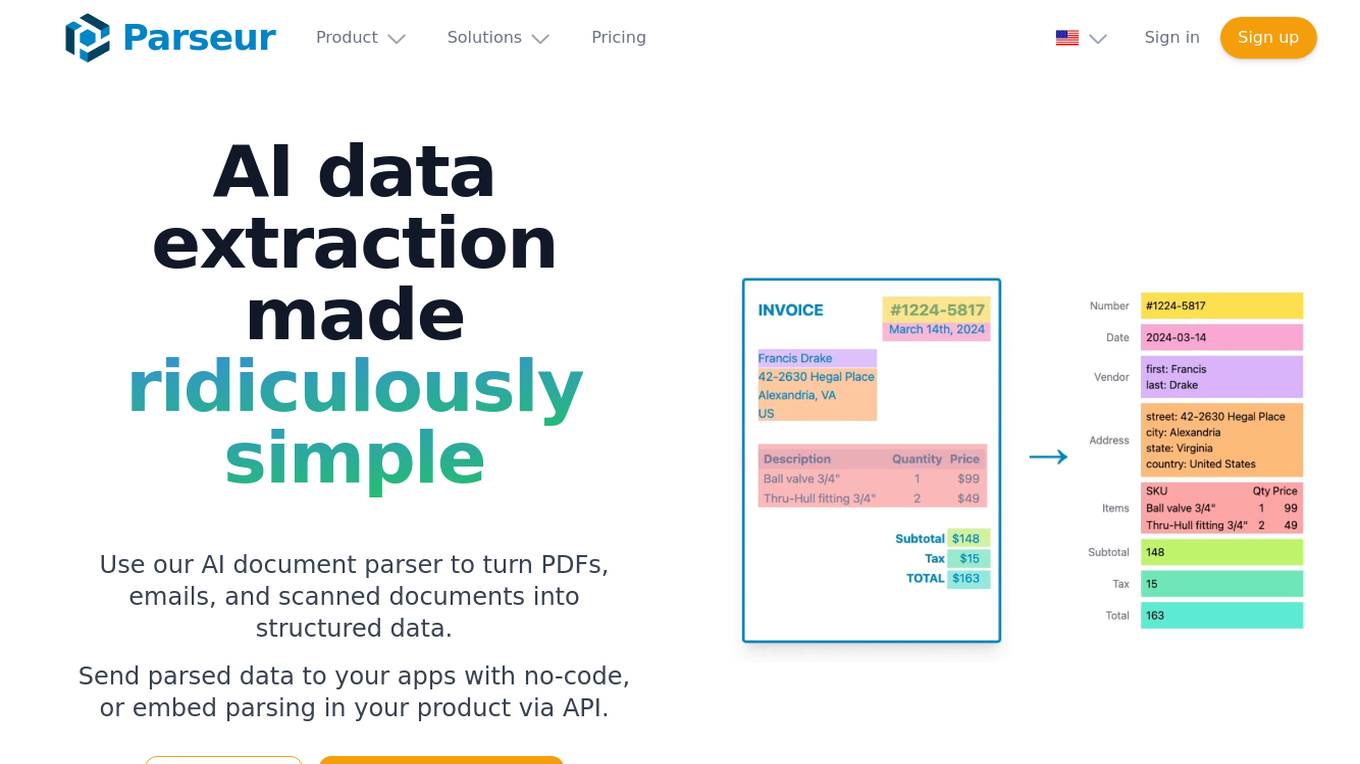
Parseur
Parseur is an AI data extraction software that uses artificial intelligence to extract structured data from various types of documents such as PDFs, emails, and scanned documents. It offers features like template-based data extraction, OCR software for character recognition, and dynamic OCR for extracting fields that move or change size. Parseur is trusted by businesses in finance, tech, logistics, healthcare, real estate, e-commerce, marketing, and human resources industries to automate data extraction processes, saving time and reducing manual errors.
Honeybear.ai
Honeybear.ai is an AI tool designed to simplify document reading tasks. It utilizes advanced algorithms to extract and analyze text from various documents, making it easier for users to access and comprehend information. With Honeybear.ai, users can streamline their document processing workflows and enhance productivity.
PrivacyDoc
PrivacyDoc is an AI-powered portal that allows users to analyze and query PDF and ebooks effortlessly. By leveraging advanced NLP technology, PrivacyDoc enables users to uncover insights and conduct thorough document analysis. The platform offers features such as easy file upload, query functionality, enhanced security measures, and free access to powerful PDF analysis tools. With PrivacyDoc, users can experience the convenience of logging in with their Google account, submitting queries for prompt AI-driven responses, and ensuring data privacy with secure file handling.
iTextMaster
iTextMaster is an AI-powered tool that allows users to analyze, summarize, and chat with text-based documents, including PDFs and web pages. It utilizes ChatGPT technology to provide intelligent answers to questions and extract key information from documents. The tool is designed to simplify text processing, improve understanding efficiency, and save time. iTextMaster supports multiple languages and offers a user-friendly interface for easy navigation and interaction.
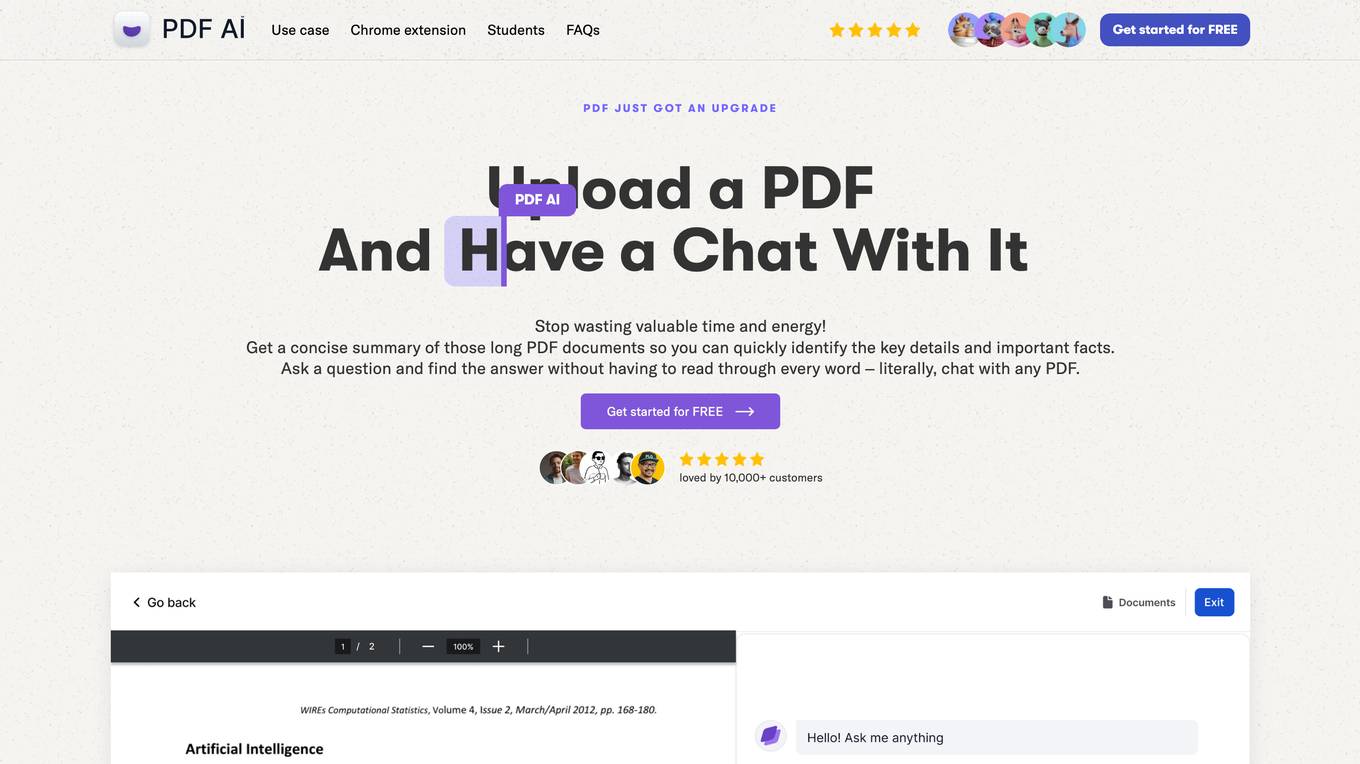
PDF AI
The website offers an AI-powered PDF reader that allows users to chat with any PDF document. Users can upload a PDF, ask questions, get answers, extract precise sections of text, summarize, annotate, highlight, classify, analyze, translate, and more. The AI tool helps in quickly identifying key details, finding answers without reading through every word, and citing sources. It is ideal for professionals in various fields like legal, finance, research, academia, healthcare, and public sector, as well as students. The tool aims to save time, increase productivity, and simplify document management and analysis.
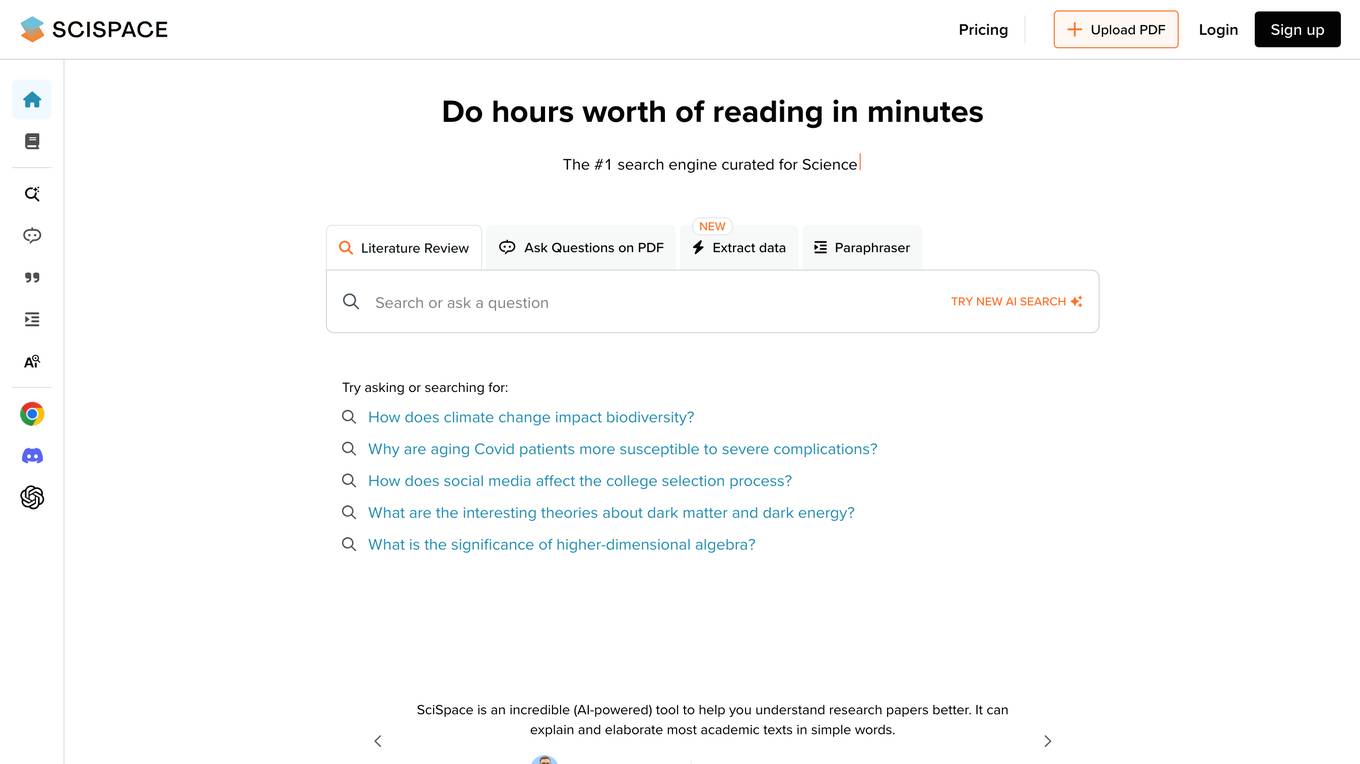
SciSpace
SciSpace is an AI-powered tool that helps researchers understand research papers better. It can explain and elaborate most academic texts in simple words. It is a great tool for students, researchers, and anyone who wants to learn more about a particular topic. SciSpace has a user-friendly interface and is easy to use. Simply upload a research paper or enter a URL, and SciSpace will do the rest. It will highlight key concepts, provide definitions, and generate a summary of the paper. SciSpace can also be used to generate citations and find related papers.

PDF Summarizer
PDFsummarizer.net is an AI tool designed to simplify how users interact with PDF documents. It instantly generates AI summaries of PDF content, breaks language barriers, and offers organized conversations with direct citations. Whether for studying, research, or professional purposes, this tool enhances understanding and accessibility of information across various fields. It improves productivity by streamlining the process of extracting vital information.
0 - Open Source AI Tools
20 - OpenAI Gpts


PDF Ninja
I extract data and tables from PDFs to CSV, focusing on data privacy and precision.
Automated Knowledge Distillation
For strategic knowledge distillation, upload the document you need to analyze and use !start. ENSURE the uploaded file shows DOCUMENT and NOT PDF. This workflow requires leveraging RAG to operate. Only a small amount of PDFs are supported, convert to txt or doc. For timeout, refresh & !continue


Watch Identification, Pricing, Sales Research Tool
Analyze watch images, extract text, and craft sales descriptions. Add 1 or more images for a single watch to get started.
QCM
ce GPT va recevoir des images dans lesquelles il y a des questions QCM codingame ou Problem Solving sur les sujets : Java, Hibernate, Angular, Spring Boot, SQL. Il doit extraire le texte depuis l'image et répondre au question QCM le plus rapidement possible.
kz image 2 typescript 2 image
Generate a Structured description in typescript format from the image and generate an image from that description. and OCR