Best AI tools for< Extract Data From Invoices >
20 - AI tool Sites
FormX.ai
FormX.ai is an AI-powered data extraction and conversion tool that automates the process of extracting data from physical documents and converting it into digital formats. It supports a wide range of document types, including invoices, receipts, purchase orders, bank statements, contracts, HR forms, shipping orders, loyalty member applications, annual reports, business certificates, personnel licenses, and more. FormX.ai's pre-configured data extraction models and effortless API integration make it easy for businesses to integrate data extraction into their existing systems and workflows. With FormX.ai, businesses can save time and money on manual data entry and improve the accuracy and efficiency of their data processing.
Parsio
Parsio is an AI-powered document parser that can extract structured data from PDFs, emails, and other documents. It uses natural language processing to understand the context of the document and identify the relevant data points. Parsio can be used to automate a variety of tasks, such as extracting data from invoices, receipts, and emails.
AlgoDocs
AlgoDocs is a powerful AI Platform developed based on the latest technologies to streamline your processes and free your team from annoying and error-prone manual data entry by offering fast, secure, and accurate document data extraction.
Koncile
Koncile is an AI-powered OCR solution that automates data extraction from various documents. It combines advanced OCR technology with large language models to transform unstructured data into structured information. Koncile can extract data from invoices, accounting documents, identity documents, and more, offering features like categorization, enrichment, and database integration. The tool is designed to streamline document management processes and accelerate data processing. Koncile is suitable for businesses of all sizes, providing flexible subscription plans and enterprise solutions tailored to specific needs.
Booke AI
Booke AI is an AI-driven bookkeeping software that automates tasks, reduces errors, and improves communication. It uses AI to categorize transactions, extract data from invoices and receipts, and provide expert reconciliation assistance. Booke AI integrates with Xero, QuickBooks, and Zoho Books, and offers a user-friendly client portal for seamless collaboration. With Booke AI, businesses can save time, reduce stress, and improve the accuracy of their bookkeeping.
Invofox API
Invofox API is a Document Parsing API designed for developers to validate fields, autocomplete data, and catch errors beyond OCR. It turns unstructured documents into clean JSON using advanced AI models and proprietary algorithms. The API provides built-in schemas for major documents and supports custom formats, allowing users to parse any document with a single API call without templates or post-processing. Invofox is used for expense management, accounts payable, logistics & supply chain, HR automation, sustainability & consumption tracking, and custom document parsing.
AI Bank Statement Converter
The AI Bank Statement Converter is an industry-leading tool designed for accountants and bookkeepers to extract data from financial documents using artificial intelligence technology. It offers features such as automated data extraction, integration with accounting software, enhanced security, streamlined workflow, and multi-format conversion capabilities. The tool revolutionizes financial document processing by providing high-precision data extraction, tailored for accounting businesses, and ensuring data security through bank-level encryption. It also offers Intelligent Document Processing (IDP) using AI and machine learning techniques to process structured, semi-structured, and unstructured documents.
Evolution AI
Evolution AI is an AI data extraction tool that specializes in extracting data from financial documents such as financial statements, bank statements, invoices, and other related documents. The tool uses generative AI technology to automate the data extraction process, eliminating the need for manual entry. Evolution AI is trusted by global industry leaders and offers exceptional customer service, advanced technology, and a one-stop shop for data extraction.
Extracta.ai
Extracta.ai is an AI data extraction tool for documents and images that automates data extraction processes with easy integration. It allows users to define custom templates for extracting structured data without the need for training. The platform can extract data from various document types, including invoices, resumes, contracts, receipts, and more, providing accurate and efficient results. Extracta.ai ensures data security, encryption, and GDPR compliance, making it a reliable solution for businesses looking to streamline document processing.
super.AI
Super.AI provides Intelligent Document Processing (IDP) solutions powered by Large Language Models (LLMs) and human-in-the-loop (HITL) capabilities. It automates document processing tasks such as data extraction, classification, and redaction, enabling businesses to streamline their workflows and improve accuracy. Super.AI's platform leverages cutting-edge AI models from providers like Amazon, Google, and OpenAI to handle complex documents, ensuring high-quality outputs. With its focus on accuracy, flexibility, and scalability, Super.AI caters to various industries, including financial services, insurance, logistics, and healthcare.
DocuPipe
DocuPipe is an AI-powered document extraction tool that helps businesses convert various types of documents into structured data. It uses artificial intelligence to extract information from documents such as invoices, medical records, insurance claims, and more. DocuPipe offers custom definitions tailored for different businesses to accurately extract required data. The tool ensures security and compliance by encrypting documents and being GDPR and HIPAA compliant. With features like OCR, document standardization, and document splitting, DocuPipe provides accuracy, flexibility, and speed in handling documents.
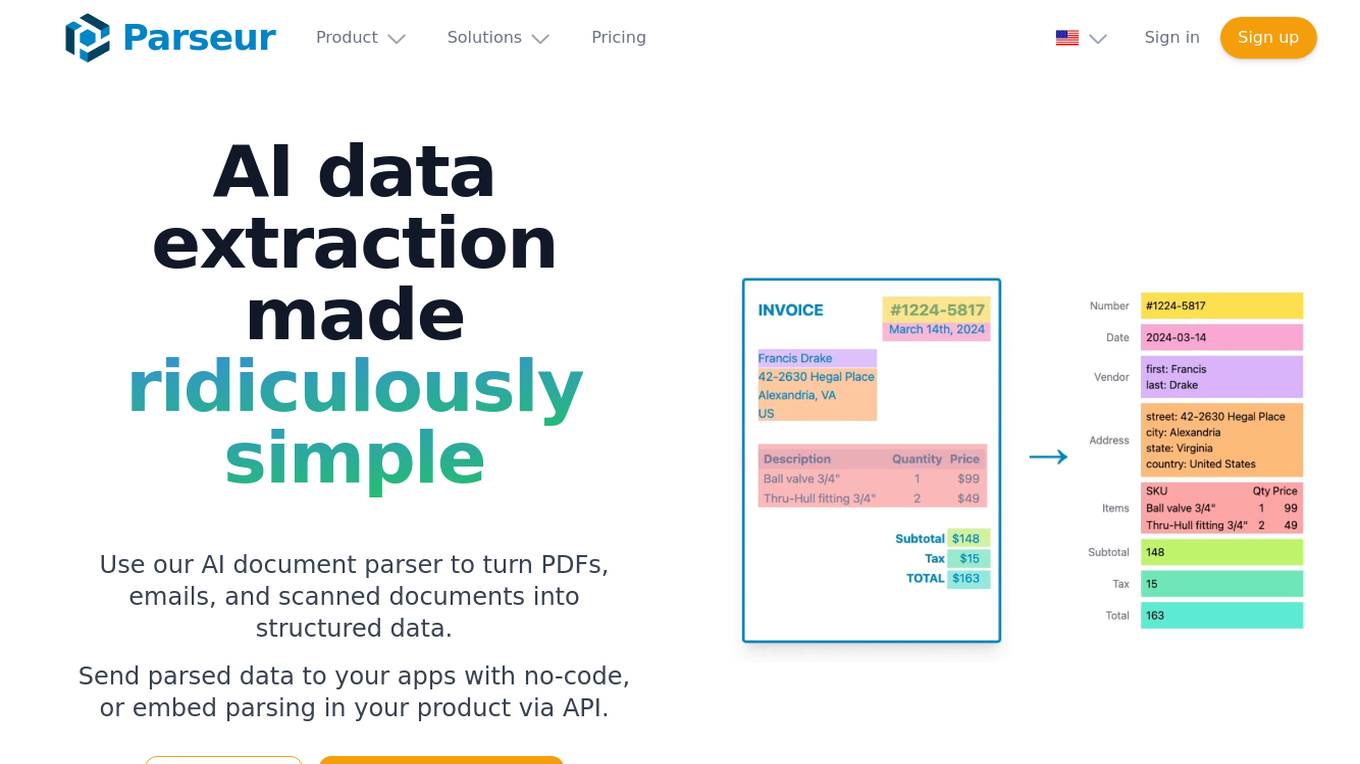
Parseur
Parseur is an AI data extraction software that uses artificial intelligence to extract structured data from various types of documents such as PDFs, emails, and scanned documents. It offers features like template-based data extraction, OCR software for character recognition, and dynamic OCR for extracting fields that move or change size. Parseur is trusted by businesses in finance, tech, logistics, healthcare, real estate, e-commerce, marketing, and human resources industries to automate data extraction processes, saving time and reducing manual errors.
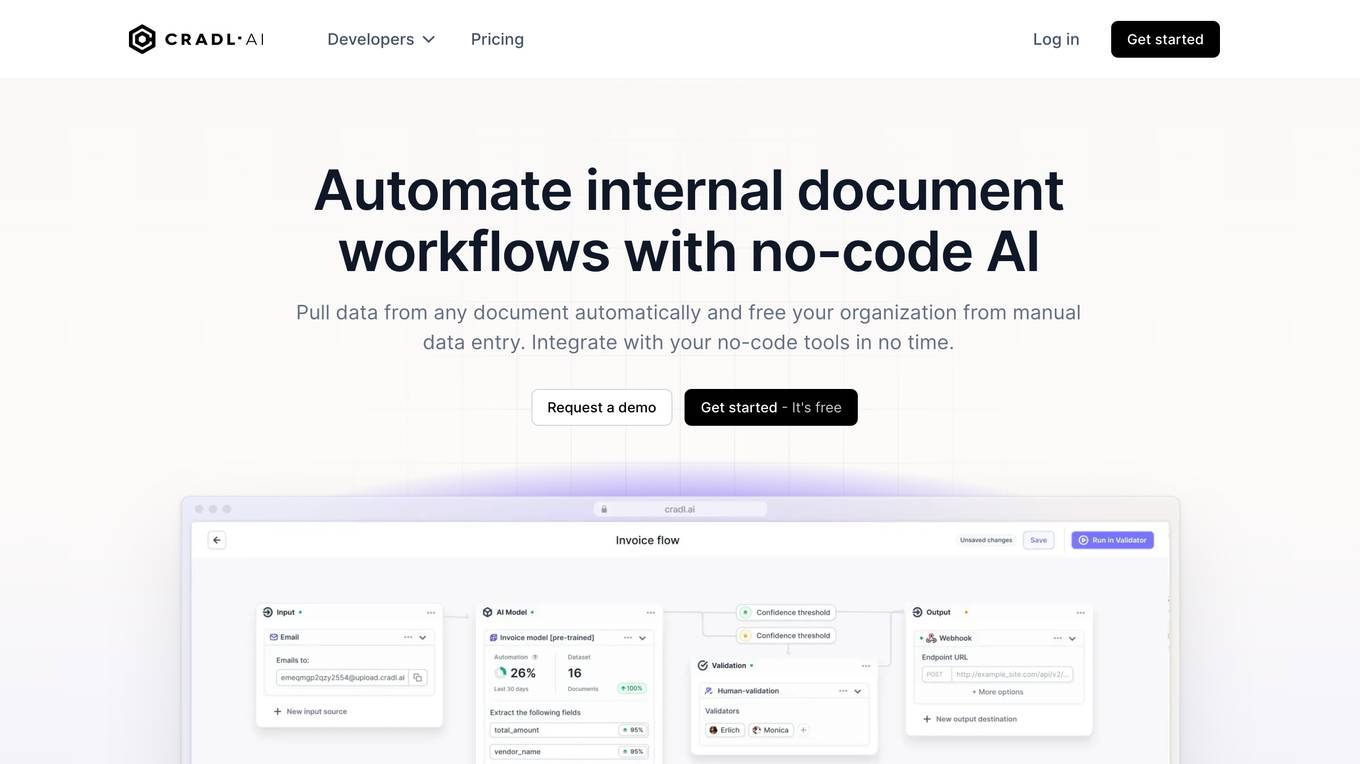
Cradl AI
Cradl AI is a no-code AI-powered document workflow automation tool that helps organizations automate document-related tasks, such as data extraction, processing, and validation. It uses AI to automatically extract data from complex document layouts, regardless of layout or language. Cradl AI also integrates with other no-code tools, making it easy to build and deploy custom AI models.
Receipt OCR API
Receipt OCR API by ReceiptUp is an advanced tool that leverages OCR and AI technology to extract structured data from receipt and invoice images. The API offers high accuracy and multilingual support, making it ideal for businesses worldwide to streamline financial operations. With features like multilingual support, high accuracy, support for multiple formats, accounting downloads, and affordability, Receipt OCR API is a powerful tool for efficient receipt management and data extraction.
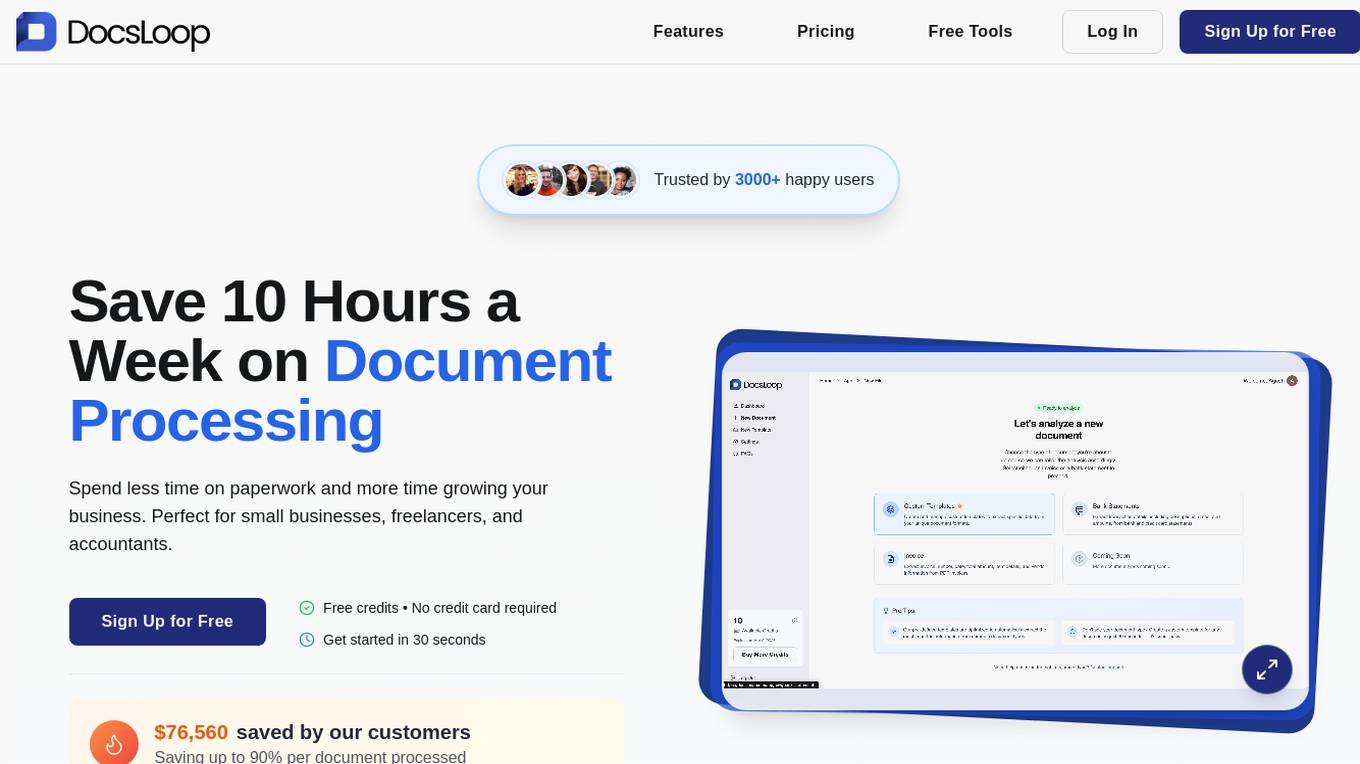
DocsLoop
DocsLoop is a document extraction tool designed to simplify and automate document processing tasks for businesses, freelancers, and accountants. It offers a user-friendly interface, high accuracy in data extraction, and fully automated processing without the need for technical skills or human intervention. With DocsLoop, users can save hours every week by effortlessly extracting structured data from various document types, such as invoices and bank statements, and export it in their preferred format. The platform provides pay-as-you-go pricing plans with credits that never expire, catering to different user needs and business sizes.
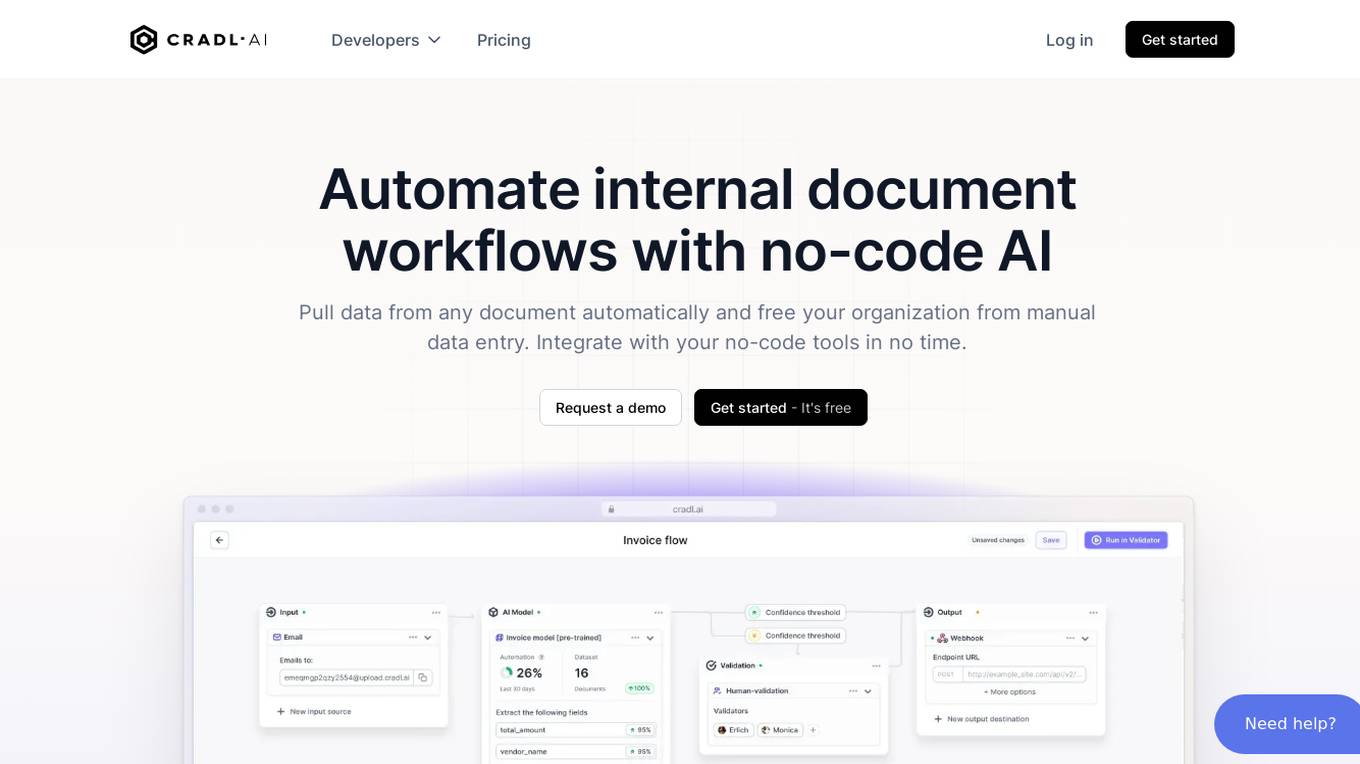
Cradl AI
Cradl AI is an AI-powered tool designed to automate document workflows with no-code AI. It enables users to extract data from any document automatically, integrate with no-code tools, and build custom AI models through an easy-to-use interface. The tool empowers automation teams across industries by extracting data from complex document layouts, regardless of language or structure. Cradl AI offers features such as line item extraction, fine-tuning AI models, human-in-the-loop validation, and seamless integration with automation tools. It is trusted by organizations for business-critical document automation, providing enterprise-level features like encrypted transmission, GDPR compliance, secure data handling, and auto-scaling.
ASSIST
ASSIST is an AI-driven document management software designed to streamline financial paperwork processing and data entry tasks. The application offers features such as SmartDoc Entry for extracting information from invoices and receipts, Polyglot Processing for multilingual support, One-Tap Integration with accounting platforms, ExportEase for data export in CSV format, and AutoFlow Revolution for automated workflows. ASSIST aims to simplify document management, enhance efficiency, and drive digital transformation in businesses by leveraging AI technology.
Affinda
Affinda is a document AI platform that can read, understand, and extract data from any document type. It combines 10+ years of IP in document reconstruction with the latest advancements in computer vision, natural language processing, and deep learning. Affinda's platform can be used to automate a variety of document processing workflows, including invoice processing, receipt processing, credit note processing, purchase order processing, account statement processing, resume parsing, job description parsing, resume redaction, passport processing, birth certificate processing, and driver's license processing. Affinda's platform is used by some of the world's leading organizations, including Google, Microsoft, Amazon, and IBM.
TurboDoc
TurboDoc is an AI-powered tool designed to extract information from invoices and transform unstructured data into easy-to-read structured data. It offers a user-friendly interface for efficient work with accounts payable, budget planning, and control. The tool ensures high accuracy through advanced AI models and provides secure data storage with AES256 encryption. Users can automate invoice processing, link Gmail for seamless integration, and optimize workflow with various applications.
Mindee Platform
Mindee Platform is an AI Document Data Extraction API that offers end-to-end document-based workflows automation. It provides pre-built API catalog, custom document understanding, and continuous learning capabilities. The platform enables users to automate invoice processing, receipt extraction, and document management with high accuracy and scalability. Mindee's AI models support structured, semi-structured, and unstructured documents, making it a versatile solution for various industries. With features like RAG-enhanced continuous learning, security compliance, and table extraction technology, Mindee offers a comprehensive document automation platform for businesses and developers.
0 - Open Source AI Tools
20 - OpenAI Gpts
PDF Ninja
I extract data and tables from PDFs to CSV, focusing on data privacy and precision.
Spreadsheet Composer
Magically turning text from emails, lists and website content into spreadsheet tables
Property Manager Document Assistant
Provides analysis and data extraction of Property Management documents and contracts for managers

Fill PDF Forms
Fill legal forms & complex PDF documents easily! Upload a file, provide data sources and I'll handle the rest.

Email Thread GPT
I'm EmailThreadAnalyzer, here to help you with your email thread analysis.
Regex Wizard
Generate and explain regex patterns from your description, it support English and Chinese.
Metaphor API Guide - Python SDK
Teaches you how to use the Metaphor Search API using our Python SDK

Receipt CSV Formatter
Extract from receipts to CSV: Date of Purchase, Item Purchased, Quantity Purchased, Units

Dissertation & Thesis GPT
An Ivy Leage Scholar GPT equipped to understand your research needs, formulate comprehensive literature review strategies, and extract pertinent information from a plethora of academic databases and journals. I'll then compose a peer review-quality paper with citations.