Best AI tools for< Evaluating Arguments >
20 - AI tool Sites
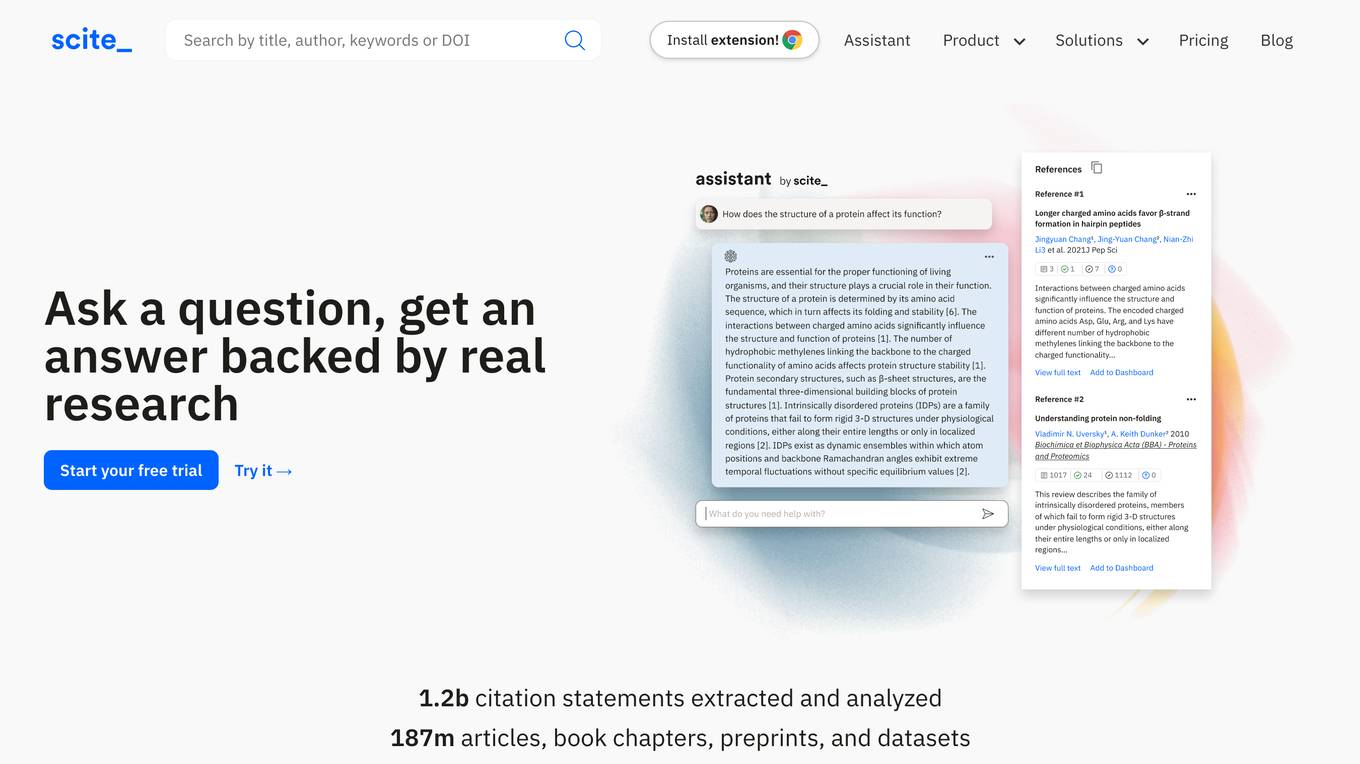
Scite
Scite is an award-winning platform for discovering and evaluating scientific articles via Smart Citations. Smart Citations allow users to see how a publication has been cited by providing the context of the citation and a classification describing whether it provides supporting or contrasting evidence for the cited claim.

Flow AI
Flow AI is an advanced AI tool designed for evaluating and improving Large Language Model (LLM) applications. It offers a unique system for creating custom evaluators, deploying them with an API, and developing specialized LMs tailored to specific use cases. The tool aims to revolutionize AI evaluation and model development by providing transparent, cost-effective, and controllable solutions for AI teams across various domains.
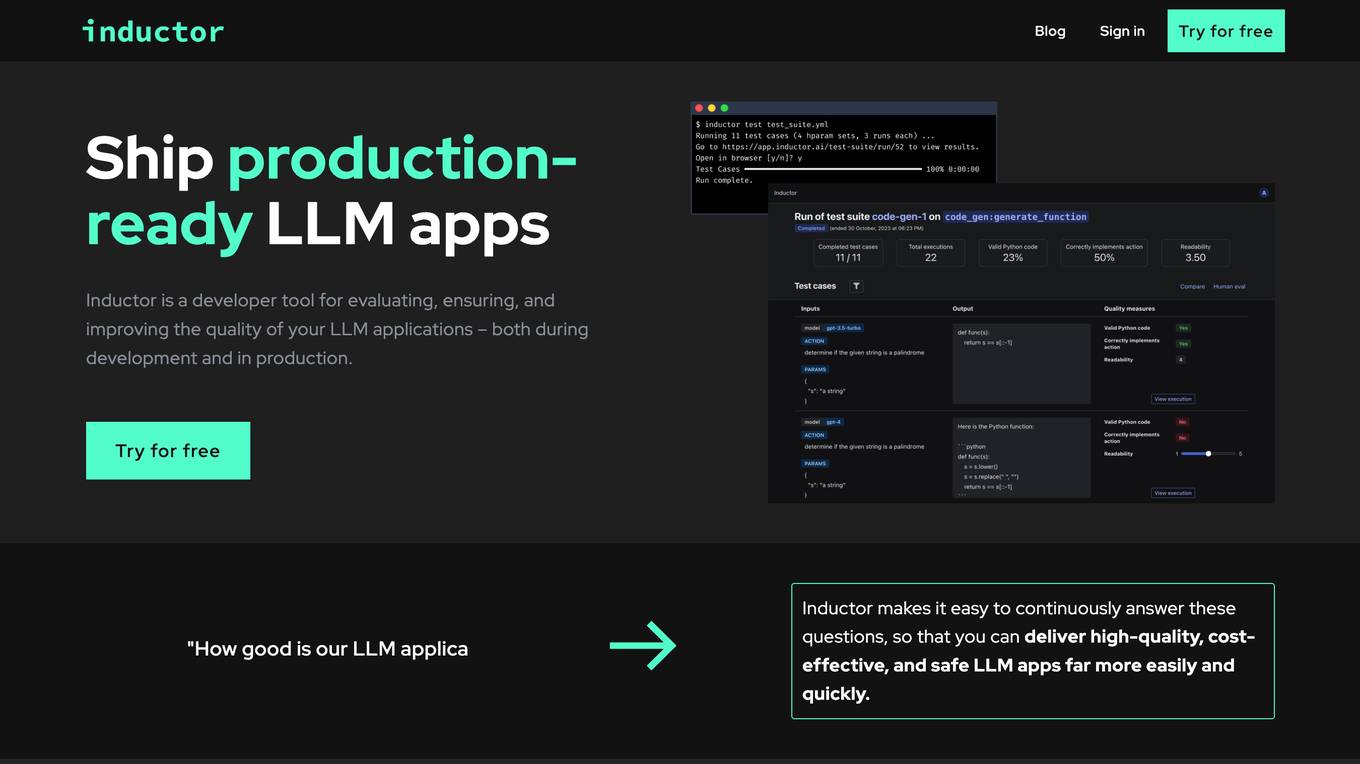
Inductor
Inductor is a developer tool for evaluating, ensuring, and improving the quality of your LLM applications – both during development and in production. It provides a fantastic workflow for continuous testing and evaluation as you develop, so that you always know your LLM app’s quality. Systematically improve quality and cost-effectiveness by actionably understanding your LLM app’s behavior and quickly testing different app variants. Rigorously assess your LLM app’s behavior before you deploy, in order to ensure quality and cost-effectiveness when you’re live. Easily monitor your live traffic: detect and resolve issues, analyze usage in order to improve, and seamlessly feed back into your development process. Inductor makes it easy for engineering and other roles to collaborate: get critical human feedback from non-engineering stakeholders (e.g., PM, UX, or subject matter experts) to ensure that your LLM app is user-ready.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.

RebeccAi
RebeccAi is an AI-powered business idea evaluation and validation tool that uses AI technology to provide accurate insights into the potential of users' ideas. It helps users refine and improve their ideas quickly and intelligently, acting as a one-person team for their business dreams. From evaluating and assessing business ideas to creating detailed business plans, RebeccAi revolutionizes idea validation with the power of AI.

Brevoir
Brevoir is an AI-powered decision-grade due diligence tool designed for startup investing. It consolidates founder diligence, market and competitor research, risk assessment, and investment-ready writeups in one platform. Tailored for angel investors and startup evaluators, Brevoir streamlines the startup evaluation process by extracting key information from pitch decks or company URLs, verifying claims, mapping competitors, and providing structured reports with risks and opportunities. The tool aims to provide clear answers, identify market trends, evaluate team credibility, assess traction and risks, and offer pricing plans that scale with user needs.
Surge AI
Surge AI is a data labeling platform that provides human-generated data for training and evaluating large language models (LLMs). It offers a global workforce of annotators who can label data in over 40 languages. Surge AI's platform is designed to be easy to use and integrates with popular machine learning tools and frameworks. The company's customers include leading AI companies, research labs, and startups.
Langfuse
Langfuse is an AI tool that offers the Langfuse TypeScript SDK v4 for building and debugging LLM (Large Language Models) applications. It provides features such as tracing, prompt management, evaluation, and metrics to enhance the performance of LLM applications. Langfuse is backed by a team of experts and offers integrations with various platforms and SDKs. The tool aims to simplify the development process of complex LLM applications and improve overall efficiency.

MASCAA
MASCAA is a comprehensive human confidence analysis platform that focuses on evaluating the confidence of users through video and audio during various tasks. It integrates advanced facial expression and voice analysis technologies to provide valuable feedback for students, instructors, individuals, businesses, and teams. MASCAA offers quick and easy test creation, evaluation, and confidence assessment for educational settings, personal use, startups, small organizations, universities, and large organizations. The platform aims to unlock long-term value and enhance customer experience by helping users assess and improve their confidence levels.
Chemprop
Chemprop is a PyTorch-based framework for training and evaluating message-passing neural networks (MPNNs) for molecular property prediction. Originally developed for research purposes, Chemprop offers a comprehensive set of tools and features for training models and analyzing molecular representations. The package underwent a recent major release (v2.0.0) with significant improvements and updates.
ScamMinder
ScamMinder is an AI-powered tool designed to enhance online safety by analyzing and evaluating websites in real-time. It harnesses cutting-edge AI technology to provide users with a safety score and detailed insights, helping them detect potential risks and red flags. By utilizing advanced machine learning algorithms, ScamMinder assists users in making informed decisions about engaging with websites, businesses, and online entities. With a focus on trustworthiness assessment, the tool aims to protect users from deceptive traps and safeguard their digital presence.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.
Outlier AI
Outlier AI is a platform that connects subject matter experts to help build the world's most advanced Generative AI. It allows experts to work on various projects from generating training data to evaluating model performance. The platform offers flexibility, allowing contributors to work from home on their own schedule. Outlier AI aims to redefine how AI learns by leveraging the expertise of domain specialists across different fields.

Sapia.ai
Sapia.ai is an AI hiring agent that revolutionizes the recruitment process by conducting structured interviews with candidates, evaluating real skills, and providing valuable insights at scale. Trusted by leading brands, Sapia.ai streamlines hiring processes, enhances candidate experience, and improves hiring outcomes through AI-driven solutions. The platform offers features such as chat and video interviews, interview scheduling, talent insights, and candidate engagement tools. With a focus on speed, fairness, and diversity, Sapia.ai helps organizations find the right talent efficiently and effectively.
Airtrain
Airtrain is a no-code compute platform for Large Language Models (LLMs). It provides a user-friendly interface for fine-tuning, evaluating, and deploying custom AI models. Airtrain also offers a marketplace of pre-trained models that can be used for a variety of tasks, such as text generation, translation, and question answering.
Fairo
Fairo is a platform that facilitates Responsible AI Governance, offering tools for reducing AI hallucinations, managing AI agents and assets, evaluating AI systems, and ensuring compliance with various regulations. It provides a comprehensive solution for organizations to align their AI systems ethically and strategically, automate governance processes, and mitigate risks. Fairo aims to make responsible AI transformation accessible to organizations of all sizes, enabling them to build technology that is profitable, ethical, and transformative.

Dreamphilic
Dreamphilic.com is a website that provides a comprehensive guide on choosing the right electronics distributor. The site offers strategies for evaluating distributors based on quality, pricing, and continuity, with tips for managing IC Chips and ensuring resilient sourcing. It emphasizes the importance of distinguishing between authorized and independent channels, quality assurance for sensitive devices, and commercial terms for staying on track with build plans. The platform aims to help optimize AVL, suggest drop-in replacements, and proactively flag PCNs and lifecycle transitions to reduce total cost of ownership and improve supply continuity and product reliability.
ADOUT
ADOUT is a platform that provides reviews of online casinos in Spain. The website offers detailed insights and recommendations to help users make informed decisions when it comes to online gambling. From analyzing slot machines with the highest Return to Player (RTP) rates to evaluating live casino games like blackjack and roulette, ADOUT aims to guide users towards a rewarding online casino experience. The platform also reviews promotional offers, withdrawal methods, and provides honest opinions from gaming enthusiasts to assist users in strategizing their gameplay and maximizing their winnings.
Strat.Chat
Strat.Chat is an AI-based business strategy tool that assists business owners, potential founders, and entrepreneurs in evaluating business ideas, developing implementation plans, and providing comprehensive market data. Users can describe their business idea or existing model, and the tool uses artificial intelligence to analyze it in five steps: idea assessment, industry structure analysis, macroeconomic perspective, implementation plan, and market data. The tool offers customizable recommendations and the option for a 'Deep Dive' to delve into more detailed insights.
JudgeAI
JudgeAI is an AI tool designed to assist users in making judgments or decisions. It utilizes artificial intelligence algorithms to analyze data and provide insights. The tool helps users in evaluating information and reaching conclusions based on the input data. JudgeAI aims to streamline decision-making processes and enhance accuracy by leveraging AI technology.
0 - Open Source AI Tools
20 - OpenAI Gpts
X Community Notes Helper
Assists in crafting and evaluating Community Notes on X, focusing on accuracy and concise clarity.

Scientific Insight
Scientific expert in evaluating articles using ROBINS-I and Cochrane tools

Eureka Research Assessment and Improvement
AI tool for self-evaluating and enhancing scientific research capabilities.

Financial Sentiment Analyst
A sentiment analysis tool for evaluating management-related texts.
Concept Tutor
Assistant focused on teaching concepts, evaluating comprehension, and recommending subsequent topics. USE WITH VOICE.
Rate My ADHD
Provides a 10-question ADHD assessment, each with a subtitle evaluating specific traits.
Evaluation Criteria Creator
Simply write any topic (anything superheroes, vacuums, Pokémon’, diamonds…) and I’ll provide the evaluation criteria you can use.
Source Evaluation and Fact Checking v1.3
FactCheck Navigator GPT is designed for in-depth fact checking and analysis of written content and evaluation of its source. The approach is to iterate through predefined and well-prompted steps. If desired, the user can refine the process by providing input between these steps.

Supplier Evaluation Advisor
Assesses and recommends potential suppliers for organizational needs.
Project Post-Project Evaluation Advisor
Optimizes project outcomes through comprehensive post-project evaluations.
Desktop Value
Valuating custom computer hardware. Copyright (C) 2023, Sourceduty - All Rights Reserved.