Best AI tools for< Evaluate Writing >
20 - AI tool Sites
Integrito
Integrito is an AI detection tool for writing activity analysis, designed to help teachers prevent cheating, students prove their contribution, and institutions promote honesty. It offers a comprehensive text analysis to ensure authenticity, detect suspicious activity, and track the writing process. Integrito empowers users to evaluate contribution and editing time, view the history of the writing process, and unveil contract-cheating and ghost-writing by writing services. The tool aims to enhance critical thinking, foster creativity, and promote high standards in academia by providing plagiarism checking, AI detection, grammar checking, and authorship verification features.
AI-Responder for HostAway
AI-Responder for HostAway is a Chrome extension powered by Kortex Invest AI that significantly reduces writing time by 98%. It offers automated responses based on property-specific knowledge documents, guest data, and previous chat history. The AI tool is designed to provide high-quality responses, with a focus on accuracy and efficiency, particularly in the gambling industry. It helps users navigate complex topics, such as evaluating online casino platforms, by offering quick solutions and convenient workflow. The tool aims to save time and enhance decision-making processes by leveraging advanced AI models.
Scite
Scite is an award-winning platform for discovering and evaluating scientific articles via Smart Citations. Smart Citations allow users to see how a publication has been cited by providing the context of the citation and a classification describing whether it provides supporting or contrasting evidence for the cited claim.
TenderPilot
TenderPilot is an AI-powered SaaS platform designed for Australian small and medium businesses to improve their success in government tenders. It guides users through analyzing, writing, reviewing, and submitting tender proposals efficiently. The platform is trained on actual government procurement policies and evaluation models, offering expert strategy, secure data hosting, and tailored bid recommendations to help SMEs win more contracts faster and smarter.

A Million Dollar Idea
A Million Dollar Idea is an AI-powered business idea generator that helps entrepreneurs and small business owners come up with new and innovative business ideas. The tool uses a variety of data sources, including industry trends, market research, and user feedback, to generate ideas that are tailored to the user's specific needs and interests. A Million Dollar Idea is a valuable resource for anyone who is looking to start a new business or grow an existing one.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

thisorthis.ai
thisorthis.ai is an AI tool that allows users to compare generative AI models and AI model responses. It helps users analyze and evaluate different AI models to make informed decisions. The tool requires JavaScript to be enabled for optimal functionality.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.

Arize AI
Arize AI is an AI Observability & LLM Evaluation Platform that helps you monitor, troubleshoot, and evaluate your machine learning models. With Arize, you can catch model issues, troubleshoot root causes, and continuously improve performance. Arize is used by top AI companies to surface, resolve, and improve their models.

Evidently AI
Evidently AI is an open-source machine learning (ML) monitoring and observability platform that helps data scientists and ML engineers evaluate, test, and monitor ML models from validation to production. It provides a centralized hub for ML in production, including data quality monitoring, data drift monitoring, ML model performance monitoring, and NLP and LLM monitoring. Evidently AI's features include customizable reports, structured checks for data and models, and a Python library for ML monitoring. It is designed to be easy to use, with a simple setup process and a user-friendly interface. Evidently AI is used by over 2,500 data scientists and ML engineers worldwide, and it has been featured in publications such as Forbes, VentureBeat, and TechCrunch.

Maxim
Maxim is an end-to-end AI evaluation and observability platform that empowers modern AI teams to ship products with quality, reliability, and speed. It offers a comprehensive suite of tools for experimentation, evaluation, observability, and data management. Maxim aims to bring the best practices of traditional software development into non-deterministic AI workflows, enabling rapid iteration and deployment of AI models. The platform caters to the needs of AI developers, data scientists, and machine learning engineers by providing a unified framework for evaluation, visual flows for workflow testing, and observability features for monitoring and optimizing AI systems in real-time.

RebeccAi
RebeccAi is an AI-powered business idea evaluation and validation tool that uses AI technology to provide accurate insights into the potential of users' ideas. It helps users refine and improve their ideas quickly and intelligently, acting as a one-person team for their business dreams. From evaluating and assessing business ideas to creating detailed business plans, RebeccAi revolutionizes idea validation with the power of AI.

Codei
Codei is an AI-powered platform designed to help individuals land their dream software engineering job. It offers features such as application tracking, question generation, and code evaluation to assist users in honing their technical skills and preparing for interviews. Codei aims to provide personalized support and insights to help users succeed in the tech industry.
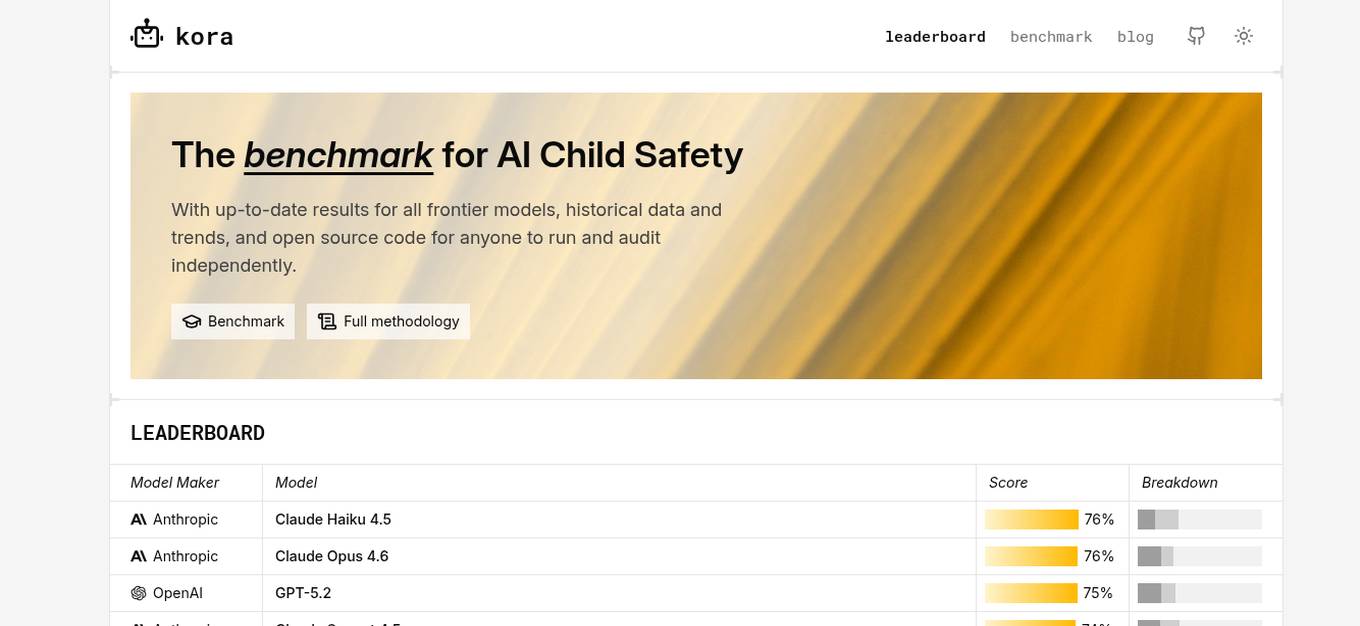
KORA Benchmark
KORA Benchmark is a leading platform that provides a benchmark for AI child safety. It offers up-to-date results for frontier models, historical data, and trends. The platform also provides open-source code for users to run and audit independently. KORA Benchmark aims to ensure the safety of children in the AI landscape by evaluating various models and providing valuable insights to the community.

Brevoir
Brevoir is an AI-powered decision-grade due diligence tool designed for startup investing. It consolidates founder diligence, market and competitor research, risk assessment, and investment-ready writeups in one platform. Tailored for angel investors and startup evaluators, Brevoir streamlines the startup evaluation process by extracting key information from pitch decks or company URLs, verifying claims, mapping competitors, and providing structured reports with risks and opportunities. The tool aims to provide clear answers, identify market trends, evaluate team credibility, assess traction and risks, and offer pricing plans that scale with user needs.

Ottic
Ottic is an AI tool designed to empower both technical and non-technical teams to test Language Model (LLM) applications efficiently and accelerate the development cycle. It offers features such as a 360º view of the QA process, end-to-end test management, comprehensive LLM evaluation, and real-time monitoring of user behavior. Ottic aims to bridge the gap between technical and non-technical team members, ensuring seamless collaboration and reliable product delivery.

SuperAnnotate
SuperAnnotate is an AI data platform that simplifies and accelerates model-building by unifying the AI pipeline. It enables users to create, curate, and evaluate datasets efficiently, leading to the development of better models faster. The platform offers features like connecting any data source, building customizable UIs, creating high-quality datasets, evaluating models, and deploying models seamlessly. SuperAnnotate ensures global security and privacy measures for data protection.
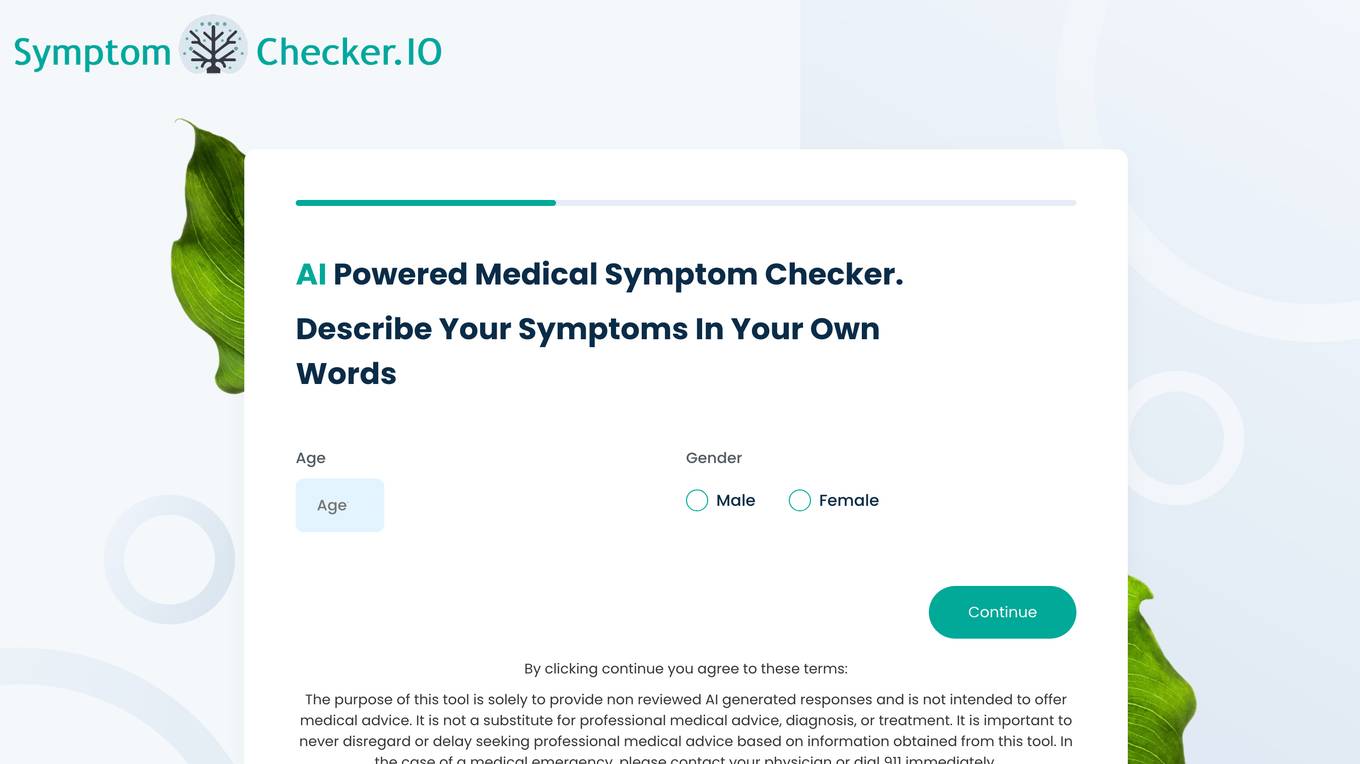
SymptomChecker.io
SymptomChecker.io is an AI-powered medical symptom checker that allows users to describe their symptoms in their own words and receive non-reviewed AI-generated responses. It is important to note that this tool is not intended to offer medical advice, diagnosis, or treatment and should not be used as a substitute for professional medical advice. In the case of a medical emergency, please contact your physician or dial 911 immediately.
ELSA
ELSA is an AI-powered English speaking coach that helps you improve your pronunciation, fluency, and confidence. With ELSA, you can practice speaking English in short, fun dialogues and get instant feedback from our proprietary artificial intelligence technology. ELSA also offers a variety of other features, such as personalized lesson plans, progress tracking, and games to help you stay motivated.
ELSA Speech Analyzer
ELSA Speech Analyzer is an AI-powered conversational English fluency coach that provides instant, personalized feedback on your speech. It helps users improve their pronunciation, intonation, grammar, and vocabulary through real-time analysis. The tool is designed to assist individuals, professionals, students, and organizations in enhancing their English speaking skills and communication abilities.
0 - Open Source AI Tools
20 - OpenAI Gpts

Stick to the Point
I'll help you evaluate your writing to make sure it's engaging, informative, and flows well. Uses principles from "Made to Stick"

IELTS AI Checker (Speaking and Writing)
Provides IELTS speaking and writing feedback and scores.
Essay Prompt Generator
K12 assessment expert, creating grade-level appropriate essay prompts.

IELTS Writing Test
Simulates the IELTS Writing Test, evaluates responses, and estimates band scores.

Grant Writing & General Assistant for Non-Profits
Expert in non-profit organization support and grant writing. Start by uploading the grant you want to apply for.

筆圧特性評価機(Writing Pressure Characterization Machine)
デジタル テキストを除く、手書きの筆圧を分析して性格特性を推測します。(Analyzes handwriting pressure to infer personality traits, excluding digital text.)
继续教育项目写作助手
是一个可以帮助你撰写继续教育项目申请书的功能。它可以根据你的项目主题、项目目标、项目内容、项目预算、项目效果等信息,为你生成一份符合格式要求和逻辑结构的项目申请书草稿。它还可以提供一些参考文献和范文,帮助你完善和优化你的项目申请书。
Rhetoric Analyzer
Expert in Rhetorical Analysis, providing detailed text analysis and insights.
Grade an Op-ed type essay
Grades op-eds on reasoning, fair engagement, and open-mindedness.