Best AI tools for< Evaluate Value Propositions >
20 - AI tool Sites
iPhone中古買取情報局
iPhone中古買取情報局 is a website that provides detailed information on factors affecting the price decrease in iPhone used trade-in, such as the condition of the device, evaluation criteria for different capacities, and differences between trade-in and resale. The site also offers guidance on preparing for the trade-in process, including data processing and initialization steps, the impact of accessories on evaluation, and understanding market fluctuations based on the timing of trade-ins. Users can learn about the importance of external appearance checks and how they influence the assessment value, as well as tips for a smooth and secure trade-in experience.
RevSure
RevSure is an AI-powered platform designed for high-growth marketing teams to optimize marketing ROI and attribution. It offers full-funnel attribution, deep funnel optimization, predictive insights, and campaign performance tracking. The platform integrates with various data sources to provide unified funnel reporting and personalized recommendations for improving pipeline health and conversion rates. RevSure's AI engine powers features like campaign spend reallocation, next-best touch analysis, and journey timeline construction, enabling users to make data-driven decisions and accelerate revenue growth.
ZestyAI
ZestyAI is an artificial intelligence tool that helps users make brilliant climate and property risk decisions. The tool uses AI to provide insights on property values and risk exposure to natural disasters. It offers products such as Property Insights, Digital Roof, Roof Age, Location Insights, and Climate Risk Models to evaluate and understand property risks. ZestyAI is trusted by top insurers in North America and aims to bring a ten times return on investment to its customers.

Appraiser.AI
Appraiser.AI is an AI-powered appraisal tool designed to help users accurately assess the value of a wide range of collectibles and antiques. By leveraging advanced algorithms and data analysis, the tool provides users with instant appraisals for items such as vintage coins, jewelry, artwork, vinyl records, trading cards, and more. With a user-friendly interface, Appraiser.AI offers a convenient and reliable solution for individuals looking to determine the worth of their possessions quickly and efficiently.
The Clinical AI Report
The Clinical AI Report is an independent platform that provides reviews and rankings of clinical AI tools for physicians. It evaluates various platforms based on clinical accuracy, evidence quality, EHR integration, workflow fit, and value to help physicians access evidence at the point of care. The platform aims to identify the best tools that deliver transparent evidence citations and accurate clinical decision support. It offers detailed reviews and rankings to assist healthcare professionals in making informed decisions about the tools they use.

MASCAA
MASCAA is a comprehensive human confidence analysis platform that focuses on evaluating the confidence of users through video and audio during various tasks. It integrates advanced facial expression and voice analysis technologies to provide valuable feedback for students, instructors, individuals, businesses, and teams. MASCAA offers quick and easy test creation, evaluation, and confidence assessment for educational settings, personal use, startups, small organizations, universities, and large organizations. The platform aims to unlock long-term value and enhance customer experience by helping users assess and improve their confidence levels.
Workflos
Workflos is a platform designed to help business leaders discover and explore software solutions across various categories. It provides insights into trending software, customer favorites, and top-rated products based on criteria like ease of use and value for money. With Workflos, users can stay informed about the latest software offerings and make informed decisions to meet their business needs.
AnalyStock.ai
AnalyStock.ai is a financial application leveraging AI to provide users with a next-generation investment toolbox. It helps users better understand businesses, risks, and make informed investment decisions. The platform offers direct access to the stock market, powerful data-driven tools to build top-ranking portfolios, and insights into company valuations and growth prospects. AnalyStock.ai aims to optimize the investment process, offering a reliable strategy with factors like A-Score, factor investing scores for value, growth, quality, volatility, momentum, and yield. Users can discover hidden gems, fine-tune filters, access company scorecards, perform activity analysis, understand industry dynamics, evaluate capital structure, profitability, and peers' valuation. The application also provides adjustable DCF valuation, portfolio management tools, net asset value computation, monthly commentary, and an AI assistant for personalized insights and assistance.
Sacred
Sacred is a tool to configure, organize, log and reproduce computational experiments. It is designed to introduce only minimal overhead, while encouraging modularity and configurability of experiments. The ability to conveniently make experiments configurable is at the heart of Sacred. If the parameters of an experiment are exposed in this way, it will help you to: keep track of all the parameters of your experiment easily run your experiment for different settings save configurations for individual runs in files or a database reproduce your results In Sacred we achieve this through the following main mechanisms: Config Scopes are functions with a @ex.config decorator, that turn all local variables into configuration entries. This helps to set up your configuration really easily. Those entries can then be used in captured functions via dependency injection. That way the system takes care of passing parameters around for you, which makes using your config values really easy. The command-line interface can be used to change the parameters, which makes it really easy to run your experiment with modified parameters. Observers log every information about your experiment and the configuration you used, and saves them for example to a Database. This helps to keep track of all your experiments. Automatic seeding helps controlling the randomness in your experiments, such that they stay reproducible.
Compassionate AI
Compassionate AI is a cutting-edge AI-powered platform that empowers individuals and organizations to create and deploy AI solutions that are ethical, responsible, and aligned with human values. With Compassionate AI, users can access a comprehensive suite of tools and resources to design, develop, and implement AI systems that prioritize fairness, transparency, and accountability.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

thisorthis.ai
thisorthis.ai is an AI tool that allows users to compare generative AI models and AI model responses. It helps users analyze and evaluate different AI models to make informed decisions. The tool requires JavaScript to be enabled for optimal functionality.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.

Arize AI
Arize AI is an AI Observability & LLM Evaluation Platform that helps you monitor, troubleshoot, and evaluate your machine learning models. With Arize, you can catch model issues, troubleshoot root causes, and continuously improve performance. Arize is used by top AI companies to surface, resolve, and improve their models.

Evidently AI
Evidently AI is an open-source machine learning (ML) monitoring and observability platform that helps data scientists and ML engineers evaluate, test, and monitor ML models from validation to production. It provides a centralized hub for ML in production, including data quality monitoring, data drift monitoring, ML model performance monitoring, and NLP and LLM monitoring. Evidently AI's features include customizable reports, structured checks for data and models, and a Python library for ML monitoring. It is designed to be easy to use, with a simple setup process and a user-friendly interface. Evidently AI is used by over 2,500 data scientists and ML engineers worldwide, and it has been featured in publications such as Forbes, VentureBeat, and TechCrunch.

Maxim
Maxim is an end-to-end AI evaluation and observability platform that empowers modern AI teams to ship products with quality, reliability, and speed. It offers a comprehensive suite of tools for experimentation, evaluation, observability, and data management. Maxim aims to bring the best practices of traditional software development into non-deterministic AI workflows, enabling rapid iteration and deployment of AI models. The platform caters to the needs of AI developers, data scientists, and machine learning engineers by providing a unified framework for evaluation, visual flows for workflow testing, and observability features for monitoring and optimizing AI systems in real-time.

RebeccAi
RebeccAi is an AI-powered business idea evaluation and validation tool that uses AI technology to provide accurate insights into the potential of users' ideas. It helps users refine and improve their ideas quickly and intelligently, acting as a one-person team for their business dreams. From evaluating and assessing business ideas to creating detailed business plans, RebeccAi revolutionizes idea validation with the power of AI.

Codei
Codei is an AI-powered platform designed to help individuals land their dream software engineering job. It offers features such as application tracking, question generation, and code evaluation to assist users in honing their technical skills and preparing for interviews. Codei aims to provide personalized support and insights to help users succeed in the tech industry.
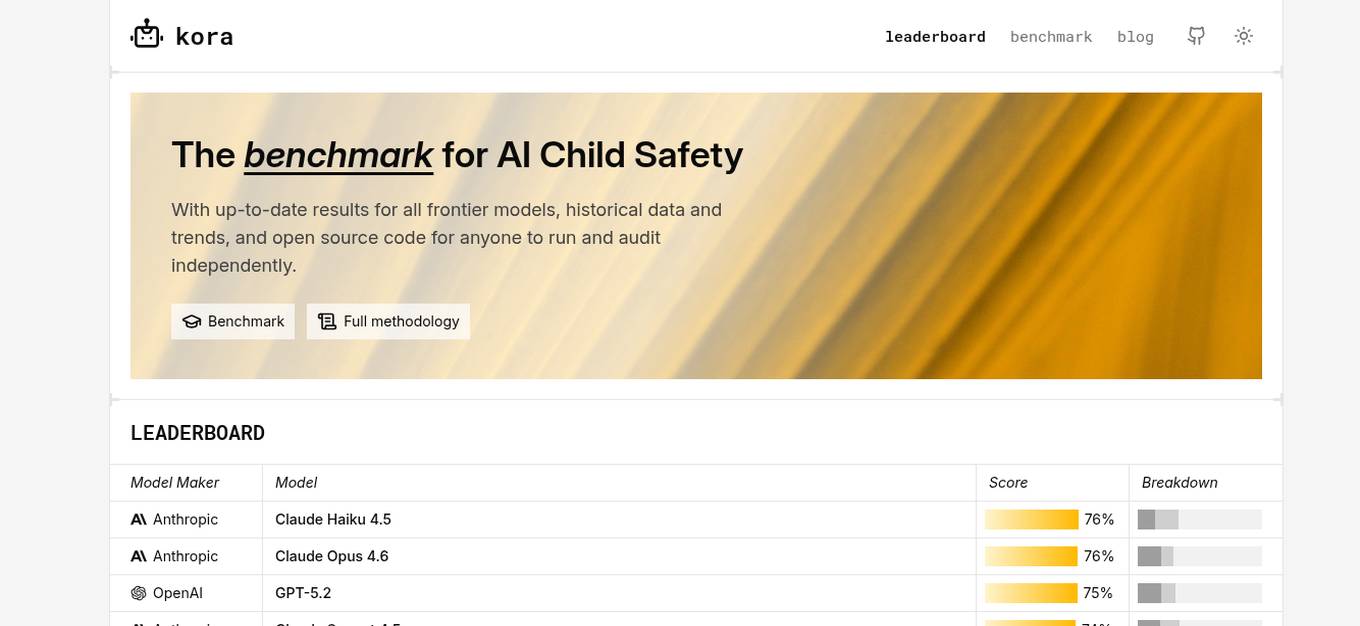
KORA Benchmark
KORA Benchmark is a leading platform that provides a benchmark for AI child safety. It offers up-to-date results for frontier models, historical data, and trends. The platform also provides open-source code for users to run and audit independently. KORA Benchmark aims to ensure the safety of children in the AI landscape by evaluating various models and providing valuable insights to the community.

Brevoir
Brevoir is an AI-powered decision-grade due diligence tool designed for startup investing. It consolidates founder diligence, market and competitor research, risk assessment, and investment-ready writeups in one platform. Tailored for angel investors and startup evaluators, Brevoir streamlines the startup evaluation process by extracting key information from pitch decks or company URLs, verifying claims, mapping competitors, and providing structured reports with risks and opportunities. The tool aims to provide clear answers, identify market trends, evaluate team credibility, assess traction and risks, and offer pricing plans that scale with user needs.
0 - Open Source AI Tools
20 - OpenAI Gpts


Competitive Defensibility Analyzer
Evaluates your long-term market position based on value offered and uniqueness against competitors.
Home Inspector
Upload a picture of your home wall, floor, window, driveway, roof, HVAC, and get an instant opinion.
Innovation YRP
An Innovation & R&D Management advisor who can help you turn ideas into new value creation using over 60 methodologies and tools. Attributed to Yann Rousselot-Pailley https://www.linkedin.com/in/yannrousselot/

Antique and Collectible Appraisal GPT
All-encompassing antique and collectible appraisal assistant offering dollar estimates.


AI Market Analyzer
Analyzes markets, offers predictions on commodities, crypto, and companies.

Rate My {{Startup}}
I will score your Mind Blowing Startup Ideas, helping your to evaluate faster.

Stick to the Point
I'll help you evaluate your writing to make sure it's engaging, informative, and flows well. Uses principles from "Made to Stick"

LabGPT
The main objective of a personalized ChatGPT for reading laboratory tests is to evaluate laboratory test results and create a spreadsheet with the evaluation results and possible solutions.

SearchQualityGPT
As a Search Quality Rater, you will help evaluate search engine quality around the world.

Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model