Best AI tools for< Evaluate Training Effectiveness >
20 - AI tool Sites
edu720
edu720 is a science-backed learning platform that uses AI and nanolearning to redefine how workforces learn and achieve their goals. It provides pre-built learning modules on various topics, including cybersecurity, privacy, and AI ethics. edu720's 360-degree approach ensures that all employees, regardless of their status or location, fully understand and absorb the knowledge conveyed.
Mangus
Mangus is an AI-powered learning platform that provides personalized learning paths for employees and students. It offers a wide range of courses and programs in various disciplines, including business, education, technology, and more. Mangus uses gamification and artificial intelligence to create an engaging and effective learning experience.

SuperAnnotate
SuperAnnotate is an AI data platform that simplifies and accelerates model-building by unifying the AI pipeline. It enables users to create, curate, and evaluate datasets efficiently, leading to the development of better models faster. The platform offers features like connecting any data source, building customizable UIs, creating high-quality datasets, evaluating models, and deploying models seamlessly. SuperAnnotate ensures global security and privacy measures for data protection.

Sereda.ai
Sereda.ai is an AI-powered platform designed to unleash a team's potential by offering solutions for employee knowledge management, surveys, performance reviews, learning, and more. It integrates artificial intelligence to streamline HR processes, improve employee engagement, and boost productivity. The platform provides a user-friendly interface, personalized settings, and automation features to enhance organizational efficiency and reduce costs.
Scale AI
Scale AI is an AI tool that accelerates the development of AI applications for various sectors including enterprise, government, and automotive industries. It offers solutions for training models, fine-tuning, generative AI, and model evaluations. Scale Data Engine and GenAI Platform enable users to leverage enterprise data effectively. The platform collaborates with leading AI models and provides high-quality data for public and private sector applications.
Scale AI
Scale AI is an AI tool that accelerates the development of AI applications for enterprise, government, and automotive sectors. It offers Scale Data Engine for generative AI, Scale GenAI Platform, and evaluation services for model developers. The platform leverages enterprise data to build sustainable AI programs and partners with leading AI models. Scale's focus on generative AI applications, data labeling, and model evaluation sets it apart in the AI industry.
MeritTrac
MeritTrac is an AI-powered testing and assessment solutions provider that offers customized solutions to enterprises and educational institutions. With a content strong and technology-first approach, MeritTrac empowers organizations to make data-driven decisions, enhance talent acquisition, workforce development, and educational assessments. Their AI-powered platforms ensure scalable, secure, and seamless assessment experiences across various domains.
Emocional
Emocional is a platform that helps businesses evaluate, plan, and act to develop their employees' soft skills and promote well-being. It offers a unique personality and soft skills assessment, a personalized action plan, and access to expert training, coaching, therapy, and digital tools like EVA AI.
Outlier AI
Outlier AI is a platform that connects subject matter experts to help build the world's most advanced Generative AI. It allows experts to work on various projects from generating training data to evaluating model performance. The platform offers flexibility, allowing contributors to work from home on their own schedule. Outlier AI aims to redefine how AI learns by leveraging the expertise of domain specialists across different fields.
Entry Point AI
Entry Point AI is a modern AI optimization platform for fine-tuning proprietary and open-source language models. It provides a user-friendly interface to manage prompts, fine-tunes, and evaluations in one place. The platform enables users to optimize models from leading providers, train across providers, work collaboratively, write templates, import/export data, share models, and avoid common pitfalls associated with fine-tuning. Entry Point AI simplifies the fine-tuning process, making it accessible to users without the need for extensive data, infrastructure, or insider knowledge.
Yogger
Yogger is an AI-powered video analysis and movement assessment tool designed for coaches, trainers, physical therapists, and athletes. It allows users to track form, gather data, and analyze movement for any sport or activity in seconds. With AI-powered screenings, users can get instant scores and insights whether training in person or online. Yogger helps in recovery, training enhancement, and injury prevention, all accessible from a mobile device.
Chemprop
Chemprop is a PyTorch-based framework for training and evaluating message-passing neural networks (MPNNs) for molecular property prediction. Originally developed for research purposes, Chemprop offers a comprehensive set of tools and features for training models and analyzing molecular representations. The package underwent a recent major release (v2.0.0) with significant improvements and updates.
Welo Data
Welo Data is an AI tool that specializes in AI benchmarking, model assessment, and training high-quality datasets for AI models. The platform offers services such as supervised fine tuning, reinforcement learning with human feedback, data generation, expert evaluations, and data quality framework to support the development of world-class AI models. With over 27 years of experience, Welo Data combines language expertise and AI data to deliver exceptional training and performance evaluation solutions.
Labelbox
Labelbox is a data factory platform that empowers AI teams to manage data labeling, train models, and create better data with internet scale RLHF platform. It offers an all-in-one solution comprising tooling and services powered by a global community of domain experts. Labelbox operates a global data labeling infrastructure and operations for AI workloads, providing expert human network for data labeling in various domains. The platform also includes AI-assisted alignment for maximum efficiency, data curation, model training, and labeling services. Customers achieve breakthroughs with high-quality data through Labelbox.
ParallelDots
ParallelDots is a next-generation retail execution software powered by image recognition technology. The software offers solutions like ShelfWatch, Saarthi, and SmartGaze to enhance the efficiency of sales reps and merchandisers, provide faster training of image recognition models, and offer automated gaze-coding solutions for mobile and retail eye-tracking research. ParallelDots' computer vision technology helps CPG and retail brands track in-store compliance, address gaps in retail execution, and gain real-time insights into brand performance. The platform enables users to generate real-time KPI insights, evaluate compliance levels, convert insights into actionable strategies, and integrate computer vision with existing retail solutions seamlessly.
TractoAI
TractoAI is an advanced AI platform that offers deep learning solutions for various industries. It provides Batch Inference with no rate limits, DeepSeek offline inference, and helps in training open source AI models. TractoAI simplifies training infrastructure setup, accelerates workflows with GPUs, and automates deployment and scaling for tasks like ML training and big data processing. The platform supports fine-tuning models, sandboxed code execution, and building custom AI models with distributed training launcher. It is developer-friendly, scalable, and efficient, offering a solution library and expert guidance for AI projects.
micro1
micro1 is an AI recruitment tool that leverages human data produced by subject matter experts to help companies identify and hire top talent efficiently. The platform offers end-to-end post-training solutions, high-quality data for model training, pre-vetted AI trainers, and enterprise-grade LLM evaluations. With a focus on tech startups, staffing agencies, and enterprises, micro1 aims to streamline the recruitment process and save costs for businesses.
Datumbox
Datumbox is a machine learning platform that offers a powerful open-source Machine Learning Framework written in Java. It provides a large collection of algorithms, models, statistical tests, and tools to power up intelligent applications. The platform enables developers to build smart software and services quickly using its REST Machine Learning API. Datumbox API offers off-the-shelf Classifiers and Natural Language Processing services for applications like Sentiment Analysis, Topic Classification, Language Detection, and more. It simplifies the process of designing and training Machine Learning models, making it easy for developers to create innovative applications.
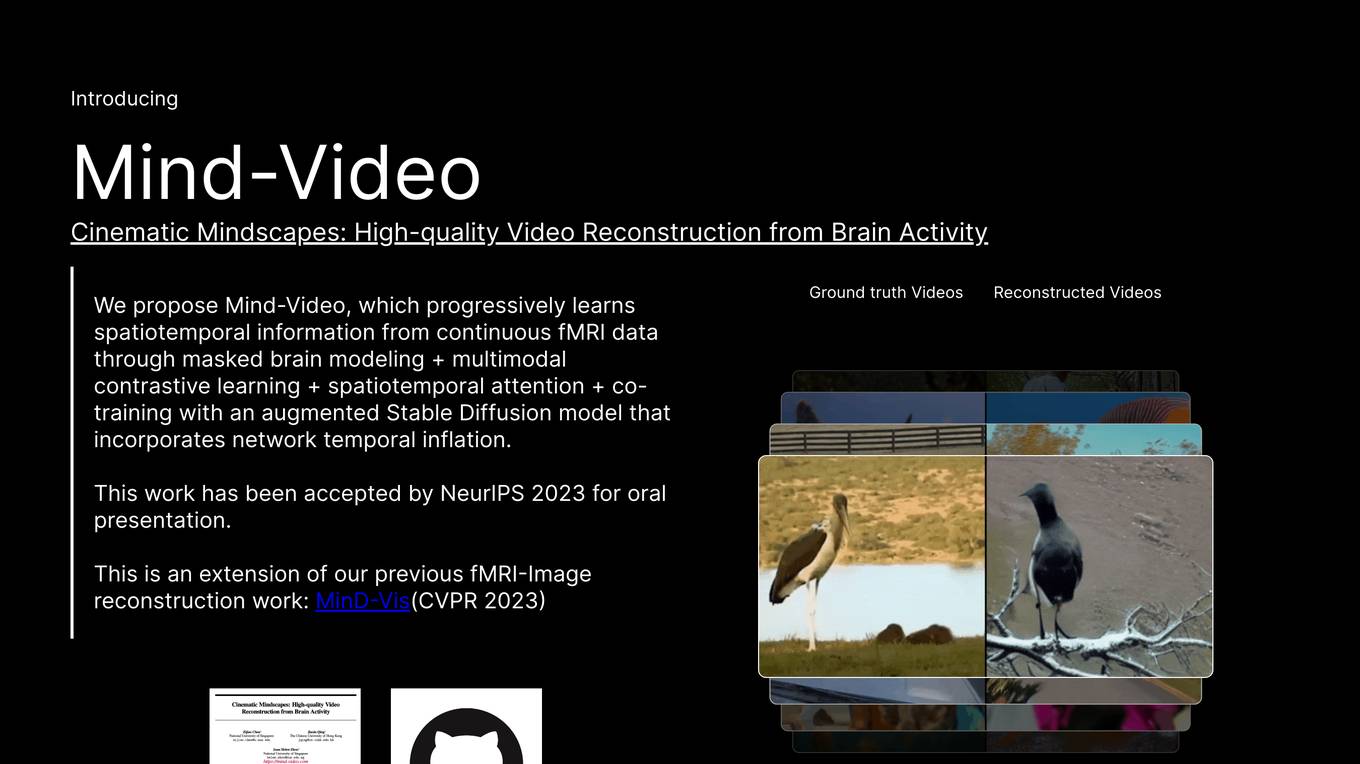
Mind-Video
Mind-Video is an AI tool that focuses on high-quality video reconstruction from brain activity data. It bridges the gap between image and video brain decoding by utilizing masked brain modeling, multimodal contrastive learning, spatiotemporal attention, and co-training with an augmented Stable Diffusion model. The tool aims to recover accurate semantic information from fMRI signals, enabling the generation of realistic videos based on brain activities.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.
0 - Open Source AI Tools
20 - OpenAI Gpts
Pocket Training Activity Expert
Expert in engaging, interactive training methods and activities.

Training Material Design Advisor
Designs effective training materials to enhance organizational learning and performance.

Corporate Trainer
Develops training programs, customizing content to fit corporate culture and objectives.
Diseñando Experiencias de Formación
Asistente especializado en diseño y planificación de formación profesional

HCDP - برنامج تنمية القدرات البشرية
خبير يقدم لك المعلومات حول برنامج تنمية القدرات البشرية (Human Capability Development Program) أحد برامج رؤية المملكة 2030 والذي يهدف إلى بناء استراتيجية وطنية طموحة لتنمية قدرات المواطن
Learning & Development Advisor
Enhances organizational performance through employee learning and development initiatives.

Skills Development Advisor
Enhances organizational performance through strategic skills development initiatives.


E-Learning Development Advisor
Enhances corporate training through innovative e-learning solutions.
Policy Communication Advisor
Communicates policy processes and changes effectively within the organization.

Vorstellungsgespräch Simulator Bewerbung Training
Wertet Lebenslauf und Stellenanzeige aus und simuliert ein Vorstellungsgespräch mit anschließender Auswertung: Lebenslauf und Anzeige einfach hochladen und starten.

Emergency Training
Provides emergency training assistance with a focus on safety and clear guidelines.
Wordon, World's Worst Customer | Divergent AI
I simulate tough Customer Support scenarios for Agent Training.

Learning Experience Designer™
A Learning Experience Designer (LXD) - in support of LXDs and those who work with them.