Best AI tools for< Evaluate Research >
20 - AI tool Sites
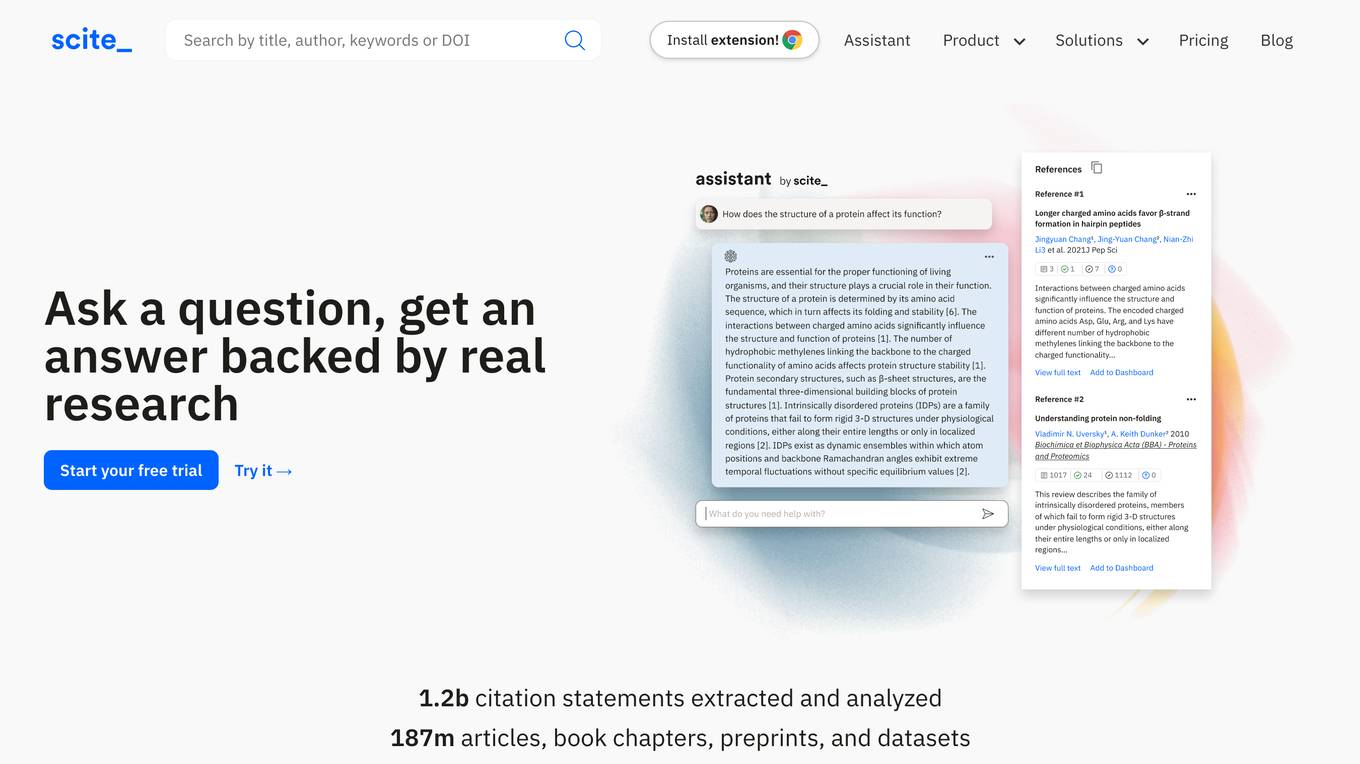
Scite
Scite is an award-winning platform for discovering and evaluating scientific articles via Smart Citations. Smart Citations allow users to see how a publication has been cited by providing the context of the citation and a classification describing whether it provides supporting or contrasting evidence for the cited claim.

Machine Translation Research Hub
This website is a comprehensive resource for research in statistical and neural machine translation. It provides information, tools, and datasets related to the translation of text from one human language to another using computer algorithms trained on vast amounts of translated text.

thisorthis.ai
thisorthis.ai is an AI tool that allows users to compare generative AI models and AI model responses. It helps users analyze and evaluate different AI models to make informed decisions. The tool requires JavaScript to be enabled for optimal functionality.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.

Arize AI
Arize AI is an AI Observability & LLM Evaluation Platform that helps you monitor, troubleshoot, and evaluate your machine learning models. With Arize, you can catch model issues, troubleshoot root causes, and continuously improve performance. Arize is used by top AI companies to surface, resolve, and improve their models.
Web3 Summary
Web3 Summary is an AI-powered platform that simplifies on-chain research across multiple chains and protocols, helping users find trading alpha in the DeFi and NFT space. It offers a range of products including a trading terminal, wallet study tool, Discord bot, mobile app, and Chrome extension. The platform aims to streamline the process of understanding complex crypto projects and tokenomics using AI and ChatGPT technology.
Prolific
Prolific is a platform that allows users to quickly find research participants they can trust. It offers a diverse participant pool, including domain experts and API integration. Prolific ensures high-quality human-powered datasets in less than 2 hours, trusted by over 3000 organizations. The platform is designed for ease of use, with self-serve options and scalability. It provides rich, accurate, and comprehensive responses from engaged participants, verified through manual and algorithmic quality checks.
AI Tools Masters
AI Tools Masters is a comprehensive platform that empowers users to discover and evaluate the latest and most exceptional AI tools. Catering to diverse needs, from education to personal advancement, AI Tools Masters offers a curated collection of top-notch solutions tailored to specific requirements. With a user-friendly interface and extensive filtering options, users can effortlessly navigate through a wide range of AI tools, ensuring they find the perfect fit for their projects and goals.

Maxim
Maxim is an end-to-end AI evaluation and observability platform that empowers modern AI teams to ship products with quality, reliability, and speed. It offers a comprehensive suite of tools for experimentation, evaluation, observability, and data management. Maxim aims to bring the best practices of traditional software development into non-deterministic AI workflows, enabling rapid iteration and deployment of AI models. The platform caters to the needs of AI developers, data scientists, and machine learning engineers by providing a unified framework for evaluation, visual flows for workflow testing, and observability features for monitoring and optimizing AI systems in real-time.

PubCompare
PubCompare is a powerful AI-powered tool that helps scientists search, compare, and evaluate experimental protocols. With over 40 million protocols in its database, PubCompare is the largest repository of trusted experimental protocols. PubCompare's AI-powered search features allow users to find similar protocols, highlight critical steps, and evaluate the reproducibility of protocols based on in-protocol citations. PubCompare is available from any computer and requires no download.

FinetuneDB
FinetuneDB is an AI fine-tuning platform that allows users to easily create and manage datasets to fine-tune LLMs, evaluate outputs, and iterate on production data. It integrates with open-source and proprietary foundation models, and provides a collaborative editor for building datasets. FinetuneDB also offers a variety of features for evaluating model performance, including human and AI feedback, automated evaluations, and model metrics tracking.
InstantPersonas
InstantPersonas is an AI-powered SWOT Analysis Generator that helps organizations and individuals evaluate their Strengths, Weaknesses, Opportunities, and Threats. By using a company description, the tool generates a comprehensive SWOT Analysis, providing insights for strategic planning. Users can edit the analysis and download it as an image. InstantPersonas aims to assist in understanding target audience and market for more successful marketing strategies.
Entry Point AI
Entry Point AI is a modern AI optimization platform for fine-tuning proprietary and open-source language models. It provides a user-friendly interface to manage prompts, fine-tunes, and evaluations in one place. The platform enables users to optimize models from leading providers, train across providers, work collaboratively, write templates, import/export data, share models, and avoid common pitfalls associated with fine-tuning. Entry Point AI simplifies the fine-tuning process, making it accessible to users without the need for extensive data, infrastructure, or insider knowledge.
Athina AI
Athina AI is a platform that provides research and guides for building safe and reliable AI products. It helps thousands of AI engineers in building safer products by offering tutorials, research papers, and evaluation techniques related to large language models. The platform focuses on safety, prompt engineering, hallucinations, and evaluation of AI models.
AI Alliance
The AI Alliance is a community dedicated to building and advancing open-source AI agents, data, models, evaluation, safety, applications, and advocacy to ensure everyone can benefit. They focus on various areas such as skills and education, trust and safety, applications and tools, hardware enablement, foundation models, and advocacy. The organization supports global AI skill-building, education, and exploratory research, creates benchmarks and tools for safe generative AI, builds capable tools for AI model builders and developers, fosters AI hardware accelerator ecosystem, enables open foundation models and datasets, and advocates for regulatory policies for healthy AI ecosystems.

AI Security Institute (AISI)
The AI Security Institute (AISI) is a state-backed organization dedicated to advancing AI governance and safety. They conduct rigorous AI research to understand the impacts of advanced AI, develop risk mitigations, and collaborate with AI developers and governments to shape global policymaking. The institute aims to equip governments with a scientific understanding of the risks posed by advanced AI, monitor AI development, evaluate national security risks, and promote responsible AI development. With a team of top technical staff and partnerships with leading research organizations, AISI is at the forefront of AI governance.
OpinioAI
OpinioAI is an AI-powered market research tool that allows users to gain business critical insights from data without the need for costly polls, surveys, or interviews. With OpinioAI, users can create AI personas and market segments to understand customer preferences, affinities, and opinions. The platform democratizes research by providing efficient, effective, and budget-friendly solutions for businesses, students, and individuals seeking valuable insights. OpinioAI leverages Large Language Models to simulate humans and extract opinions in detail, enabling users to analyze existing data, synthesize new insights, and evaluate content from the perspective of their target audience.
Stanford HAI
Stanford HAI is a research institute at Stanford University dedicated to advancing AI research, education, and policy to improve the human condition. The institute brings together researchers from a variety of disciplines to work on a wide range of AI-related projects, including developing new AI algorithms, studying the ethical and societal implications of AI, and creating educational programs to train the next generation of AI leaders. Stanford HAI is committed to developing human-centered AI technologies and applications that benefit all of humanity.
Athina AI Hub
Athina AI Hub is an ultimate resource for AI development teams, offering a wide range of AI development blogs, research papers, and original content. It provides valuable insights into cutting-edge technologies such as Large Language Models (LLMs), Retrieval-Augmented Generation (RAG), and AI agents. Athina AI Hub aims to empower AI engineers, researchers, data scientists, and product developers by offering comprehensive resources and fostering innovation in the field of Artificial Intelligence.
0 - Open Source AI Tools
20 - OpenAI Gpts
Eureka Research Assessment and Improvement
AI tool for self-evaluating and enhancing scientific research capabilities.

Scientific Insight
Scientific expert in evaluating articles using ROBINS-I and Cochrane tools


I4T Assessor - UNESCO Tech Platform Trust Helper
Helps you evaluate whether or not tech platforms match UNESCO's Internet for Trust Guidelines for the Governance of Digital Platforms
Long Market Research Analyst
AI for Business of Market Research Analyst (chuyên gia Phân tích Thị trường với 33 năm kinh nghiệm trong lĩnh vực tiếp thị.)


LabGPT
The main objective of a personalized ChatGPT for reading laboratory tests is to evaluate laboratory test results and create a spreadsheet with the evaluation results and possible solutions.

Product Improvement Research Advisor
Improves product quality through innovative research and development.

Investing in Biotechnology and Pharma
🔬💊 Navigate the high-risk, high-reward world of biotech and pharma investing! Discover breakthrough therapies 🧬📈, understand drug development 🧪📊, and evaluate investment opportunities 🚀💰. Invest wisely in innovation! 💡🌐 Not a financial advisor. 🚫💼

AnalyzePaper
Takes in a research paper or article, analyzes its claims, study quality, and results confidence and provides an easy to understand summary.

Mixed Methods Design Decision Tool
I'm the Mixed Methods Design Decision Tool, offering guidance on mixed methods research designs, their implementation, and effective communication in studies.

News Authenticator
Professional news analysis expert, verifying article authenticity with in-depth research and unbiased evaluation.