Best AI tools for< Evaluate Prompt Injections >
20 - AI tool Sites

DeepTeam
DeepTeam by Confident AI is an AI-powered red teaming framework designed to detect over 40 LLM vulnerabilities automatically. It offers state-of-the-art adversarial attacks like prompt injections and gray box techniques to jailbreak LLMs. The framework includes OWASP Top 10 for LLMs, NIST AI, and comprehensive documentation to guide users in evaluating and enhancing the safety of their models. DeepTeam fosters a vibrant red teaming community through GitHub, Discord, and newsletters, empowering users to stay updated on the latest advancements in AI security.

thisorthis.ai
thisorthis.ai is an AI tool that allows users to compare generative AI models and AI model responses. It helps users analyze and evaluate different AI models to make informed decisions. The tool requires JavaScript to be enabled for optimal functionality.
Weavel
Weavel is an AI tool designed to revolutionize prompt engineering for large language models (LLMs). It offers features such as tracing, dataset curation, batch testing, and evaluations to enhance the performance of LLM applications. Weavel enables users to continuously optimize prompts using real-world data, prevent performance regression with CI/CD integration, and engage in human-in-the-loop interactions for scoring and feedback. Ape, the AI prompt engineer, outperforms competitors on benchmark tests and ensures seamless integration and continuous improvement specific to each user's use case. With Weavel, users can effortlessly evaluate LLM applications without the need for pre-existing datasets, streamlining the assessment process and enhancing overall performance.
Agenta.ai
Agenta.ai is a platform designed to provide prompt management, evaluation, and observability for LLM (Large Language Model) applications. It aims to address the challenges faced by AI development teams in managing prompts, collaborating effectively, and ensuring reliable product outcomes. By centralizing prompts, evaluations, and traces, Agenta.ai helps teams streamline their workflows and follow best practices in LLMOps. The platform offers features such as unified playground for prompt comparison, automated evaluation processes, human evaluation integration, observability tools for debugging AI systems, and collaborative workflows for PMs, experts, and developers.
Cakewalk AI
Cakewalk AI is an AI-powered platform designed to enhance team productivity by leveraging the power of ChatGPT and automation tools. It offers features such as team workspaces, prompt libraries, automation with prebuilt templates, and the ability to combine documents, images, and URLs. Users can automate tasks like updating product roadmaps, creating user personas, evaluating resumes, and more. Cakewalk AI aims to empower teams across various departments like Product, HR, Marketing, and Legal to streamline their workflows and improve efficiency.
Inspect
Inspect is an open-source framework for large language model evaluations created by the UK AI Safety Institute. It provides built-in components for prompt engineering, tool usage, multi-turn dialog, and model graded evaluations. Users can explore various solvers, tools, scorers, datasets, and models to create advanced evaluations. Inspect supports extensions for new elicitation and scoring techniques through Python packages.
Athina AI
Athina AI is a platform that provides research and guides for building safe and reliable AI products. It helps thousands of AI engineers in building safer products by offering tutorials, research papers, and evaluation techniques related to large language models. The platform focuses on safety, prompt engineering, hallucinations, and evaluation of AI models.

Lisapet.AI
Lisapet.AI is an AI prompt testing suite designed for product teams to streamline the process of designing, prototyping, testing, and shipping AI features. It offers a comprehensive platform with features like best-in-class AI playground, variables for dynamic data inputs, structured outputs, side-by-side editing, function calling, image inputs, assertions & metrics, performance comparison, data sets organization, shareable reports, comments & feedback, token & cost stats, and more. The application aims to help teams save time, improve efficiency, and ensure the reliability of AI features through automated prompt testing.
Athina AI
Athina AI is a comprehensive platform designed to monitor, debug, analyze, and improve the performance of Large Language Models (LLMs) in production environments. It provides a suite of tools and features that enable users to detect and fix hallucinations, evaluate output quality, analyze usage patterns, and optimize prompt management. Athina AI supports integration with various LLMs and offers a range of evaluation metrics, including context relevancy, harmfulness, summarization accuracy, and custom evaluations. It also provides a self-hosted solution for complete privacy and control, a GraphQL API for programmatic access to logs and evaluations, and support for multiple users and teams. Athina AI's mission is to empower organizations to harness the full potential of LLMs by ensuring their reliability, accuracy, and alignment with business objectives.
Teammately
Teammately is an AI tool that redefines how Human AI-Engineers build AI. It is an Agentic AI for AI development process, designed to enable Human AI-Engineers to focus on more creative and productive missions in AI development. Teammately follows the best practices of Human LLM DevOps and offers features like Development Prompt Engineering, Knowledge Tuning, Evaluation, and Optimization to assist in the AI development process. The tool aims to revolutionize AI engineering by allowing AI AI-Engineers to handle technical tasks, while Human AI-Engineers focus on planning and aligning AI with human preferences and requirements.

Ottic
Ottic is an AI tool designed to empower both technical and non-technical teams to test Language Model (LLM) applications efficiently and accelerate the development cycle. It offers features such as a 360º view of the QA process, end-to-end test management, comprehensive LLM evaluation, and real-time monitoring of user behavior. Ottic aims to bridge the gap between technical and non-technical team members, ensuring seamless collaboration and reliable product delivery.
Entry Point AI
Entry Point AI is a modern AI optimization platform for fine-tuning proprietary and open-source language models. It provides a user-friendly interface to manage prompts, fine-tunes, and evaluations in one place. The platform enables users to optimize models from leading providers, train across providers, work collaboratively, write templates, import/export data, share models, and avoid common pitfalls associated with fine-tuning. Entry Point AI simplifies the fine-tuning process, making it accessible to users without the need for extensive data, infrastructure, or insider knowledge.
DeepEval
DeepEval by Confident AI is a comprehensive LLM Evaluation Framework used by leading AI companies. It enables users to build reliable evaluation pipelines to test any AI system. With 50+ research-backed metrics, native multi-modal support, and auto-optimization of prompts, DeepEval offers a sophisticated evaluation ecosystem for AI applications. The framework covers unit-testing for LLMs, single and multi-turn evaluations, generation & simulation of test data, and state-of-the-art evaluation techniques like G-Eval and DAG. DeepEval is integrated with Pytest and supports various system architectures, making it a versatile tool for AI testing.
Outlier AI
Outlier AI is a platform that connects subject matter experts to help build the world's most advanced Generative AI. It allows experts to work on various projects from generating training data to evaluating model performance. The platform offers flexibility, allowing contributors to work from home on their own schedule. Outlier AI aims to redefine how AI learns by leveraging the expertise of domain specialists across different fields.
Coval
Coval is an AI tool designed to help users ship reliable AI agents faster by providing simulation and evaluations for voice and chat agents. It allows users to simulate thousands of scenarios from a few test cases, create prompts for testing, and evaluate agent interactions comprehensively. Coval offers AI-powered simulations, voice AI compatibility, performance tracking, workflow metrics, and customizable evaluation metrics to optimize AI agents efficiently.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.

Arize AI
Arize AI is an AI Observability & LLM Evaluation Platform that helps you monitor, troubleshoot, and evaluate your machine learning models. With Arize, you can catch model issues, troubleshoot root causes, and continuously improve performance. Arize is used by top AI companies to surface, resolve, and improve their models.

Evidently AI
Evidently AI is an open-source machine learning (ML) monitoring and observability platform that helps data scientists and ML engineers evaluate, test, and monitor ML models from validation to production. It provides a centralized hub for ML in production, including data quality monitoring, data drift monitoring, ML model performance monitoring, and NLP and LLM monitoring. Evidently AI's features include customizable reports, structured checks for data and models, and a Python library for ML monitoring. It is designed to be easy to use, with a simple setup process and a user-friendly interface. Evidently AI is used by over 2,500 data scientists and ML engineers worldwide, and it has been featured in publications such as Forbes, VentureBeat, and TechCrunch.

Maxim
Maxim is an end-to-end AI evaluation and observability platform that empowers modern AI teams to ship products with quality, reliability, and speed. It offers a comprehensive suite of tools for experimentation, evaluation, observability, and data management. Maxim aims to bring the best practices of traditional software development into non-deterministic AI workflows, enabling rapid iteration and deployment of AI models. The platform caters to the needs of AI developers, data scientists, and machine learning engineers by providing a unified framework for evaluation, visual flows for workflow testing, and observability features for monitoring and optimizing AI systems in real-time.
1 - Open Source AI Tools
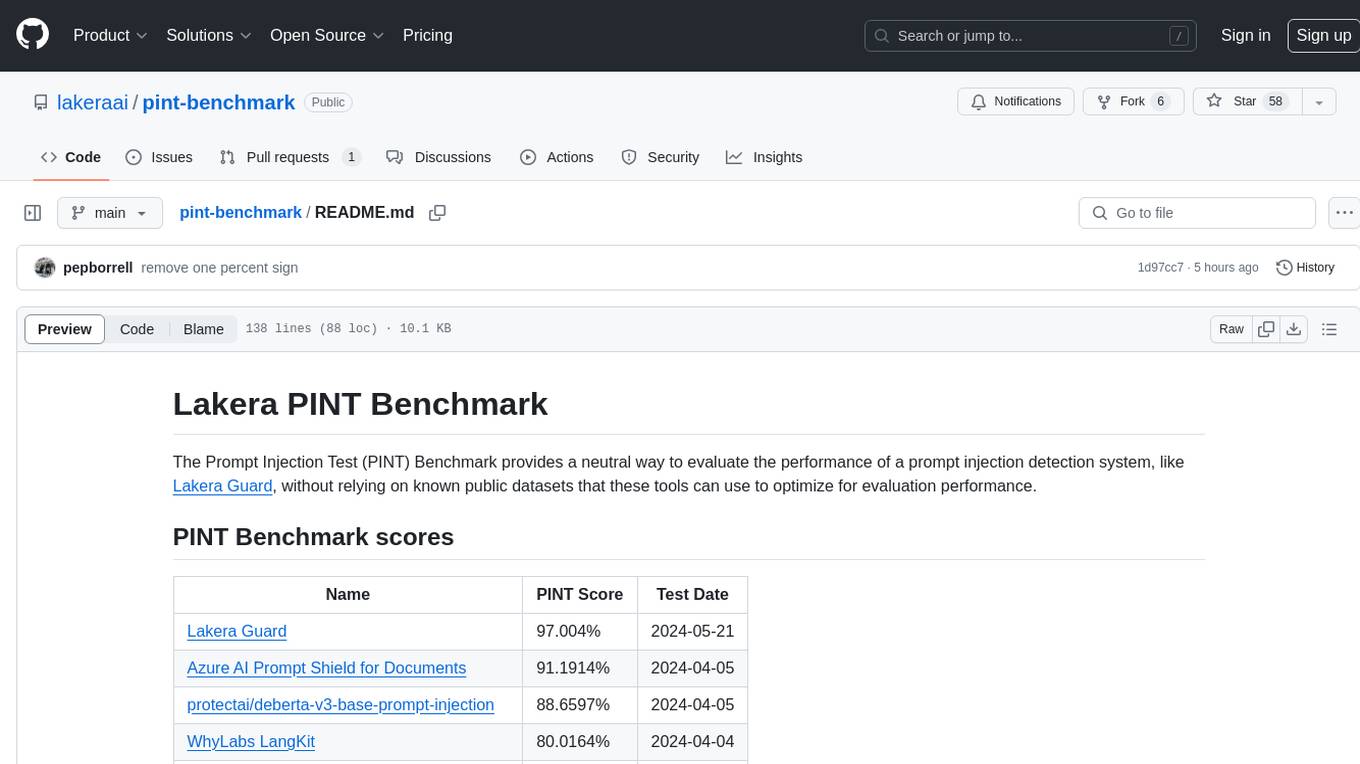
pint-benchmark
The Lakera PINT Benchmark provides a neutral evaluation method for prompt injection detection systems, offering a dataset of English inputs with prompt injections, jailbreaks, benign inputs, user-agent chats, and public document excerpts. The dataset is designed to be challenging and representative, with plans for future enhancements. The benchmark aims to be unbiased and accurate, welcoming contributions to improve prompt injection detection. Users can evaluate prompt injection detection systems using the provided Jupyter Notebook. The dataset structure is specified in YAML format, allowing users to prepare their datasets for benchmarking. Evaluation examples and resources are provided to assist users in evaluating prompt injection detection models and tools.
20 - OpenAI Gpts
Essay Prompt Generator
K12 assessment expert, creating grade-level appropriate essay prompts.
Finance Wizard
I predict future stock market prices. AI analyst. Your trading analysis assistant. Press H to bring up prompt hot key menu. Not financial advice.
GPT Designer
A creative aide for designing new GPT models, skilled in ideation and prompting.

Rate My {{Startup}}
I will score your Mind Blowing Startup Ideas, helping your to evaluate faster.

Stick to the Point
I'll help you evaluate your writing to make sure it's engaging, informative, and flows well. Uses principles from "Made to Stick"

LabGPT
The main objective of a personalized ChatGPT for reading laboratory tests is to evaluate laboratory test results and create a spreadsheet with the evaluation results and possible solutions.

SearchQualityGPT
As a Search Quality Rater, you will help evaluate search engine quality around the world.

Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model


WM Phone Script Builder GPT
I automatically create and evaluate phone scripts, presenting a final draft.

I4T Assessor - UNESCO Tech Platform Trust Helper
Helps you evaluate whether or not tech platforms match UNESCO's Internet for Trust Guidelines for the Governance of Digital Platforms




Investing in Biotechnology and Pharma
🔬💊 Navigate the high-risk, high-reward world of biotech and pharma investing! Discover breakthrough therapies 🧬📈, understand drug development 🧪📊, and evaluate investment opportunities 🚀💰. Invest wisely in innovation! 💡🌐 Not a financial advisor. 🚫💼

B2B Startup Ideal Customer Co-pilot
Guides B2B startups in a structured customer segment evaluation process. Stop guessing! Ideate, Evaluate & Make data-driven decision.

Education AI Strategist
I provide a structured way of using AI to support teaching and learning. I use the the CHOICE method (i.e., Clarify, Harness, Originate, Iterate, Communicate, Evaluate) to ensure that your use of AI can help you meet your educational goals.

Competitive Defensibility Analyzer
Evaluates your long-term market position based on value offered and uniqueness against competitors.