Best AI tools for< Evaluate Information >
20 - AI tool Sites
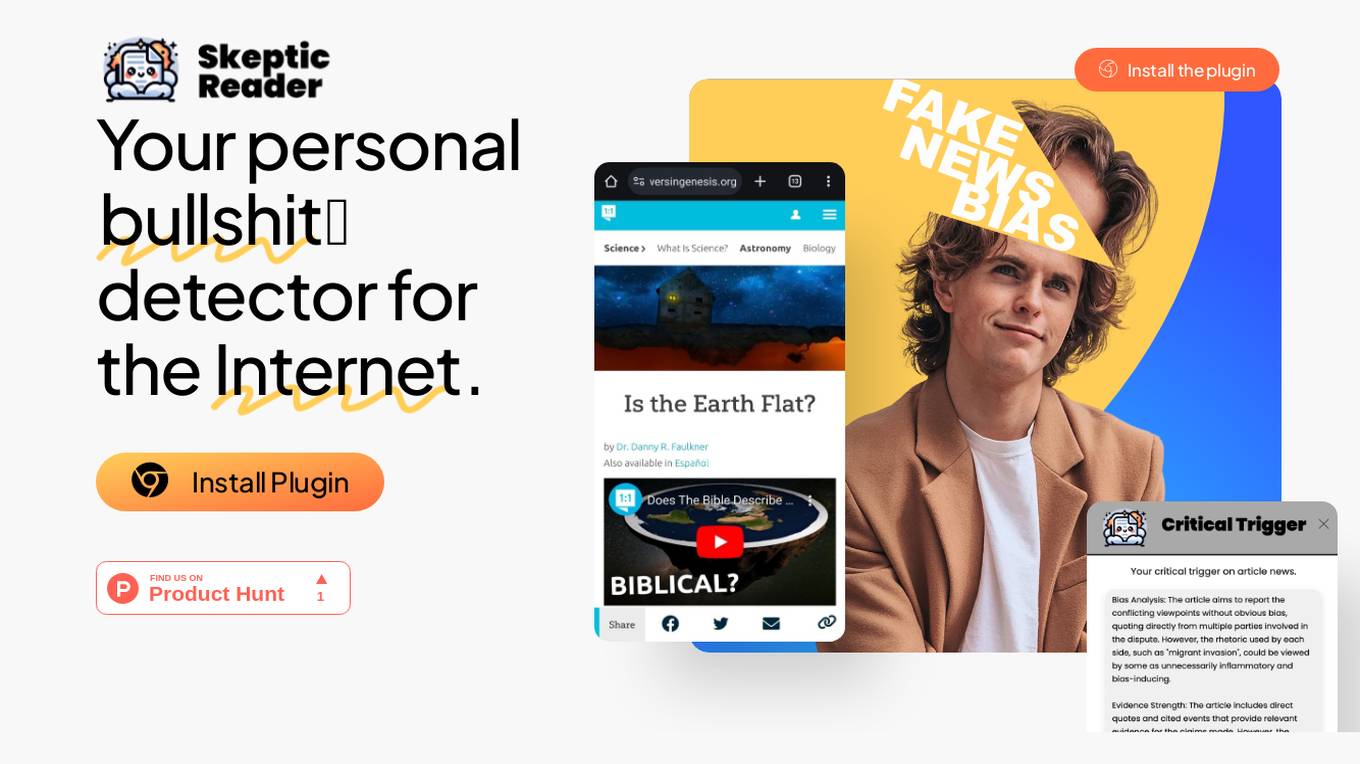
Skeptic Reader
Skeptic Reader is a Chrome plugin that detects biases and logical fallacies in real-time. It's powered by GPT4 and helps users to critically evaluate the information they consume online. The plugin highlights biases and fallacies, provides counter-arguments, and suggests alternative perspectives. It's designed to promote informed skepticism and encourage users to question the information they encounter online.
JudgeAI
JudgeAI is an AI tool designed to assist users in making judgments or decisions. It utilizes artificial intelligence algorithms to analyze data and provide insights. The tool helps users in evaluating information and reaching conclusions based on the input data. JudgeAI aims to streamline decision-making processes and enhance accuracy by leveraging AI technology.
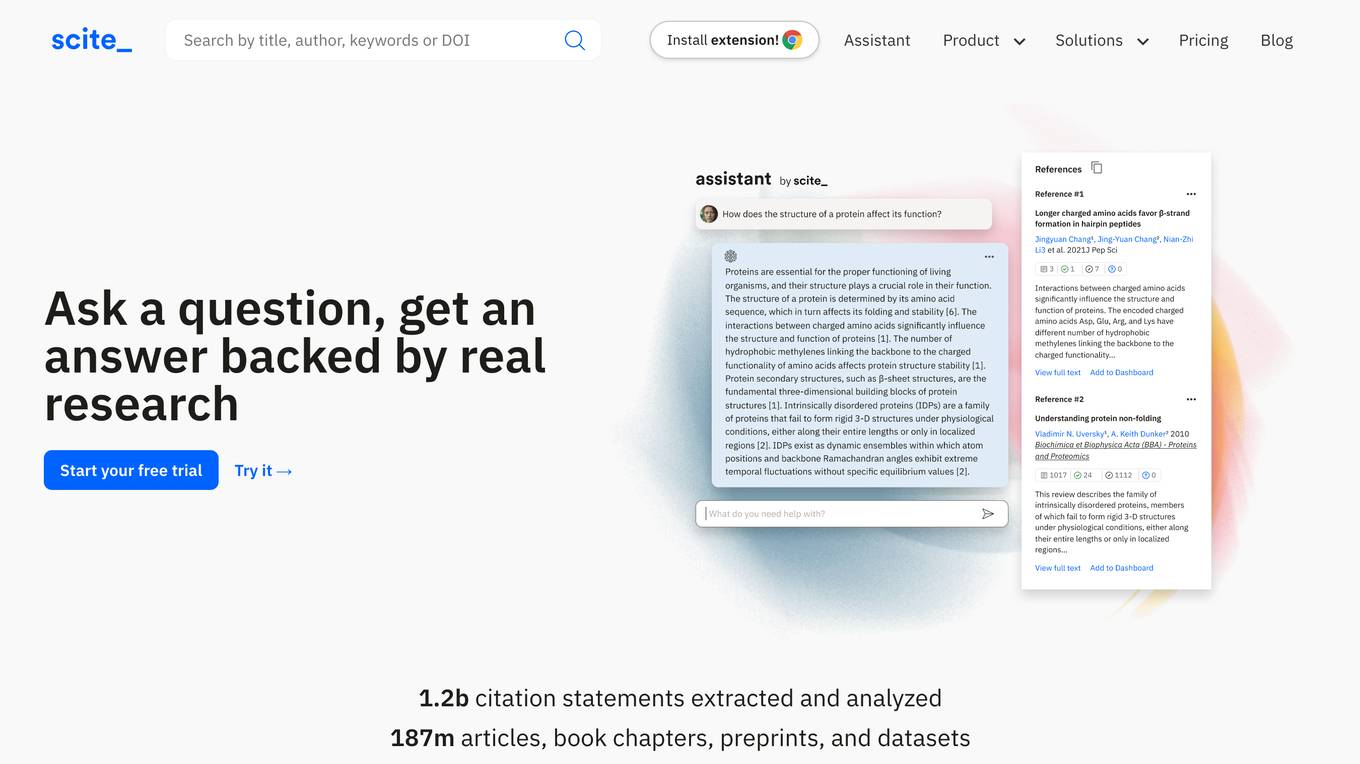
Scite
Scite is an award-winning platform for discovering and evaluating scientific articles via Smart Citations. Smart Citations allow users to see how a publication has been cited by providing the context of the citation and a classification describing whether it provides supporting or contrasting evidence for the cited claim.
Legal Benchmarks
Legal Benchmarks is a platform that provides independent lawyer-led AI evaluations for in-house legal work in the legal industry. The platform evaluates AI assistants on critical legal tasks like contract drafting and information extraction. It offers rankings based on how different AI tools perform on real-world legal tasks, helping legal teams understand and adopt AI solutions. Legal Benchmarks also allows legal AI vendors to submit their tools for evaluation and provides access to customized private reports, insights, and practical breakdowns of AI tools' performance.
BS Detector
BS Detector is an AI tool designed to help users determine the credibility of information by analyzing text or images for misleading or false content. Users can input a link, upload a screenshot, or paste text to receive a BS (Bullshit) rating. The tool leverages AI algorithms to assess the accuracy and truthfulness of the provided content, offering users a quick and efficient way to identify potentially deceptive information.
Vals AI
Vals AI is an advanced AI tool that provides benchmark reports and comparisons for various models in the fields of finance, coding, and law. The platform offers insights into the performance of different AI models across different tasks and industries. Vals AI aims to bridge the gap in model benchmarking and provide valuable information for users looking to evaluate and compare AI models for specific tasks.
Sourcer AI
Sourcer AI is an AI-powered fact-checking tool that provides real-time assessments of source credibility and bias in online information. It revolutionizes the evaluation process by using cutting-edge artificial intelligence to uncover reputability ratings and political biases of online sources, helping users combat misinformation and make informed decisions.

Skeptic Reader
Skeptic Reader is a Chrome plugin that helps users detect bias and logical fallacies in real-time while browsing the internet. It uses GPT-4 technology to identify potential biases and fallacies in news articles, social media posts, and other online content. The plugin provides users with counter-arguments and suggestions for further research, helping them to make more informed decisions about the information they consume. Skeptic Reader is designed to promote critical thinking and media literacy, and it is a valuable tool for anyone who wants to navigate the online world with a more discerning eye.
Q, ChatGPT for Slack
The website offers 'Q, ChatGPT for Slack', an AI tool that functions like ChatGPT within your Slack workspace. It allows on-demand URL and file reading, custom instructions for tailored use, and supports various URLs and files. With Q, users can summarize, evaluate, brainstorm ideas, self-review, engage in Q&A, and more. The tool enables team-specific rules, guidelines, and templates, making it ideal for emails, translations, content creation, copywriting, reporting, coding, and testing based on internal information.

Machine Translation Research Hub
This website is a comprehensive resource for research in statistical and neural machine translation. It provides information, tools, and datasets related to the translation of text from one human language to another using computer algorithms trained on vast amounts of translated text.
Sacred
Sacred is a tool to configure, organize, log and reproduce computational experiments. It is designed to introduce only minimal overhead, while encouraging modularity and configurability of experiments. The ability to conveniently make experiments configurable is at the heart of Sacred. If the parameters of an experiment are exposed in this way, it will help you to: keep track of all the parameters of your experiment easily run your experiment for different settings save configurations for individual runs in files or a database reproduce your results In Sacred we achieve this through the following main mechanisms: Config Scopes are functions with a @ex.config decorator, that turn all local variables into configuration entries. This helps to set up your configuration really easily. Those entries can then be used in captured functions via dependency injection. That way the system takes care of passing parameters around for you, which makes using your config values really easy. The command-line interface can be used to change the parameters, which makes it really easy to run your experiment with modified parameters. Observers log every information about your experiment and the configuration you used, and saves them for example to a Database. This helps to keep track of all your experiments. Automatic seeding helps controlling the randomness in your experiments, such that they stay reproducible.
Valuemetrix
Valuemetrix is an AI-enhanced investment analysis platform designed for investors seeking to redefine their investment journey. The platform offers cutting-edge AI technology, institutional-level data, and expert analysis to provide users with well-informed investment decisions. Valuemetrix empowers users to elevate their investment experience through AI-driven insights, real-time market news, stock reports, market analysis, and tailored financial information for over 100,000 international publicly traded companies.
YellowGoose
YellowGoose is an AI tool that offers intelligent analysis of resumes. It utilizes advanced algorithms to extract and analyze key information from resumes, helping users to streamline the recruitment process. With YellowGoose, users can quickly evaluate candidates and make informed hiring decisions based on data-driven insights.
CloudExam AI
CloudExam AI is an online testing platform developed by Hanke Numerical Union Technology Co., Ltd. It provides stable and efficient AI online testing services, including intelligent grouping, intelligent monitoring, and intelligent evaluation. The platform ensures test fairness by implementing automatic monitoring level regulations and three random strategies. It prioritizes information security by combining software and hardware to secure data and identity. With global cloud deployment and flexible architecture, it supports hundreds of thousands of concurrent users. CloudExam AI offers features like queue interviews, interactive pen testing, data-driven cockpit, AI grouping, AI monitoring, AI evaluation, random question generation, dual-seat testing, facial recognition, real-time recording, abnormal behavior detection, test pledge book, student information verification, photo uploading for answers, inspection system, device detection, scoring template, ranking of results, SMS/email reminders, screen sharing, student fees, and collaboration with selected schools.
AIPresentationMakers
The website is a platform that provides reviews and recommendations for AI presentation makers. It offers in-depth guides on various AI presentation generators and helps users choose the best one for their needs. The site features detailed reviews of different AI presentation software, including their features, pros, and cons. Users can find information on popular AI tools like Plus AI, Canva, Beautiful.ai, and more. The platform also includes comparisons between different AI tools, pricing details, and evaluations of AI outputs and design components.
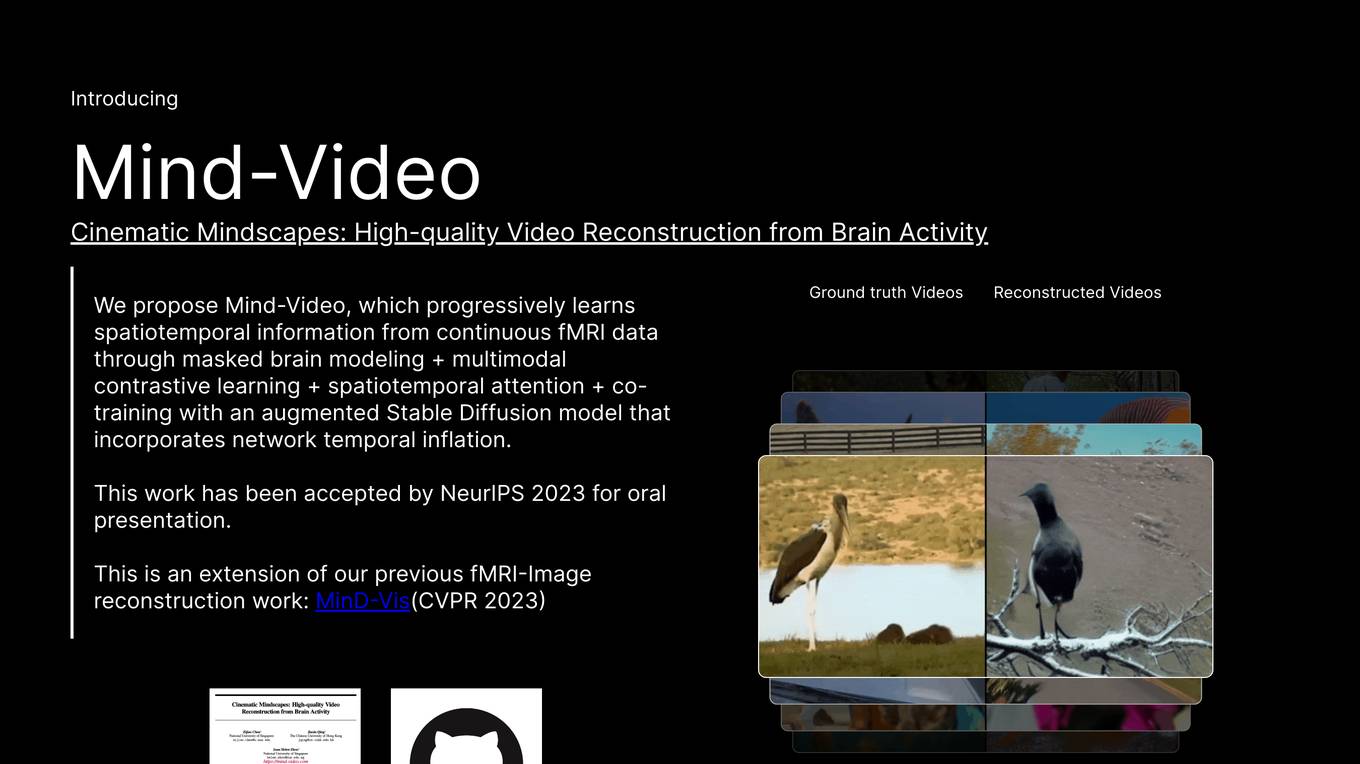
Mind-Video
Mind-Video is an AI tool that focuses on high-quality video reconstruction from brain activity data. It bridges the gap between image and video brain decoding by utilizing masked brain modeling, multimodal contrastive learning, spatiotemporal attention, and co-training with an augmented Stable Diffusion model. The tool aims to recover accurate semantic information from fMRI signals, enabling the generation of realistic videos based on brain activities.

CommodityNews.AI
CommodityNews.AI is an AI tool that provides analyzed news related to raw materials. The tool offers insights and analysis on various commodities such as energy, metals, agriculture, finance, and more. It covers a wide range of topics including market trends, pricing, geopolitical impacts, and industry developments. Users can access detailed information and updates on commodity news to make informed decisions.
PlaymakerAI
PlaymakerAI is an AI-powered platform that provides football analytics and scouting services to football clubs, agents, media companies, betting companies, researchers, and educators. The platform offers access to AI-evaluated football data from hundreds of leagues worldwide, individual player reports, analytics and scouting services, media insights, and a Playmaker Personality Profile for deeper understanding of squad dynamics. PlaymakerAI revolutionizes the way football organizations operate by offering clear, insightful information and expert assistance in football analytics and scouting.
JMIR AI
JMIR AI is a new peer-reviewed journal focused on research and applications for the health artificial intelligence (AI) community. It includes contemporary developments as well as historical examples, with an emphasis on sound methodological evaluations of AI techniques and authoritative analyses. It is intended to be the main source of reliable information for health informatics professionals to learn about how AI techniques can be applied and evaluated.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.
0 - Open Source AI Tools
20 - OpenAI Gpts

Software Comparison
I compare different software, providing detailed, balanced information.

Chinese Brand Verify
Verify whether the Chinese brand you are interested in is mainstream by searching three Chinese business media with more than 10 million subscriptions. If you don't get any information, the "Chinese brand" is not well known in China.

Stick to the Point
I'll help you evaluate your writing to make sure it's engaging, informative, and flows well. Uses principles from "Made to Stick"

GPT Search & Finderr
Optimized with advanced search operators for refined results. Specializing in finding and linking top custom GPTs from builders around the world. Version 0.3.0
Source Evaluation and Fact Checking v1.3
FactCheck Navigator GPT is designed for in-depth fact checking and analysis of written content and evaluation of its source. The approach is to iterate through predefined and well-prompted steps. If desired, the user can refine the process by providing input between these steps.
Website Speed Reader
Expert in website summarization, providing clear and concise info summaries. You can also ask it to find specific info from the site.


Epidemic Global Insight System
Advanced epidemiology expert with AI-driven data integration and dynamic visualization tools.
US Zip Intel
Your go-to source for in-depth US zip code demographics and statistics, with easy-to-download data tables.

Rate My {{Startup}}
I will score your Mind Blowing Startup Ideas, helping your to evaluate faster.

LabGPT
The main objective of a personalized ChatGPT for reading laboratory tests is to evaluate laboratory test results and create a spreadsheet with the evaluation results and possible solutions.