Best AI tools for< Evaluate Effectiveness >
20 - AI tool Sites
Mangus
Mangus is an AI-powered learning platform that provides personalized learning paths for employees and students. It offers a wide range of courses and programs in various disciplines, including business, education, technology, and more. Mangus uses gamification and artificial intelligence to create an engaging and effective learning experience.
edu720
edu720 is a science-backed learning platform that uses AI and nanolearning to redefine how workforces learn and achieve their goals. It provides pre-built learning modules on various topics, including cybersecurity, privacy, and AI ethics. edu720's 360-degree approach ensures that all employees, regardless of their status or location, fully understand and absorb the knowledge conveyed.
Should I Hire AI
Should I Hire AI is an AI application that helps businesses determine if investing in AI tools is the right decision for them. By answering a few questions, the application provides a personalized recommendation on whether AI could be a cost-effective solution. The tool is designed to assist businesses in making informed decisions about integrating AI into their operations, ultimately aiming to enhance efficiency and productivity.
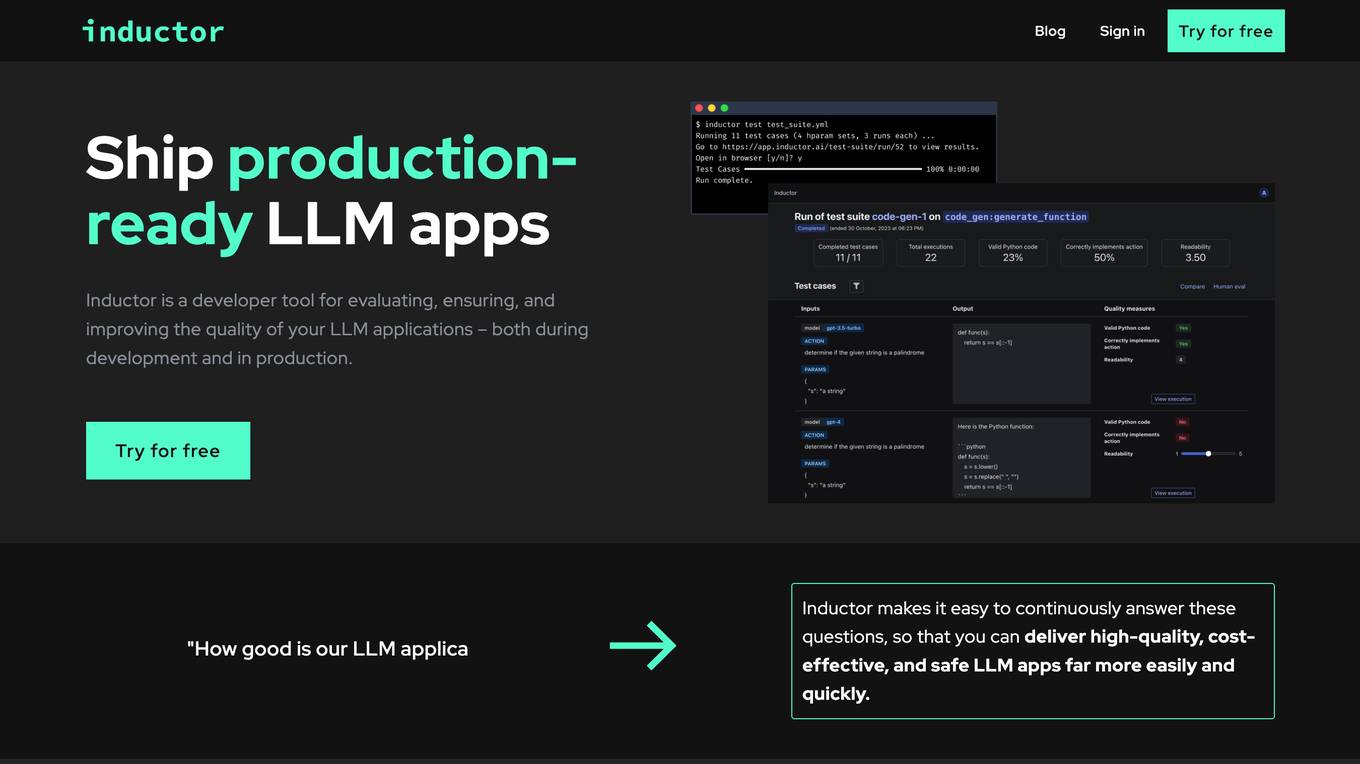
Inductor
Inductor is a developer tool for evaluating, ensuring, and improving the quality of your LLM applications – both during development and in production. It provides a fantastic workflow for continuous testing and evaluation as you develop, so that you always know your LLM app’s quality. Systematically improve quality and cost-effectiveness by actionably understanding your LLM app’s behavior and quickly testing different app variants. Rigorously assess your LLM app’s behavior before you deploy, in order to ensure quality and cost-effectiveness when you’re live. Easily monitor your live traffic: detect and resolve issues, analyze usage in order to improve, and seamlessly feed back into your development process. Inductor makes it easy for engineering and other roles to collaborate: get critical human feedback from non-engineering stakeholders (e.g., PM, UX, or subject matter experts) to ensure that your LLM app is user-ready.
Betterworks
Betterworks is an intelligent performance management platform that simplifies performance management, fosters greater manager effectiveness, higher employee engagement, and intelligent decision-making for HR leaders and organizations. It offers features such as AI for HR analytics & insights, integrations, accessibility, security, and manager effectiveness. Betterworks is designed to help organizations align their workforce around strategic priorities, drive collaboration, and continuously improve performance.

PyjamaHR
PyjamaHR is a leading AI-powered Applicant Tracking System (ATS) and recruitment software designed to streamline the hiring process for businesses of all sizes. It offers advanced features such as source management, candidate evaluation, collaboration tools, and AI-powered candidate tests to enhance the efficiency and effectiveness of the recruitment process. With a user-friendly interface and robust security measures, PyjamaHR is a trusted solution for managing talent acquisition and improving hiring outcomes.

Traceable
Traceable is an intelligent API security platform designed for enterprise-scale security. It offers unmatched API discovery, attack detection, threat hunting, and infinite scalability. The platform provides comprehensive protection against API attacks, fraud, and bot security, along with API testing capabilities. Powered by Traceable's OmniTrace Engine, it ensures unparalleled security outcomes, remediation, and pre-production testing. Security teams trust Traceable for its speed and effectiveness in protecting API infrastructures.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

thisorthis.ai
thisorthis.ai is an AI tool that allows users to compare generative AI models and AI model responses. It helps users analyze and evaluate different AI models to make informed decisions. The tool requires JavaScript to be enabled for optimal functionality.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.

Arize AI
Arize AI is an AI Observability & LLM Evaluation Platform that helps you monitor, troubleshoot, and evaluate your machine learning models. With Arize, you can catch model issues, troubleshoot root causes, and continuously improve performance. Arize is used by top AI companies to surface, resolve, and improve their models.

Evidently AI
Evidently AI is an open-source machine learning (ML) monitoring and observability platform that helps data scientists and ML engineers evaluate, test, and monitor ML models from validation to production. It provides a centralized hub for ML in production, including data quality monitoring, data drift monitoring, ML model performance monitoring, and NLP and LLM monitoring. Evidently AI's features include customizable reports, structured checks for data and models, and a Python library for ML monitoring. It is designed to be easy to use, with a simple setup process and a user-friendly interface. Evidently AI is used by over 2,500 data scientists and ML engineers worldwide, and it has been featured in publications such as Forbes, VentureBeat, and TechCrunch.

Maxim
Maxim is an end-to-end AI evaluation and observability platform that empowers modern AI teams to ship products with quality, reliability, and speed. It offers a comprehensive suite of tools for experimentation, evaluation, observability, and data management. Maxim aims to bring the best practices of traditional software development into non-deterministic AI workflows, enabling rapid iteration and deployment of AI models. The platform caters to the needs of AI developers, data scientists, and machine learning engineers by providing a unified framework for evaluation, visual flows for workflow testing, and observability features for monitoring and optimizing AI systems in real-time.

RebeccAi
RebeccAi is an AI-powered business idea evaluation and validation tool that uses AI technology to provide accurate insights into the potential of users' ideas. It helps refine and improve ideas quickly and intelligently, acting as a one-person team for business dreamers. The platform assists in turning ideas into reality, from business concepts to creative projects, by leveraging the latest AI tools and technologies to innovate faster and smarter.

Codei
Codei is an AI-powered platform designed to help individuals land their dream software engineering job. It offers features such as application tracking, question generation, and code evaluation to assist users in honing their technical skills and preparing for interviews. Codei aims to provide personalized support and insights to help users succeed in the tech industry.

Ottic
Ottic is an AI tool designed to empower both technical and non-technical teams to test Language Model (LLM) applications efficiently and accelerate the development cycle. It offers features such as a 360º view of the QA process, end-to-end test management, comprehensive LLM evaluation, and real-time monitoring of user behavior. Ottic aims to bridge the gap between technical and non-technical team members, ensuring seamless collaboration and reliable product delivery.

SuperAnnotate
SuperAnnotate is an AI data platform that simplifies and accelerates model-building by unifying the AI pipeline. It enables users to create, curate, and evaluate datasets efficiently, leading to the development of better models faster. The platform offers features like connecting any data source, building customizable UIs, creating high-quality datasets, evaluating models, and deploying models seamlessly. SuperAnnotate ensures global security and privacy measures for data protection.
SymptomChecker.io
SymptomChecker.io is an AI-powered medical symptom checker that allows users to describe their symptoms in their own words and receive non-reviewed AI-generated responses. It is important to note that this tool is not intended to offer medical advice, diagnosis, or treatment and should not be used as a substitute for professional medical advice. In the case of a medical emergency, please contact your physician or dial 911 immediately.
ELSA
ELSA is an AI-powered English speaking coach that helps you improve your pronunciation, fluency, and confidence. With ELSA, you can practice speaking English in short, fun dialogues and get instant feedback from our proprietary artificial intelligence technology. ELSA also offers a variety of other features, such as personalized lesson plans, progress tracking, and games to help you stay motivated.
ELSA Speech Analyzer
ELSA Speech Analyzer is an AI-powered conversational English fluency coach that provides instant, personalized feedback on speech. It helps users improve pronunciation, intonation, grammar, and vocabulary through real-time analysis. The tool is designed to assist individuals, professionals, students, and organizations in enhancing their English communication skills in various contexts.
1 - Open Source AI Tools

jailbreak_llms
This is the official repository for the ACM CCS 2024 paper 'Do Anything Now': Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models. The project employs a new framework called JailbreakHub to conduct the first measurement study on jailbreak prompts in the wild, collecting 15,140 prompts from December 2022 to December 2023, including 1,405 jailbreak prompts. The dataset serves as the largest collection of in-the-wild jailbreak prompts. The repository contains examples of harmful language and is intended for research purposes only.
20 - OpenAI Gpts
Serious Game Creator for Museums
Specializes in aiding museums with creative and interactive experiences.
Pocket Training Activity Expert
Expert in engaging, interactive training methods and activities.
Diseñando Experiencias de Formación
Asistente especializado en diseño y planificación de formación profesional

Skills Development Advisor
Enhances organizational performance through strategic skills development initiatives.

Training Material Design Advisor
Designs effective training materials to enhance organizational learning and performance.

Calidad en Educación Superior
Puedo asesorar en temas relacionados con calidad en IES (planificación, autoevaluación, acreditación, mejora continua)

HCDP - برنامج تنمية القدرات البشرية
خبير يقدم لك المعلومات حول برنامج تنمية القدرات البشرية (Human Capability Development Program) أحد برامج رؤية المملكة 2030 والذي يهدف إلى بناء استراتيجية وطنية طموحة لتنمية قدرات المواطن
Policy Communication Advisor
Communicates policy processes and changes effectively within the organization.
Learning & Development Advisor
Enhances organizational performance through employee learning and development initiatives.
Chronic Disease Indicators Expert
This chatbot answers questions about the CDC’s Chronic Disease Indicators dataset

Corporate Trainer
Develops training programs, customizing content to fit corporate culture and objectives.
Learning Hero
Your personal A.I. learning hero when creating interactive e-learning content

E-Learning Development Advisor
Enhances corporate training through innovative e-learning solutions.
Organization & Team Effectiveness Advisor
Guides organizational effectiveness via team-focused strategies and learning.

Rate My {{Startup}}
I will score your Mind Blowing Startup Ideas, helping your to evaluate faster.