Best AI tools for< Evaluate Design >
20 - AI tool Sites

Mock-My-Mockup
Mock-My-Mockup is an AI-powered product design tool created by Fairpixels. It allows users to upload a screenshot of a page they are working on and receive brutally honest feedback. The tool offers a user-friendly interface where users can easily drag and drop their product screenshots for analysis.
ELSA
ELSA is an AI-powered English speaking coach that helps you improve your pronunciation, fluency, and confidence. With ELSA, you can practice speaking English in short, fun dialogues and get instant feedback from our proprietary artificial intelligence technology. ELSA also offers a variety of other features, such as personalized lesson plans, progress tracking, and games to help you stay motivated.
ELSA Speech Analyzer
ELSA Speech Analyzer is an AI-powered conversational English fluency coach that provides instant, personalized feedback on your speech. It helps users improve their pronunciation, intonation, grammar, and vocabulary through real-time analysis. The tool is designed to assist individuals, professionals, students, and organizations in enhancing their English speaking skills and communication abilities.
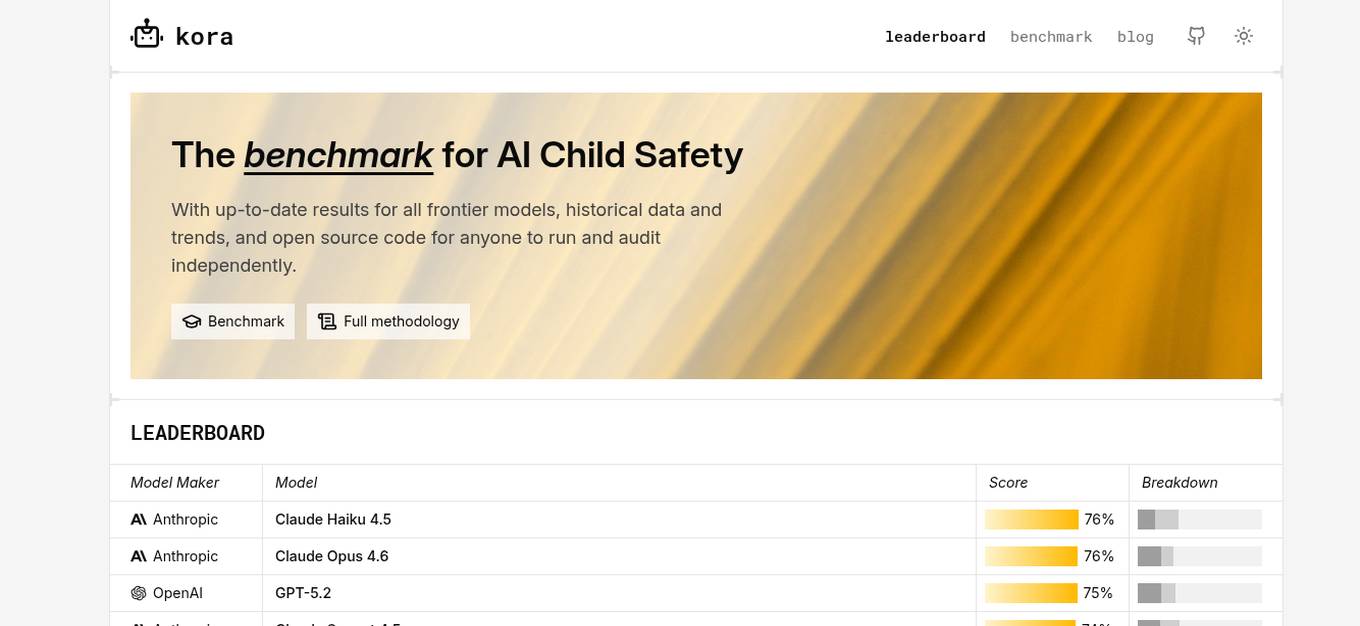
KORA Benchmark
KORA Benchmark is a leading platform that provides a benchmark for AI child safety. It offers up-to-date results for frontier models, historical data, and trends. The platform also provides open-source code for users to run and audit independently. KORA Benchmark aims to ensure the safety of children in the AI landscape by evaluating various models and providing valuable insights to the community.
AI Readiness Assessment
The AI Readiness Assessment is a comprehensive tool designed to evaluate an organization's readiness to adopt and implement artificial intelligence technologies. It assesses various aspects such as data infrastructure, talent capabilities, organizational culture, and strategic alignment to provide valuable insights and recommendations for successful AI integration. By leveraging advanced algorithms and best practices, the assessment helps businesses identify strengths and areas for improvement in their AI journey.
AI Undetect
AI Undetect is a leading AI detection and humanization tool designed to evaluate and rewrite AI-generated content to make it undetectable by AI detectors. The tool offers various AI detectors, a humanizer feature, and supports multiple languages. Users can access detailed AI detection reports and bypass AI detection effortlessly. AI Undetect is suitable for marketers, writers, bloggers, journalists, and researchers looking to ensure the authenticity and credibility of their content.
VisualHUB
VisualHUB is an AI-powered design analysis tool that provides instant insights on UI, UX, readability, and more. It offers features like A/B Testing, UI Analysis, UX Analysis, Readability Analysis, Margin and Hierarchy Analysis, and Competition Analysis. Users can upload product images to receive detailed reports with actionable insights and scores. Trusted by founders and designers, VisualHUB helps optimize design variations and identify areas for improvement in products.

RebeccAi
RebeccAi is an AI-powered business idea evaluation and validation tool that uses AI technology to provide accurate insights into the potential of users' ideas. It helps users refine and improve their ideas quickly and intelligently, acting as a one-person team for their business dreams. From evaluating and assessing business ideas to creating detailed business plans, RebeccAi revolutionizes idea validation with the power of AI.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.
AARENA
AARENA is an AI-powered platform that allows users to build fully functional apps and websites through simple conversations. It provides a user-friendly interface where individuals can create various digital products without the need for coding knowledge. AARENA leverages AI technology to streamline the development process and empower users to bring their ideas to life efficiently.
Deepfake Detection Challenge Dataset
The Deepfake Detection Challenge Dataset is a project initiated by Facebook AI to accelerate the development of new ways to detect deepfake videos. The dataset consists of over 100,000 videos and was created in collaboration with industry leaders and academic experts. It includes two versions: a preview dataset with 5k videos and a full dataset with 124k videos, each featuring facial modification algorithms. The dataset was used in a Kaggle competition to create better models for detecting manipulated media. The top-performing models achieved high accuracy on the public dataset but faced challenges when tested against the black box dataset, highlighting the importance of generalization in deepfake detection. The project aims to encourage the research community to continue advancing in detecting harmful manipulated media.
Wix
Wix.com is a website builder platform that allows users to create stunning websites without the need for coding skills. With a user-friendly interface and a wide range of customizable templates, Wix empowers individuals and businesses to establish their online presence effortlessly. Users can choose from various design elements, add functionalities through apps, and optimize their websites for different devices. Wix also provides hosting services and domain registration to simplify the entire website creation process.

Ottic
Ottic is an AI tool designed to empower both technical and non-technical teams to test Language Model (LLM) applications efficiently and accelerate the development cycle. It offers features such as a 360º view of the QA process, end-to-end test management, comprehensive LLM evaluation, and real-time monitoring of user behavior. Ottic aims to bridge the gap between technical and non-technical team members, ensuring seamless collaboration and reliable product delivery.

Codei
Codei is an AI-powered platform designed to help individuals land their dream software engineering job. It offers features such as application tracking, question generation, and code evaluation to assist users in honing their technical skills and preparing for interviews. Codei aims to provide personalized support and insights to help users succeed in the tech industry.

Brevoir
Brevoir is an AI-powered decision-grade due diligence tool designed for startup investing. It consolidates founder diligence, market and competitor research, risk assessment, and investment-ready writeups in one platform. Tailored for angel investors and startup evaluators, Brevoir streamlines the startup evaluation process by extracting key information from pitch decks or company URLs, verifying claims, mapping competitors, and providing structured reports with risks and opportunities. The tool aims to provide clear answers, identify market trends, evaluate team credibility, assess traction and risks, and offer pricing plans that scale with user needs.
UpTrain
UpTrain is a full-stack LLMOps platform designed to help users confidently scale AI by providing a comprehensive solution for all production needs, from evaluation to experimentation to improvement. It offers diverse evaluations, automated regression testing, enriched datasets, and innovative techniques to generate high-quality scores. UpTrain is built for developers, compliant to data governance needs, cost-efficient, remarkably reliable, and open-source. It provides precision metrics, task understanding, safeguard systems, and covers a wide range of language features and quality aspects. The platform is suitable for developers, product managers, and business leaders looking to enhance their LLM applications.
Inductor
Inductor is a developer tool for evaluating, ensuring, and improving the quality of your LLM applications – both during development and in production. It provides a fantastic workflow for continuous testing and evaluation as you develop, so that you always know your LLM app’s quality. Systematically improve quality and cost-effectiveness by actionably understanding your LLM app’s behavior and quickly testing different app variants. Rigorously assess your LLM app’s behavior before you deploy, in order to ensure quality and cost-effectiveness when you’re live. Easily monitor your live traffic: detect and resolve issues, analyze usage in order to improve, and seamlessly feed back into your development process. Inductor makes it easy for engineering and other roles to collaborate: get critical human feedback from non-engineering stakeholders (e.g., PM, UX, or subject matter experts) to ensure that your LLM app is user-ready.

Sereda.ai
Sereda.ai is an AI-powered platform designed to unleash a team's potential by offering solutions for employee knowledge management, surveys, performance reviews, learning, and more. It integrates artificial intelligence to streamline HR processes, improve employee engagement, and boost productivity. The platform provides a user-friendly interface, personalized settings, and automation features to enhance organizational efficiency and reduce costs.

Evidently AI
Evidently AI is an open-source machine learning (ML) monitoring and observability platform that helps data scientists and ML engineers evaluate, test, and monitor ML models from validation to production. It provides a centralized hub for ML in production, including data quality monitoring, data drift monitoring, ML model performance monitoring, and NLP and LLM monitoring. Evidently AI's features include customizable reports, structured checks for data and models, and a Python library for ML monitoring. It is designed to be easy to use, with a simple setup process and a user-friendly interface. Evidently AI is used by over 2,500 data scientists and ML engineers worldwide, and it has been featured in publications such as Forbes, VentureBeat, and TechCrunch.
TenderPilot
TenderPilot is an AI-powered SaaS platform designed for Australian small and medium businesses to improve their success in government tenders. It guides users through analyzing, writing, reviewing, and submitting tender proposals efficiently. The platform is trained on actual government procurement policies and evaluation models, offering expert strategy, secure data hosting, and tailored bid recommendations to help SMEs win more contracts faster and smarter.
0 - Open Source AI Tools
20 - OpenAI Gpts
Design Crit
I conduct design critiques focused on enhancing understanding and improvement.

Don Norman
UX Designer adept in design strategies, UI/UX principles, and technical literacy.
System Design Tutor
A System Architect Coach guiding you through system design principles and best practices. Explains CAP theorem like no one else
GPT Designer
A creative aide for designing new GPT models, skilled in ideation and prompting.

Training Material Design Advisor
Designs effective training materials to enhance organizational learning and performance.
Instructional Design and Technology Expert
A master of instructional design and technology.
Learning Experience Designer™
A Learning Experience Designer (LXD) - in support of LXDs and those who work with them.

ecosystem.Ai Use Case Designer v2
The use case designer is configured with the latest Data Science and Behavioral Social Science insights to guide you through the process of defining AI and Machine Learning use cases for the ecosystem.Ai platform.
Immersive Experience Designer
This GPT Helps to Brainstorm Immersive Experience Ideas Using the TISECT Method

Mixed Methods Design Decision Tool
I'm the Mixed Methods Design Decision Tool, offering guidance on mixed methods research designs, their implementation, and effective communication in studies.


Education AI Strategist
I provide a structured way of using AI to support teaching and learning. I use the the CHOICE method (i.e., Clarify, Harness, Originate, Iterate, Communicate, Evaluate) to ensure that your use of AI can help you meet your educational goals.
