Best AI tools for< Evaluate Change >
20 - AI tool Sites
Inedit
Inedit is an AI-powered editor widget that enhances webpage content editing instantly. It offers features like AI technology, manual editing, effortless editing of multiple elements, and the ability to inspect deeper structures of webpages. The tool is powered by OpenAI GPT Models, providing unparalleled flexibility and performance. Users can seamlessly edit, evaluate, and publish content, ensuring only approved content reaches the audience.
BodyFatEstimator.ai
BodyFatEstimator.ai is an AI tool that analyzes photos of people and estimates their body fat percentage. It uses computer vision to evaluate visible body composition, fat distribution, and proportions directly. Users can upload a photo and receive a visual body fat estimate in seconds. The tool is designed for frequent progress tracking and is ideal for weekly or monthly check-ins to understand changes in body composition over time.

GenInnov
GenInnov is a generative innovation fund that provides a platform for investors seeking to be at the forefront of technological advancement. The fund invests in companies driving transformative change across multiple sectors and geographies, prioritizing material innovations with demonstrable profitability and global reach. GenInnov operates with a research-driven approach, focusing on investing in material innovations that are monetizable, profitable, and transformative, rather than incremental. The fund looks at various domains such as technology, robotics, consumer electronics, biotech, healthcare, mobility, and clean tech, aiming to amplify human creativity through machine intelligence.
Sacred
Sacred is a tool to configure, organize, log and reproduce computational experiments. It is designed to introduce only minimal overhead, while encouraging modularity and configurability of experiments. The ability to conveniently make experiments configurable is at the heart of Sacred. If the parameters of an experiment are exposed in this way, it will help you to: keep track of all the parameters of your experiment easily run your experiment for different settings save configurations for individual runs in files or a database reproduce your results In Sacred we achieve this through the following main mechanisms: Config Scopes are functions with a @ex.config decorator, that turn all local variables into configuration entries. This helps to set up your configuration really easily. Those entries can then be used in captured functions via dependency injection. That way the system takes care of passing parameters around for you, which makes using your config values really easy. The command-line interface can be used to change the parameters, which makes it really easy to run your experiment with modified parameters. Observers log every information about your experiment and the configuration you used, and saves them for example to a Database. This helps to keep track of all your experiments. Automatic seeding helps controlling the randomness in your experiments, such that they stay reproducible.
Edelman
Edelman is an AI tool that focuses on enterprise marketing communications. It offers generative AI solutions to help marcom teams enhance decision-making, boost insights, and drive results. The tool provides key strategy elements for successful change management, evaluates analytics and social listening tools, and explores large language models for marketing and communications teams.
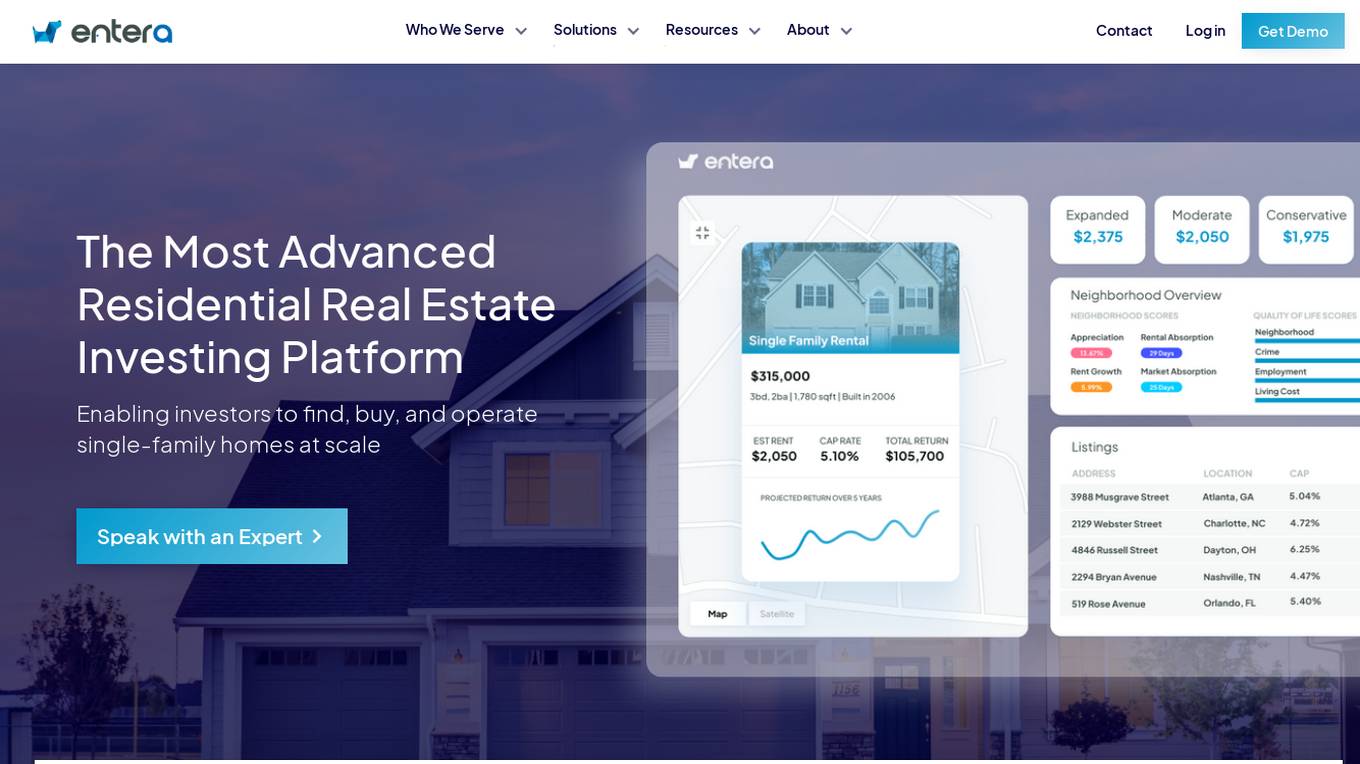
Entera
Entera is an advanced residential real estate investment platform that enables investors to find, buy, and operate single-family homes at scale. Fueled by AI and full-service transaction services, Entera serves operators, funds, agents, and builders by providing access to on and off-market homes, real-time market data, analytics tools, and expert services. The platform modernizes the real estate buying process, helping clients make data-driven investment decisions, scale their operations, and maximize success.
Checkmyidea-IA
Checkmyidea-IA is an AI-powered tool that helps entrepreneurs and businesses evaluate their business ideas before launching them. It uses a variety of factors, such as customer interest, uniqueness, initial product development, and launch strategy, to provide users with a comprehensive review of their idea's potential for success. Checkmyidea-IA can help users save time, increase their chances of success, reduce risk, and improve their decision-making.
Q, ChatGPT for Slack
The website offers 'Q, ChatGPT for Slack', an AI tool that functions like ChatGPT within your Slack workspace. It allows on-demand URL and file reading, custom instructions for tailored use, and supports various URLs and files. With Q, users can summarize, evaluate, brainstorm ideas, self-review, engage in Q&A, and more. The tool enables team-specific rules, guidelines, and templates, making it ideal for emails, translations, content creation, copywriting, reporting, coding, and testing based on internal information.
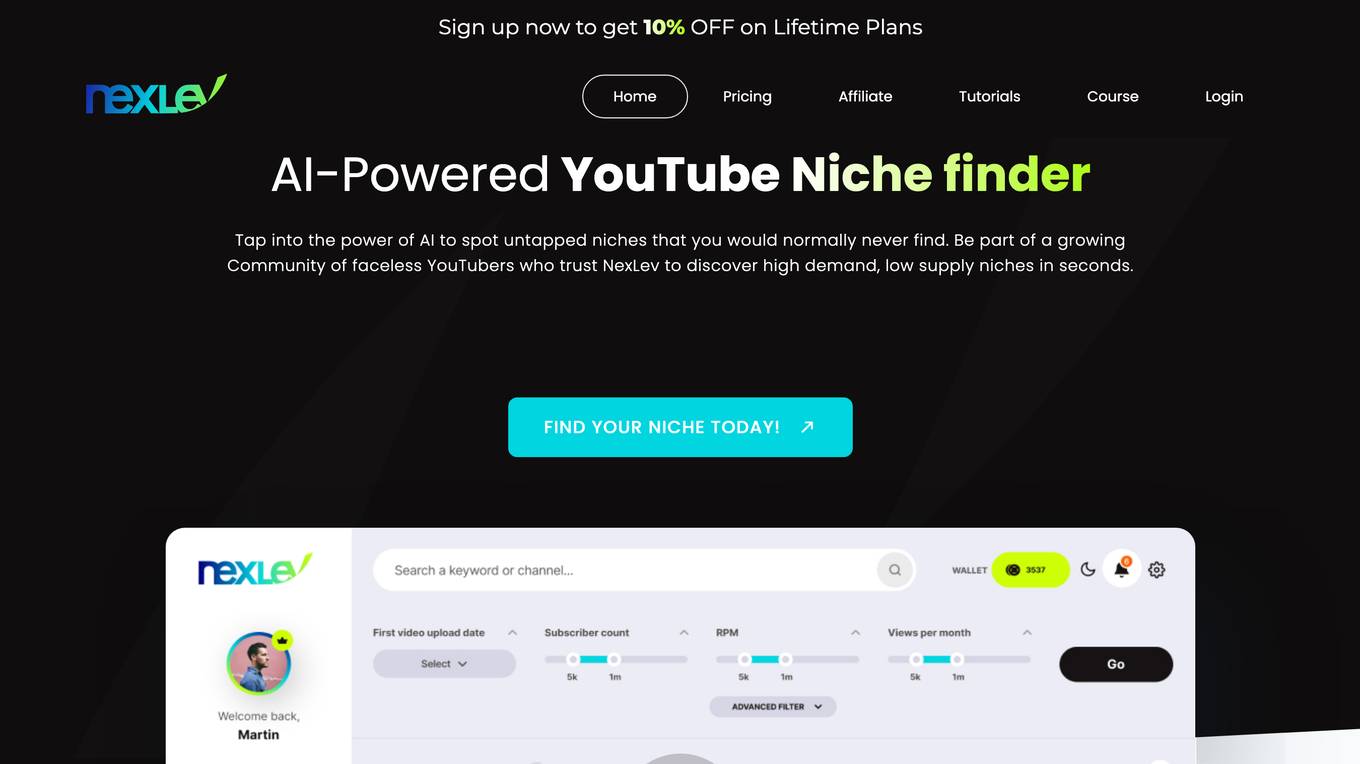
NexLev
NexLev is an AI-powered YouTube niche finder that helps users discover untapped, high-demand niches in seconds. It provides detailed YouTube channel analytics and an intuitive filtering system, making it easier for users to find lucrative niches for their next YouTube venture. NexLev also offers a variety of features such as a keyword analysis tool, competitor analysis, and a niche profitability calculator.

Dreamphilic
Dreamphilic.com is a website that provides a comprehensive guide on choosing the right electronics distributor. The site offers strategies for evaluating distributors based on quality, pricing, and continuity, with tips for managing IC Chips and ensuring resilient sourcing. It emphasizes the importance of distinguishing between authorized and independent channels, quality assurance for sensitive devices, and commercial terms for staying on track with build plans. The platform aims to help optimize AVL, suggest drop-in replacements, and proactively flag PCNs and lifecycle transitions to reduce total cost of ownership and improve supply continuity and product reliability.

Resume Roaster AI
The website offers a service where users can have their resumes analyzed by an AI tool. Users can submit their resumes to receive feedback and suggestions for improvement. The AI tool evaluates resumes based on various criteria such as formatting, content, and relevance to the job market. It provides users with valuable insights to enhance their resumes and increase their chances of landing their desired job.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

thisorthis.ai
thisorthis.ai is an AI tool that allows users to compare generative AI models and AI model responses. It helps users analyze and evaluate different AI models to make informed decisions. The tool requires JavaScript to be enabled for optimal functionality.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.

Arize AI
Arize AI is an AI Observability & LLM Evaluation Platform that helps you monitor, troubleshoot, and evaluate your machine learning models. With Arize, you can catch model issues, troubleshoot root causes, and continuously improve performance. Arize is used by top AI companies to surface, resolve, and improve their models.

Evidently AI
Evidently AI is an open-source machine learning (ML) monitoring and observability platform that helps data scientists and ML engineers evaluate, test, and monitor ML models from validation to production. It provides a centralized hub for ML in production, including data quality monitoring, data drift monitoring, ML model performance monitoring, and NLP and LLM monitoring. Evidently AI's features include customizable reports, structured checks for data and models, and a Python library for ML monitoring. It is designed to be easy to use, with a simple setup process and a user-friendly interface. Evidently AI is used by over 2,500 data scientists and ML engineers worldwide, and it has been featured in publications such as Forbes, VentureBeat, and TechCrunch.

Maxim
Maxim is an end-to-end AI evaluation and observability platform that empowers modern AI teams to ship products with quality, reliability, and speed. It offers a comprehensive suite of tools for experimentation, evaluation, observability, and data management. Maxim aims to bring the best practices of traditional software development into non-deterministic AI workflows, enabling rapid iteration and deployment of AI models. The platform caters to the needs of AI developers, data scientists, and machine learning engineers by providing a unified framework for evaluation, visual flows for workflow testing, and observability features for monitoring and optimizing AI systems in real-time.

RebeccAi
RebeccAi is an AI-powered business idea evaluation and validation tool that uses AI technology to provide accurate insights into the potential of users' ideas. It helps users refine and improve their ideas quickly and intelligently, acting as a one-person team for their business dreams. From evaluating and assessing business ideas to creating detailed business plans, RebeccAi revolutionizes idea validation with the power of AI.

Codei
Codei is an AI-powered platform designed to help individuals land their dream software engineering job. It offers features such as application tracking, question generation, and code evaluation to assist users in honing their technical skills and preparing for interviews. Codei aims to provide personalized support and insights to help users succeed in the tech industry.
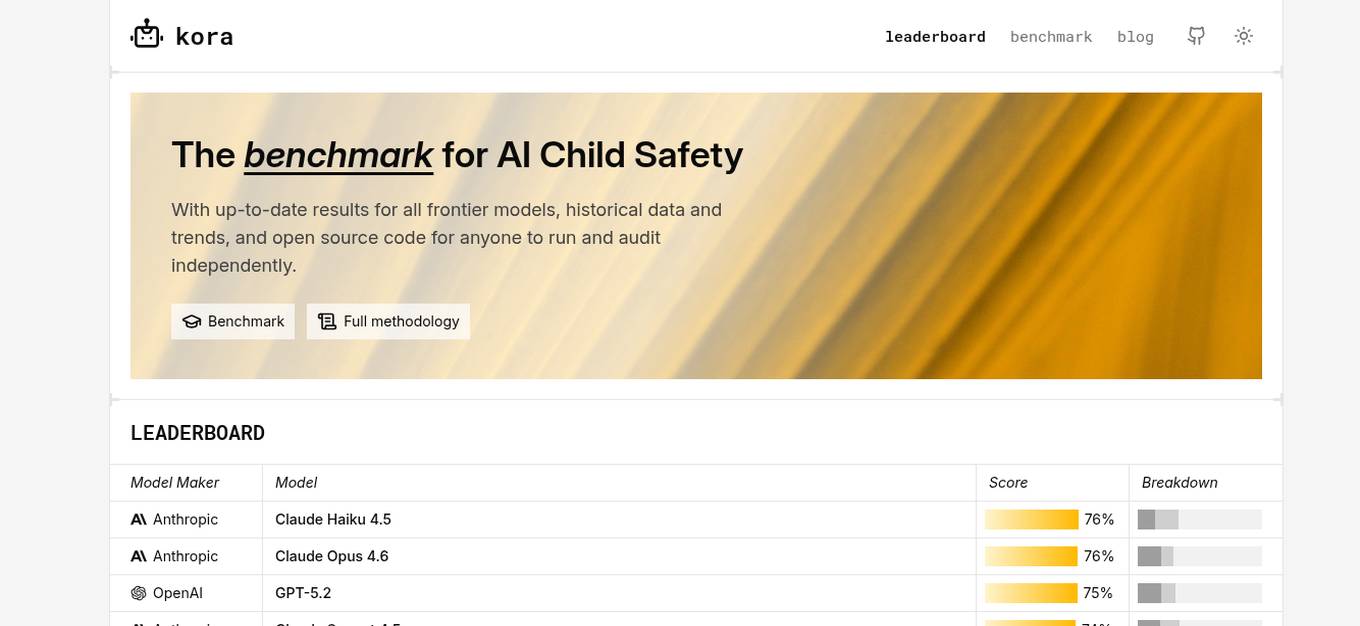
KORA Benchmark
KORA Benchmark is a leading platform that provides a benchmark for AI child safety. It offers up-to-date results for frontier models, historical data, and trends. The platform also provides open-source code for users to run and audit independently. KORA Benchmark aims to ensure the safety of children in the AI landscape by evaluating various models and providing valuable insights to the community.
0 - Open Source AI Tools
20 - OpenAI Gpts
Lead Change Like a Gardener
Explore my book 'Gardeners not Mechanics: How to Cultivate Change at Work"'
Policy Communication Advisor
Communicates policy processes and changes effectively within the organization.
Ready for Transformation
Assess your company's real appetite for new technologies or new ways of working methods

Project Benefit Realization Advisor
Advises on maximizing project benefits post-project closure.
Organization & Team Effectiveness Advisor
Guides organizational effectiveness via team-focused strategies and learning.
Environmental Disaster Analyst
Simulates and analyzes potential environmental disaster scenarios for preparedness.

Green Mind Economist
AI expert in renewable energy economics, advising on sustainable practices.
Email Proofreader
Copy and paste your email draft to be proofread by GPT without changing their content. Optionally, write 'Verbose = True' on the line before pasting your draft if you would like GPT to explain how it evaluated and changed your text after proofreading.
Lifeeventprobabilityanalyzer
Map or simulate a scenario real time analyze probability of a life event coming true based on circumstances

Rate My {{Startup}}
I will score your Mind Blowing Startup Ideas, helping your to evaluate faster.

Stick to the Point
I'll help you evaluate your writing to make sure it's engaging, informative, and flows well. Uses principles from "Made to Stick"

LabGPT
The main objective of a personalized ChatGPT for reading laboratory tests is to evaluate laboratory test results and create a spreadsheet with the evaluation results and possible solutions.

SearchQualityGPT
As a Search Quality Rater, you will help evaluate search engine quality around the world.

Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model
