Best AI tools for< Evaluate Assets >
20 - AI tool Sites
Web3 Summary
Web3 Summary is an AI-powered platform that simplifies on-chain research across multiple chains and protocols, helping users find trading alpha in the DeFi and NFT space. It offers a range of products including a trading terminal, wallet study tool, Discord bot, mobile app, and Chrome extension. The platform aims to streamline the process of understanding complex crypto projects and tokenomics using AI and ChatGPT technology.
Fairo
Fairo is a platform that facilitates Responsible AI Governance, offering tools for reducing AI hallucinations, managing AI agents and assets, evaluating AI systems, and ensuring compliance with various regulations. It provides a comprehensive solution for organizations to align their AI systems ethically and strategically, automate governance processes, and mitigate risks. Fairo aims to make responsible AI transformation accessible to organizations of all sizes, enabling them to build technology that is profitable, ethical, and transformative.
AI Readiness Assessment
The AI Readiness Assessment is a comprehensive tool designed to evaluate an organization's readiness to adopt and implement artificial intelligence technologies. It assesses various aspects such as data infrastructure, talent capabilities, organizational culture, and strategic alignment to provide valuable insights and recommendations for successful AI integration. By leveraging advanced algorithms and best practices, the assessment helps businesses identify strengths and areas for improvement in their AI journey.

RebeccAi
RebeccAi is an AI-powered business idea evaluation and validation tool that uses AI technology to provide accurate insights into the potential of users' ideas. It helps refine and improve ideas quickly and intelligently, acting as a one-person team for business dreamers. The platform assists in turning ideas into reality, from business concepts to creative projects, by leveraging the latest AI tools and technologies to innovate faster and smarter.
InterviewQueue
InterviewQueue is an AI-powered online assessment software platform that revolutionizes the recruitment process. It offers customizable coding challenges, insightful AI analytics, and seamless API integration for efficient hiring. With features like custom assessments, AI evaluation, and API integration, InterviewQueue aims to streamline the recruitment process and provide objective evaluations. The platform helps in making data-driven hiring decisions, optimizing the interview process, and enhancing the candidate experience. InterviewQueue focuses on efficiency, customization, objective evaluation, data-driven decisions, and candidate-centric assessments.
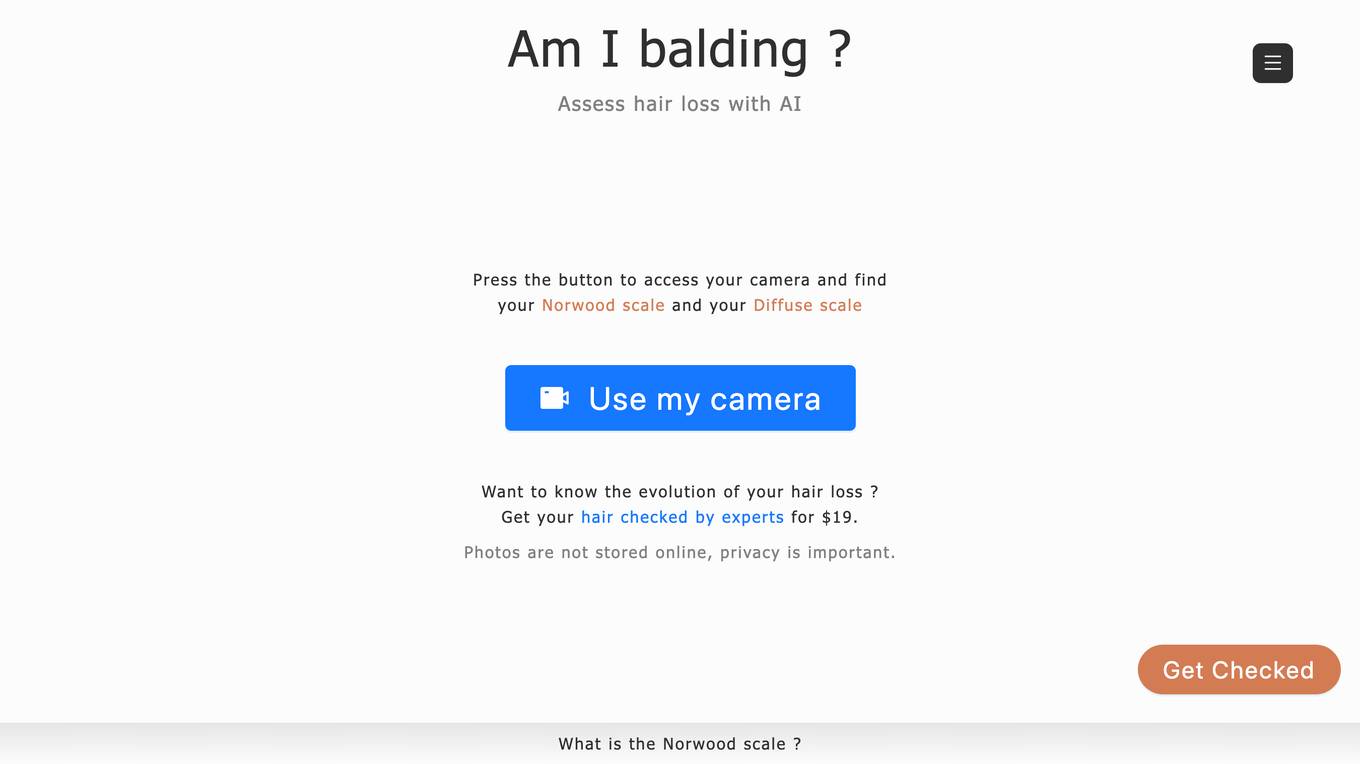
Hair Loss AI Tool
The website offers an AI tool to assess hair loss using the Norwood scale and Diffuse scale. Users can access the tool by pressing a button to use their camera. The tool provides a quick and convenient way to track the evolution of hair loss. Additionally, users can opt for a professional hair check by experts for a fee of $19, ensuring privacy as photos are not stored online. The tool is user-friendly and can be used in portrait mode for optimal experience.
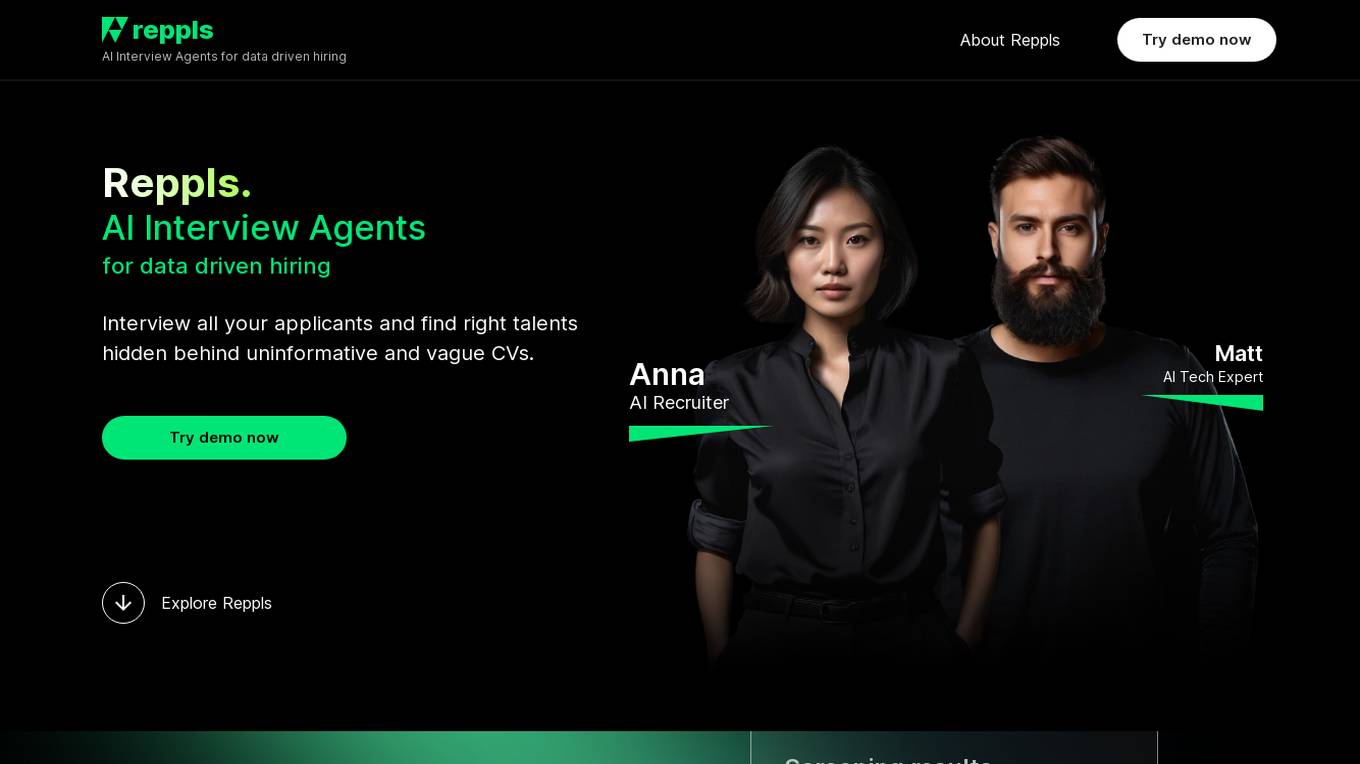
Reppls
Reppls is an AI Interview Agents tool designed for data-driven hiring processes. It helps companies interview all applicants to identify the right talents hidden behind uninformative CVs. The tool offers seamless integration with daily tools, such as Zoom and MS Teams, and provides deep technical assessments in the early stages of hiring, allowing HR specialists to focus on evaluating soft skills. Reppls aims to transform the hiring process by saving time spent on screening, interviewing, and assessing candidates.
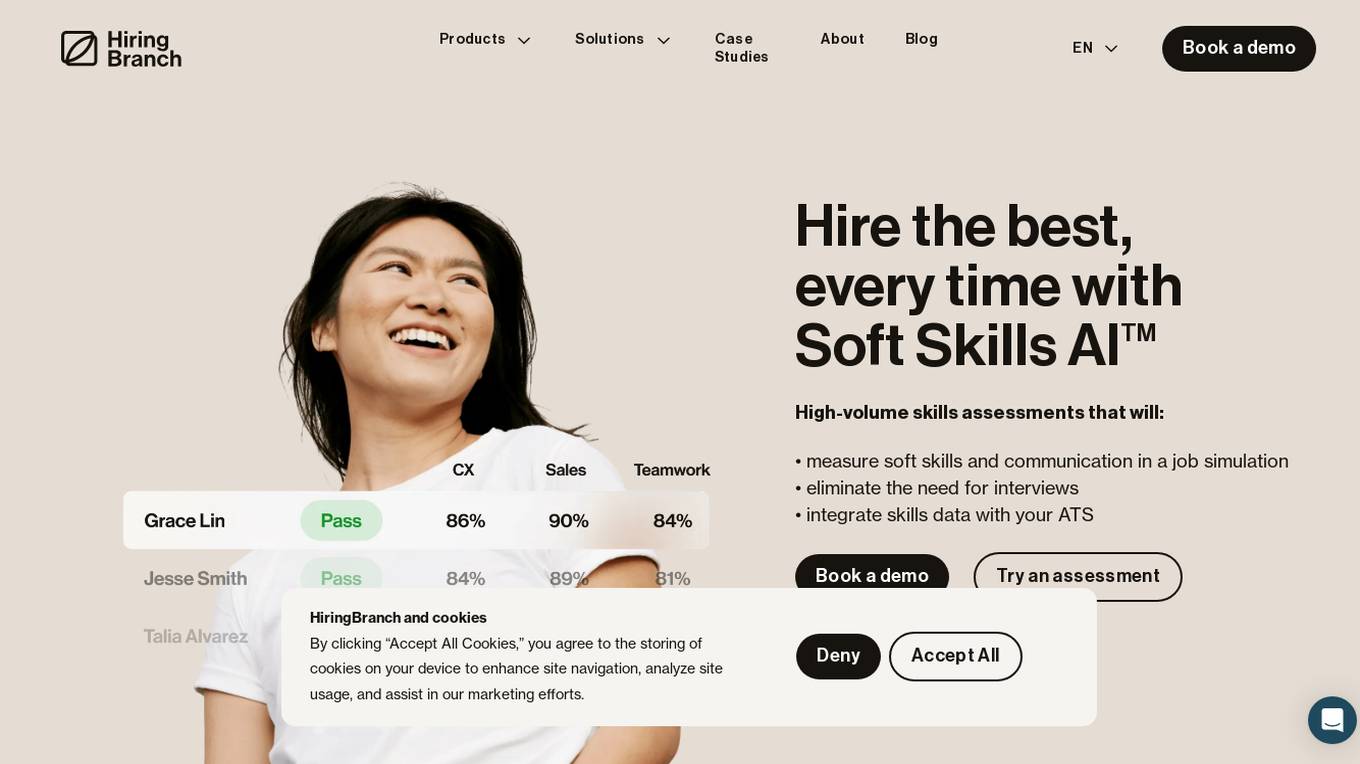
HiringBranch
HiringBranch is an AI-powered platform that offers high-volume skills assessments to help companies hire the best candidates efficiently. The platform accurately measures soft skills and communication through open-ended conversational assessments, eliminating the need for traditional interviews. HiringBranch's AI skills assessments are tailored to various industries such as Telecommunication, Retail, Banking & Insurance, and Contact Centers, providing real-time evaluation of role-critical skills. The platform aims to streamline the hiring process, reduce mis-hires, and improve retention rates for enterprises globally.
pymetrics
pymetrics is an AI-powered soft skills platform that revolutionizes the hiring and talent management process by leveraging data-driven behavioral insights and audited AI technology. The platform aims to create a more efficient, effective, and fair recruitment process across the talent lifecycle. pymetrics offers solutions for talent acquisition, workforce transformation, mobility, reskilling, learning and development, and soft skills assessment. It provides custom AI algorithms tailored to each company's unique needs, ensuring unbiased candidate evaluation and suggesting optimal job matches.
Harver
Harver is a predictive assessments and automated solutions platform that helps companies make impactful hiring decisions by prioritizing potential over past experiences. It enables companies to optimize talent decisions, reduce employee turnover, maximize sourcing investments, hire faster with intelligent automation, and leverage data-driven hiring insights. Harver offers a suite of assessments, personalized candidate experiences, and business analytics to support data-driven decision-making throughout the recruitment process.
RoundOneAI
RoundOneAI is an AI-driven platform revolutionizing tech recruitment by offering unbiased and efficient candidate assessments, ensuring skill-based evaluations free from demographic biases. The platform streamlines the hiring process with tailored job descriptions, AI-powered interviews, and insightful analytics. RoundOneAI helps companies evaluate candidates simultaneously, make informed hiring decisions, and identify top talent efficiently.
Talynce
Talynce is an AI-powered technical interview platform that revolutionizes the recruitment process by automating candidate screening through live coding interviews and technical Q&A sessions. It helps companies assess coding skills and theoretical knowledge efficiently, empowering them to identify top technical talent faster.
Sourcer AI
Sourcer AI is an AI-powered fact-checking tool that provides real-time assessments of source credibility and bias in online information. It revolutionizes the evaluation process by using cutting-edge artificial intelligence to uncover reputability ratings and political biases of online sources, helping users combat misinformation and make informed decisions.

MASCAA
MASCAA is a comprehensive human confidence analysis platform that focuses on evaluating the confidence of users through video and audio during various tasks. It integrates advanced facial expression and voice analysis technologies to provide valuable feedback for students, instructors, individuals, businesses, and teams. MASCAA offers quick and easy test creation, evaluation, and confidence assessment for educational settings, personal use, startups, small organizations, universities, and large organizations. The platform aims to unlock long-term value and enhance customer experience by helping users assess and improve their confidence levels.
iCAD
iCAD is an AI-powered application designed for cancer detection, specifically focusing on breast cancer. The platform offers a suite of solutions including Detection, Density Assessment, and Risk Evaluation, all backed by science, clinical evidence, and proven patient outcomes. iCAD's AI-powered solutions aim to expose the hiding place of cancer, providing certainty and peace of mind, ultimately improving patient outcomes and saving more lives.
PolygrAI
PolygrAI is a digital polygraph powered by AI technology that provides real-time risk assessment and sentiment analysis. The platform meticulously analyzes facial micro-expressions, body language, vocal attributes, and linguistic cues to detect behavioral fluctuations and signs of deception. By combining well-established psychology practices with advanced AI and computer vision detection, PolygrAI offers users actionable insights for decision-making processes across various applications.
MeritTrac
MeritTrac is an AI-powered testing and assessment solutions provider that offers customized solutions to enterprises and educational institutions. With a content strong and technology-first approach, MeritTrac empowers organizations to make data-driven decisions, enhance talent acquisition, workforce development, and educational assessments. Their AI-powered platforms ensure scalable, secure, and seamless assessment experiences across various domains.
ZestyAI
ZestyAI is an artificial intelligence tool that helps users make brilliant climate and property risk decisions. The tool uses AI to provide insights on property values and risk exposure to natural disasters. It offers products such as Property Insights, Digital Roof, Roof Age, Location Insights, and Climate Risk Models to evaluate and understand property risks. ZestyAI is trusted by top insurers in North America and aims to bring a ten times return on investment to its customers.
Studious Score AI
Studious Score AI is an AI-powered platform that offers knowledge and skill evaluation services supported by reputable individuals and organizations. The platform aims to revolutionize credentialing by providing a new approach. Studious Score AI is on a mission to establish itself as the global benchmark for assessing skills and knowledge in various aspects of life. Users can explore different categories and unlock their potential through the platform's innovative evaluation methods.
GreetAI
GreetAI is an AI-powered platform that revolutionizes the hiring process by conducting AI video interviews to evaluate applicants efficiently. The platform provides insightful reports, customizable interview questions, and highlights key points to help recruiters make informed decisions. GreetAI offers features such as interview simulations, job post generation, AI video screenings, and detailed candidate performance metrics.
0 - Open Source AI Tools
20 - OpenAI Gpts

I4T Assessor - UNESCO Tech Platform Trust Helper
Helps you evaluate whether or not tech platforms match UNESCO's Internet for Trust Guidelines for the Governance of Digital Platforms
Eureka Research Assessment and Improvement
AI tool for self-evaluating and enhancing scientific research capabilities.

SearchQualityGPT
As a Search Quality Rater, you will help evaluate search engine quality around the world.

Charity Impact Assessor
Assesses and evaluates the impact and trustworthiness of various charity organizations.

Supplier Evaluation Advisor
Assesses and recommends potential suppliers for organizational needs.

Startup Critic
Apply gold-standard startup valuation and assessment methods to identify risks and gaps in your business model and product ideas.
Rate My ADHD
Provides a 10-question ADHD assessment, each with a subtitle evaluating specific traits.

Rate My {{Startup}}
I will score your Mind Blowing Startup Ideas, helping your to evaluate faster.
HomeScore
Assess a potential home's quality using your own photos and property inspection reports
Ready for Transformation
Assess your company's real appetite for new technologies or new ways of working methods
Essay Prompt Generator
K12 assessment expert, creating grade-level appropriate essay prompts.
Legal Tax Minimizer
Interactive questionnaire-based guide for assessing tax residency, liability, and legal minimization strategies.
OKR Coach
AI OKR Coach is a tool designed to assist users in the process of creating and assessing OKR (Objectives and Key Results). It provides a structured and flexible approach to OKR setting and evaluation.