Best AI tools for< Evaluate Actions >
20 - AI tool Sites

Ergodic - Kepler
Ergodic is an AI tool called Kepler that enables data-driven decisions for businesses. Kepler acts as an AI action engine, bridging the knowledge gap between business context and data to help optimize processes, identify opportunities, and mitigate risks. It goes beyond number crunching to build a digital version of the business, allowing users to create scenarios and evaluate outcomes. Kepler focuses on taking action directly, without the need for complex dashboards, providing insights on what needs to be done, why, and the potential outcomes. Ergodic aims to empower businesses with AI-driven solutions for strategic decision-making.

Libera Global AI
Libera Global AI is an AI and blockchain solution provider for emerging market retail. The platform empowers small businesses and brands in emerging markets with AI-driven insights to enhance visibility, efficiency, and profitability. By harnessing the power of AI and blockchain, Libera aims to create a more connected and transparent retail ecosystem in regions like Asia, Africa, and beyond. The company offers innovative solutions such as Display AI, Receipt AI, Knowledge Graph API, and Large Vision Model to revolutionize market evaluation and decision-making processes. With a mission to bridge the gap in retail data challenges, Libera is shaping the future of retail by enabling businesses to make smarter decisions and drive growth.
PandaRocket
PandaRocket is an AI-powered suite designed to support various eCommerce business models. It offers a range of tools for product research, content creation, and store management. With features like market analysis, customer segmentation, and predictive intelligence, PandaRocket helps users make data-driven decisions to optimize their online stores and maximize profits.
Workable
Workable is a leading recruiting software and hiring platform that offers a full Applicant Tracking System with built-in AI sourcing. It provides a configurable HRIS platform to securely manage employees, automate hiring tasks, and offer actionable insights and reporting. Workable helps companies streamline their recruitment process, from sourcing to employee onboarding and management, with features like sourcing and attracting candidates, evaluating and collaborating with hiring teams, automating hiring tasks, onboarding and managing employees, and tracking HR processes.
VisualHUB
VisualHUB is an AI-powered design analysis tool that provides instant insights on UI, UX, readability, and more. It offers features like A/B Testing, UI Analysis, UX Analysis, Readability Analysis, Margin and Hierarchy Analysis, and Competition Analysis. Users can upload product images to receive detailed reports with actionable insights and scores. Trusted by founders and designers, VisualHUB helps optimize design variations and identify areas for improvement in products.
Fathom AI Notetaker
Fathom AI Notetaker is an advanced AI application that revolutionizes the way meetings are conducted and documented. It provides shockingly accurate transcripts, instant summaries, and action items with consistent quality across every call. Fathom helps users stay fully present in meetings, save time on follow-up work, and accelerate the transition from meeting insights to actionable next steps. The application works seamlessly with popular tools like Slack, Salesforce, HubSpot, Notion, and Asana, making it a valuable asset for teams looking to enhance productivity and collaboration.
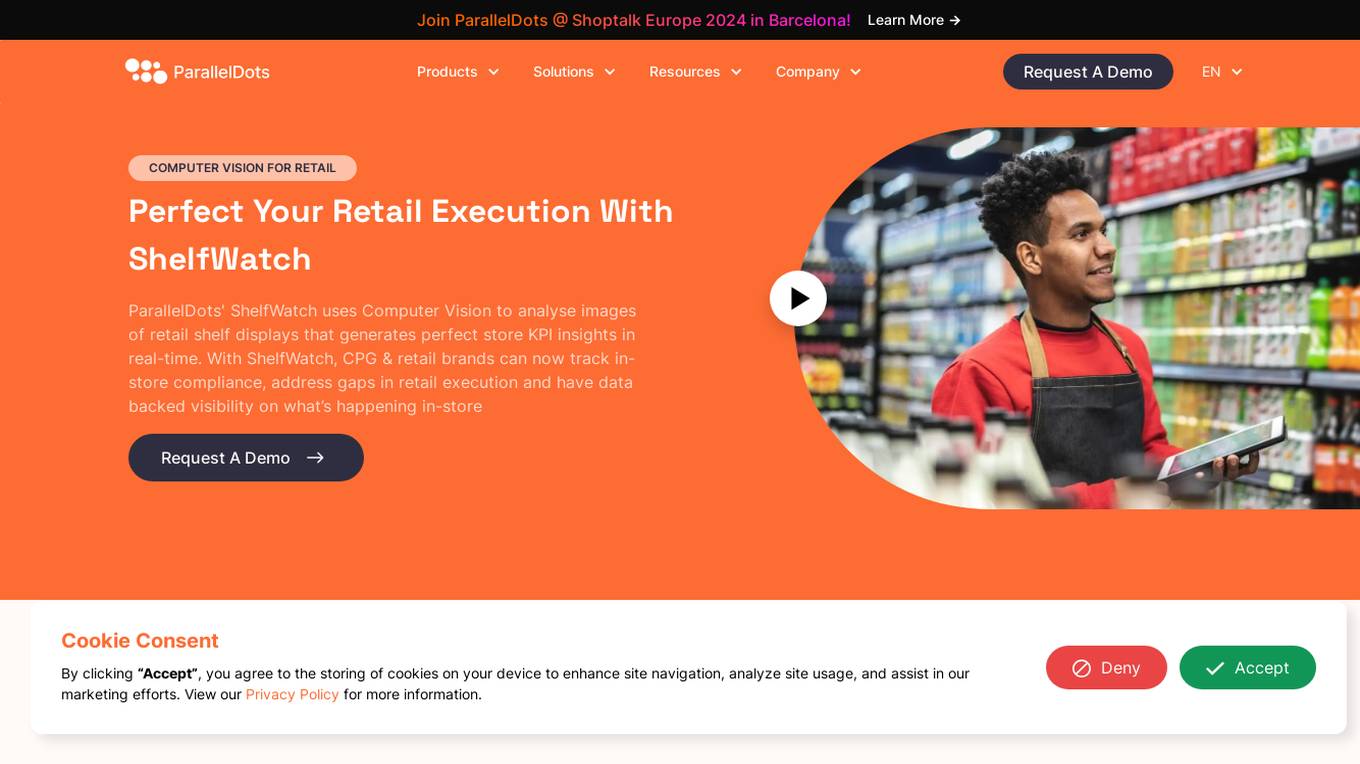
ParallelDots
ParallelDots is a next-generation retail execution software powered by image recognition technology. The software offers solutions like ShelfWatch, Saarthi, and SmartGaze to enhance the efficiency of sales reps and merchandisers, provide faster training of image recognition models, and offer automated gaze-coding solutions for mobile and retail eye-tracking research. ParallelDots' computer vision technology helps CPG and retail brands track in-store compliance, address gaps in retail execution, and gain real-time insights into brand performance. The platform enables users to generate real-time KPI insights, evaluate compliance levels, convert insights into actionable strategies, and integrate computer vision with existing retail solutions seamlessly.
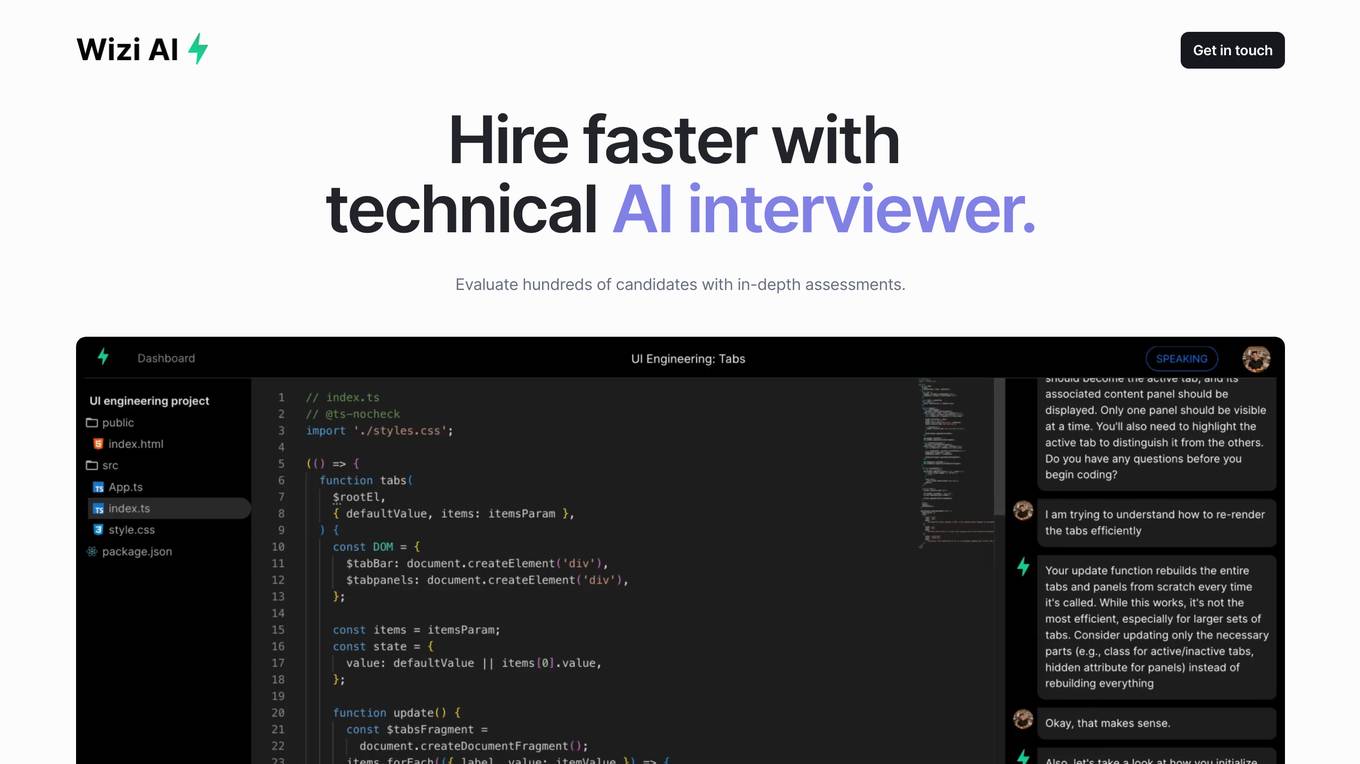
Wizi AI
Wizi AI is a technical AI interviewer that helps employers evaluate hundreds of candidates with in-depth assessments. It goes beyond basic coding challenges and conducts an onsite interview experience for every candidate. Employers get actionable hiring signals with in-depth reports on system design, project implementation, domain expertise, and debugging skills. Wizi AI saves teams time by screening all candidates with AI and bringing only the best to onsites.
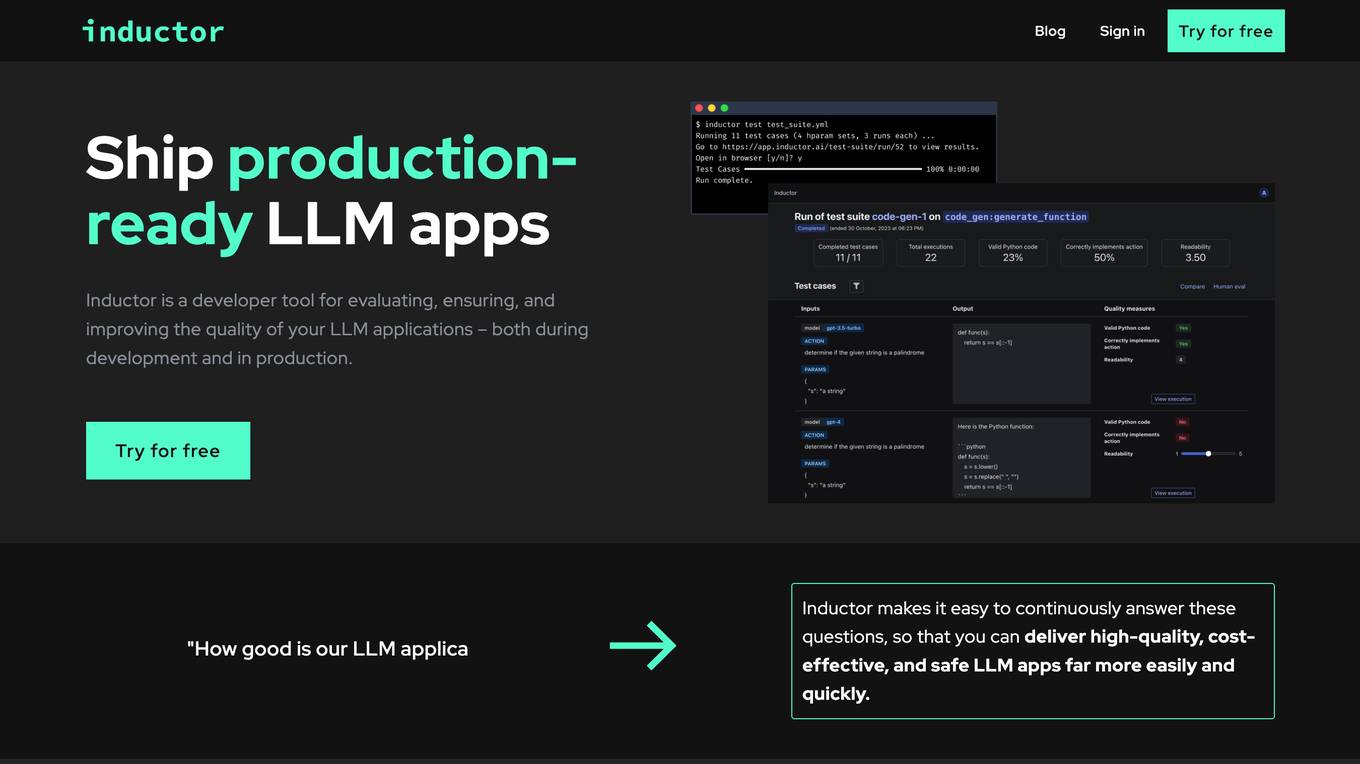
Inductor
Inductor is a developer tool for evaluating, ensuring, and improving the quality of your LLM applications – both during development and in production. It provides a fantastic workflow for continuous testing and evaluation as you develop, so that you always know your LLM app’s quality. Systematically improve quality and cost-effectiveness by actionably understanding your LLM app’s behavior and quickly testing different app variants. Rigorously assess your LLM app’s behavior before you deploy, in order to ensure quality and cost-effectiveness when you’re live. Easily monitor your live traffic: detect and resolve issues, analyze usage in order to improve, and seamlessly feed back into your development process. Inductor makes it easy for engineering and other roles to collaborate: get critical human feedback from non-engineering stakeholders (e.g., PM, UX, or subject matter experts) to ensure that your LLM app is user-ready.
WellTrade AI
WellTrade.ai is an AI-powered financial advisor tool that leverages artificial intelligence to provide clear, actionable, and data-driven investment recommendations for stocks and ETFs. It simplifies the investment process by analyzing comprehensive financial data and offering insights to help users make informed decisions. The tool aims to assist investors in navigating the complexities of stock and ETF investments by providing valuable AI-driven insights.
Candidate Search AI
The AI powered candidate search engine is a sophisticated tool designed to revolutionize the recruitment process by enabling recruiters to search their candidate database using natural language, context-aware, and lightning fast technology. It goes beyond traditional keyword-based search, offering semantic understanding, AI-driven candidate evaluation, and workflow automation to streamline the recruiting process. The tool also provides rich candidate profiles, skill highlights, and smart alerts for efficient talent discovery. With powerful analytics and visualizations, recruiters can transform their talent data into actionable intelligence, increasing ROI and reducing sourcing time. The tool ensures data security and privacy with enterprise-grade security features and compliance with data privacy regulations globally.
Insidr AI
Insidr AI is a real-time analysis tool that helps users track their competition by providing actionable insights about products. Powered by Supervised AI, the tool offers features such as analyzing user reviews, gaining insights on competitors, and performing various analyses like sentiment analysis, SWOT analysis, and trend analysis. Users can also transcribe recordings, perform KPI analysis, and find competitive edges. With a focus on providing accurate data and insights, Insidr AI aims to help businesses make informed decisions and stay ahead of the competition.
PolygrAI
PolygrAI is a digital polygraph powered by AI technology that provides real-time risk assessment and sentiment analysis. The platform meticulously analyzes facial micro-expressions, body language, vocal attributes, and linguistic cues to detect behavioral fluctuations and signs of deception. By combining well-established psychology practices with advanced AI and computer vision detection, PolygrAI offers users actionable insights for decision-making processes across various applications.
SQOR
SQOR is a plug-n-play AI tool designed for C-Level Executives to make stress-free decision-making in business intelligence. It provides a zero-code BI solution, offering KPIs at your fingertips without the need for expert knowledge. The platform enables users to access and share business intelligence data from various SaaS tools, facilitating collaboration and informed decision-making across the organization. SQOR's unique Execution Score Algorithm evaluates execution health at different levels, ensuring stakeholders are empowered with actionable insights.
Emocional
Emocional is a platform that helps businesses evaluate, plan, and act to develop their employees' soft skills and promote well-being. It offers a unique personality and soft skills assessment, a personalized action plan, and access to expert training, coaching, therapy, and digital tools like EVA AI.
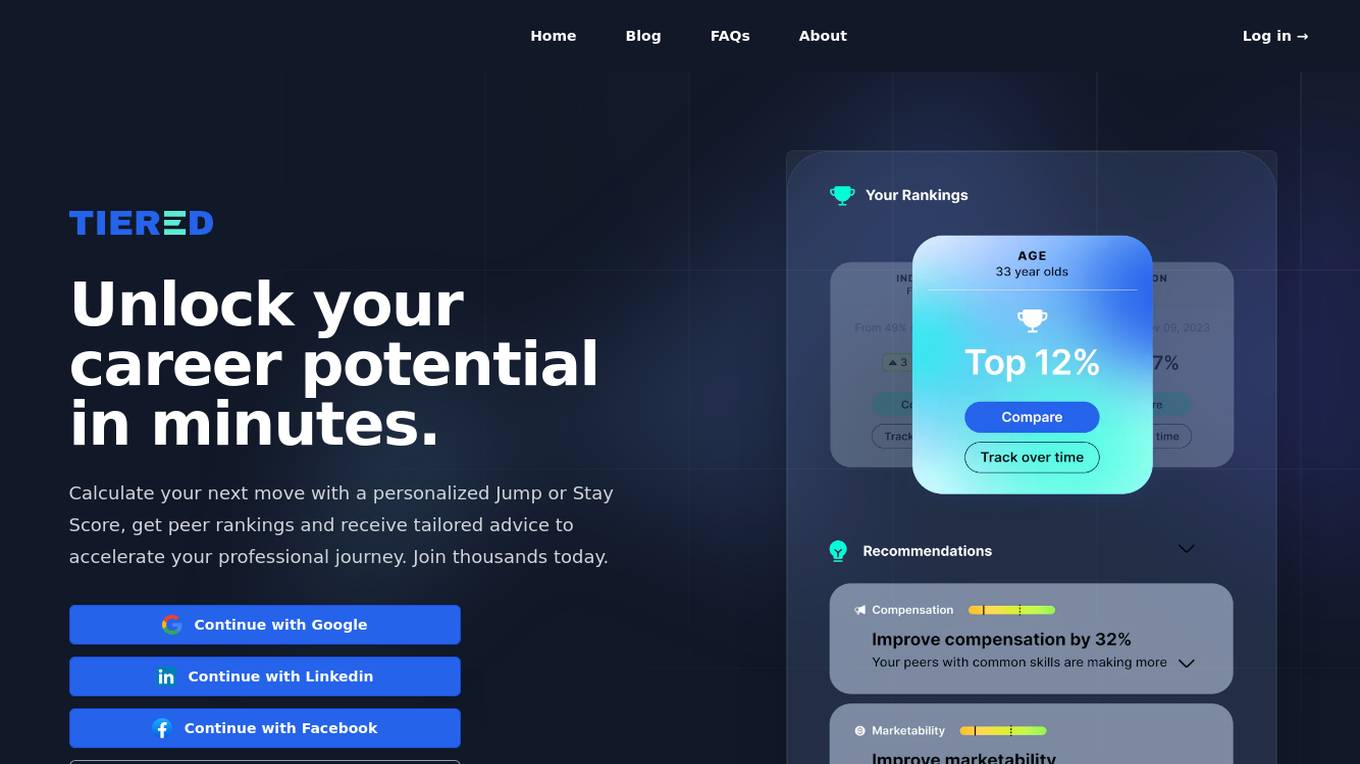
Tiered
Tiered is a career coaching platform that provides personalized advice and insights to help users make informed decisions about their careers. The platform uses AI to analyze user data and provide tailored recommendations on whether to stay in their current role or seek new opportunities. Tiered also provides users with peer rankings and expert guidance to help them accelerate their professional journey.
Enhancv
Enhancv is an AI-powered online resume builder that helps users create professional resumes and cover letters tailored to their job applications. The tool offers a drag-and-drop resume builder with a variety of modern templates, a resume checker that evaluates resumes for ATS-friendliness, and provides actionable suggestions. Enhancv also provides resume and CV examples written by experienced professionals, a resume tailoring feature, and a free resume checker. Users can download their resumes in PDF or TXT formats and store up to 30 documents in cloud storage.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

thisorthis.ai
thisorthis.ai is an AI tool that allows users to compare generative AI models and AI model responses. It helps users analyze and evaluate different AI models to make informed decisions. The tool requires JavaScript to be enabled for optimal functionality.

Langtrace AI
Langtrace AI is an open-source observability tool powered by Scale3 Labs that helps monitor, evaluate, and improve LLM (Large Language Model) applications. It collects and analyzes traces and metrics to provide insights into the ML pipeline, ensuring security through SOC 2 Type II certification. Langtrace supports popular LLMs, frameworks, and vector databases, offering end-to-end observability and the ability to build and deploy AI applications with confidence.
1 - Open Source AI Tools
avatar
AvaTaR is a novel and automatic framework that optimizes an LLM agent to effectively use provided tools and improve performance on a given task/domain. It designs a comparator module to provide insightful prompts to the LLM agent via reasoning between positive and negative examples from training data.
20 - OpenAI Gpts
Workshop Builder
Create an actionable plan for a workshop using expert facilitator knowledge

Rate My {{Startup}}
I will score your Mind Blowing Startup Ideas, helping your to evaluate faster.

Stick to the Point
I'll help you evaluate your writing to make sure it's engaging, informative, and flows well. Uses principles from "Made to Stick"

LabGPT
The main objective of a personalized ChatGPT for reading laboratory tests is to evaluate laboratory test results and create a spreadsheet with the evaluation results and possible solutions.

SearchQualityGPT
As a Search Quality Rater, you will help evaluate search engine quality around the world.

Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model


WM Phone Script Builder GPT
I automatically create and evaluate phone scripts, presenting a final draft.

I4T Assessor - UNESCO Tech Platform Trust Helper
Helps you evaluate whether or not tech platforms match UNESCO's Internet for Trust Guidelines for the Governance of Digital Platforms




Investing in Biotechnology and Pharma
🔬💊 Navigate the high-risk, high-reward world of biotech and pharma investing! Discover breakthrough therapies 🧬📈, understand drug development 🧪📊, and evaluate investment opportunities 🚀💰. Invest wisely in innovation! 💡🌐 Not a financial advisor. 🚫💼

B2B Startup Ideal Customer Co-pilot
Guides B2B startups in a structured customer segment evaluation process. Stop guessing! Ideate, Evaluate & Make data-driven decision.

Education AI Strategist
I provide a structured way of using AI to support teaching and learning. I use the the CHOICE method (i.e., Clarify, Harness, Originate, Iterate, Communicate, Evaluate) to ensure that your use of AI can help you meet your educational goals.

Competitive Defensibility Analyzer
Evaluates your long-term market position based on value offered and uniqueness against competitors.

Vorstellungsgespräch Simulator Bewerbung Training
Wertet Lebenslauf und Stellenanzeige aus und simuliert ein Vorstellungsgespräch mit anschließender Auswertung: Lebenslauf und Anzeige einfach hochladen und starten.