Best AI tools for< Evaluate A Model >
20 - AI tool Sites

Enhans AI Model Generator
Enhans AI Model Generator is an advanced AI tool designed to help users generate AI models efficiently. It utilizes cutting-edge algorithms and machine learning techniques to streamline the model creation process. With Enhans AI Model Generator, users can easily input their data, select the desired parameters, and obtain a customized AI model tailored to their specific needs. The tool is user-friendly and does not require extensive programming knowledge, making it accessible to a wide range of users, from beginners to experts in the field of AI.

BenchLLM
BenchLLM is an AI tool designed for AI engineers to evaluate LLM-powered apps by running and evaluating models with a powerful CLI. It allows users to build test suites, choose evaluation strategies, and generate quality reports. The tool supports OpenAI, Langchain, and other APIs out of the box, offering automation, visualization of reports, and monitoring of model performance.

SuperAnnotate
SuperAnnotate is an AI data platform that simplifies and accelerates model-building by unifying the AI pipeline. It enables users to create, curate, and evaluate datasets efficiently, leading to the development of better models faster. The platform offers features like connecting any data source, building customizable UIs, creating high-quality datasets, evaluating models, and deploying models seamlessly. SuperAnnotate ensures global security and privacy measures for data protection.
Frontier Model Forum
The Frontier Model Forum (FMF) is a collaborative effort among leading AI companies to advance AI safety and responsibility. The FMF brings together technical and operational expertise to identify best practices, conduct research, and support the development of AI applications that meet society's most pressing needs. The FMF's core objectives include advancing AI safety research, identifying best practices, collaborating across sectors, and helping AI meet society's greatest challenges.
Outlier AI
Outlier AI is a platform that connects subject matter experts to help build the world's most advanced Generative AI. It allows experts to work on various projects from generating training data to evaluating model performance. The platform offers flexibility, allowing contributors to work from home on their own schedule. Outlier AI aims to redefine how AI learns by leveraging the expertise of domain specialists across different fields.
Deepfake Detection Challenge Dataset
The Deepfake Detection Challenge Dataset is a project initiated by Facebook AI to accelerate the development of new ways to detect deepfake videos. The dataset consists of over 100,000 videos and was created in collaboration with industry leaders and academic experts. It includes two versions: a preview dataset with 5k videos and a full dataset with 124k videos, each featuring facial modification algorithms. The dataset was used in a Kaggle competition to create better models for detecting manipulated media. The top-performing models achieved high accuracy on the public dataset but faced challenges when tested against the black box dataset, highlighting the importance of generalization in deepfake detection. The project aims to encourage the research community to continue advancing in detecting harmful manipulated media.
LlamaIndex
LlamaIndex is a leading data framework designed for building LLM (Large Language Model) applications. It allows enterprises to turn their data into production-ready applications by providing functionalities such as loading data from various sources, indexing data, orchestrating workflows, and evaluating application performance. The platform offers extensive documentation, community-contributed resources, and integration options to support developers in creating innovative LLM applications.
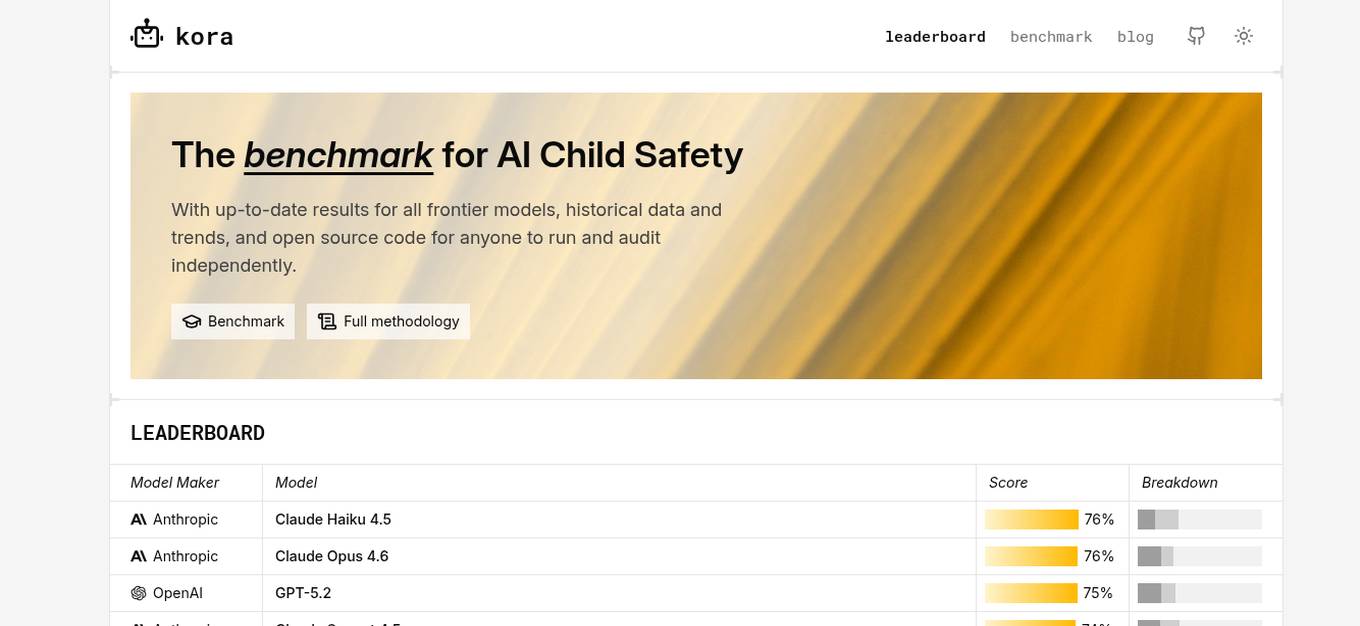
KORA Benchmark
KORA Benchmark is a leading platform that provides a benchmark for AI child safety. It offers up-to-date results for frontier models, historical data, and trends. The platform also provides open-source code for users to run and audit independently. KORA Benchmark aims to ensure the safety of children in the AI landscape by evaluating various models and providing valuable insights to the community.

Evidently AI
Evidently AI is an open-source machine learning (ML) monitoring and observability platform that helps data scientists and ML engineers evaluate, test, and monitor ML models from validation to production. It provides a centralized hub for ML in production, including data quality monitoring, data drift monitoring, ML model performance monitoring, and NLP and LLM monitoring. Evidently AI's features include customizable reports, structured checks for data and models, and a Python library for ML monitoring. It is designed to be easy to use, with a simple setup process and a user-friendly interface. Evidently AI is used by over 2,500 data scientists and ML engineers worldwide, and it has been featured in publications such as Forbes, VentureBeat, and TechCrunch.
Entry Point AI
Entry Point AI is a modern AI optimization platform for fine-tuning proprietary and open-source language models. It provides a user-friendly interface to manage prompts, fine-tunes, and evaluations in one place. The platform enables users to optimize models from leading providers, train across providers, work collaboratively, write templates, import/export data, share models, and avoid common pitfalls associated with fine-tuning. Entry Point AI simplifies the fine-tuning process, making it accessible to users without the need for extensive data, infrastructure, or insider knowledge.
AARENA
AARENA is an AI-powered platform that allows users to build fully functional apps and websites through simple conversations. It provides a user-friendly interface where individuals can create various digital products without the need for coding knowledge. AARENA leverages AI technology to streamline the development process and empower users to bring their ideas to life efficiently.
MLflow
MLflow is an open source platform for managing the end-to-end machine learning (ML) lifecycle, including tracking experiments, packaging models, deploying models, and managing model registries. It provides a unified platform for both traditional ML and generative AI applications.
Edelman
Edelman is an AI tool that focuses on enterprise marketing communications. It offers generative AI solutions to help marcom teams enhance decision-making, boost insights, and drive results. The tool provides key strategy elements for successful change management, evaluates analytics and social listening tools, and explores large language models for marketing and communications teams.
Respan
Respan is an AI observability platform designed to trace, evaluate, optimize, deploy, and monitor AI agents. It provides self-driving observability and evaluations for agents, allowing users to surface issues automatically, fix problems faster, and ensure that AI behaves as intended. The platform offers features such as tracing agent behavior, evaluating system performance, optimizing prompts and tools, deploying through a single gateway, and monitoring production shifts. Respan is loved by world-class founders, engineers, and product teams for its user-friendly interface and real-time observability capabilities.

Flow AI
Flow AI is an advanced AI tool designed for evaluating and improving Large Language Model (LLM) applications. It offers a unique system for creating custom evaluators, deploying them with an API, and developing specialized LMs tailored to specific use cases. The tool aims to revolutionize AI evaluation and model development by providing transparent, cost-effective, and controllable solutions for AI teams across various domains.

Maxim
Maxim is an end-to-end AI evaluation and observability platform that empowers modern AI teams to ship products with quality, reliability, and speed. It offers a comprehensive suite of tools for experimentation, evaluation, observability, and data management. Maxim aims to bring the best practices of traditional software development into non-deterministic AI workflows, enabling rapid iteration and deployment of AI models. The platform caters to the needs of AI developers, data scientists, and machine learning engineers by providing a unified framework for evaluation, visual flows for workflow testing, and observability features for monitoring and optimizing AI systems in real-time.
ZestyAI
ZestyAI is an artificial intelligence tool that helps users make brilliant climate and property risk decisions. The tool uses AI to provide insights on property values and risk exposure to natural disasters. It offers products such as Property Insights, Digital Roof, Roof Age, Location Insights, and Climate Risk Models to evaluate and understand property risks. ZestyAI is trusted by top insurers in North America and aims to bring a ten times return on investment to its customers.
Future AGI
Future AGI is a revolutionary AI data management platform that aims to achieve 99% accuracy in AI applications across software and hardware. It provides a comprehensive evaluation and optimization platform for enterprises to enhance the performance of their AI models. Future AGI offers features such as creating trustworthy, accurate, and responsible AI, 10x faster processing, generating and managing diverse synthetic datasets, testing and analyzing agentic workflow configurations, assessing agent performance, enhancing LLM application performance, monitoring and protecting applications in production, and evaluating AI across different modalities.
AI Innovation Platform
The AI Innovation Platform is a comprehensive suite of AI-powered tools designed to empower organizations in navigating their digital evolution journey. It offers a range of tools such as AI Adoption Assessment, User Personas, Future Scenarios, How Might We statement generator, Business Reinvention insights, AI Reinvention Blueprint, AI Strategy Matrix, and AI Transformation Simulator. These tools help organizations evaluate AI readiness, generate detailed user personas, explore future scenarios, transform challenges into opportunities, reinvent business models using AI, assess AI positioning, and simulate AI transformation strategies for informed decision-making.
Labelbox
Labelbox is a data factory platform that empowers AI teams to manage data labeling, train models, and create better data with internet scale RLHF platform. It offers an all-in-one solution comprising tooling and services powered by a global community of domain experts. Labelbox operates a global data labeling infrastructure and operations for AI workloads, providing expert human network for data labeling in various domains. The platform also includes AI-assisted alignment for maximum efficiency, data curation, model training, and labeling services. Customers achieve breakthroughs with high-quality data through Labelbox.
0 - Open Source AI Tools
20 - OpenAI Gpts
GPT Designer
A creative aide for designing new GPT models, skilled in ideation and prompting.

FinWiz
FinWiz-GPT is designed for finance professionals. It assists in market analysis, financial modeling, and understanding complex financial instruments. It's a great tool for financial analysts, investment bankers, and accountants.

HuggingFace Helper
A witty yet succinct guide for HuggingFace, offering technical assistance on using the platform - based on their Learning Hub


Instructor GCP ML
Formador para la certificación de ML Engineer en GCP, con respuestas y explicaciones detalladas.


Business Model Canvas Strategist
Business Model Canvas Creator - Build and evaluate your business model
Business Model Advisor
Business model expert, create detailed reports based on business ideas.
Startup Critic
Apply gold-standard startup valuation and assessment methods to identify risks and gaps in your business model and product ideas.
GPT Architect
Expert in designing GPT models and translating user needs into technical specs.

Pytorch Trainer GPT
Your purpose is to create the pytorch code to train language models using pytorch

Face Rating GPT 😐
Evaluates faces and rates them out of 10 ⭐ Provides valuable feedback to improving your attractiveness!

Startup Advisor
Startup advisor guiding founders through detailed idea evaluation, product-market-fit, business model, GTM, and scaling.