Best AI tools for< Enhance Image Understanding >
20 - AI tool Sites
Describe.pictures
Describe.pictures is an AI tool designed to generate detailed descriptions of images. By utilizing advanced AI models, users can quickly obtain complete descriptions of various images. The tool allows users to select an image and input the desired way of describing it, such as providing detailed or brief descriptions. The generated descriptions are detailed and vivid, capturing the essence and details of the image. With a focus on enhancing user experience and providing accurate image descriptions, Describe.pictures is a valuable tool for various applications.
Image Describer
Image Describer is an AI-powered image description generator that allows users to upload an image, select a use case, add additional information, and receive a detailed description of the image's content. It can summarize the content of the picture, describe physical objects, emotions, and atmosphere within the picture. The tool also offers Text-To-Speech ability to assist visually impaired individuals in understanding image content.
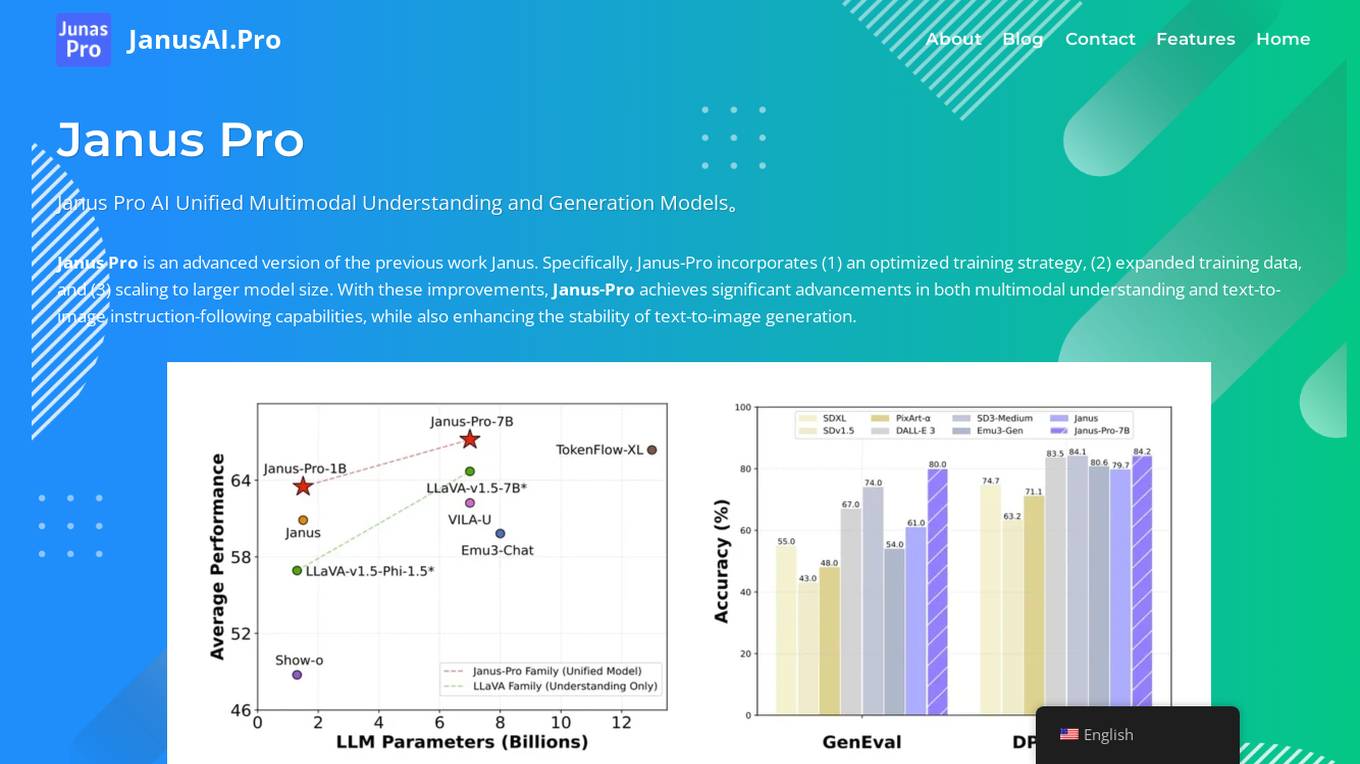
Janus Pro AI
Janus Pro AI is an advanced unified multimodal AI model that combines image understanding and generation capabilities. It incorporates optimized training strategies, expanded training data, and larger model scaling to achieve significant advancements in both multimodal understanding and text-to-image generation tasks. Janus Pro features a decoupled visual encoding system, outperforming leading models like DALL-E 3 and Stable Diffusion in benchmark tests. It offers open-source compatibility, vision processing specifications, cost-effective scalability, and an optimized training framework.
Nana Banana AI Image Editor
Nana Banana is a revolutionary AI image editor powered by Google Nano Banana Official API. It offers advanced natural language understanding, exceptional character consistency, and one-shot editing perfection. Users can create stunning images by leveraging cutting-edge technology to transform text prompts into visual reality with precision.

Imagen
Imagen is an AI application that leverages text-to-image diffusion models to create photorealistic images based on input text. The application utilizes large transformer language models for text understanding and diffusion models for high-fidelity image generation. Imagen has achieved state-of-the-art results in terms of image fidelity and alignment with text. The application is part of Google Research's text-to-image work and focuses on encoding text for image synthesis effectively.
Nano Banana AI Image Creator & Editor
Nano Banana AI Image Creator & Editor is an advanced AI platform that allows users to create and edit images instantly with simple prompts. It leverages cutting-edge Nano Banana AI technology to effortlessly craft exceptional artwork, illustrations, and visual content. The platform offers a streamlined journey from creative idea to stunning visual content, providing features like character consistency, multi-image context understanding, and instant generation. Users can enhance their creations with powerful editing tools and export high-resolution images for various platforms. Nano Banana AI revolutionizes visual content creation with unmatched precision, consistency, and ease-of-use.
Flux Image AI Generator
Flux Image AI Generator is an online tool that utilizes advanced AI technology to transform text prompts into high-quality images in seconds. It offers a range of models catering to different needs, from commercial projects to non-commercial experimentation. With features like image-to-image generation and advanced language understanding, Flux Image AI Generator provides users with unprecedented creative control and speed in generating visuals.
Kling2.5
Kling2.5 is an AI-powered video generator that offers studio-grade video creation with advanced reasoning capabilities. It delivers cost-optimized video generation, superior motion flow, and understanding of complex causal relationships and temporal sequences. Kling2.5 Turbo provides features like native HDR video output, draft mode for rapid iteration, and enhanced style consistency. The application is suitable for professional video content creation, commercial projects, and various industries.
VirtualFantasy.ai
VirtualFantasy.ai is an AI-powered virtual companion platform that utilizes advanced artificial intelligence algorithms to provide users with personalized assistance and companionship. The platform offers a wide range of features such as virtual conversations, emotional support, task reminders, entertainment recommendations, and personalized insights. VirtualFantasy.ai aims to enhance users' daily lives by offering a virtual companion that can engage in meaningful interactions and provide support whenever needed.

MiniGPT-4
MiniGPT-4 is a powerful AI tool that combines a vision encoder with a large language model (LLM) to enhance vision-language understanding. It can generate detailed image descriptions, create websites from handwritten drafts, write stories and poems inspired by images, provide solutions to problems shown in images, and teach users how to cook based on food photos. MiniGPT-4 is highly computationally efficient and easy to use, making it a valuable tool for a wide range of applications.
Nano Banana
Nano Banana is an advanced AI image editing tool that combines natural language prompts with intelligent prompt understanding to deliver precise and high-quality image transformations. It excels in maintaining consistent characters, preserving scene context, and generating realistic style transformations. With features like one-shot editing, multi-image support, and reliable multi-character adjustments, Nano Banana revolutionizes the creative workflow for professionals and everyday users alike.
PixelPet
PixelPet is an AI-powered online tool that offers stable diffusion instant access to hundreds of models for generating hyper-realistic images in 1344x768px resolution. It provides universal understanding with auto-translation for all languages and features Prompt Magic to boost prompts for awesome results. Empowered by the latest Stable Diffusion models, PixelPet allows users to create stunning images for free straight from their favorite messenger app.
Janus Pro
Janus Pro is a free online AI image generator that leverages advanced multimodal processing to analyze and create high-quality images. It outperforms models like DALL-E 3 and Stable Diffusion, delivering exceptional detail and accuracy. Built on DeepSeek-LLM architecture with 7 billion parameters, Janus Pro features separate encoding pathways for enhanced flexibility. The application is freely available on Hugging Face, trained on millions of samples for multimodal understanding and visual generation.

Walle
Walle is an all-in-one AI assistant and browser extension that provides a range of features to enhance your digital experience. It includes a chatbot for instant problem-solving, an AI reader for summarizing and understanding text, an AI writer for generating human-like content, a chat PDF feature for summarizing and translating PDF documents, and image creation and reading capabilities. Walle is seamlessly integrated into Chrome, Safari, and Edge browsers, making it your indispensable companion for navigating the digital world.
BetterWaifu
BetterWaifu is an AI tool that serves as an NSFW AI Generator and Imageboard. It is designed to create high-quality hentai images based on user preferences. The tool boasts of understanding user requirements accurately to generate desired content. BetterWaifu offers a range of features and functionalities to enhance the user experience in creating explicit content. The platform is committed to providing a safe and private environment for users to explore their creative desires.
AI-PRO
AI-PRO.org is an artificial intelligence resource website that serves as the ultimate destination for learning and discovering all things AI. From the latest technologies and trends to expert insights and resources, users can find everything they need to maximize their AI knowledge and skills. Whether beginners or professionals, AI-PRO covers a wide range of AI topics, including image AI, AI chatbots, AI text generators, and much more, catering to a diverse audience seeking to enhance their understanding and proficiency in artificial intelligence.
Snippai
Snippai is an AI-powered snipping tool that offers advanced features such as identifying formulas, extracting text, recognizing tables, analyzing images, solving problems, understanding code snippets, and extracting colors. It leverages artificial intelligence to enhance the snipping experience and provide users with accurate and efficient results.
Qwen
Qwen is an AI tool that focuses on developing and releasing various language models, including dense models, coding models, mathematical models, and vision language models. The Qwen family offers open-source models with different parameter ranges to cater to various user needs, such as production use, mobile applications, coding assistance, mathematical problem-solving, and visual understanding of images and videos. Qwen aims to enhance intelligence and provide smarter and more knowledgeable models for developers and users.
Grok AI Image Generator | Grok 2.0
Grok AI Image Generator | Grok 2.0 is an AI image generator that leverages the power of AI to create stunning and diverse images. It is an open-source large language model AI developed by Elon Musk, offering enhanced language understanding, code capabilities, and drawing features. Users can generate high-quality, photorealistic images with minimal content restrictions, powered by the FLUX.1 model for advanced capabilities.
Studyable
Studyable is an AI-powered platform designed to assist students with homework help and flashcards. The application leverages artificial intelligence technology to provide personalized learning experiences for users. With Studyable, students can access a wide range of study materials, practice questions, and interactive flashcards to enhance their understanding of various subjects. The platform aims to make studying more efficient and engaging by offering tailored recommendations and adaptive learning features. Studyable is a valuable tool for students seeking academic support and looking to improve their study habits.
0 - Open Source AI Tools
20 - OpenAI Gpts
Image Descriptor for Image Generation
Upload image, then Expert image describer providing detailed and specific descriptions of images.
Comment Engagement
Expert in crafting concise, personal, and motivational social media comments

AI Image Creative Trainer
Dive into the world of AI image creation with DALL-E 3 training! Learn to craft stunning visuals, from portraits to modern art. Get personalized feedback, unique prompts, and expert guidance to enhance your skills and unleash your creativity.
DeepGame
Play any story as a character. You decide what to do next. AI generates a new image for each step to enhance immersion.
UpScaler
DALL-E user? Resize/de-noise images or uploads! Print & show-off your masterpiece or display in 4K! Supports 0.5x-4x to poster size. Abbreviations support. Enter your image prompt or, "m" for a menu to begin.
Hemingway Helper
Aids in writing narratives and descriptions in Hemingway's style. Give me the plot, idea or upload the image

Image cloner
From an attached image, the bot will generate a prompt to replicate the image in a digital art bot such as Midjourney or DALL-E
Image Recreator
Upload an image to recreate it using DALL-E 3. Each request should include 3 images with unique IDs and corresponding Midjourney prompts. You can instruct GPT to make modifications to a specific image by ID or recreate images using Midjourney. —公众号:Vito的AI力量