Best AI tools for< Dub Content >
20 - AI tool Sites

TransDub
TransDub is an AI-powered tool that enables users to automatically translate and dub YouTube videos into multiple languages with natural human-like voices. It supports translating to 29+ languages, provides unique voices for each speaker, and allows for closed captions/SRT. The tool simplifies the process of translation and dubbing, helping content creators reach a wider audience by removing language barriers. TransDub is designed to be user-friendly, offering features like direct YouTube publishing and easy import options.
Typecast
Typecast is an online AI voice generator and content creation tool that offers advanced AI voice models for creating natural and expressive voiceovers. With over 530 unique voices to choose from, Typecast's AI voice actors excel in narrating audiobooks, enhancing video games, creating rap music, delivering announcements, and crafting compelling marketing messages. The tool utilizes machine learning to produce lifelike speech with correct intonation, pausing, and breathing between words. Users can effortlessly create professional voice content, clone their own AI voice actors, and integrate voiceovers with video files for quick and easy content production.
DubSync.AI
DubSync.AI is an AI-powered dubbing system that allows users to automatically translate and dub their content into over 20 languages. It is a cloud-based platform that is easy to use and requires no technical expertise. With DubSync.AI, users can quickly and easily create high-quality dubbed videos that can be used for a variety of purposes, such as marketing, education, and entertainment.
Dub AI
Dub AI is an AI-powered video localization platform that enables users to translate and dub their videos into multiple languages with ease. It offers a range of features such as voice cloning, multi-speaker support, and seamless translation, making it an ideal tool for content creators, businesses, and individuals looking to expand their global reach.

Dubbah
Dubbah is an AI-powered dubbing solution designed for short-form content. It allows users to translate and dub their videos into 28 different languages, while preserving the original voice and background music. Dubbah's state-of-the-art voice cloning technology ensures that the dubbed videos sound natural and authentic.
VoiceCheap
VoiceCheap is an AI-powered application that offers dubbing, transcription, and speech synthesis services. It enables users to translate videos into multiple languages, clone voices, generate subtitles, remove background noise, and more. With features like SmartSync Technology and multi-speaker dubbing, VoiceCheap helps content creators produce professional-quality dubbed videos efficiently. The application uses advanced AI technology to provide cost-effective dubbing solutions and seamless integration with various platforms. VoiceCheap is trusted by professionals and loved by users worldwide for its innovative tools and services.
DubSmart
DubSmart is an AI-powered platform that offers advanced video dubbing and voice cloning services. It allows users to transform text into lifelike speech, dub videos with voice cloning technology, and generate subtitles for audio or video content. With a user-friendly interface, DubSmart enables users to create unique voices, edit projects, and download finished projects in various formats. The platform supports 33 languages for AI dubbing and 60+ languages for speech-to-text conversion. DubSmart caters to small creators, YouTubers, and companies looking to enhance their audiovisual content with personalized voices and multilingual capabilities.
UniDub
UniDub is a multi-lingual AI dubbing platform that allows users to create or dub videos in over 40 languages. It is cost-effective, expressive, super fast, and easy to use. UniDub can be used for a variety of purposes, including dubbing videos, creating animated videos, making audiobooks, and creating custom avatars and voices.
Unmixr AI
Unmixr AI is a suite of AI products that includes AI Voiceover, Audio/Video Dubbing, AI Chat & Copywriting tools (AI Templates, AI Writing Editor, AI Chat, and AI Image Generator). With Unmixr AI, you can create realistic voiceovers, dub audio/video files, engage in dynamic chat conversations, refine your writing with AI assistance, generate stunning visuals, and more. Unmixr AI is designed to streamline your creative workflow and enhance your content effortlessly. It empowers your creativity and opens doors to endless possibilities, allowing you to unleash your imagination and captivate your audience.
Yepic AI
Yepic AI is a comprehensive AI tool that offers a range of innovative solutions for creating AI videos, real-time avatars, and interactive video agents. The platform leverages advanced technologies such as facial recognition, emotional intelligence, and multilingual capabilities to provide engaging and personalized experiences. With features like lifelike avatar animation, contextual answers, and extensive language support, Yepic AI is designed to cater to various industries and use cases. The tool is developer-friendly with API documentation and research-backed projects, making it a versatile choice for businesses looking to integrate AI into their operations.
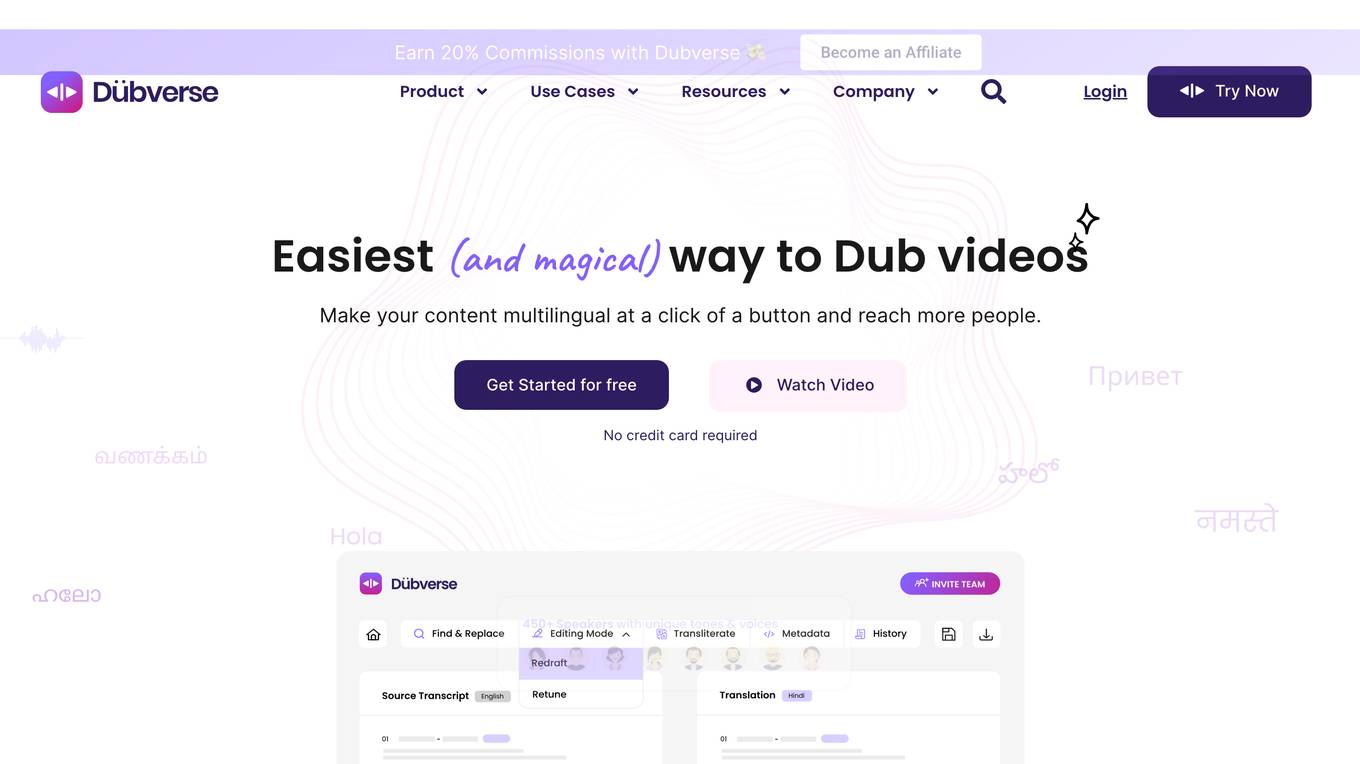
Dubverse
Dubverse is an AI-powered platform offering services like AI Video Dubbing, AI Subtitles, and Text-to-Speech. It provides users with the ability to generate realistic AI voiceovers, translate videos into different languages, and create accurate subtitles. With features like Multi-Speaker Voice Cloning and Emotive Voiceovers, Dubverse aims to deliver high-quality audio solutions for various projects. The platform also offers developer-friendly APIs for seamless integration of lifelike voices into chatbots, apps, and websites, making it easier to scale voice solutions across different projects.
Vidby
Vidby is an AI-powered software designed for rapid and accurate video and document translation, subtitling, and dubbing. It offers a range of services including video translation, document translation, subtitles, and text-to-speech. With advanced technologies of understanding, Vidby provides automated solutions that are x1000 faster and x10 more cost-effective. Trusted by over 2000 companies in 70 countries, Vidby is a reliable tool for various translation needs.
SteosVoice
SteosVoice (formerly CyberVoice) is an AI tool that provides high-quality neural voice AI for everyone. It offers a wide range of voices and speech synthesis technology to create unique content, dub videos, podcasts, and more. With over 800 voices and growing, SteosVoice is a leader in sound generation quality thanks to unique AI developments. The platform allows users to monetize their voice, license their voice for passive income, and offers a free Telegram bot for convenient access to voice synthesis. SteosVoice is used by YouTubers, businesses, media, indie game developers, and more for various voice-related tasks.
Captions App
Captions App is an AI-powered subtitles and captions application designed to help content creators easily subtitle their videos in multiple languages. The app offers features such as auto-subtitle generation, video translation, AI video dubbing, teleprompter functionality, and AI script generation. With a user-friendly interface and advanced AI technology, Captions App enables users to customize subtitles, add animations, and dub videos with their own voice in over 100 languages. The app aims to make video content more accessible, engaging, and globally appealing.
Respeecher
Respeecher is a voice cloning software that allows users to create synthetic voices that are indistinguishable from the original speaker. The software is used by content creators in a variety of industries, including film, television, gaming, advertising, and audiobooks. Respeecher's technology is based on artificial intelligence and machine learning, and it can replicate the voice of any person with just a few minutes of audio recording. The software is easy to use and can be accessed through a web interface. Respeecher offers a variety of features, including the ability to change the pitch, speed, and volume of the synthetic voice, as well as the ability to add effects such as reverb and delay. The software also includes a library of pre-recorded voices that can be used for a variety of purposes.
CAMB.AI
CAMB.AI is a leading AI-powered localization tool for content, entertainment, and sports industries. It offers real-time translation services in over 150 languages, catering to a wide audience of 8 billion people. Trusted by major entertainment and sports brands, CAMB.AI sets the gold standard in AI-powered localization, ensuring every nuance and emotion is accurately conveyed. The tool has been instrumental in scaling content for top creators, dubbing movies and sports events, and breaking language barriers in various media formats.
TTSMaker
TTSMaker is a free online text-to-speech tool that allows users to convert text into natural-sounding speech. It supports multiple languages and voices, and the resulting audio files can be downloaded for free and used for commercial purposes. TTSMaker is a valuable tool for creating audiobooks, dubbing videos, and other projects that require high-quality voiceovers.

AITransDub
AITransDub is an AI-powered video translation and dubbing tool that breaks language barriers instantly. It offers precise and natural translations while maintaining the warmth and authenticity of the original content. With support for over 50 languages and hundreds of voice options, AITransDub provides smart voice synthesis for a natural pronunciation with authentic emotion. The tool also supports multi-language translation, enabling users to connect with a global audience. AITransDub simplifies the video translation process with its multi-step contextual translation and easy operation, making it a valuable tool for content creators and businesses looking to reach a diverse audience.
Soca AI
Soca AI is a company that specializes in language and voice technology. They offer a variety of products and services for both consumers and enterprises, including a custom LLM for enterprise, a speech and audio API, and a voice and dubbing studio. Soca AI's mission is to democratize creativity and productivity through AI, and they are committed to developing multimodal AI systems that unleash superhuman potential.
Murf AI
Murf AI is a versatile text-to-speech software that simplifies business communication. It offers a range of solutions for various projects, including voiceovers, translations, and AI dubbing, ensuring clear, engaging, and far-reaching messages. With over 120 voices in 20+ languages, Murf AI empowers users to create realistic voiceovers that enhance content accessibility and engagement. Its voice cloning feature allows for the creation of near-perfect voice twins, ensuring intellectual property rights and delivering a realistic audio experience. Murf AI's AI dubbing service enables businesses to take their stories to a global audience with over 20 languages available, promoting universal understanding and cultural connectivity. Additionally, Murf AI's translation service simplifies the translation of business content into more than 20 languages, facilitating seamless international engagement. The Murf API allows developers to integrate high-quality voices into their digital platforms, ensuring a consistent brand voice across various applications. Murf Voices Installer adds favorite Murf voices to Windows systems, enabling users to enjoy them on any Microsoft SAPI-supported platform.