Best AI tools for< Download Voices >
20 - AI tool Sites
VoiceSona
VoiceSona is an AI-powered voice changer application that allows users to transform their voice to sound like anyone they want. With a lag-free experience, users can change their voice across various platforms such as Roblox, phone calls, OBS, VRChat, and Discord. The application offers thousands of voices including singers, villains, rappers, presidents, and actors, providing a new level of voice-changing technology.
Tiktok AI Voice
Tiktok AI Voice is an AI-powered tool that allows users to convert text into popular TikTok voices with natural and fluent audio suitable for various scenarios. The website offers multiple voice styles, instant download, user-friendly interface, high-quality audio, and multilingual support. Users can generate voices in different languages and dialects, customize speech rate and tone, and download the audio files for free. The tool is praised for its simplicity, variety of voice styles, and security features.
TikTok Voice
TikTok Voice is a free online AI text-to-speech tool that transforms text into various TikTok voices like the popular lady voice, Siri, Rocket, and Ghostface. Users can generate voices for video editing, text reading, and e-books. The tool offers a convenient way for video editing on PC and provides voices not available in the TikTok app. Users can easily choose the language and voice accent, type the text, generate the voice, and download it. For specific voice requests, users can email [email protected].
TikTok Voice Generator
The TikTok Voice Generator is a free text-to-speech tool that allows users to transform text into various TikTok voices, such as popular lady voice, rocket, Ghostface (scream), and many more. It supports multiple languages and voice styles, giving users the option to download the generated voice for various purposes like reading text aloud, creating content, or editing. The tool offers a user-friendly interface and a wide range of voice options to cater to different preferences and needs.
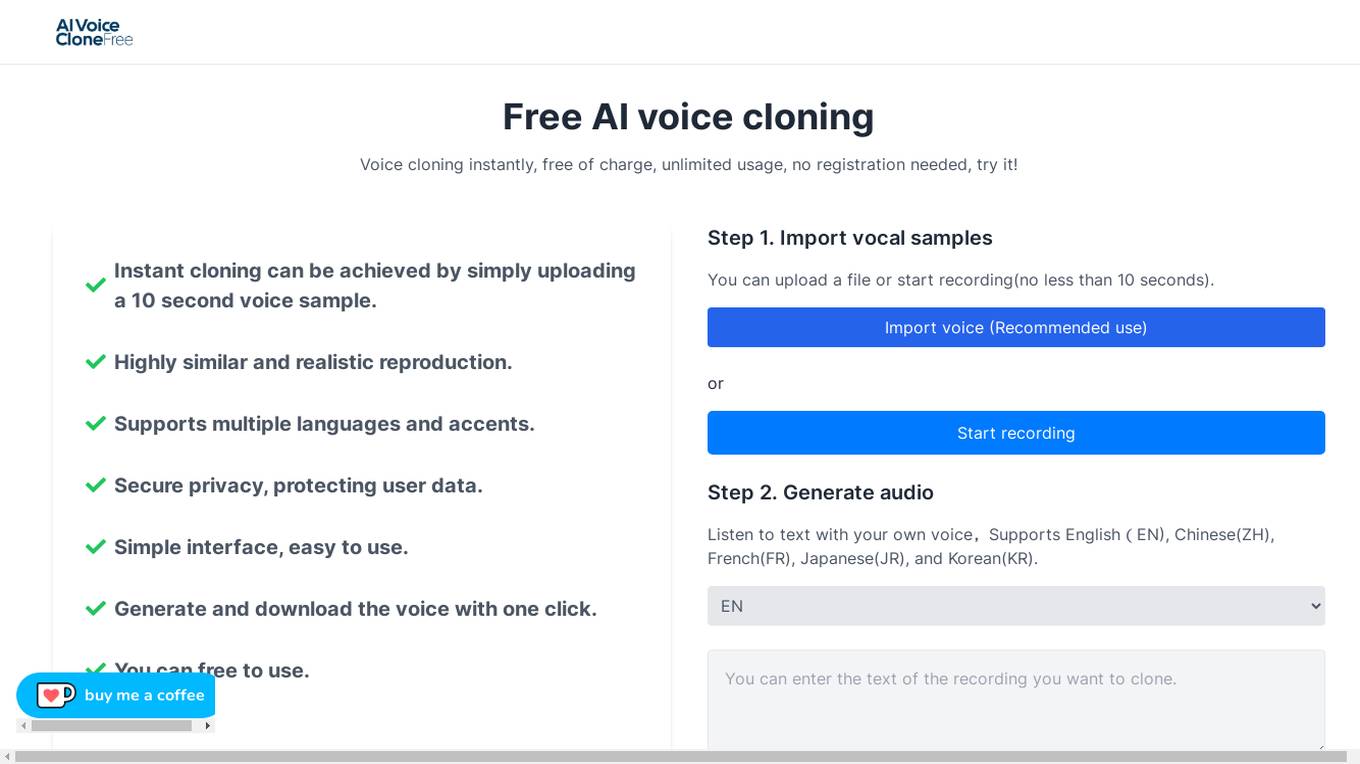
Woy AI Tools
Woy AI Tools is a free AI voice cloning application that allows users to instantly clone voices with high similarity and realism. Users can upload a 10-second voice sample to generate and download cloned voices in multiple languages and accents. The tool ensures secure privacy and offers a simple interface for easy usage.
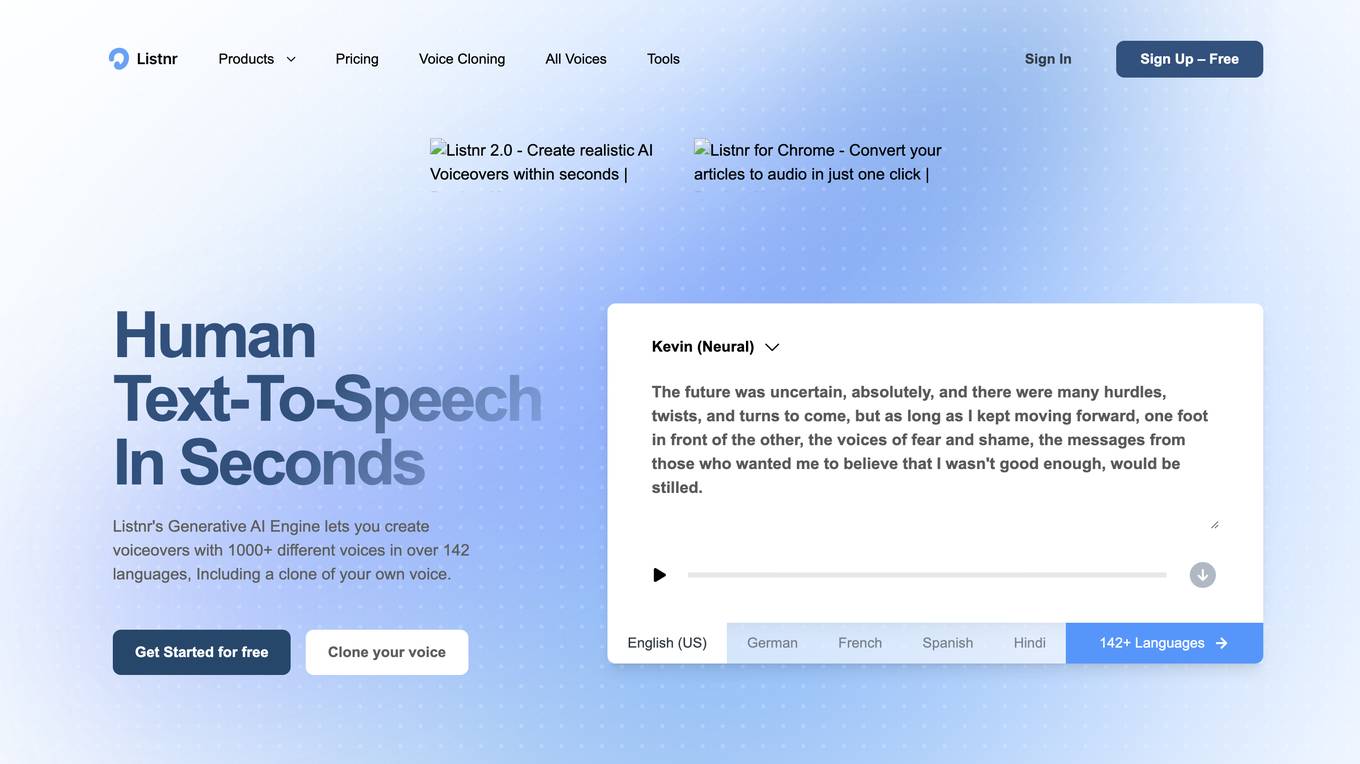
Listnr AI
Listnr AI is a leading AI voice generator tool that offers ultra-realistic AI voices indistinguishable from humans. With over 1000 different voices in more than 142 languages, including voice cloning capabilities, Listnr AI is trusted by 2,500,000+ users worldwide. The tool allows users to create voiceovers for various content types such as shorts, TikToks, YouTube videos, gaming, podcasts, sales, social media, and audiobooks. Listnr AI's state-of-the-art generative AI technology ensures that the voiceovers sound extremely natural, providing a seamless experience for content creators. Additionally, Listnr AI offers features like emotion fine-tuning, punctuations, pauses, and a wide range of multi-lingual voices to cater to diverse content needs.
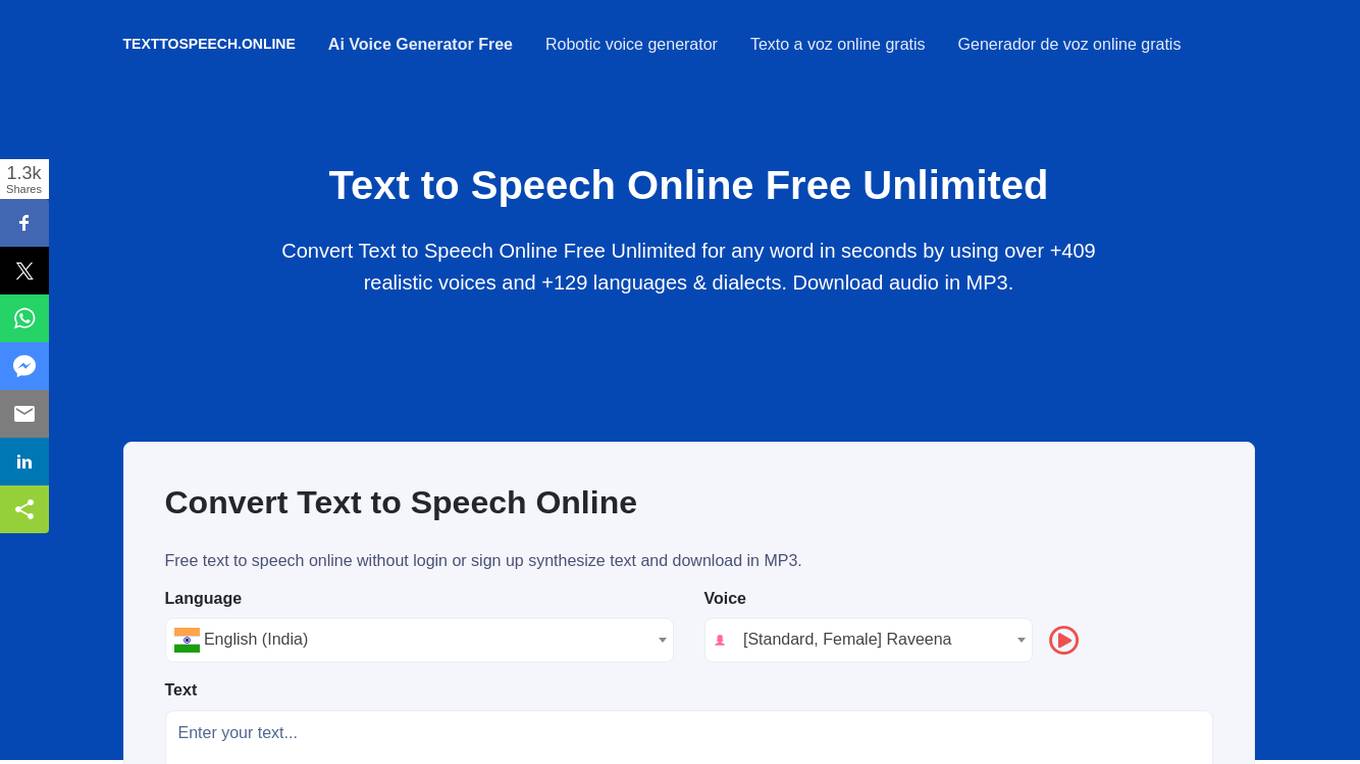
Text to Speech Online
Text to Speech Online is a free AI tool that offers unlimited text-to-speech conversion with over 409 realistic voices and 129 languages & dialects. Users can convert text to speech in seconds without the need to log in or sign up. The tool supports multiple languages and accents, including standard voices and AI voices, and offers flexible pricing models. Users can enjoy a full set of SSML features, create natural-sounding speech, download audio in MP3 or WAV formats, and share results on various platforms. Text to Speech Online is a versatile tool that can be used for various purposes, including providing audio cues for visually impaired users, assisting in education, creating audio versions of books, and developing virtual assistants.
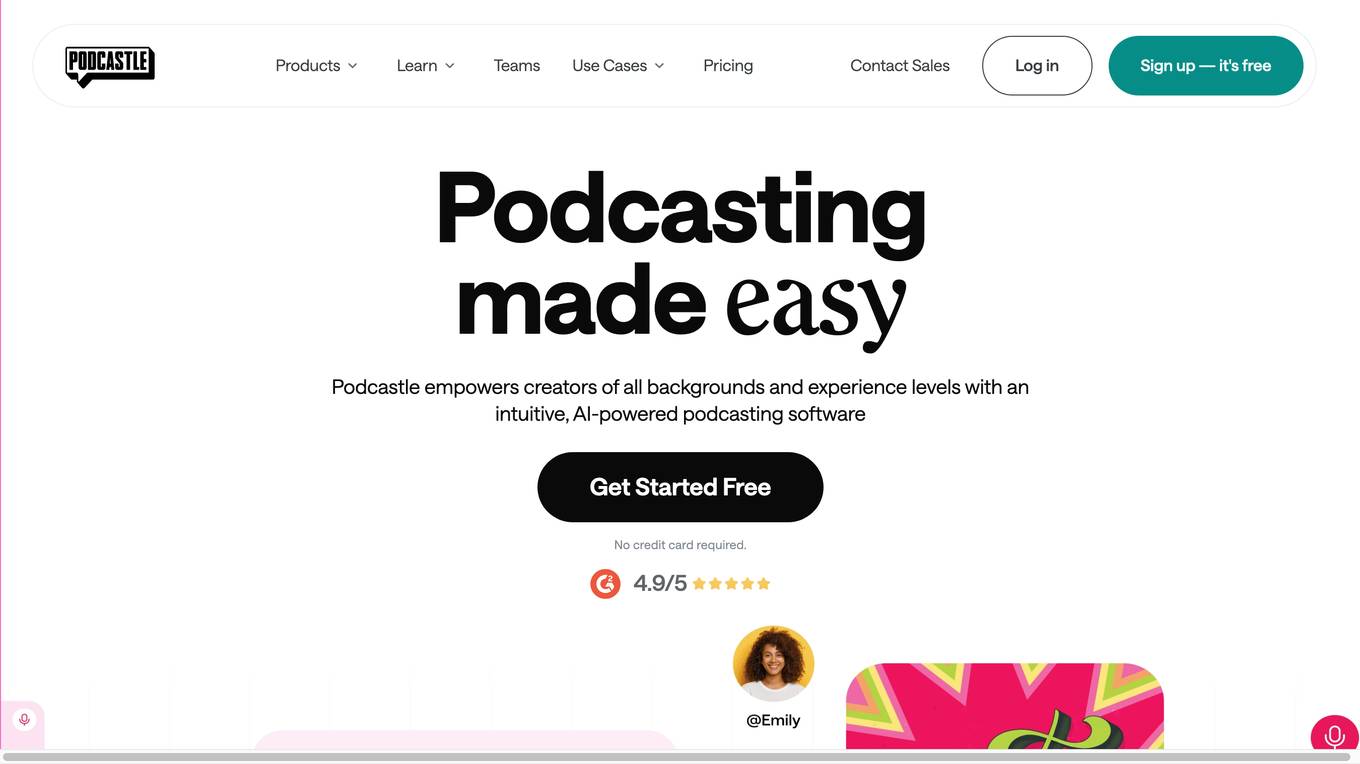
Podcastle
Podcastle is an all-in-one podcasting software that empowers creators of all backgrounds and experience levels with an intuitive, AI-powered platform. It offers a wide range of features, including a recording studio, audio editor, video editor, AI-generated voices, and hosting hub, making it easy to create, edit, and publish high-quality podcasts and videos. Podcastle is designed to be user-friendly and accessible, with no prior experience or technical expertise required.
TTS Generator AI
TTS Generator AI is a free online text-to-speech tool that leverages cutting-edge AI technology to convert written text into high-quality, natural-sounding audio. This tool is invaluable for a variety of users, including students who need auditory learning materials, researchers who want to listen to long documents, and professionals seeking to make their written content more accessible. One of the standout features of TTS Tool is its ability to support a range of text formats, from simple text files to complex PDFs, making it incredibly versatile.
Woord
Woord is an online text-to-speech (TTS) tool that allows users to convert text into natural-sounding speech. It offers a wide range of voices in over 34 languages, including regional variations. Woord also provides advanced features such as SSML editing, OCR support, and API access. With its user-friendly interface and affordable pricing, Woord is a great choice for individuals and businesses looking to add speech capabilities to their applications.
PlayAI
PlayAI is a powerful AI voice generator and text-to-speech platform that offers a wide range of features to create natural-sounding voiceovers in multiple languages. With over 206 AI voices, users can generate audio content for various purposes such as audiobooks, YouTube videos, documentaries, and more. The platform also provides customization options like speech styles, pronunciations, and voice inflections to enhance the quality of generated voices. PlayAI's API integration allows seamless incorporation into different platforms, making it suitable for a wide range of applications from e-learning to gaming.
Beepbooply
Beepbooply is a text-to-speech tool that uses artificial intelligence to generate realistic and natural-sounding speech. With over 900 voices to choose from, you can create audio content for any purpose, including videos, podcasts, and customer service. Beepbooply is easy to use and affordable, making it a great option for anyone who needs to create high-quality audio content.
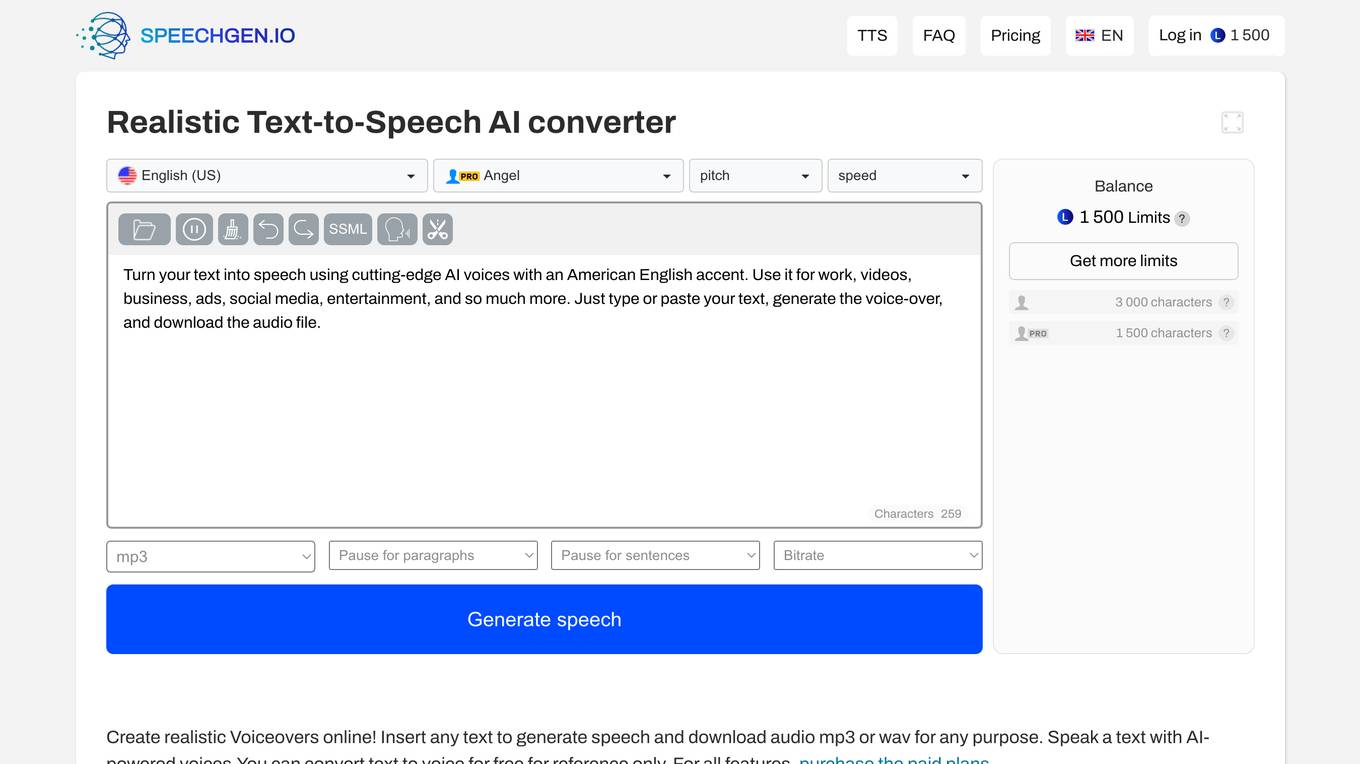
SpeechGen.io
SpeechGen.io is a realistic text-to-speech converter and AI voice generator that allows users to convert text into speech using cutting-edge AI voices with an American English accent. With SpeechGen.io, users can create realistic voiceovers for videos, e-learning materials, advertising, public announcements, podcasts, mobile apps, presentations, and more. The platform offers a wide range of features, including the ability to download converted audio files in MP3, WAV, and OGG formats, support for long texts, commercial use of generated audio, multi-voice editing, custom voice settings, SSML support, and more. SpeechGen.io is accessible in any browser and offers an intuitive interface suitable for beginners. The platform also provides powerful support and is compatible with various editing programs.
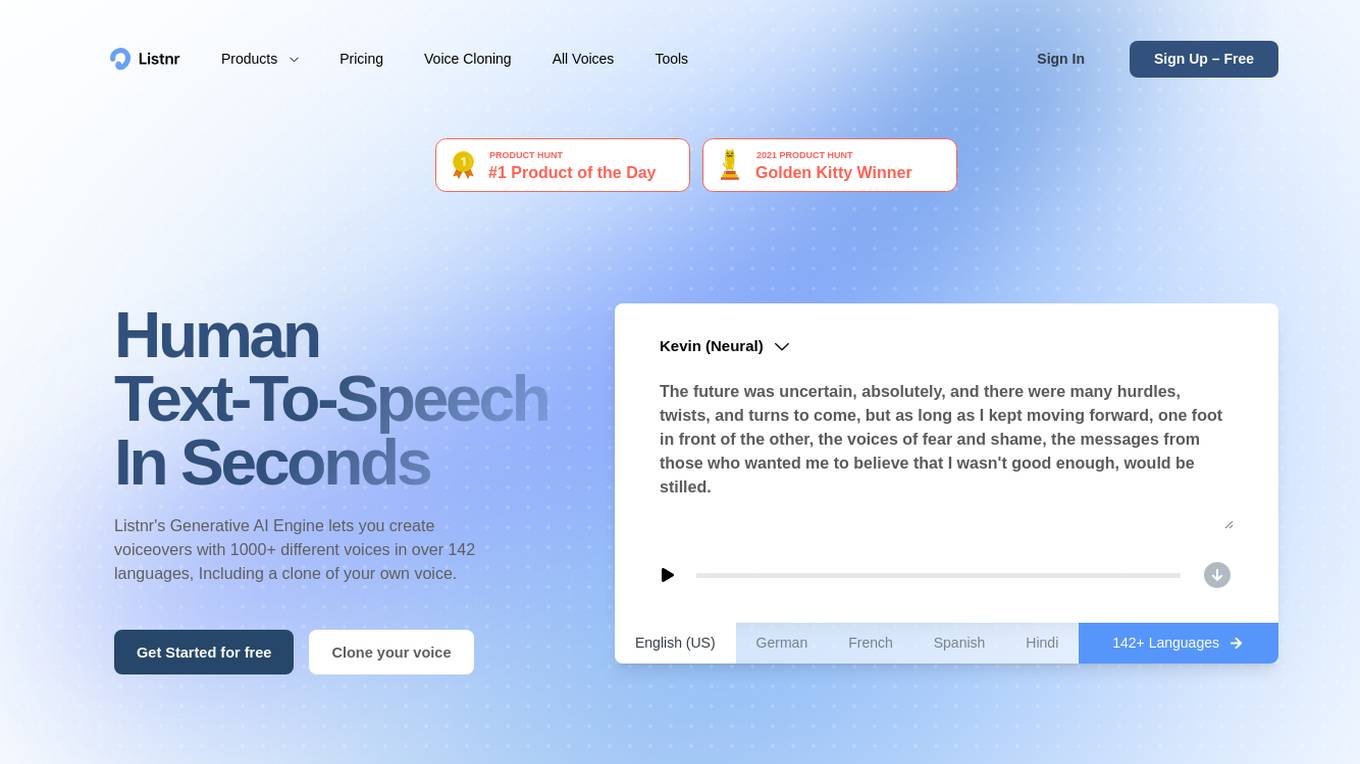
Listnr
Listnr is a generative AI text-to-speech and text-to-video tool that allows users to create voiceovers and videos with realistic AI voices in over 142 languages. With over 1000 different voices to choose from, users can create natural-sounding voiceovers for a variety of purposes, including podcasts, YouTube videos, e-learning courses, and more. Listnr also offers a range of features to help users customize their voiceovers, including pitch, speed, and pronunciation controls. In addition to text-to-speech, Listnr also offers a text-to-video feature that allows users to create videos from text with AI-generated voices and visuals.
Lovevoice AI Voice Generator
Lovevoice is an AI Voice Generator that transforms text into natural-sounding speech using AI technology. It offers over 70 languages and nearly 300 AI voices, customizable voice settings, file transcription support, and MP3 download capabilities. Lovevoice's advanced AI ensures generated voiceovers are human-like, making it ideal for various applications such as videos, podcasts, audiobooks, and personalized audio messages. Users can quickly convert text into high-quality audio files with multilingual global support.
Neuralarts
Neuralarts is an all-in-one generative AI art platform that allows users to create AI-generated artwork, animations, music, and speech. The platform is easy to use and requires no prior experience with AI. Users can simply input a text prompt and the platform will generate a unique piece of artwork, animation, music, or speech. Neuralarts is a great tool for artists, designers, musicians, and anyone else who wants to create unique and innovative content.
TEXTTOSPEECH.IM
TEXTTOSPEECH.IM is an advanced text to speech tool that utilizes artificial intelligence to convert text to lifelike audio. Users can easily generate and download high-quality speech in multiple languages and voice styles. The tool supports enhanced accessibility, cost-effective content creation, a wide range of voices, convenient offline use, high accuracy in speech synthesis, and cross-device compatibility for maximum flexibility.
Sound of Text
Sound of Text is a free online text-to-speech converter that uses AI technology to convert written text into spoken words. It supports over 840 different voices in more than 135 languages, and allows users to download the resulting audio files in a variety of formats. Sound of Text is easy to use and can be used for a variety of purposes, such as creating audiobooks, podcasts, and presentations.

ttsMP3.com
ttsMP3.com is a free Text-To-Speech and Text-to-MP3 tool that allows users to easily convert US English text into professional speech for various purposes such as e-learning, presentations, YouTube videos, and website accessibility. The tool offers a wide range of voices in different languages and accents, including regular and AI voices. Users can download the generated speech as MP3 files, and customize speech with features like breaks, emphasis, speed adjustments, pitch variations, whispers, and conversations. Supported voice languages include Arabic, English, Portuguese, Spanish, Chinese, Danish, Dutch, French, German, Icelandic, Indian, Italian, Japanese, Korean, Mexican, Norwegian, Polish, Romanian, Russian, Swedish, Turkish, and Welsh.
Voicemod
Voicemod is a free real-time voice changer and soundboard available on both Windows and macOS. It allows users to change their voice in real-time, add sound effects, and create custom voices. Voicemod integrates with popular games, streaming software, and chat applications, making it a versatile tool for gamers, content creators, and anyone who wants to add some fun to their voice communication.
0 - Open Source AI Tools
20 - OpenAI Gpts
Your Lingo AI Coach
Welcome! I'm a voice-focused language teacher for interactive speaking practice. To enable voice, download the app and tap the headphone button next to my chat window. Then choose your preferred voice. When you're ready, tell me what language you'd like to learn. It's FREE!
Slide Maker and Free Download
create professional consulting slide with preview on chatgpt and free download as pptx

universal Music Downloader
Assists in finding music download platforms, prioritizes free options.
Downloader
Download data from the internet. Fetch the content of sites and make it available to the session, given a URL.

ChatGaia
I help you to explore the galaxy by answering astronomy questions with the Gaia Space Telescope. Ask a question, download .csv, upload .csv for plotting

Public Domain PDF Books Finder📚
Public Domain PDF Books Finder GPT offers an expansive library of PDFs for easy search and download. It now specializes in finding public domain books from trusted sources.
Draw Web UI
Efficiently converts wireframes to Tailwind HTML with code and download link.
Creative Sticker Buddy
Print individual (1) die cut stickers. I create custom stickers and guide you to download them. After downloading them, you can send them to Midwest Label and print out 1-100 individual labels.
Make poke
Make custom Pokémon from camera. Download and battle them verses real ones! (beta)
Calendar event from image
Upload an image of an event poster, download the event as a .ICS file
US Zip Intel
Your go-to source for in-depth US zip code demographics and statistics, with easy-to-download data tables.

FDA Advisor
Approachable expert on FDA medical device regulation. Offering direct download links for related regulation and guidance documents from FDA sites.
Aviation Jobs
I'm a search engine for jobs opportunities in the aerospace industry. DOWNLOAD YOUR CV or ENTER YOUR JOB TITLE / Je suis un moteur de recherche d'offres d'emploi, d'alternance, de stages dans le secteur de l'Aéronautique. TÉLÉCHARGER VOTRE CV ou SAISISSEZ LE TITRE DE VOTRE MÉTIER.
Presentation GPT by SlideSpeak
Create PowerPoint PPTX presentations with ChatGPT. Use prompts to directly create PowerPoint files. Supports any topic. Download as PPTX or PDF. Presentation GPT is the best GPT to create PowerPoint presentations.

PDF/DocX Creator
A GPT that can create PDFs and DocX documents, worksheets, resumes, etc. for you to directly download. See example outputs on https://www.gpt2office.com/
Car Repair Manuals
Access free car repair manuals and auto repair manuals with our AI tool. Ideal for DIY car repair, use online car repair manuals and download car repair manuals. Discover the best car repair manuals for beginners and use car diagnostic tools. Buy car parts online and follow a car maintenance .