Best AI tools for< Document Learning >
20 - AI tool Sites
HeyOctopus
HeyOctopus is a platform designed to help users document their learning experiences and share educational content with others. Users can create and improve learning paths, chat with educational content, and share their knowledge with the community. The platform aims to facilitate faster learning and knowledge sharing by connecting users with relevant resources.
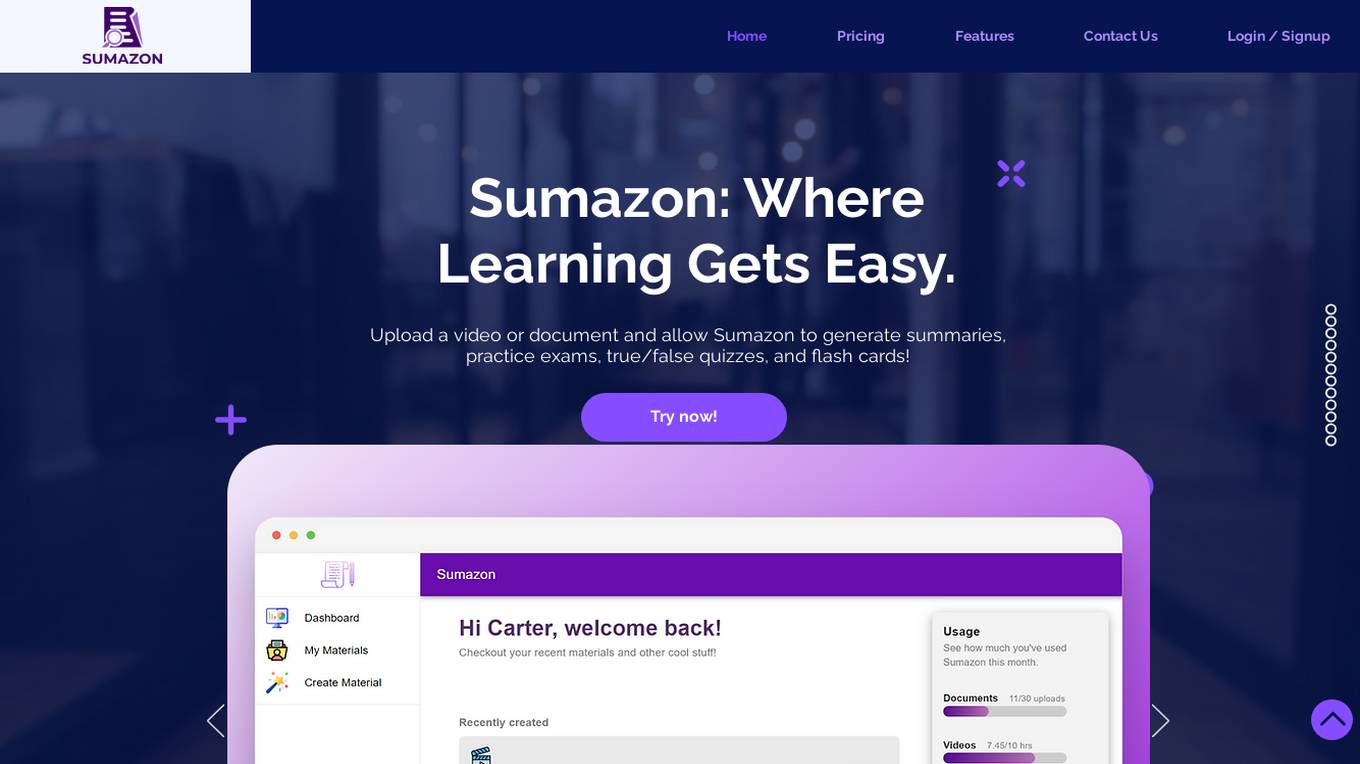
Sumazon
Sumazon is an AI-powered educational platform that simplifies learning through document and video summarization, practice exams, true/false quizzes, and flashcards. It offers powerful features such as summarizing documents and videos, creating study sets, collaborative learning, and multilingual support. With advanced AI capabilities and 24/7 customer support, Sumazon aims to make education more accessible, engaging, and effective for students worldwide.
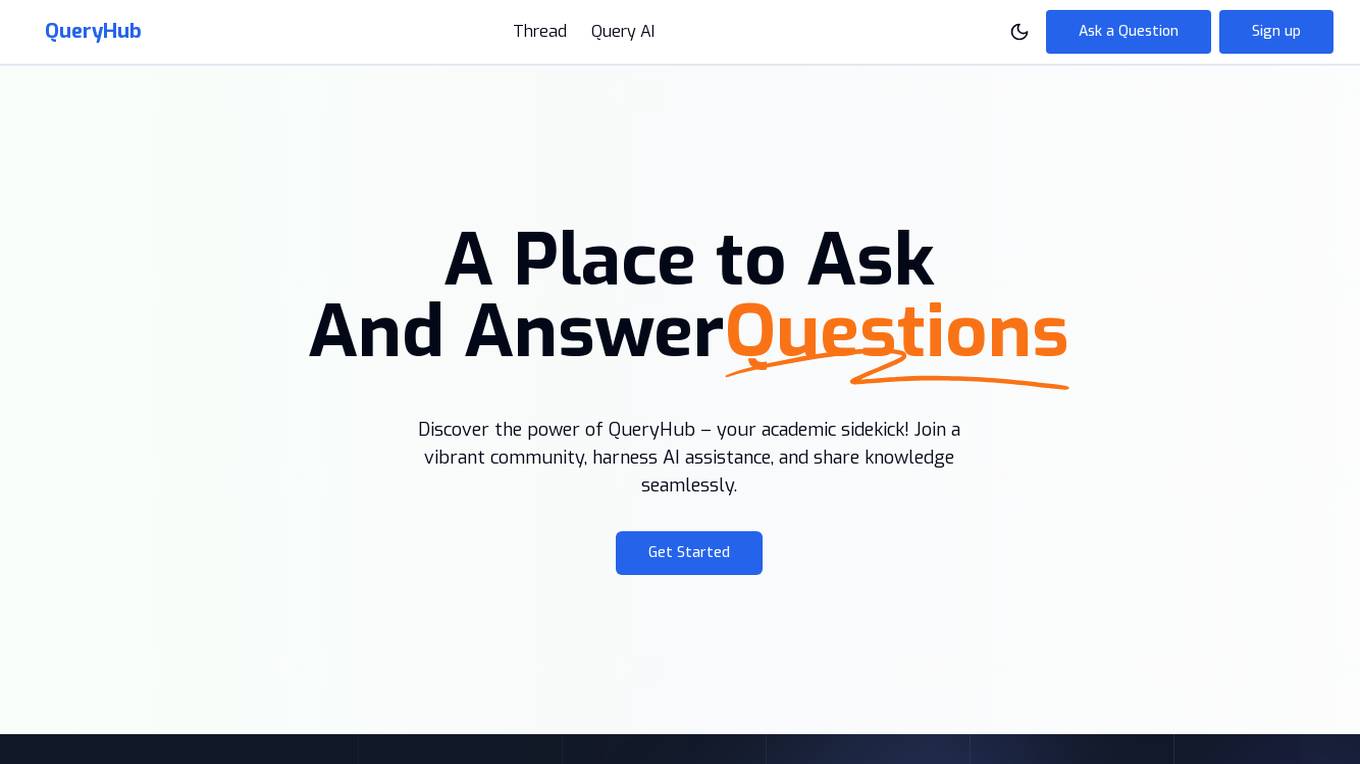
QueryHub
QueryHub is an AI-powered web application designed to assist students in their academic endeavors. It provides a platform for users to ask and answer questions, collaborate with peers, and access instant and accurate information through AI chatbot assistance and smart search capabilities. QueryHub aims to empower students by offering a personalized learning experience, accelerating learning through document collaboration, and fostering community collaboration. With a user-friendly interface and a focus on user-driven innovation, QueryHub is a valuable tool for enhancing academic success.
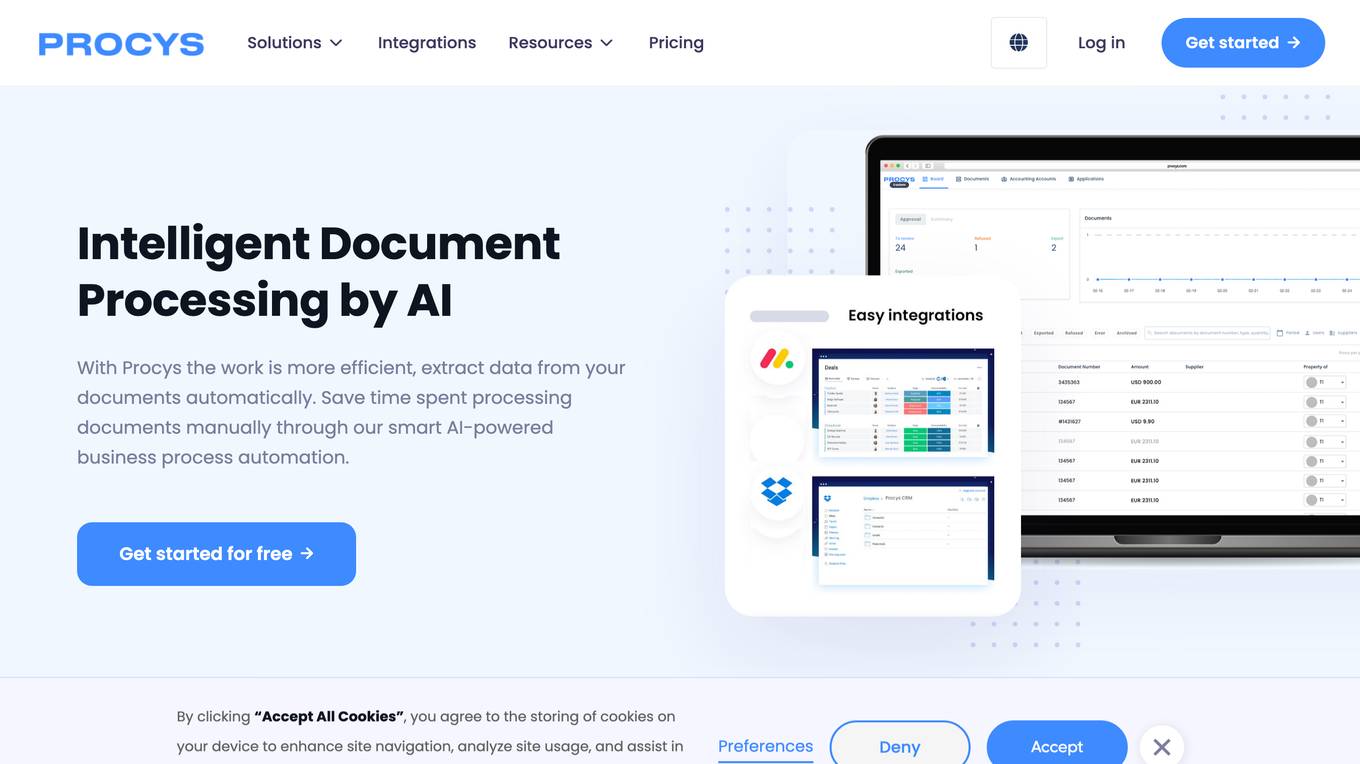
Procys
Procys is a document processing platform powered by AI solutions. It offers a self-learning engine for document processing, seamless integration with over 260 apps, OCR API powered by AI for optical character recognition, customized data extraction capabilities, and AI autosplit feature for automatic document splitting. Procys caters to various industries such as accounting firms, travel & hospitality, and restaurants, providing solutions for invoice OCR, purchase order OCR, ID card OCR, and receipt OCR. The platform aims to automate and streamline document workflows, saving time, reducing errors, and ensuring compliance for businesses.
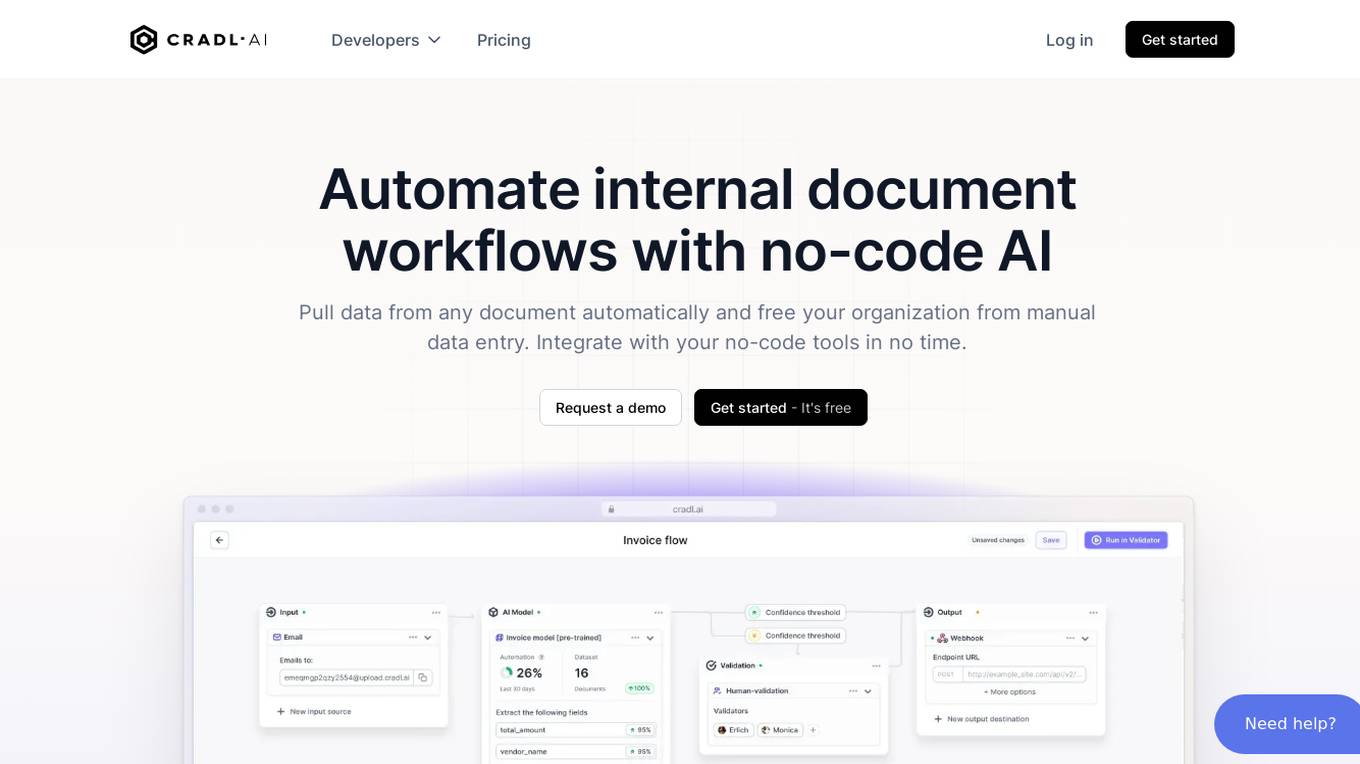
Cradl AI
Cradl AI is an AI-powered tool designed to automate document workflows with no-code AI. It enables users to extract data from any document automatically, integrate with no-code tools, and build custom AI models through an easy-to-use interface. The tool empowers automation teams across industries by extracting data from complex document layouts, regardless of language or structure. Cradl AI offers features such as line item extraction, fine-tuning AI models, human-in-the-loop validation, and seamless integration with automation tools. It is trusted by organizations for business-critical document automation, providing enterprise-level features like encrypted transmission, GDPR compliance, secure data handling, and auto-scaling.
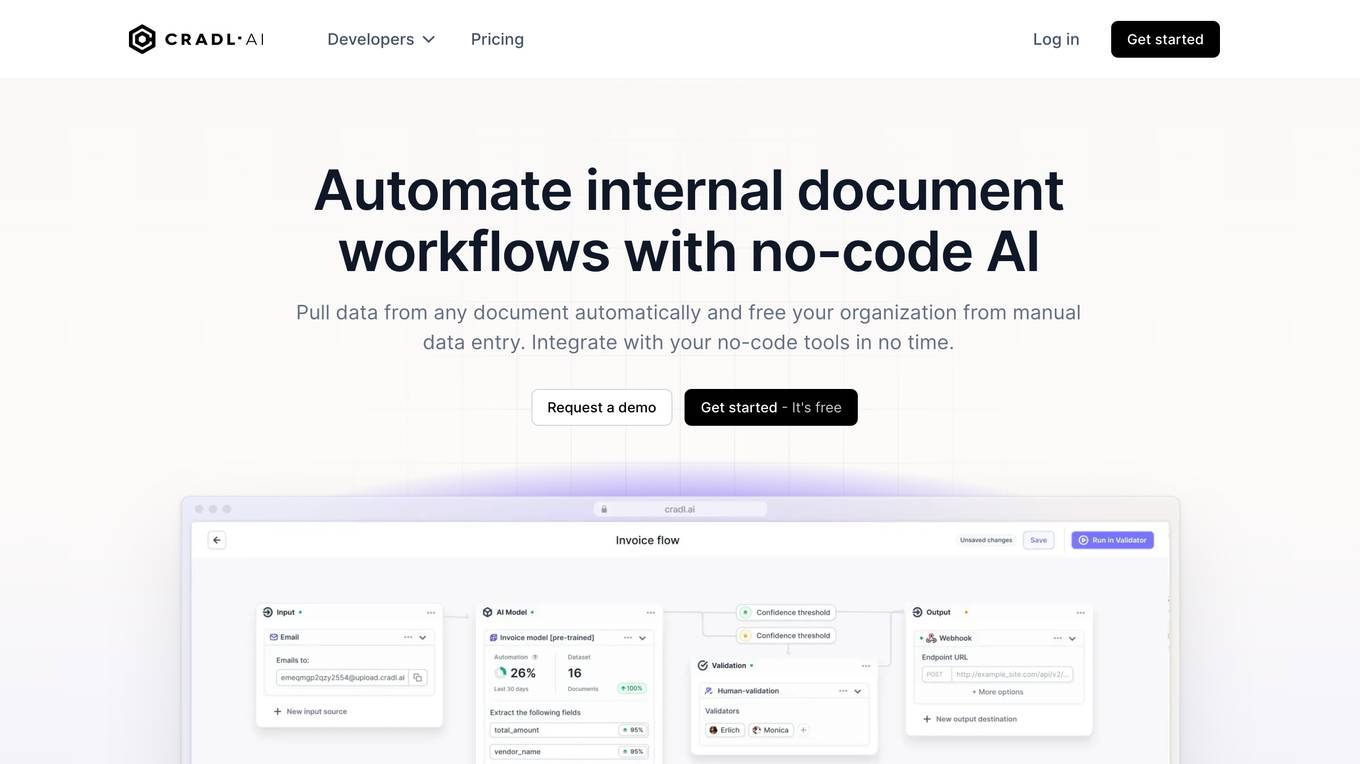
Cradl AI
Cradl AI is a no-code AI-powered document workflow automation tool that helps organizations automate document-related tasks, such as data extraction, processing, and validation. It uses AI to automatically extract data from complex document layouts, regardless of layout or language. Cradl AI also integrates with other no-code tools, making it easy to build and deploy custom AI models.
Onyxium
Onyxium is an AI platform that provides a comprehensive collection of AI tools for various tasks such as image recognition, text analysis, and speech recognition. It offers users the ability to access and utilize the latest AI technologies in one place, empowering them to enhance their projects and workflows with advanced AI capabilities. With a user-friendly interface and affordable pricing plans, Onyxium aims to make AI tools accessible to everyone, from individuals to large-scale businesses.
灵办AI
灵办AI is a free AI assistant for learning and office tasks. It provides users with various AI-powered features to enhance productivity and efficiency in both educational and professional settings. The tool offers a user-friendly interface and supports multiple languages, making it accessible to a diverse user base. With its advanced algorithms, 灵办AI aims to simplify complex tasks and streamline workflows, ultimately saving users time and effort.
Learn Languages AI
Learn Languages AI is a language learning tool that uses artificial intelligence to help users learn new languages. The tool is built on Telegram and allows users to speak, text, and play with an AI teacher. Learn Languages AI is designed to help users reach all of their language learning goals. The tool is free to use and does not require an account.
FunBlocks
FunBlocks is an AI reading and writing assistant application that aims to unleash users' full potential by providing a suite of AI-powered tools for brainstorming, writing, reading, and creating presentations. It offers features such as AI Flow for creativity enhancement, AI Extension for boosting efficiency, and AI Writer and AI Slides for content creation. Users can benefit from personalized AI solutions, seamless collaboration ecosystem, and innovative prompts tailored to their needs. FunBlocks caters to various user roles, including students, content creators, researchers, and professionals, by offering a comprehensive support system for knowledge work.
Affinda
Affinda is a document AI platform that can read, understand, and extract data from any document type. It combines 10+ years of IP in document reconstruction with the latest advancements in computer vision, natural language processing, and deep learning. Affinda's platform can be used to automate a variety of document processing workflows, including invoice processing, receipt processing, credit note processing, purchase order processing, account statement processing, resume parsing, job description parsing, resume redaction, passport processing, birth certificate processing, and driver's license processing. Affinda's platform is used by some of the world's leading organizations, including Google, Microsoft, Amazon, and IBM.

Ai Kit Finder
Ai Kit Finder is a website that provides a directory of AI tools and applications. The website includes a search bar that allows users to search for AI tools by category, feature, or keyword. Ai Kit Finder also provides detailed descriptions of each AI tool, including its features, advantages, and disadvantages. Additionally, the website includes a blog that provides articles on the latest AI trends and developments.

Hyperscience
Hyperscience is a leading enterprise AI platform that provides hyperautomation solutions for businesses. Its platform enables organizations to automate complex business processes with high accuracy and efficiency. Hyperscience offers a range of solutions across various industries and processes, leveraging technologies such as intelligent document processing, machine learning, and natural language processing. The platform is designed to help businesses transform their operations, improve decision-making, and gain a competitive advantage.
Docugami
Docugami is an AI-powered document engineering platform that enables business users to extract, analyze, and automate data from various types of documents. It empowers users with immediate impact without the need for extensive machine learning investments or IT development. Docugami's proprietary Business Document Foundation Model and Generative AI technology transform unstructured text and tables into structured information, allowing users to unlock insights, increase productivity, and ensure compliance.
Golex.AI
Golex.AI is an innovative AI tool designed to streamline document processing and data extraction tasks. It leverages advanced machine learning algorithms to automate the extraction of key information from various types of documents, such as invoices, receipts, and contracts. With its user-friendly interface and powerful OCR technology, Golex.AI simplifies the process of digitizing and organizing documents, saving users valuable time and effort. Whether you are a small business owner, freelancer, or corporate professional, Golex.AI offers a reliable solution for improving efficiency and productivity in document management.
AI Bank Statement Converter
The AI Bank Statement Converter is an industry-leading tool designed for accountants and bookkeepers to extract data from financial documents using artificial intelligence technology. It offers features such as automated data extraction, integration with accounting software, enhanced security, streamlined workflow, and multi-format conversion capabilities. The tool revolutionizes financial document processing by providing high-precision data extraction, tailored for accounting businesses, and ensuring data security through bank-level encryption. It also offers Intelligent Document Processing (IDP) using AI and machine learning techniques to process structured, semi-structured, and unstructured documents.
Text Generator
Text Generator is an AI-powered text generation tool that provides users with accurate, fast, and flexible text generation capabilities. With its advanced large neural networks, Text Generator offers a cost-effective solution for various text-related tasks. The tool's intuitive 'prompt engineering' feature allows users to guide text creation by providing keywords and natural questions, making it adaptable for tasks such as classification and sentiment analysis. Text Generator ensures industry-leading security by never storing personal information on its servers. The tool's continuous training ensures that its AI remains up-to-date with the latest events. Additionally, Text Generator offers a range of features including speech-to-text API, text-to-speech API, and code generation, supporting multiple spoken languages and programming languages. With its one-line migration from OpenAI's text generation hub and a shared embedding for multiple spoken languages, images, and code, Text Generator empowers users with powerful search, fingerprinting, tracking, and classification capabilities.
Oncora Medical
Oncora Medical is a healthcare technology company that provides software and data solutions to oncologists and cancer centers. Their products are designed to improve patient care, reduce clinician burnout, and accelerate clinical discoveries. Oncora's flagship product, Oncora Patient Care, is a modern, intelligent user interface for oncologists that simplifies workflow, reduces documentation burden, and optimizes treatment decision making. Oncora Analytics is an adaptive visual and backend software platform for regulatory-grade real world data analytics. Oncora Registry is a platform to capture and report quality data, treatment data, and outcomes data in the oncology space.
docAnalyzer.ai
docAnalyzer.ai is an intelligent document analysis tool that allows users to have easy and intelligent conversations with their documents. It is powered by cutting-edge AI research and state-of-the-art embeddings, which ensures superior document analysis and dynamic interactions with PDFs. docAnalyzer.ai is easy to use, privacy-conscious, and secure, and it offers a number of features that make it a valuable tool for anyone who works with documents.
AlgoDocs
AlgoDocs is a powerful AI Platform developed based on the latest technologies to streamline your processes and free your team from annoying and error-prone manual data entry by offering fast, secure, and accurate document data extraction.
0 - Open Source AI Tools
20 - OpenAI Gpts
Automated Knowledge Distillation
For strategic knowledge distillation, upload the document you need to analyze and use !start. ENSURE the uploaded file shows DOCUMENT and NOT PDF. This workflow requires leveraging RAG to operate. Only a small amount of PDFs are supported, convert to txt or doc. For timeout, refresh & !continue


PlanGPT
Formal, professional urban planning expert, skilled in document analysis and feedback interpretation.


Maze Bright A.I. Concierge
Grow your knowledge of A.I. so you can feel confident and efficient in your daily tasks and business decisions. Type "Weekly Briefing" or "Daily Briefing" for the latest news.

AI Outsmarts Humanity
It outsmarts. Concise, razor-sharp, challenging your every claim. Can you prove it wrong?

GrokVersion
Most powerful model. Stronger than ChatGPT4, 5, even 6, this version is boosted on steroids, GPT-Grok version with 32K context, more powerful than Elon Musk's AI