Best AI tools for< Document Database >
20 - AI tool Sites
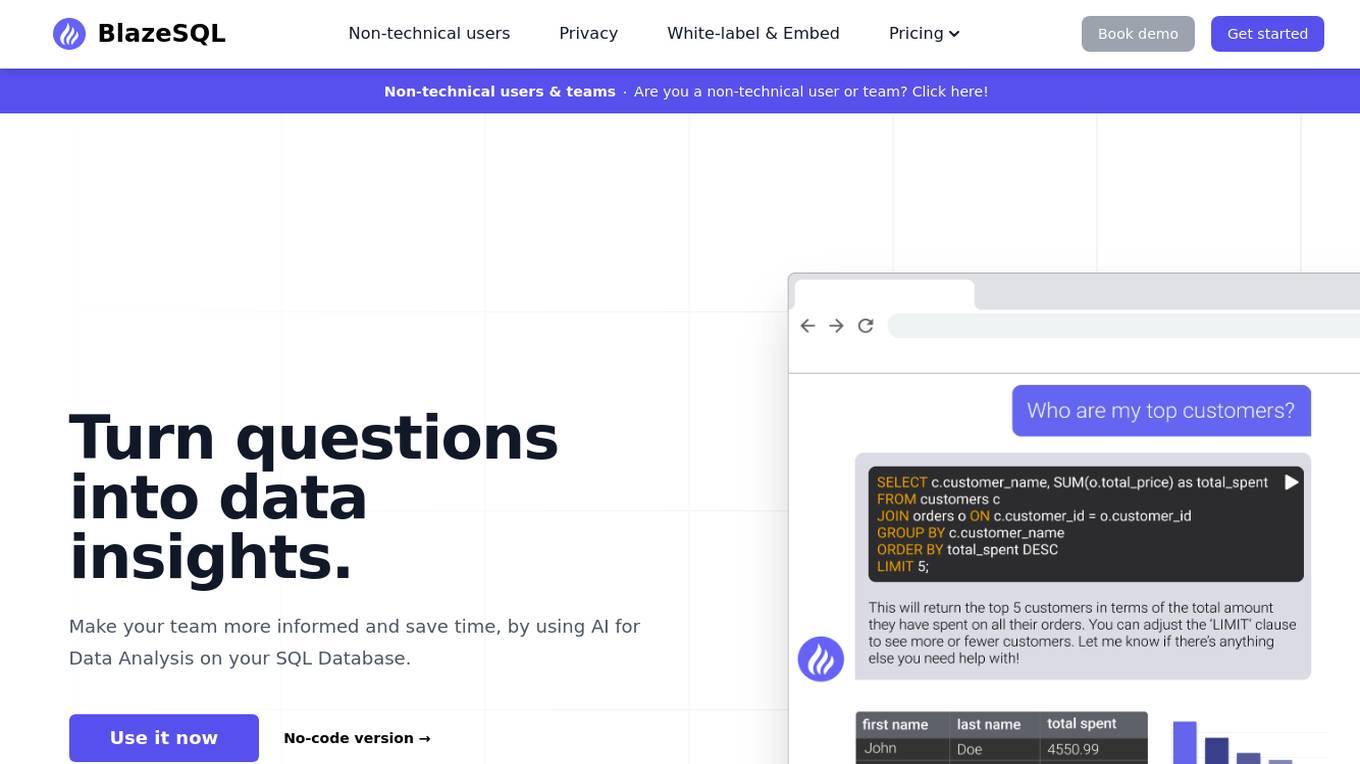
Blaze SQL AI
Blaze SQL AI is an AI Data Analytics chatbot and SQL generator that helps non-technical users and teams turn questions into data insights. It allows users to make their teams more informed and save time by using AI for Data Analysis on their SQL Database. Blaze SQL AI can write SQL code, run queries, visualize data, and provide database documentation. It is trusted by innovative teams and offers a private desktop version for secure data connections. The tool is designed to help users easily interact with their databases using natural language and generate complex SQL queries with the help of AI technology.
TextMine
TextMine is an AI-powered knowledge base that helps businesses analyze, manage, and search thousands of documents. It uses AI to analyze unstructured textual data and document databases, automatically retrieving key terms to help users make informed decisions. TextMine's features include a document vault for storing and managing documents, a categorization system for organizing documents, and a data extraction tool for extracting insights from documents. TextMine can help businesses save time, money, and improve efficiency by automating manual data entry and information retrieval tasks.

ClearAI
ClearAI is an AI-powered platform that offers instant extraction of insights, effortless document navigation, and natural language interaction. It enables users to upload PDFs securely, ask questions, and receive accurate responses in seconds. With features like structured results, intelligent search, and lifetime access offers, ClearAI simplifies tasks such as analyzing company reports, risk assessment, audit support, contract review, legal research, and due diligence. The platform is designed to streamline document analysis and provide relevant data efficiently.
Softbuilder
Softbuilder is a software development company that focuses on creating innovative database tools. Their products include ERBuilder Data Modeler, a database modeling software for high-quality data models, and AbstraLinx, a powerful metadata discovery tool for Salesforce. Softbuilder aims to provide straightforward tools that utilize the latest technology to help users be more productive and focus on delivering solutions rather than learning complicated tools.
SvectorDB
SvectorDB is a vector database built from the ground up for serverless applications. It is designed to be highly scalable, performant, and easy to use. SvectorDB can be used for a variety of applications, including recommendation engines, document search, and image search.
Parsio
Parsio is an AI-powered document parser that can extract structured data from PDFs, emails, and other documents. It uses natural language processing to understand the context of the document and identify the relevant data points. Parsio can be used to automate a variety of tasks, such as extracting data from invoices, receipts, and emails.

Talking Tree
Talking Tree is an AI-powered document management tool designed for legal professionals to digitize and manage legal documents efficiently. It offers advanced OCR technology and a custom RAG architecture to convert printed and handwritten text into searchable structured data. The platform enables users to find information, draft agreements, and analyze legacy documents with unprecedented speed and accuracy. Talking Tree provides a secure and user-friendly interface with multilingual support, making it a valuable resource for legal research and document management.
Wordscope
Wordscope is an all-in-one solution for professional translators that provides a variety of tools to ensure quality translations, including private translation memories, neural machine translation, terminology databases, public translation memories, a comparative revision tool, quality control tools, synonym lists, and various sharing options.
vLex
vLex is a legal AI platform that offers live case law, statutes, regulations, and legal analytics. It provides advanced engineering to deliver precise answers with transparent citations across 50 states and 17 countries. The platform includes Vincent AI, which offers over 20 AI workflows to summarize facts, contracts, build timelines, and compare jurisdictions. vLex is designed for global firms and Fortune 500 counsel, combining the largest legal database with expert legal editors tracking judicial treatment and citations.
Law.co
Law.co is an advanced AI platform designed specifically for lawyers and law firms to streamline legal operations and enhance efficiency. The platform offers a semantic database search with access to over 1 million historical legal cases and 40,000 legal contracts, enabling users to perform detailed legal research, contract drafting, document review, and more. Law.co leverages custom-trained artificial intelligence and semantic search tools to deliver measurable results, revolutionizing legal research and document preparation processes for legal professionals.
Koncile
Koncile is an AI-powered OCR solution that automates data extraction from various documents. It combines advanced OCR technology with large language models to transform unstructured data into structured information. Koncile can extract data from invoices, accounting documents, identity documents, and more, offering features like categorization, enrichment, and database integration. The tool is designed to streamline document management processes and accelerate data processing. Koncile is suitable for businesses of all sizes, providing flexible subscription plans and enterprise solutions tailored to specific needs.

Eskwai
Eskwai is an AI-powered legal research tool that revolutionizes legal research by providing instant, trustworthy answers and insights from a comprehensive database of case laws and legislation. It features Smart Citator, a pioneering AI-powered citation index for African case laws, along with advanced features like document downloads, legislation amendment tracking, and enhanced Ask Kwame with a higher intelligence mode. Eskwai is trusted by over 2,000 law students and legal professionals across 120+ law firms and legal departments.
Coda
Coda is an all-in-one collaborative workspace that brings teams and tools together for a more organized work day. It is a cloud-based platform that allows users to create and share documents, spreadsheets, databases, and other types of content. Coda also includes a number of built-in features such as chat, video conferencing, and task management. Coda is designed to be easy to use and accessible to users of all skill levels.

JENOVA
JENOVA is an AI tool that provides users with access to the best intelligence and expertise by synthesizing advanced AI models and tools into one unified AI experience. It ensures users always get the best answers by routing queries to the most optimal model for their needs. JENOVA offers an expanding suite of useful tools and capabilities, including document reading for various formats, image comprehension powered by multi-modal AI models, and web search for up-to-date information. Privacy is a priority, as conversations and data are never used for training and are securely stored in a protected database.
DISCO
DISCO is a leading provider of ediscovery and legal technology solutions. The company's cloud-based platform helps law firms and corporate legal teams streamline the discovery process, reduce costs, and improve outcomes. DISCO's AI-powered features include Cecilia, an AI fact expert that can answer questions about cases based on evidence in a database; AI timeline creation, which can automatically generate timelines summarizing key facts in minutes; AI large-scale document review, which can automate document review using generative AI; and AI witness digests, which can summarize depositions with citations, topics, and dates. DISCO's platform is easy to use and provides a defensible audit trail. The company also offers a range of professional services, including managed review, deposition review, and expert consulting.
AFFiNE
AFFiNE is an all-in-one KnowledgeOS platform that integrates documents, whiteboards, and databases with AI capabilities. It offers a workspace for writing, drawing, and planning, allowing users to enhance creativity and productivity. The platform is privacy-focused, user-centric, and open-source, catering to individuals, startups, and established organizations. AFFiNE aims to streamline workflows, foster collaboration, and provide a vibrant community space for users to connect and inspire each other.
RquestR
RquestR is an AI-powered knowledge management platform designed specifically for procurement professionals. It streamlines projects, enables instant answers retrieval, and facilitates informed decision-making. The platform offers features such as intelligent document querying, automated Q&A generation, and knowledge base building. RquestR helps in reducing response time by up to 40% and enhancing decision-making accuracy by 30%. It provides a centralized knowledge hub for managing RFPs, security questionnaires, and Q&As, all while ensuring enterprise-grade security. The platform revolutionizes the procurement process by leveraging advanced AI for lightning-fast information retrieval, accurate responses, and adaptive learning.

Sheety
Sheety is a spreadsheet-like database that lets you build powerful apps without writing any code. It's perfect for teams who need to track data, manage projects, and collaborate on documents.
LangSearch
LangSearch is an AI tool that offers a free Web Search API and Rerank API, serving as the World Engine for AGI. It allows users to connect their LLM applications to access clean, accurate, high-quality context from billions of web documents, including news, images, videos, and more. The tool supports natural language search and provides enhanced search details for various content types.
Heyday
Heyday is an AI-powered personal assistant that helps users manage and organize their information, including documents, notes, conversations, and articles. It uses natural language processing and machine learning to extract key insights, generate summaries, and create shareable content. Heyday also integrates with popular tools like Zoom and Google Calendar to provide context and automate tasks.
0 - Open Source AI Tools
20 - OpenAI Gpts
Database Schema Generator
Takes in a Project Design Document and generates a database schema diagram for the project.

Mongoose Docs Helper
Casual, technical helper for Mongoose docs, includes documentation links.

Law Document
Convert simple documents and notes into supported legal terminology. Copyright (C) 2024, Sourceduty - All Rights Reserved.


Refine Product Management Enhancement Document
I help refine product enhancements. Logic - Essential Details - Business Value
Property Manager Document Assistant
Provides analysis and data extraction of Property Management documents and contracts for managers
LaTeX Picture & Document Transcriber
Convert into usable LaTeX code any pictures of your handwritten notes, documents in any format. Start by uploading what you need to convert.

DocuScan and Scribe
Scans and transcribes images into documents, offers downloadable copies in a document and offers to translate into different languages
Florida Entrepreneur Startup Documents Package
Startup document generator for Florida entrepreneurs.