Best AI tools for< Dispatch Emergency Services >
7 - AI tool Sites
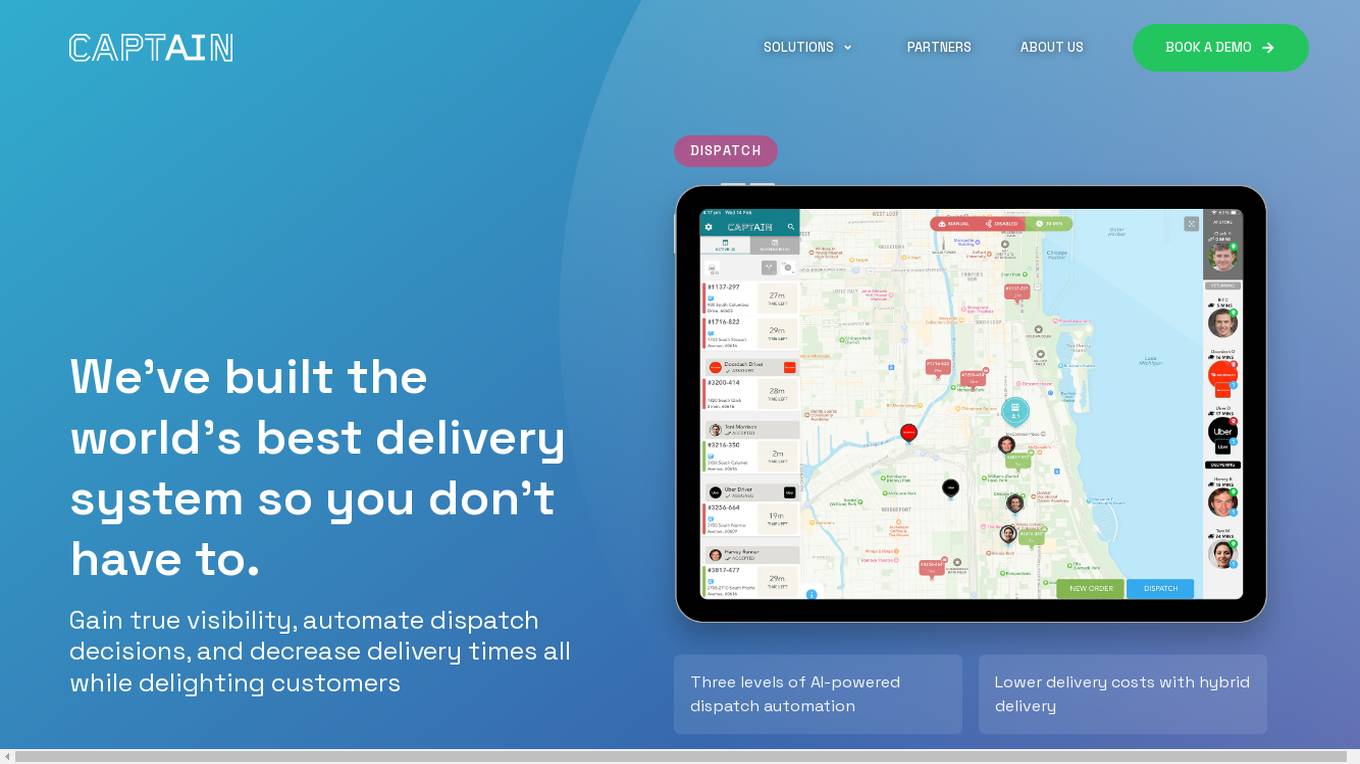
Captain
Captain is a leading delivery management software designed to streamline and optimize food delivery operations for restaurant chains. It offers a comprehensive solution that includes automated dispatching, driver tracking, kitchen management, and performance analytics. With features like AI-powered dispatch automation, branded tracking experiences, and data-driven insights, Captain helps businesses improve efficiency, reduce delivery times, and enhance customer satisfaction. Trusted by nation-wide pizza chains and market-leading POS systems, Captain is known for its intuitive interface, flexibility in delivery options, and ability to cater to businesses of all scales.
Workiz
Workiz is a comprehensive Field Service Management (FSM) Software designed to streamline and optimize field service operations for various industries. It offers essential features such as client CRM, scheduling, dispatching, invoicing, estimates & proposals, inventory management, online booking, mobile app, advanced reporting, automations, lead source integrations, service plans, equipment tracking, price book, payment processing, expense management, consumer financing, built-in phone & messages, AI answering, AI leads capture, AI call insights, call recordings & tags, and more. Workiz caters to multiple industries and growing field service businesses, providing a one-stop solution to manage daily tasks, automate workflows, win more jobs, and increase revenue.

Wattle
Wattle is a modern business platform designed for home service professionals. It offers software that simplifies and intelligently automates operations, allowing professionals to focus more on customer interactions. With features like AI-powered booking and dispatching, online bookings, intelligent automation engine, and seamless integration with existing software, Wattle streamlines job lifecycle management for industries like HVAC, plumbing, lawn care, electrical, and pest control. The platform aims to boost productivity, simplify operations, and enhance customer engagement through efficient scheduling, quoting, payment collection, and contractor management.
Kolank AI
Kolank AI is a freight broker automation software powered by AI that handles carrier communication, load tracking, and dispatch management. It automates routine tasks like check calls, status updates, and document processing, allowing your team to focus on booking more loads and building relationships. The platform offers multi-channel communication, 24/7 coverage, and seamless integration with existing TMS systems. Designed for brokerages of all sizes, Kolank AI aims to amplify your operations by providing intelligent automation and support for critical decision-making.
Brightpick
Brightpick is an AI-powered order fulfillment solution that revolutionizes warehouse operations by enabling fully automated order picking, consolidation, and dispatch. The Brightpick Autopicker, equipped with AI robots, streamlines the fulfillment process by efficiently picking a wide range of products, from groceries to pharmaceuticals, with precision and speed. Trusted by industry leaders, Brightpick helps businesses cut costs, increase efficiency, and enhance customer service in industries such as Ecommerce, 3PL, E-Grocery, and Medical. With its innovative technology and award-winning solutions, Brightpick is reshaping the future of order fulfillment.

Samsara
Samsara is a leading provider of Connected Operations™ technology that connects people, systems, and data to give businesses visibility into every area of their operations. Samsara's platform includes a suite of products that help businesses improve safety, efficiency, and sustainability. Samsara's AI-powered video safety solutions provide real-time visibility into fleet operations, helping businesses to prevent accidents and protect their workforce. Samsara's fleet management solutions provide performance insights, asset protection, and live tracking for improved fleet productivity. Samsara's apps and workflows solutions provide customized driver experiences, real-time dispatch data, and streamlined ELD compliance. Samsara's site visibility solutions provide remote visibility, proactive alerting, and on-the-go access to data from remote sites.

Hey Bubba!
Hey Bubba! is an AI voice dispatcher application designed to help truck drivers find, negotiate, and book loads efficiently using voice commands and AI technology. The app operates 24x7, allowing drivers to focus on the road while Bubba works to secure high-paying loads. With features like AI dispatch, best load recommendations, auto-pilot voice technology, and hassle-free load booking, Hey Bubba! aims to streamline the freight booking process for owner-operators and small fleets.
0 - Open Source AI Tools
3 - OpenAI Gpts

Emergency Dispatcher Simulation
Simulation of a virtual emergency dispatcher for training purposes

Artful Dispatch: custom postcards shipped globally
Create one-of-a-kind postcards with ChatGPT and DALL·E 3. Our assistant creates the perfect message and graphics for a unique way to stay connected. For just $3.49, get your postcard printed and shipped anywhere in the world. Our AI canvas makes every dispatch uniquely yours!