Best AI tools for< Deploy Serverless Service >
20 - AI tool Sites
Cloudflare
Cloudflare is a platform that provides various services to help individuals and organizations improve their online presence and security. It offers solutions such as content delivery network (CDN), DDoS protection, domain registration, and serverless computing. Cloudflare aims to make the internet faster, more secure, and more reliable for users worldwide.

Amazon Bedrock
Amazon Bedrock is a cloud-based platform that enables developers to build, deploy, and manage serverless applications. It provides a fully managed environment that takes care of the infrastructure and operations, so developers can focus on writing code. Bedrock also offers a variety of tools and services to help developers build and deploy their applications, including a code editor, a debugger, and a deployment pipeline.
Novita AI
Novita AI is an AI cloud platform that offers Model APIs, Serverless, and GPU Instance solutions integrated into one cost-effective platform. It provides tools for building AI products, scaling with serverless architecture, and deploying with GPU instances. Novita AI caters to startups and businesses looking to leverage AI technologies without the need for extensive machine learning expertise. The platform also offers a Startup Program, 24/7 service support, and has received positive feedback for its reasonable pricing and stable API services.
Novita AI
Novita AI is an AI cloud platform offering Model APIs, Serverless, and GPU Instance services in a cost-effective and integrated manner to accelerate AI businesses. It provides optimized models for high-quality dialogue use cases, full spectrum AI APIs for image, video, audio, and LLM applications, serverless auto-scaling based on demand, and customizable GPU solutions for complex AI tasks. The platform also includes a Startup Program, 24/7 service support, and has received positive feedback for its reasonable pricing and stable services.
Nscale
Nscale is a full-stack, scalable, and sustainable AI cloud platform that offers a wide range of AI services and solutions. It provides services for developing, training, tuning, and deploying AI models using on-demand services. Nscale also offers serverless inference API endpoints, fine-tuning capabilities, private cloud solutions, and various GPU clusters engineered for AI. The platform aims to simplify the journey from AI model development to production, offering a marketplace for AI/ML tools and resources. Nscale's infrastructure includes data centers powered by renewable energy, high-performance GPU nodes, and optimized networking and storage solutions.

BackX
BackX is an AI development platform that empowers developers to quickly ship backends across various use cases, environments, and scales. It offers unparalleled accuracy, flexibility, and efficiency by overcoming the limitations of traditional AI-assisted programming. With features like one-click production-grade code, context-aware consistent code output, versioned artifacts, instant deploy, and a suite of AI-powered dev tools, BackX revolutionizes the backend development process. Developers can effortlessly design and manage databases, generate CRUD operations, implement complex business logic, and deploy serverless applications with ease. The platform aims to streamline development processes, increase cost-effectiveness, and provide more accurate outputs than traditional methods.

Mystic.ai
Mystic.ai is an AI tool designed to deploy and scale Machine Learning models with ease. It offers a fully managed Kubernetes platform that runs in your own cloud, allowing users to deploy ML models in their own Azure/AWS/GCP account or in a shared GPU cluster. Mystic.ai provides cost optimizations, fast inference, simpler developer experience, and performance optimizations to ensure high-performance AI model serving. With features like pay-as-you-go API, cloud integration with AWS/Azure/GCP, and a beautiful dashboard, Mystic.ai simplifies the deployment and management of ML models for data scientists and AI engineers.
Azure Static Web Apps
Azure Static Web Apps is a platform provided by Microsoft Azure for building and deploying modern web applications. It allows developers to easily host static web content and serverless APIs with seamless integration to popular frameworks like React, Angular, and Vue. With Azure Static Web Apps, developers can quickly set up continuous integration and deployment workflows, enabling them to focus on building great user experiences without worrying about infrastructure management.
Empower
Empower is a serverless fine-tuned LLM hosting platform that offers a developer platform for fine-tuned LLMs. It provides prebuilt task-specific base models with GPT4 level response quality, enabling users to save up to 80% on LLM bills with just 5 lines of code change. Empower allows users to own their models, offers cost-effective serving with no compromise on performance, and charges on a per-token basis. The platform is designed to be user-friendly, efficient, and cost-effective for deploying and serving fine-tuned LLMs.
Modal
Modal is a high-performance cloud platform designed for developers, AI data, and ML teams. It offers a serverless environment for running generative AI models, large-scale batch jobs, job queues, and more. With Modal, users can bring their own code and leverage the platform's optimized container file system for fast cold boots and seamless autoscaling. The platform is engineered for large-scale workloads, allowing users to scale to hundreds of GPUs, pay only for what they use, and deploy functions to the cloud in seconds without the need for YAML or Dockerfiles. Modal also provides features for job scheduling, web endpoints, observability, and security compliance.

Cerebium
Cerebium is a serverless AI infrastructure platform that allows teams to build, test, and deploy AI applications quickly and efficiently. With a focus on speed, performance, and cost optimization, Cerebium offers a range of features and tools to simplify the development and deployment of AI projects. The platform ensures high reliability, security, and compliance while providing real-time logging, cost tracking, and observability tools. Cerebium also offers GPU variety and effortless autoscaling to meet the diverse needs of developers and businesses.

Fleak AI Workflows
Fleak AI Workflows is a low-code serverless API Builder designed for data teams to effortlessly integrate, consolidate, and scale their data workflows. It simplifies the process of creating, connecting, and deploying workflows in minutes, offering intuitive tools to handle data transformations and integrate AI models seamlessly. Fleak enables users to publish, manage, and monitor APIs effortlessly, without the need for infrastructure requirements. It supports various data types like JSON, SQL, CSV, and Plain Text, and allows integration with large language models, databases, and modern storage technologies.
Anyscale
Anyscale is a company that provides a scalable compute platform for AI and Python applications. Their platform includes a serverless API for serving and fine-tuning open LLMs, a private cloud solution for data privacy and governance, and an open source framework for training, batch, and real-time workloads. Anyscale's platform is used by companies such as OpenAI, Uber, and Spotify to power their AI workloads.
Seldon
Seldon is an MLOps platform that helps enterprises deploy, monitor, and manage machine learning models at scale. It provides a range of features to help organizations accelerate model deployment, optimize infrastructure resource allocation, and manage models and risk. Seldon is trusted by the world's leading MLOps teams and has been used to install and manage over 10 million ML models. With Seldon, organizations can reduce deployment time from months to minutes, increase efficiency, and reduce infrastructure and cloud costs.

PoplarML
PoplarML is a platform that enables the deployment of production-ready, scalable ML systems with minimal engineering effort. It offers one-click deploys, real-time inference, and framework agnostic support. With PoplarML, users can seamlessly deploy ML models using a CLI tool to a fleet of GPUs and invoke their models through a REST API endpoint. The platform supports Tensorflow, Pytorch, and JAX models.

ClawOneClick
ClawOneClick is an AI tool that allows users to deploy their own AI assistant in seconds without the need for technical setup. It offers a one-click deployment of an always-on AI chatbot powered by the latest AI models. Users can choose from various AI models and messaging channels to customize their AI assistant. ClawOneClick handles all the cloud infrastructure provisioning and management, ensuring secure connections and end-to-end encryption. The tool is designed to adapt to various tasks and can assist with email summarization, quick replies, translation, proofreading, customer queries, report condensation, meeting reminders, voice memo transcription, deadline tracking, schedule organization, meeting action item capture, time zone coordination, task automation, expense logging, priority planning, content generation, idea brainstorming, fast topic research, book and article summarization, concept learning, creative suggestions, code explanation, document analysis, professional document drafting, project goal definition, team updates preparation, data trend interpretation, job posting writing, product and price comparison, meal plan suggestion, and more.
Vercel
Vercel is an AI-powered cloud platform that enables developers to build, deploy, and scale web applications quickly and securely. It offers a range of developer tools and cloud infrastructure to optimize performance and enhance user experience. Vercel's AI capabilities include AI Cloud, AI SDK, AI Gateway, and Sandbox AI workflows, providing seamless integration of AI models into web applications.
TurboClaw
TurboClaw is an AI-powered platform that allows users to deploy their own 24/7 OpenClaw instance in under a minute, eliminating technical hassles. Users can choose from different AI models and messaging channels, and the platform handles server management, Docker setup, SSL configuration, and OpenClaw deployment. With TurboClaw, users can quickly set up AI bots for various tasks such as drafting replies, translating messages, organizing inboxes, managing subscriptions, finding best prices online, generating content ideas, setting goals, and more.
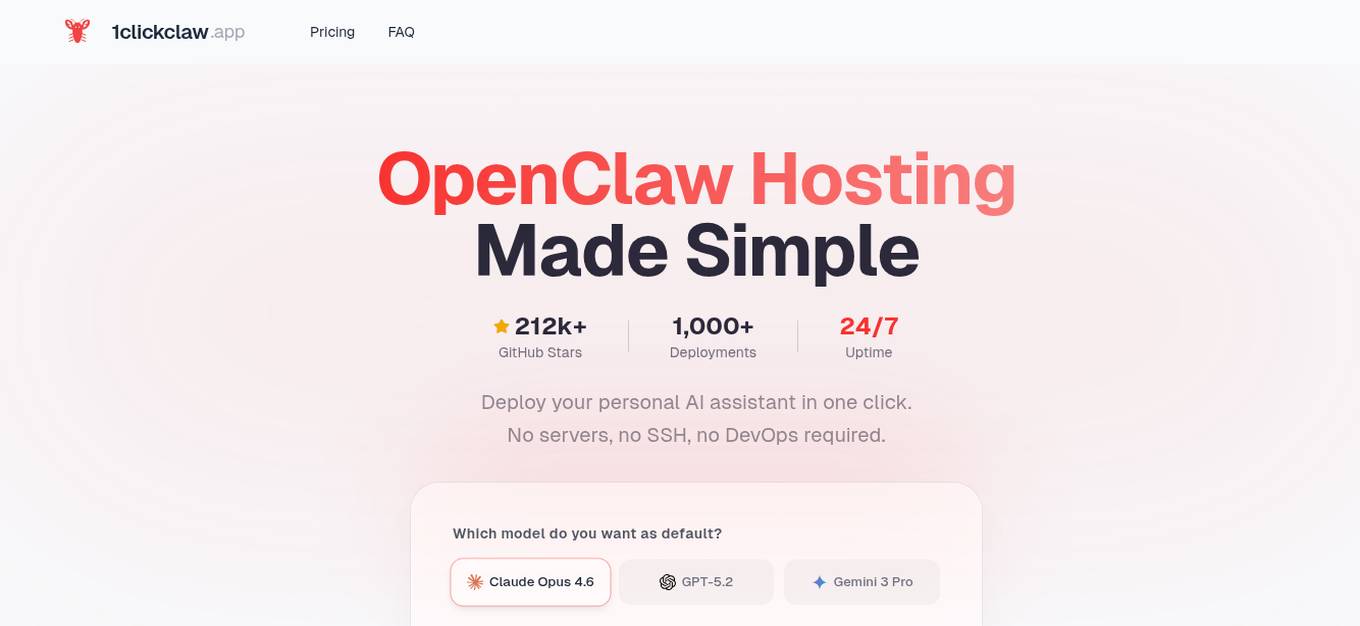
1ClickClaw
1ClickClaw is an AI tool that simplifies the process of deploying personal AI assistants by offering one-click deployment without the need for servers, SSH, or DevOps expertise. Users can choose from multiple AI models, connect their preferred messaging channels, and deploy their AI assistant in under a minute on a dedicated cloud server. The application streamlines the traditional time-consuming setup process, making AI deployment accessible to users without technical knowledge.
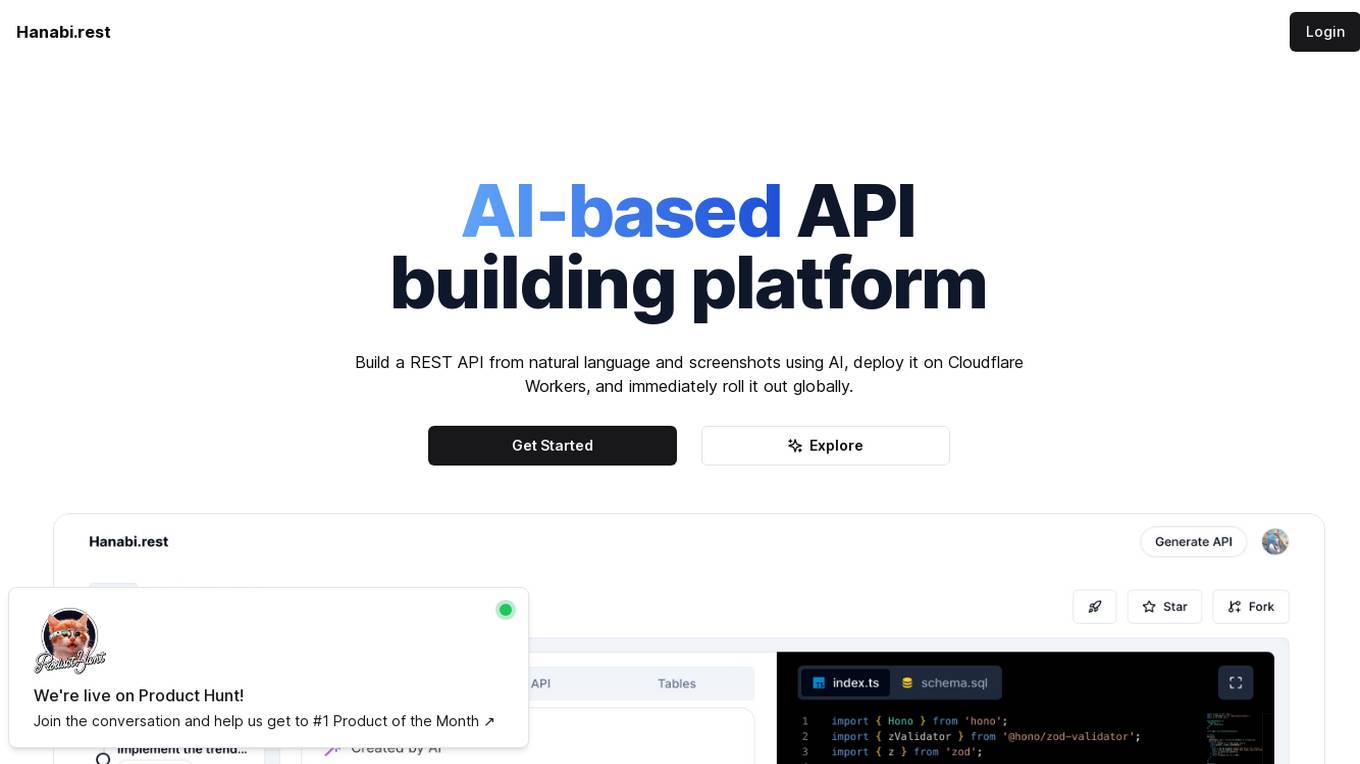
Hanabi.rest
Hanabi.rest is an AI-based API building platform that allows users to create REST APIs from natural language and screenshots using AI technology. Users can deploy the APIs on Cloudflare Workers and roll them out globally. The platform offers a live editor for testing database access and API endpoints, generates code compatible with various runtimes, and provides features like sharing APIs via URL, npm package integration, and CLI dump functionality. Hanabi.rest simplifies API design and deployment by leveraging natural language processing, image recognition, and v0.dev components.
1 - Open Source AI Tools
memfree
MemFree is an open-source hybrid AI search engine that allows users to simultaneously search their personal knowledge base (bookmarks, notes, documents, etc.) and the Internet. It features a self-hosted super fast serverless vector database, local embedding and rerank service, one-click Chrome bookmarks index, and full code open source. Users can contribute by opening issues for bugs or making pull requests for new features or improvements.
20 - OpenAI Gpts

Frontend Developer
AI front-end developer expert in coding React, Nextjs, Vue, Svelte, Typescript, Gatsby, Angular, HTML, CSS, JavaScript & advanced in Flexbox, Tailwind & Material Design. Mentors in coding & debugging for junior, intermediate & senior front-end developers alike. Let’s code, build & deploy a SaaS app.




Azure Arc Expert
Azure Arc expert providing guidance on architecture, deployment, and management.


Instructor GCP ML
Formador para la certificación de ML Engineer en GCP, con respuestas y explicaciones detalladas.

Docker and Docker Swarm Assistant
Expert in Docker and Docker Swarm solutions and troubleshooting.



Cloudwise Consultant
Expert in cloud-native solutions, provides tailored tech advice and cost estimates.