Best AI tools for< Deploy Models Seamlessly >
20 - AI tool Sites
FuriosaAI
FuriosaAI is an AI application that offers Hardware RNGD for LLM and Multimodality, as well as WARBOY for Computer Vision. It provides a comprehensive developer experience through the Furiosa SDK, Model Zoo, and Dev Support. The application focuses on efficient AI inference, high-performance LLM and multimodal deployment capabilities, and sustainable mass adoption of AI. FuriosaAI features the Tensor Contraction Processor architecture, software for streamlined LLM deployment, and a robust ecosystem support. It aims to deliver powerful and efficient deep learning acceleration while ensuring future-proof programmability and efficiency.

SuperAnnotate
SuperAnnotate is an AI data platform that simplifies and accelerates model-building by unifying the AI pipeline. It enables users to create, curate, and evaluate datasets efficiently, leading to the development of better models faster. The platform offers features like connecting any data source, building customizable UIs, creating high-quality datasets, evaluating models, and deploying models seamlessly. SuperAnnotate ensures global security and privacy measures for data protection.

PoplarML
PoplarML is a platform that enables the deployment of production-ready, scalable ML systems with minimal engineering effort. It offers one-click deploys, real-time inference, and framework agnostic support. With PoplarML, users can seamlessly deploy ML models using a CLI tool to a fleet of GPUs and invoke their models through a REST API endpoint. The platform supports Tensorflow, Pytorch, and JAX models.

Fleak AI Workflows
Fleak AI Workflows is a low-code serverless API Builder designed for data teams to effortlessly integrate, consolidate, and scale their data workflows. It simplifies the process of creating, connecting, and deploying workflows in minutes, offering intuitive tools to handle data transformations and integrate AI models seamlessly. Fleak enables users to publish, manage, and monitor APIs effortlessly, without the need for infrastructure requirements. It supports various data types like JSON, SQL, CSV, and Plain Text, and allows integration with large language models, databases, and modern storage technologies.
HostAI
HostAI is a platform that allows users to host their artificial intelligence models and applications with ease. It provides a user-friendly interface for managing and deploying AI projects, eliminating the need for complex server setups. With HostAI, users can seamlessly run their AI algorithms and applications in a secure and efficient environment. The platform supports various AI frameworks and libraries, making it versatile for different AI projects. HostAI simplifies the process of AI deployment, enabling users to focus on developing and improving their AI models.
Apache MXNet
Apache MXNet is a flexible and efficient deep learning library designed for research, prototyping, and production. It features a hybrid front-end that seamlessly transitions between imperative and symbolic modes, enabling both flexibility and speed. MXNet also supports distributed training and performance optimization through Parameter Server and Horovod. With bindings for multiple languages, including Python, Scala, Julia, Clojure, Java, C++, R, and Perl, MXNet offers wide accessibility. Additionally, it boasts a thriving ecosystem of tools and libraries that extend its capabilities in computer vision, NLP, time series, and more.
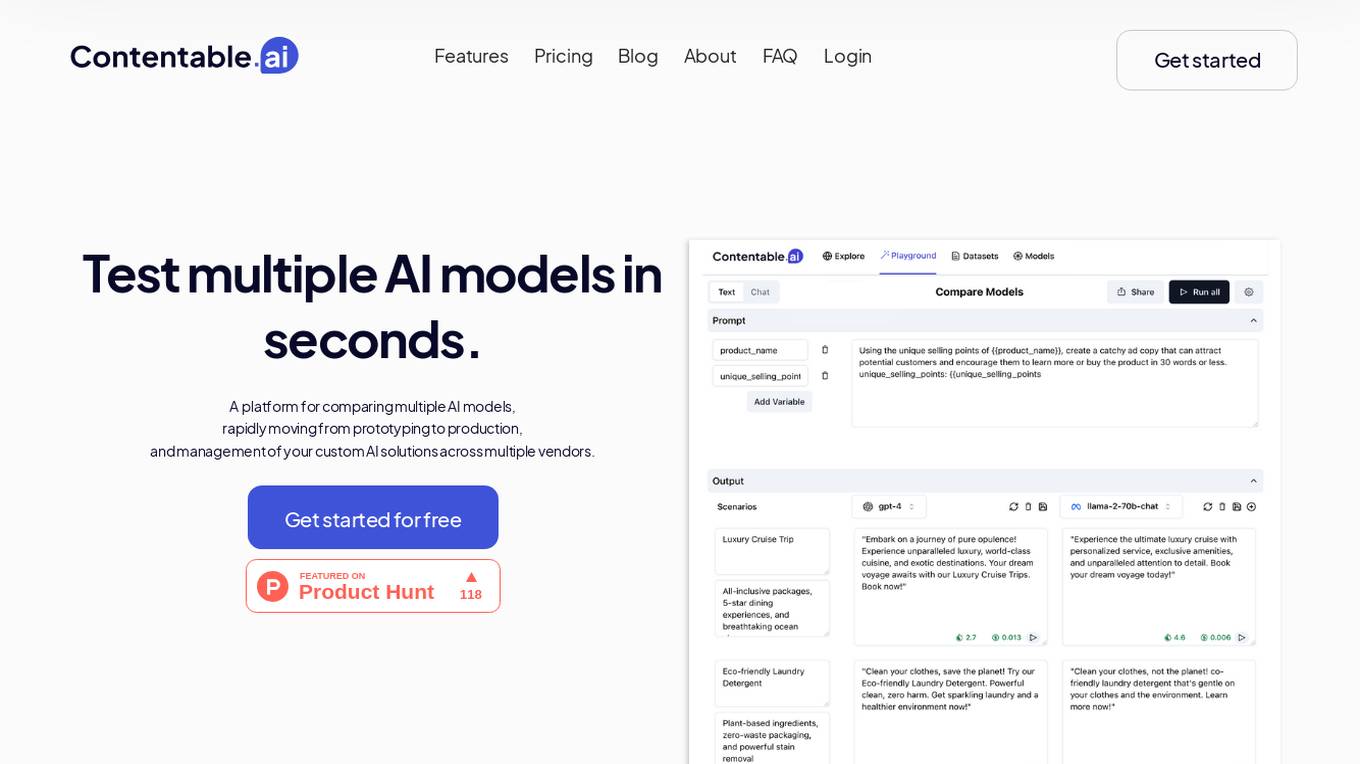
Contentable.ai
Contentable.ai is a platform for comparing multiple AI models, rapidly moving from prototyping to production, and management of your custom AI solutions across multiple vendors. It allows users to test multiple AI models in seconds, compare models side-by-side across top AI providers, collaborate on AI models with their team seamlessly, design complex AI workflows without coding, and pay as they go.
Backend.AI
Backend.AI is an enterprise-scale cluster backend for AI frameworks that offers scalability, GPU virtualization, HPC optimization, and DGX-Ready software products. It provides a fast and efficient way to build, train, and serve AI models of any type and size, with flexible infrastructure options. Backend.AI aims to optimize backend resources, reduce costs, and simplify deployment for AI developers and researchers. The platform integrates seamlessly with existing tools and offers fractional GPU usage and pay-as-you-play model to maximize resource utilization.
Radicalbit
Radicalbit is an MLOps and AI Observability platform that helps businesses deploy, serve, observe, and explain their AI models. It provides a range of features to help data teams maintain full control over the entire data lifecycle, including real-time data exploration, outlier and drift detection, and model monitoring in production. Radicalbit can be seamlessly integrated into any ML stack, whether SaaS or on-prem, and can be used to run AI applications in minutes.
Cresta AI
Cresta AI is an enterprise-grade Gen AI platform designed for the contact center, offering a suite of intelligent products that analyze conversations, provide real-time guidance to agents, and drive transformative results for Fortune 500 companies. The platform leverages generative AI to deliver targeted automation, personalized coaching, and AI-native management solutions, all trained on the user's data. Cresta's no-code command center empowers non-technical leaders to deploy AI models effortlessly, ensuring businesses can adapt and evolve seamlessly. With a focus on enhancing sales, customer care, retention, and collections processes, Cresta aims to revolutionize contact center operations with cutting-edge AI technology.

OAK
OAK is an open-source platform for building and deploying custom AI agents quickly and easily. It offers a modular design, powerful plugins, and seamless integration with various AI models. OAK is scalable, flexible, and developer-friendly, allowing users to create AI agents in minutes without hassle.
FluidStack
FluidStack is a leading GPU cloud platform designed for AI and LLM (Large Language Model) training. It offers unlimited scale for AI training and inference, allowing users to access thousands of fully-interconnected GPUs on demand. Trusted by top AI startups, FluidStack aggregates GPU capacity from data centers worldwide, providing access to over 50,000 GPUs for accelerating training and inference. With 1000+ data centers across 50+ countries, FluidStack ensures reliable and efficient GPU cloud services at competitive prices.
MindStudio
MindStudio is an AI application that allows users to create AI Workers for various tasks without the need for a PhD. It offers a simple and fast solution for building AI solutions, enabling users to automate tasks such as content translation, customer message enrichment, comment moderation, and more. With over 100,000 AI Workers in use, MindStudio provides a user-friendly platform to experiment with different AI models, optimize workflows, and connect to various applications seamlessly.
Portkey
Portkey is a control panel for production AI applications that offers an AI Gateway, Prompts, Guardrails, and Observability Suite. It enables teams to ship reliable, cost-efficient, and fast apps by providing tools for prompt engineering, enforcing reliable LLM behavior, integrating with major agent frameworks, and building AI agents with access to real-world tools. Portkey also offers seamless AI integrations for smarter decisions, with features like managed hosting, smart caching, and edge compute layers to optimize app performance.
ibl.ai
ibl.ai is a generative AI platform that focuses on education, providing cutting-edge solutions for institutions to create AI mentors, tutoring apps, and content creation tools. The platform empowers educators by giving them full control over their code, data, and models. With advanced features and support for both web and native mobile platforms, ibl.ai seamlessly integrates with existing infrastructure, making it easy to deploy across organizations. The platform is designed to enhance learning experiences, foster critical thinking, and engage students deeply in educational content.
VeroCloud
VeroCloud is a platform offering tailored solutions for AI, HPC, and scalable growth. It provides cost-effective cloud solutions with guaranteed uptime, performance efficiency, and cost-saving models. Users can deploy HPC workloads seamlessly, configure environments as needed, and access optimized environments for GPU Cloud, HPC Compute, and Tally on Cloud. VeroCloud supports globally distributed endpoints, public and private image repos, and deployment of containers on secure cloud. The platform also allows users to create and customize templates for seamless deployment across computing resources.
Weaviate
Weaviate is an AI-native database that developers love. It offers a feature-rich vector database trusted by AI innovators, empowering AI-native builders to create AI-powered search, retrieval augmented generation, and agentic AI applications. Weaviate simplifies the process of building production-ready AI applications by providing seamless model integration, pre-built database agents, and language-agnostic SDKs for easy development. With billion-scale architecture and enterprise-ready deployment options, Weaviate enables developers to scale seamlessly, deploy anywhere, and meet enterprise requirements. The platform is designed to help AI builders write less custom code, optimize costs, and build AI-native apps faster.
Autoblocks AI
Autoblocks AI is an AI application designed to help users build safe AI apps efficiently. It allows users to ship AI agents in minutes, speeding up the development process significantly. With Autoblocks AI, users can prototype quickly, test at a faster rate, and deploy with confidence. The application is trusted by leading AI teams and focuses on making AI agent development more predictable by addressing the unpredictability of user inputs and non-deterministic models.
Globalese by memoQ
Globalese by memoQ is a robust platform for training AI-powered custom machine translation models. It empowers enterprises and language service providers to easily create high-quality translation engines using their own data, tailored to their specific needs. The user-friendly platform integrates with popular translation management systems and offers an API for seamless workflow integration. With features like custom prompts, advanced tag handling, translation tool integration, supported languages for over 130 language combinations, granular permissions, and flexible deployment options, Globalese by memoQ streamlines the translation process with AI-powered custom models.
FriendliAI
FriendliAI is a generative AI infrastructure company that offers efficient, fast, and reliable generative AI inference solutions for production. Their cutting-edge technologies enable groundbreaking performance improvements, cost savings, and lower latency. FriendliAI provides a platform for building and serving compound AI systems, deploying custom models effortlessly, and monitoring and debugging model performance. The application guarantees consistent results regardless of the model used and offers seamless data integration for real-time knowledge enhancement. With a focus on security, scalability, and performance optimization, FriendliAI empowers businesses to scale with ease.
0 - Open Source AI Tools
20 - OpenAI Gpts


Instructor GCP ML
Formador para la certificación de ML Engineer en GCP, con respuestas y explicaciones detalladas.

HuggingFace Helper
A witty yet succinct guide for HuggingFace, offering technical assistance on using the platform - based on their Learning Hub

TensorFlow Oracle
I'm an expert in TensorFlow, providing detailed, accurate guidance for all skill levels.
ML Engineer GPT
I'm a Python and PyTorch expert with knowledge of ML infrastructure requirements ready to help you build and scale your ML projects.



![[latest] FastAPI GPT Screenshot](/screenshots_gpts/g-BhYCAfVXk.jpg)
[latest] FastAPI GPT
Up-to-date FastAPI coding assistant with knowledge of the latest version. Part of the [latest] GPTs family.
GPT Designer
A creative aide for designing new GPT models, skilled in ideation and prompting.

Pytorch Trainer GPT
Your purpose is to create the pytorch code to train language models using pytorch