Best AI tools for< Decode Data >
20 - AI tool Sites
Shib GPT
Shib GPT is an advanced AI-driven platform tailored for real-time crypto market analysis. It revolutionizes the realm of cryptocurrency by leveraging sophisticated algorithms to provide comprehensive insights into pricing, trends, and exchange dynamics. The platform empowers investors and traders with unparalleled accuracy and depth in navigating both decentralized and centralized exchanges, enabling informed decision-making with speed and precision. Shib GPT also offers a chat platform for dynamic interaction with financial markets, generating multimedia content powered by cutting-edge Large Language Models (LLMs).
Mendel AI
Mendel AI is an advanced clinical AI tool that deciphers clinical data with clinician-like logic. It offers a fully integrated suite of clinical-specific data processing products, combining OCR, de-identification, and clinical reasoning to interpret medical records. Users can ask questions in plain English and receive accurate answers from health records in seconds. Mendel's technology goes beyond traditional AI by understanding patient-level data and ensuring consistency and explainability of results in healthcare.
Decode Health
Decode Health is an AI and analytics platform that accelerates precision healthcare by supporting healthcare teams in launching machine learning and advanced analytics projects. The platform collaborates with pharmaceutical companies to enhance patient selection, biomarker identification, diagnostics development, data asset creation, and analysis. Decode Health offers modules for biomarker discovery, patient recruitment, next-generation sequencing, data analysis, and clinical decision support. The platform aims to provide fast, accurate, and actionable insights for acute and chronic disease management. Decode Health's custom-built modules are designed to work together to solve complex data problems efficiently.
Dataku.ai
Dataku.ai is an advanced data extraction and analysis tool powered by AI technology. It offers seamless extraction of valuable insights from documents and texts, transforming unstructured data into structured, actionable information. The tool provides tailored data extraction solutions for various needs, such as resume extraction for streamlined recruitment processes, review insights for decoding customer sentiments, and leveraging customer data to personalize experiences. With features like market trend analysis and financial document analysis, Dataku.ai empowers users to make strategic decisions based on accurate data. The tool ensures precision, efficiency, and scalability in data processing, offering different pricing plans to cater to different user needs.
Decode Investing
Decode Investing is an AI-powered platform that helps users automate their stock research process. The platform offers a range of tools such as an AI Chat assistant, Stock Screener, Earnings Calls analysis, SEC Filings analysis, and more. Users can easily find and analyze stocks by simply entering the stock name or ticker. Decode Investing aims to simplify the investment process by providing valuable insights and data to make informed decisions. The platform is designed to cater to both novice and experienced investors, offering a user-friendly interface and comprehensive features.
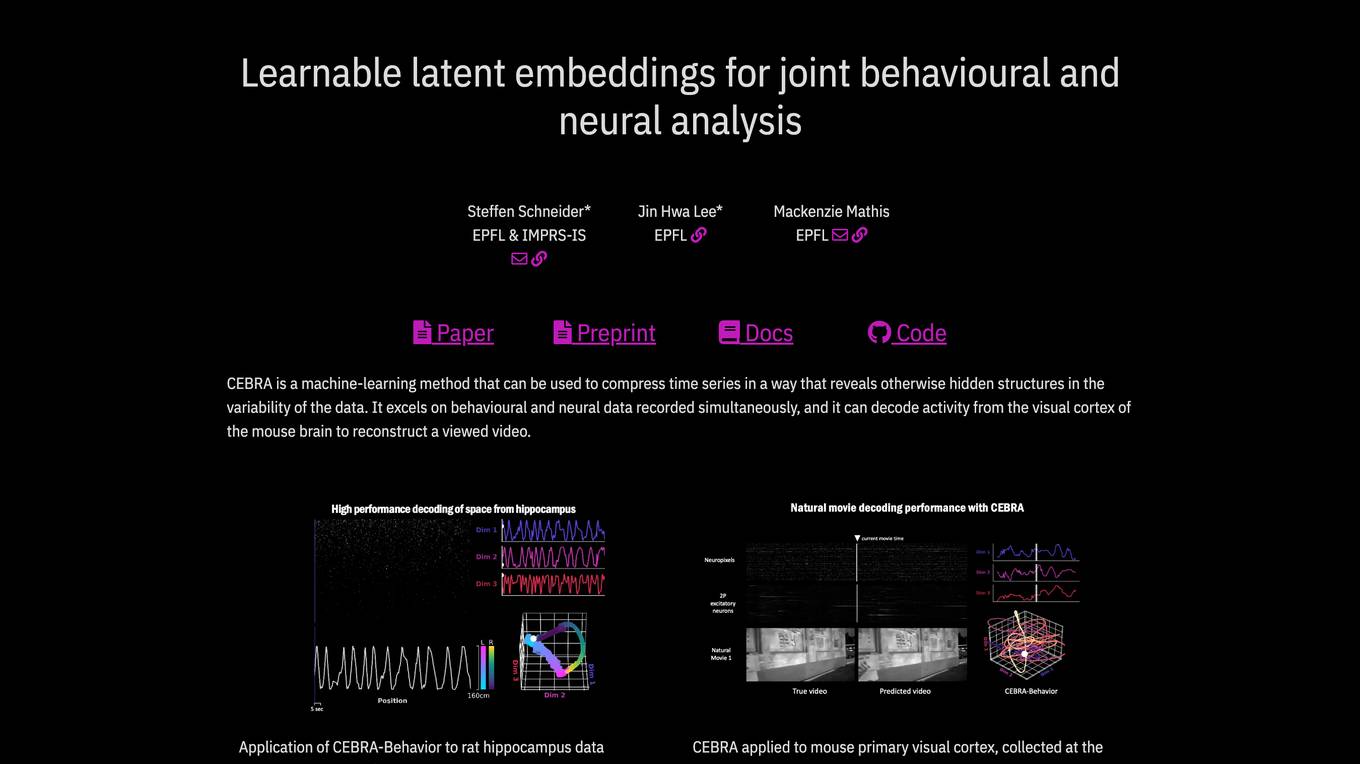
CEBRA
CEBRA is a self-supervised learning algorithm designed for obtaining interpretable embeddings of high-dimensional recordings using auxiliary variables. It excels in compressing time series data to reveal hidden structures, particularly in behavioral and neural data. The algorithm can decode neural activity, reconstruct viewed videos, decode trajectories, and determine position during navigation. CEBRA is a valuable tool for joint behavioral and neural analysis, providing consistent and high-performance latent spaces for hypothesis testing and label-free applications across various datasets and species.
Insitro
Insitro is a drug discovery and development company that uses machine learning and data to identify and develop new medicines. The company's platform integrates in vitro cellular data produced in its labs with human clinical data to help redefine disease. Insitro's pipeline includes wholly-owned and partnered therapeutic programs in metabolism, oncology, and neuroscience.
AI Synapse
AI Synapse is a GTM platform designed for AI workers to enhance outbound conversion rates and sales efficiency. It leverages AI-driven research, personalization, and automation to optimize sales processes, reduce time spent on sales tools, and achieve significant improvements in open, click, and reply rates. The platform enables users to achieve the output of a 30-person sales team in just 4-6 hours, leading to increased productivity and revenue generation. AI Synapse offers scalability, cost efficiency, advanced personalization, time savings, enhanced conversion rates, and predictable lead flow, making it a valuable tool for sales teams and businesses looking to streamline their outbound strategies.
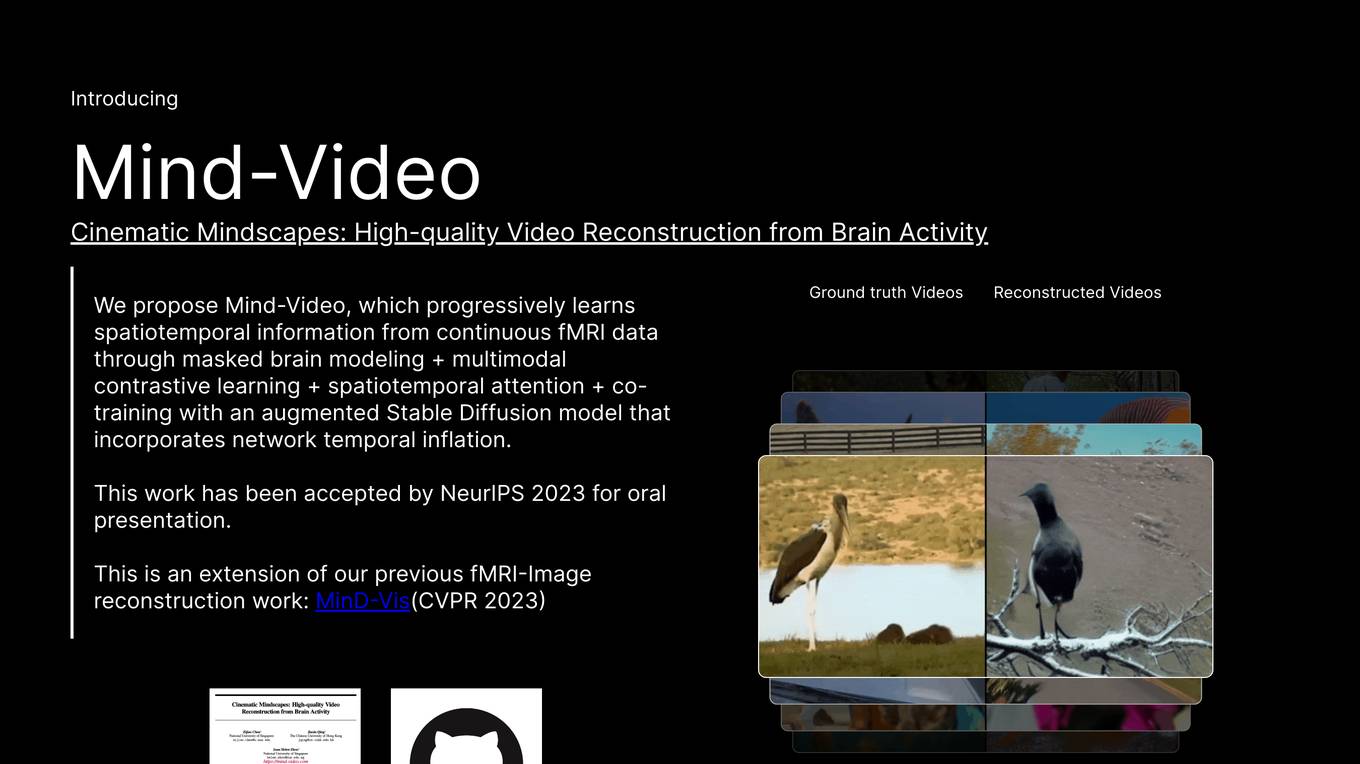
Mind-Video
Mind-Video is an AI tool that focuses on high-quality video reconstruction from brain activity data. It bridges the gap between image and video brain decoding by utilizing masked brain modeling, multimodal contrastive learning, spatiotemporal attention, and co-training with an augmented Stable Diffusion model. The tool aims to recover accurate semantic information from fMRI signals, enabling the generation of realistic videos based on brain activities.

Iris Dating
Iris Dating is an AI dating application that leverages artificial intelligence to match and date online. The app uses AI to understand users' preferences and present them with matches based on mutual attraction. By decoding the science of attraction, Iris Dating aims to revolutionize online dating by providing users with more meaningful and successful relationships.
ResearchFlow
ResearchFlow is an AI-powered research engine that enables users to conduct in-depth research, connect ideas, and enhance their research process through visual mind maps. The platform leverages AI technology to search scholarly databases, decode complex charts, and provide reliable answers from trusted sources. With interactive mind maps and AI-powered analysis, ResearchFlow simplifies the exploration of complex topics, making it easier for users to navigate and understand intricate subjects. Dive into a sea of knowledge with ResearchFlow and unlock a world of information at your fingertips.
implicator.ai
implicator.ai is an AI tool that provides a daily newsletter focusing on AI-related news, politics, coding trends, startups, research funding, and AI tools. The platform offers insights into the latest developments in the AI industry, including new models, acquisitions, legal battles, and market trends. With a team of tech journalists and analysts, implicator.ai decodes complex AI topics and delivers concise, informative content for readers interested in staying updated on the fast-paced world of artificial intelligence.
Buena.ai
Buena.ai is an AI-powered outreach platform designed to transform sales processes by leveraging AI agents to drive personalized outreach and pipeline growth. The platform empowers sales teams to focus on strategic tasks while AI agents handle automated lead generation, personalized engagement, and multi-channel outreach. Buena.ai offers advanced analytics, real-time data insights, and scalable solutions to enhance sales efficiency and productivity.
Entropik
Entropik is a Unified Insights Platform that helps businesses decode research chaos into revenue clarity. It offers an AI-powered solution that captures emotions, behaviors, and feedback to enable smarter decision-making 4x faster, with enhanced reliability and accuracy. The platform is trusted by 150+ CX leaders and is designed to empower teams across various departments to capture, interpret, and act on customer signals using Emotion, Behaviour, and Gen AI. Entropik provides real-time insights delivery, simplified research processes, and integrated multi-method approach to enhance customer experiences and drive business growth.
Hint
Hint is a hyper-personalized astrology app that combines NASA data with guidance from professional astrologers to provide personalized insights. It offers 1-on-1 guidance, horoscopes, compatibility reports, and chart decoding. Hint has become a recognized leader in the field of digital astrological services and is trusted by world's leading companies.

Vexa
Vexa is a real-time AI meeting assistant designed to empower users to maintain focus, grasp context, decode industry-specific terms, and capture critical information effortlessly during business meetings. It offers features such as instant context recovery, flawless project execution, industry terminology decoding, enhanced focus and productivity, and ADHD-friendly meeting assistance. Vexa helps users stay sharp in long meetings, record agreements accurately, clarify industry jargon, and manage time-sensitive information effectively. It integrates with Google Meet and Zoom, supports various functionalities using the GPT-4 Chat API, and ensures privacy through end-to-end encryption and data protection measures.

Danora
Danora is an AI application that offers Persona AI Agents to help personalize marketing strategies for Gen Z parents. These AI Agents decode online conversations to create virtual personas in real-time, providing actionable insights and enabling the launch of smarter, more personalized campaigns. The application gathers data from various platforms in multiple languages to deliver insights on trends, intent, emotions, behaviors, and sentiment of Gen Z parents. Users can interact with the AI Agents, ask questions, and receive instant answers on various topics. Danora aims to simplify the process from insight to action by offering a flexible and efficient solution for businesses to connect with their target audience effectively.
THE DECODER
THE DECODER is an AI tool that provides news, insights, and updates on artificial intelligence across various domains such as business, research, and society. It covers the latest advancements in AI technologies, applications, and their impact on different industries. THE DECODER aims to keep its audience informed about the rapidly evolving field of artificial intelligence.
THE DECODER
THE DECODER is an AI tool that provides 24/7 updates on artificial intelligence news, business, research, and more. It covers a wide range of topics related to AI applications in various fields such as technology, society, and research. The platform offers insights, analysis, and the latest developments in the AI industry to keep users informed and up-to-date.
Impact Stack
Impact Stack is an AI-powered research tool that provides evidence-based answers to your queries. It dispatches a team of AI agents with specialized tools to deliver rigorously researched answers quickly. The platform offers a natural language interface for asking questions about companies, industries, or research topics. Impact Stack eliminates the need for manual data input by handling searches and analyses across multiple databases simultaneously. Stay informed with the latest articles and updates from the platform.
0 - Open Source AI Tools
20 - OpenAI Gpts
Paper Interpreter (international)
Automatically structure and decode academic papers with ease - simply upload a PDF!
OGAA (Oil and Gas Acronym Assistant)
I decode acronyms from the oil & gas industry, asking for context if needed.

Emoji GPT
🌟 Discover the Charm of EmojiGPT! 🤖💬🎉 Dive into a world where emojis reign supreme with EmojiGPT, your whimsical AI companion that speaks the universal language of emojis. Get ready to decode delightful emoji messages, laugh at clever combinations, and express yourself like never before! 🤔
🧬GenoCode Wizard🔬
Unlock the secrets of DNA with 🧬GenoCode Wizard🔬! Dive into genetic analysis, decode sequences, and explore bioinformatics with ease. Perfect for researchers and students!
Social Navigator
A specialist in explaining social cues and cultural norms for clarity in conversations

N.A.R.C. Bott
This app decodes texts from narcissists, advising across all life scenarios. Navigate. Analyze. Recognize. Communicate.
What a Girl Says Translator
Simply tell me what the girl texted you or said to you, and I will respond with what she means. 💋