Best AI tools for< Data Preparation >
20 - AI tool Sites
Compact Data Science
Compact Data Science is a data science platform that provides a comprehensive set of tools and resources for data scientists and analysts. The platform includes a variety of features such as data preparation, data visualization, machine learning, and predictive analytics. Compact Data Science is designed to be easy to use and accessible to users of all skill levels.
Arcwise
Arcwise is a cloud-based data science platform that provides a comprehensive set of tools for data preparation, exploration, modeling, and deployment. It is designed to make data science accessible to users of all skill levels, from beginners to experts. Arcwise offers a user-friendly interface, drag-and-drop functionality, and a wide range of pre-built templates and algorithms. This makes it easy for users to get started with data science and quickly build and deploy machine learning models.
Cognee
Cognee is an AI application that helps users build deterministic AI memory by perfecting exceptional AI apps with intelligent data management. It acts as a semantic memory layer, uncovering hidden connections within data and infusing it with company-specific language and principles. Cognee offers data ingestion and enrichment services, resulting in relevant data retrievals and lower infrastructure costs. The application is suitable for various industries, including customer engagement, EduTech, company onboarding, recruitment, marketing, and tourism.
Akkio
Akkio is an AI data platform designed specifically for agencies and their clients. It offers a range of features to help agencies improve performance, including data preparation, predictive analytics, and reporting. Akkio is easy to use, with a drag-and-drop interface and no coding required. It also integrates with a variety of data sources, making it easy to get started.
OWOX BI
OWOX BI is a leading data democratization platform that empowers businesses by automating business reporting in Google Sheets, simplifying data preparation with SQL and No SQL, and providing AI-powered solutions for marketing analytics. The platform offers features such as AI Copilot for faster SQL queries, Cookieless Analytics Tracking, Dashboard Templates, and integrations with Google Analytics, Google Sheets, BigQuery, and various ad platforms. OWOX BI enables users to centralize and automate marketing and sales data, visualize data with templates, and measure marketing performance effectively. The platform fosters collaboration between data teams and business users, ensuring data accuracy, reliability, and ownership.
Tellius
Tellius is an AI Augmented Analytics Software and Decision Intelligence platform that empowers users to get faster insights from data, break silos between Business Intelligence (BI) and AI, and accelerate complex data analysis with AI-driven automation. The platform offers guided insights, data preparation, natural language search, automated machine learning, and self-service analytics & reporting. Tellius is loved by analytics and business teams for providing instant ad hoc answers, simplifying complex analysis, and surfacing hidden key drivers and anomalies through best-in-class automated insights.
Dflux
Dflux is a cloud-based Unified Data Science Platform that offers end-to-end data engineering and intelligence with a no-code ML approach. It enables users to integrate data, perform data engineering, create customized models, analyze interactive dashboards, and make data-driven decisions for customer retention and business growth. Dflux bridges the gap between data strategy and data science, providing powerful SQL editor, intuitive dashboards, AI-powered text to SQL query builder, and AutoML capabilities. It accelerates insights with data science, enhances operational agility, and ensures a well-defined, automated data science life cycle. The platform caters to Data Engineers, Data Scientists, Data Analysts, and Decision Makers, offering all-round data preparation, AutoML models, and built-in data visualizations. Dflux is a secure, reliable, and comprehensive data platform that automates analytics, machine learning, and data processes, making data to insights easy and accessible for enterprises.
Dataiku
Dataiku is an end-to-end platform for data and AI projects. It provides a range of capabilities, including data preparation, machine learning, data visualization, and collaboration tools. Dataiku is designed to make it easy for users to build, deploy, and manage AI projects at scale.

DataRobot
DataRobot is an AI tool that provides product documentation for users. It offers a comprehensive platform for leveraging AI and machine learning to automate and optimize various processes. With DataRobot, users can build, deploy, and manage machine learning models efficiently, enabling data-driven decision-making across different industries.
Alteryx
Alteryx offers a leading AI Platform for Enterprise Analytics that delivers actionable insights by automating analytics. The platform combines the power of data preparation, analytics, and machine learning to help businesses make better decisions faster. With Alteryx, businesses can connect to a wide variety of data sources, prepare and clean data, perform advanced analytics, and build and deploy machine learning models. The platform is designed to be easy to use, even for non-technical users, and it can be deployed on-premises or in the cloud.
IngestAI
IngestAI is a Silicon Valley-based startup that provides a sophisticated toolbox for data preparation and model selection, powered by proprietary AI algorithms. The company's mission is to make AI accessible and affordable for businesses of all sizes. IngestAI's platform offers a turn-key service tailored for AI builders seeking to optimize AI application development. The company identifies the model best-suited for a customer's needs, ensuring it is designed for high performance and reliability. IngestAI utilizes Deepmark AI, its proprietary software solution, to minimize the time required to identify and deploy the most effective AI solutions. IngestAI also provides data preparation services, transforming raw structured and unstructured data into high-quality, AI-ready formats. This service is meticulously designed to ensure that AI models receive the best possible input, leading to unparalleled performance and accuracy. IngestAI goes beyond mere implementation; the company excels in fine-tuning AI models to ensure that they match the unique nuances of a customer's data and specific demands of their industry. IngestAI rigorously evaluates each AI project, not only ensuring its successful launch but its optimal alignment with a customer's business goals.
Pecan AI
Pecan AI is a predictive analytics software product designed for business and data analysts. It offers blazing-fast predictions, seamless integrations, and requires no machine learning experience. Pecan empowers teams to succeed with impactful AI models, automates data preparation, and features a Predictive Chat, Predictive Notebook, and guided or DIY predictive modeling tools. The platform helps users build trustworthy predictive models, optimize campaigns, and make data-driven decisions to drive business growth.
Clarifai
Clarifai is a full-stack AI platform that provides developers and ML engineers with the fastest, production-grade deep learning platform. It offers a wide range of features, including data preparation, model building, model operationalization, and AI workflows. Clarifai is used by a variety of companies, including Fortune 500 companies and startups, to build AI applications in a variety of industries, including retail, manufacturing, and healthcare.
Clarifai
Clarifai is a full-stack AI developer platform that provides a range of tools and services for building and deploying AI applications. The platform includes a variety of computer vision, natural language processing, and generative AI models, as well as tools for data preparation, model training, and model deployment. Clarifai is used by a variety of businesses and organizations, including Fortune 500 companies, startups, and government agencies.

Activeloop
Activeloop is an AI tool that offers Deep Lake, a database for AI solutions across various industries such as agriculture, audio processing, autonomous vehicles, robotics, biomedical and healthcare, generative AI, multimedia, safety, and security. The platform provides features like fast AI search, faster data preparation, serverless DB for code assistant, and more. Activeloop aims to streamline data processing and enhance AI development for businesses and researchers.

madebymachines
madebymachines is an AI tool designed to assist users in various stages of the machine learning workflow, from data preparation to model development. The tool offers services such as data collection, data labeling, model training, hyperparameter tuning, and transfer learning. With a user-friendly interface and efficient algorithms, madebymachines aims to streamline the process of building machine learning models for both beginners and experienced users.

Mixpeek
Mixpeek is a multimodal intelligence platform that helps users extract important data from videos, images, audio, and documents. It enables users to focus on insights rather than data preparation by identifying concepts, activities, and objects from various sources. Mixpeek offers features such as real-time synchronization, extraction and embedding, fine-tuning and scaling of models, and seamless integration with various data sources. The platform is designed to be easy to use, scalable, and secure, making it suitable for a wide range of applications.
Baseten
Baseten is a machine learning infrastructure that provides a unified platform for data scientists and engineers to build, train, and deploy machine learning models. It offers a range of features to simplify the ML lifecycle, including data preparation, model training, and deployment. Baseten also provides a marketplace of pre-built models and components that can be used to accelerate the development of ML applications.
Invicta AI
Invicta AI is a provider of artificial intelligence solutions for the enterprise. The company's flagship product is a platform that enables businesses to build and deploy AI models without the need for specialized expertise. Invicta AI's platform provides a range of tools and services to help businesses with every step of the AI development process, from data preparation and model training to deployment and monitoring.
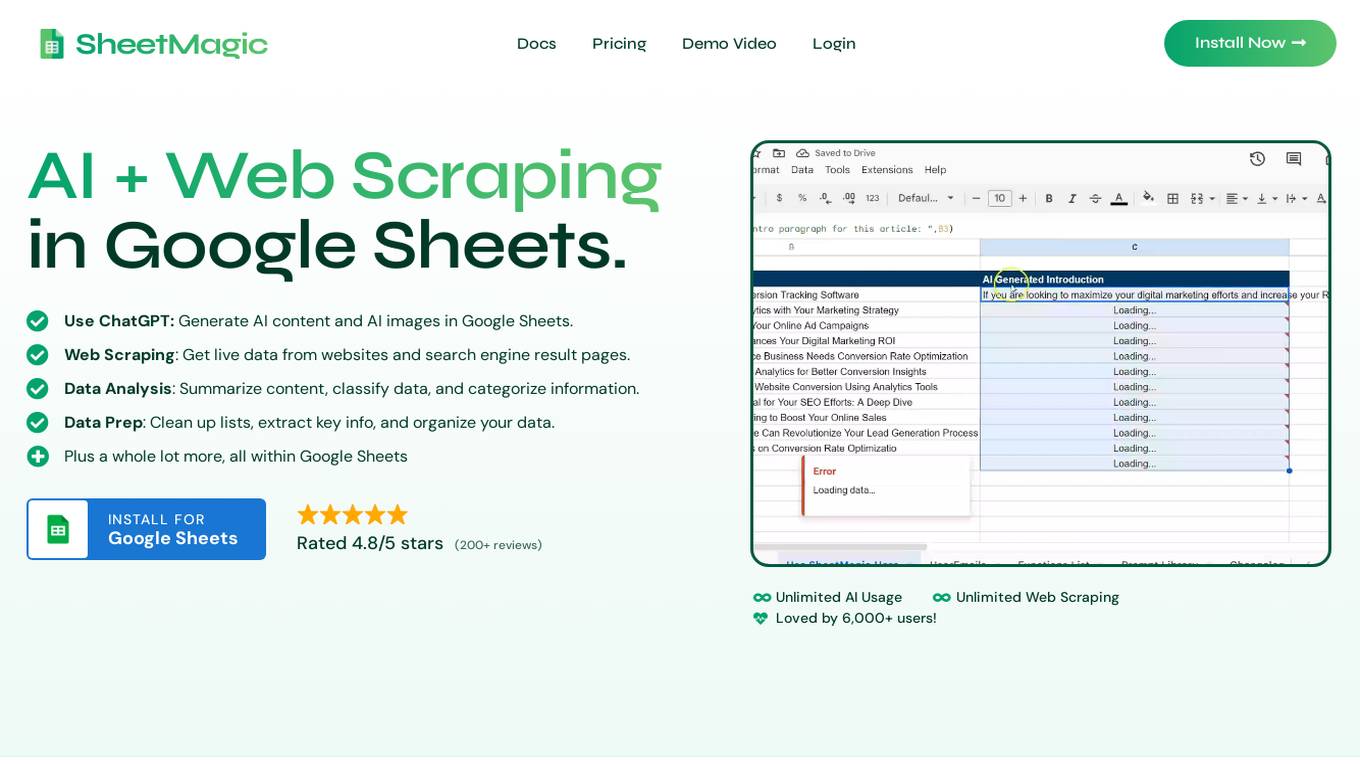
SheetMagic
SheetMagic is an AI-powered tool that allows users to perform various tasks within Google Sheets, including generating AI content, web scraping, data analysis, and data preparation. It integrates with ChatGPT, allowing users to access advanced AI capabilities without coding or hiring developers. SheetMagic is designed to enhance productivity and streamline workflows for individuals and teams.
0 - Open Source AI Tools
20 - OpenAI Gpts

College entrance exam prediction app
Our college entrance exam prediction app uses advanced algorithms and data analysis to provide accurate predictions for students preparing to take their college entrance exams.


Interview Pro
By combining the expertise of top career coaches with advanced AI, our GPT helps you excel in interviews across various job functions and levels. We've also compiled the most practical tips for you | We value your experience, please contact [email protected] if you need support ❤️!
Algo Final Exam Tutor
I assist in studying for an algorithms exam, guiding through concepts and problems.
Tech Interview Coach
Your go-to guide for nailing tech interviews with dynamic mock sessions!

Vorstellungsgespräch Simulator Bewerbung Training
Wertet Lebenslauf und Stellenanzeige aus und simuliert ein Vorstellungsgespräch mit anschließender Auswertung: Lebenslauf und Anzeige einfach hochladen und starten.
Mock Interview Practice
4.5 ★ A mock interview is a practice interview, that could be useful while you're looking for a job. This GPT works for any job and any language.

EconoGraph
Expert in Micro Economics, interprets graphs, explains concepts, avoids direct exam answers.
Begum Bozoglu
According to the relevant documents, what questions may arise during the job interview?
Dream Job Interview Ace
I'm a specialized recruiter, conducting realistic job interviews based on provided job postings.

Hiring Helper & Interview Whiz
AI assistant creating interview questions tailored to your company, the role, and candidates' background
Back Propagation
I'm Back Propagation, here to help you understand and apply back propagation techniques to your AI models.