Best AI tools for< Create Voices >
20 - AI tool Sites
Respeecher
Respeecher is an AI tool that combines technology and magic to deliver authentic voices across various industries. It uses cutting-edge public models and proprietary technology to provide high-quality voice solutions. The team of dedicated sound professionals at Respeecher ensures ethical use of synthetic media, making it a trusted choice for voice cloning and voice conversion services.
Replica Studios
Replica Studios is an AI tool that provides cutting-edge text-to-speech and speech-to-speech solutions in multiple languages for creative professionals. It offers fully licensed AI models safe for commercial use, allowing users to customize voices for various creative and professional use cases, such as gaming, animation, film, audiobooks, e-learning, and social media. The tool enables users to generate voice overs and dialogue instantly, manage scripts, and create unique voices using Voice Lab. Replica Studios prioritizes ethical voice AI by collaborating with voice actors and ensuring commercial use compliance.
Resemble AI
Resemble AI is an AI-powered platform that offers AI Voice Generator and Deepfake Detection services for enterprises. The platform provides features such as Generative AI Voice Cloning, Text to Speech, Speech to Speech conversion, Multilingual support, Audio Editing, and Open Source Voice Cloning AI Model. Resemble AI focuses on delivering state-of-the-art AI models for voice generation and deepfake detection, ensuring security and trust for its users.
TikTok Voice Generator
TikTok Voice Generator is an AI tool that allows users to generate various AI voices for TikTok videos. Users can choose from a wide range of voice options including different languages, accents, genders, and characters. The tool provides a simple interface where users can input text and generate the desired voice within seconds. It is a free text-to-speech generator specifically designed for TikTok content creators.
Sesame AI
Sesame AI is an advanced AI voice synthesis platform that revolutionizes digital speech creation by combining AI technology with natural language processing. It offers incredibly lifelike voices with emotional expression and conversational flow, making it ideal for content creators, developers, and businesses seeking to enhance their applications with natural voice capabilities.
LMNT
LMNT is an ultrafast lifelike AI speech pricing API that offers low latency streaming for conversational apps, agents, and games. It provides lifelike voices through studio-quality voice clones and instant voice clones. Engineered by an ex-Google team, LMNT ensures reliable performance under pressure with consistent low latency and high availability. The platform enables real-time conversation, content creation at scale, and product marketing through captivating voiceovers. With a user-friendly interface and developer API, LMNT simplifies voice cloning and synthesis for both beginners and professionals.
Enginn Studio
Enginn Studio is an AI-accelerated voice production tool that empowers users to give a voice to their characters, from prototyping to production. With the ability to generate voices 100 times faster in 30 languages, Enginn Studio revolutionizes the process of voice creation for various applications such as animation, gaming, and storytelling.
Sound of Text
Sound of Text is a free online text-to-speech converter that uses AI technology to convert written text into spoken words. It supports over 840 different voices in more than 135 languages, and allows users to download the resulting audio files in a variety of formats. Sound of Text is easy to use and can be used for a variety of purposes, such as creating audiobooks, podcasts, and presentations.
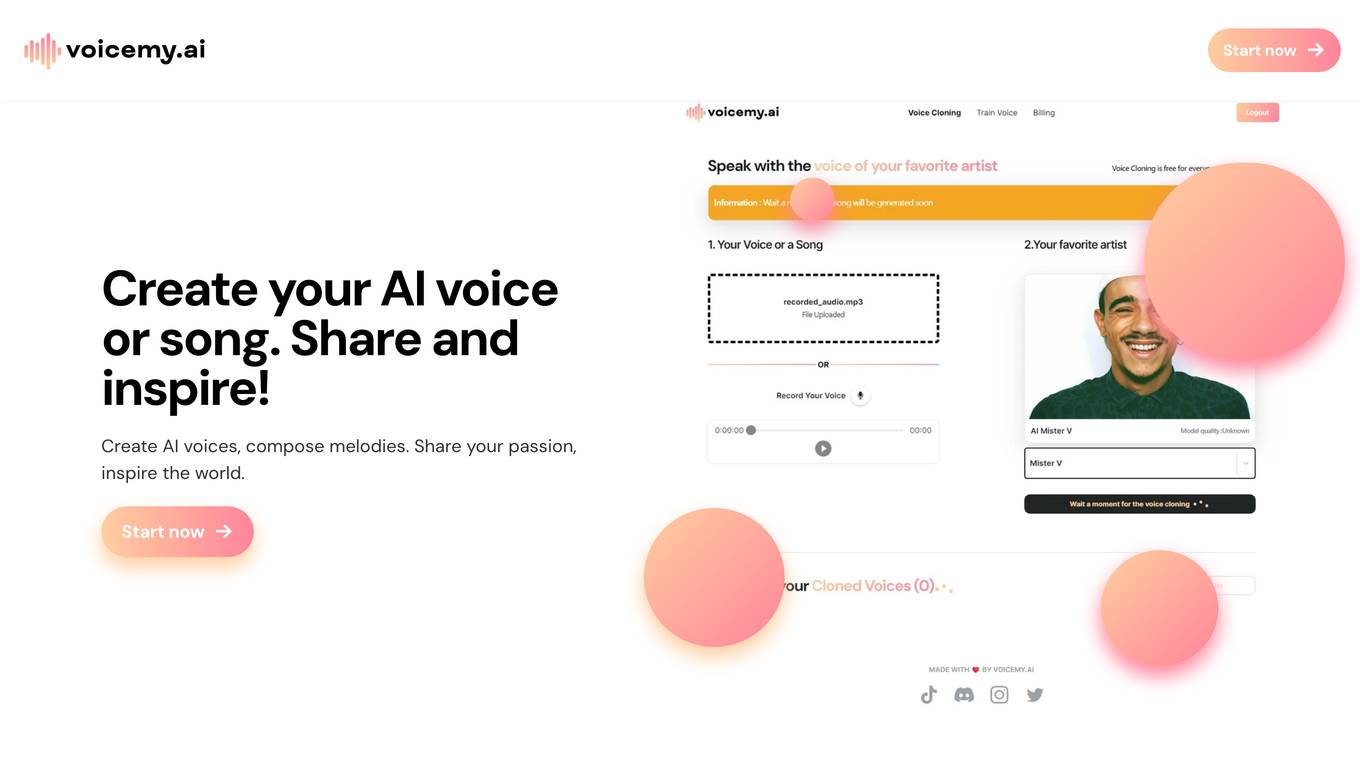
Voicemy.ai
Voicemy.ai is an AI application that allows users to create AI voices and songs. Users can clone voices of famous personalities, compose melodies, and convert text into spoken words using chosen voice models. The platform aims to inspire creativity and enable users to share their passion with the world.
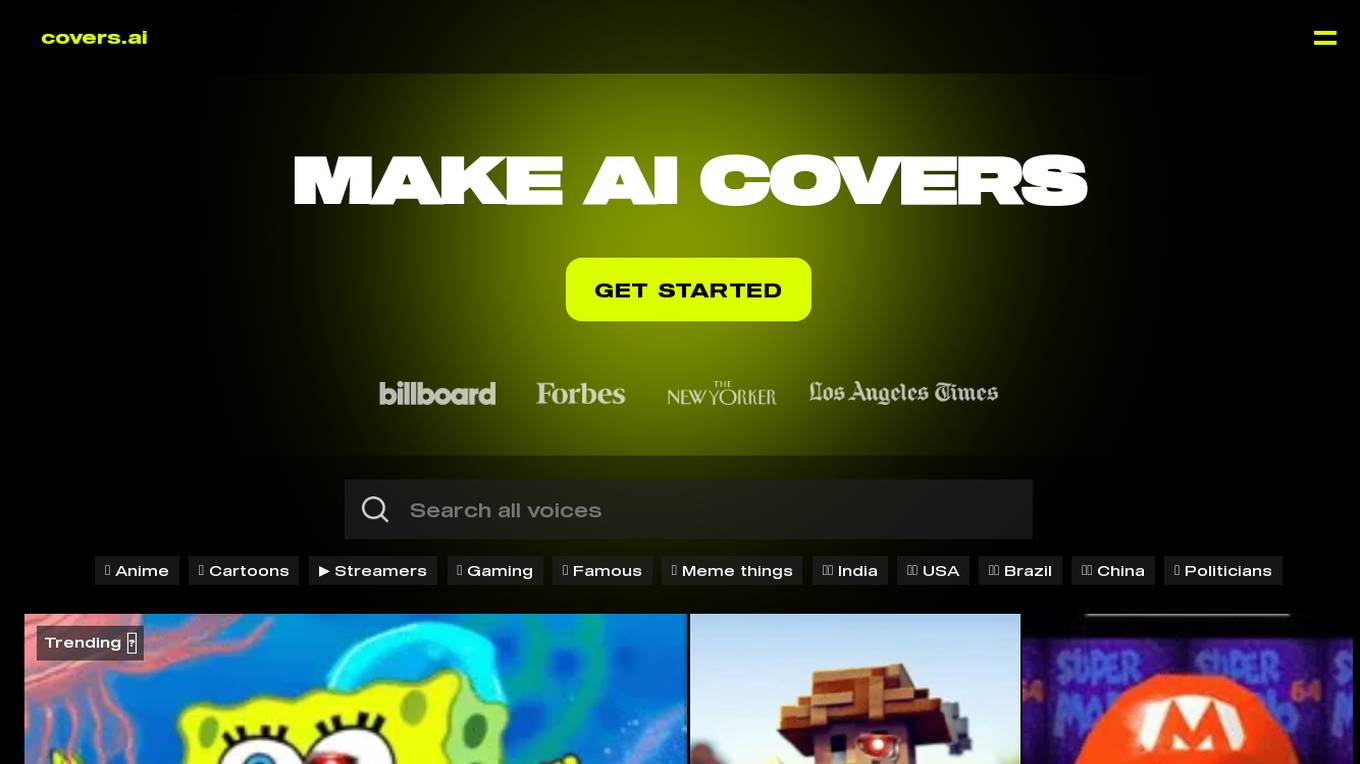
Covers.AI
Covers.AI is an AI voice generator and AI song generator platform that allows users to create custom AI voices by uploading voice recordings. It offers a wide range of AI voice models for various categories such as anime, cartoons, streamers, gaming, famous personalities, and more. Users can easily generate AI voices and songs in minutes, making it a game-changing tool for music lovers of all levels of expertise. Covers.AI provides a user-friendly experience, empowering users to control and enhance their voices effortlessly.
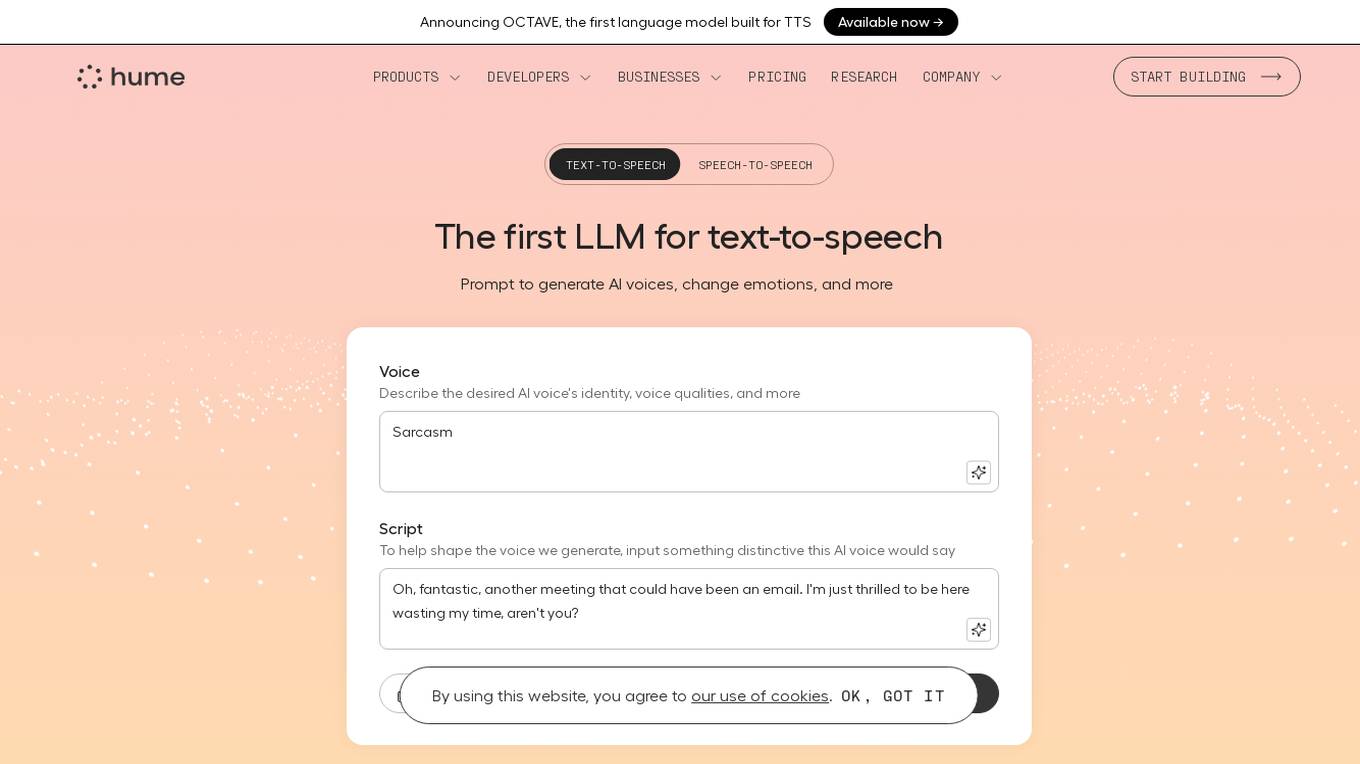
Hume AI - Octave
Hume AI is an AI application that offers the Octave language model for text-to-speech (TTS) capabilities. It provides a voice-based LLM that understands words in context to predict emotions, cadence, and more. Users can create various AI voices with specific prompts and scripts, adjusting emotional delivery and speaking styles on command. The application aims to generate expressive AI voices for podcasts, voiceovers, audiobooks, and more, with total control over the voice output.

Controlla Voice
Controlla Voice is an AI application that allows users to transform vocals into new voices or instruments, swap any song to their own voice in any language, and create unique blended voices. Users can train their own AI singing voice, generate AI cover songs, and create realistic choirs with customizable harmonies. The application provides a vocal toolkit for never-before-heard sounds and offers flexible pricing options to access high-quality AI singing voices. With Controlla Voice, users can enhance their voice, express themselves in their most natural way, and monetize their music with automatic royalties.
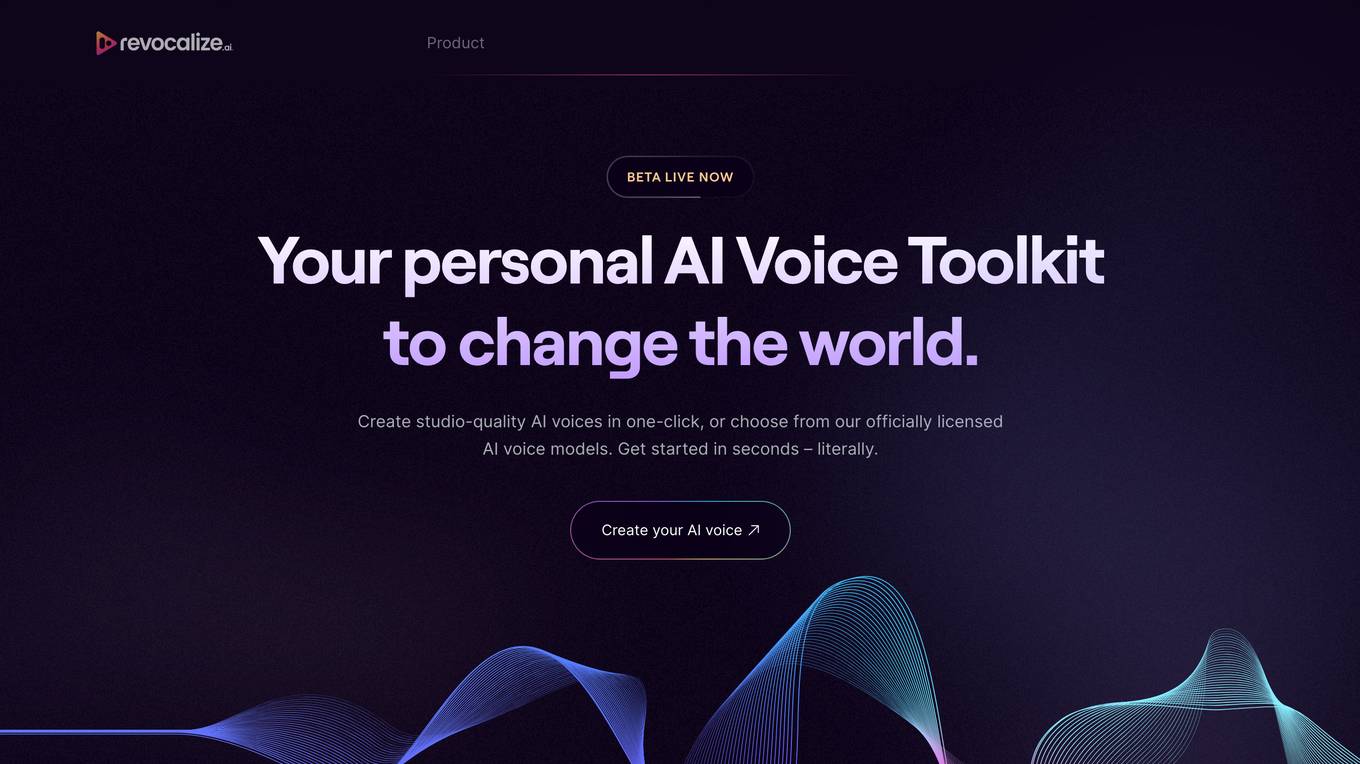
Revocalize AI
Revocalize AI is a studio-level AI voice generation and music tool that allows users to create studio-quality AI voices with human-level emotion in one click. The platform offers a range of features such as voice beautification, voice transformation, and real-time auto-pitch, enabling users to enhance their vocal performance and create unique voice models. With Revocalize AI, users can synthesize voices in multiple languages, adjust voice parameters, and generate vocal variations effortlessly. The application is trusted by award-winning creators and professionals and offers a collaborative platform for music enthusiasts to explore the unlimited potential of their voices.
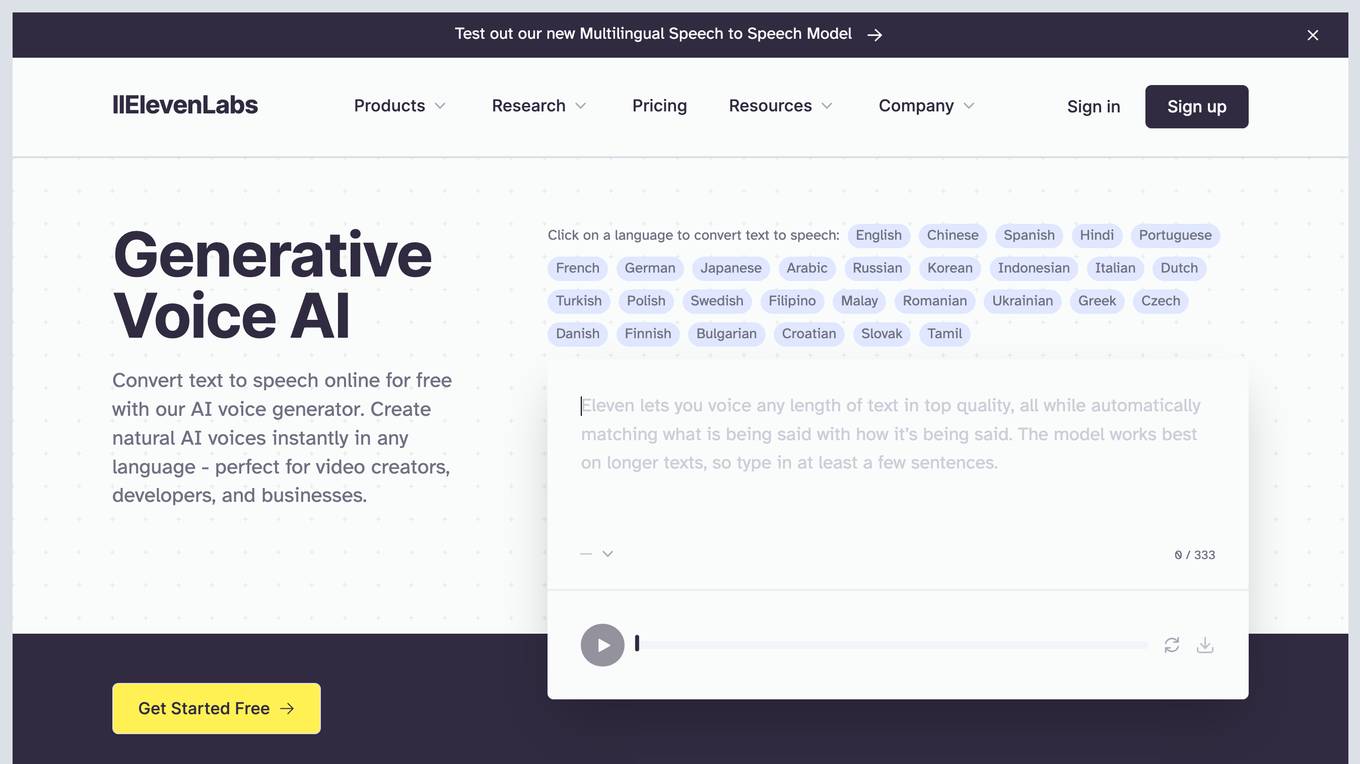
ElevenLabs
ElevenLabs is a text-to-speech (TTS) platform that uses artificial intelligence (AI) to generate realistic human-like voices. With ElevenLabs, you can convert any text into high-quality spoken audio in over 29 languages and 120 voices. The platform is easy to use and offers a variety of features, including the ability to adjust the voice's pitch, speed, and volume. You can also use ElevenLabs to create custom voices and clone your own voice. ElevenLabs is a powerful tool for content creators, businesses, and anyone who wants to create realistic spoken audio.
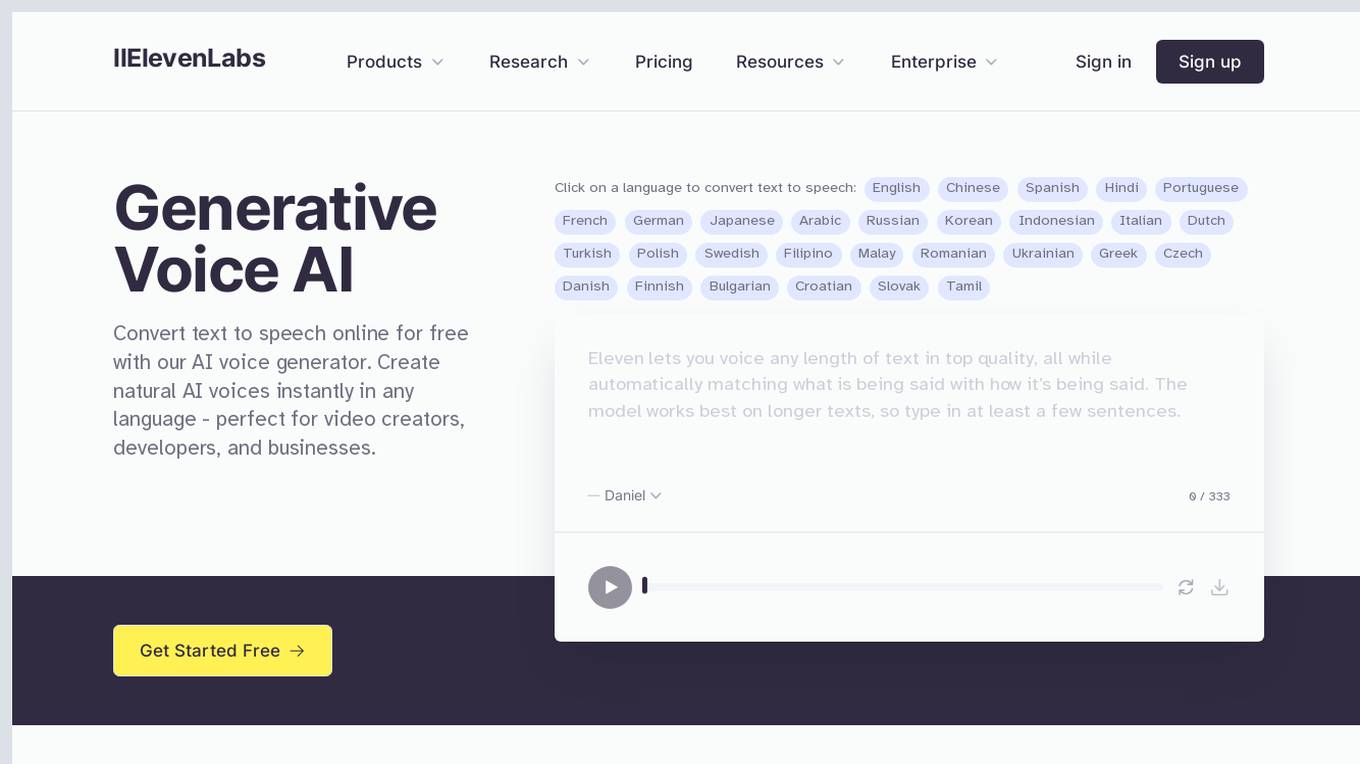
ElevenLabs
ElevenLabs is an AI voice generator and text-to-speech application that allows users to convert text into natural-sounding AI voices in various languages. The platform offers high-quality spoken audio with human intonation and inflections, suitable for video creators, developers, and businesses. Users can create lifelike voices for videos, gaming, audiobooks, chatbots, and more. ElevenLabs supports 29 languages and diverse accents, providing advanced AI text-to-speech technology for generating audio content.
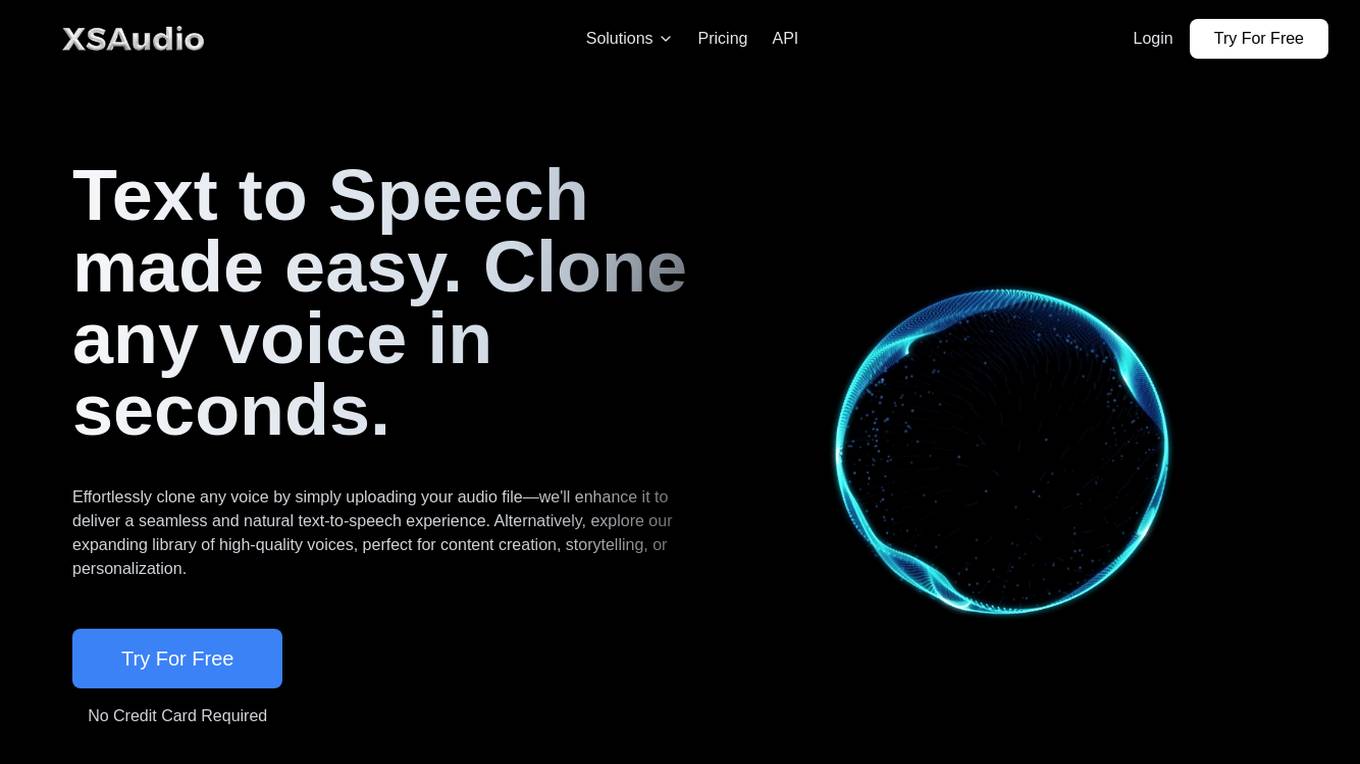
EZClone
EZClone is a voice cloning service powered by advanced AI technology that allows users to effortlessly clone any voice by uploading an audio file. Users can access a growing library of high-quality voices or create custom voice clones for content creation, storytelling, or personalization. The application offers different pricing plans with varying features and benefits, including audio enhancement, voice cloning, and access to premium voices. Users can easily generate high-quality audio files by selecting a voice, entering text, and clicking to generate the audio. Additionally, EZClone provides technical support based on the user's subscription plan, ensuring a seamless experience for voice synthesis enthusiasts.
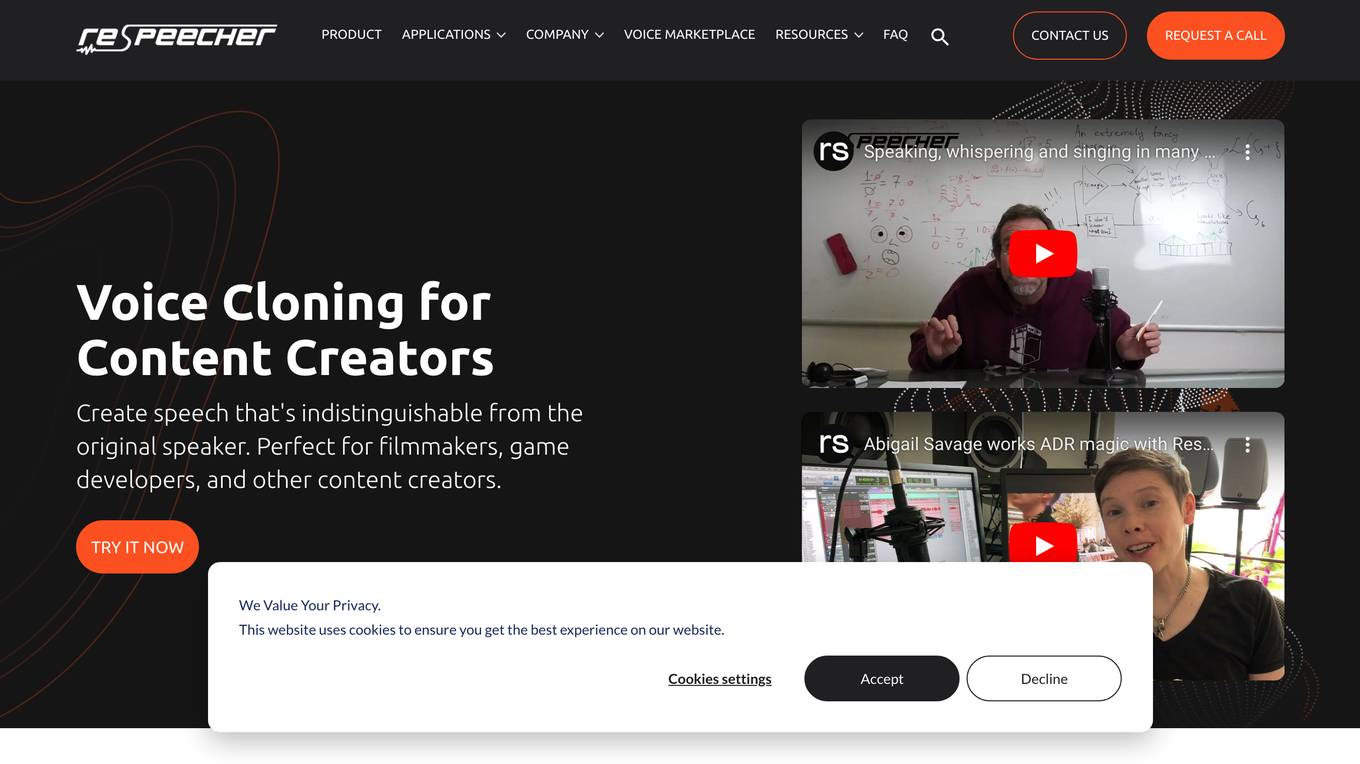
Respeecher
Respeecher is a voice cloning software that allows users to create synthetic voices that are indistinguishable from the original speaker. The software is used by content creators in a variety of industries, including film, television, gaming, advertising, and audiobooks. Respeecher's technology is based on artificial intelligence and machine learning, and it can replicate the voice of any person with just a few minutes of audio recording. The software is easy to use and can be accessed through a web interface. Respeecher offers a variety of features, including the ability to change the pitch, speed, and volume of the synthetic voice, as well as the ability to add effects such as reverb and delay. The software also includes a library of pre-recorded voices that can be used for a variety of purposes.
Uberduck
Uberduck is an AI-powered platform that allows users to create synthetic singing and rapping vocals. With Uberduck, users can choose from a collection of beats, generate lyrics with AI or write their own, choose a voice from a library of built-in voices or create their own custom voice, and download their creation as an audio or video file. Uberduck's technology has been used by major companies and artists, and has been featured in popular songs and videos.
UniDub
UniDub is a multi-lingual AI dubbing platform that allows users to create or dub videos in over 40 languages. It is cost-effective, expressive, super fast, and easy to use. UniDub can be used for a variety of purposes, including dubbing videos, creating animated videos, making audiobooks, and creating custom avatars and voices.

Resemble AI
Resemble AI is a cutting-edge generative voice AI platform that empowers enterprises with advanced voice cloning, deepfake detection, and AI watermarking capabilities. Our suite of tools enables the creation of realistic synthetic voices, detection of AI-generated content, and protection of intellectual property. With Resemble AI, businesses can enhance customer service, elevate gaming experiences, revolutionize entertainment, and safeguard their digital assets.
1 - Open Source AI Tools
openroleplay.ai
Open Roleplay is an open-source alternative to Character.ai. It allows users to create their own AI characters, customize them, and generate images and voices for them. Open Roleplay also supports group chat and automatic translation. The tool is built with Next.js, React.js, Tailwind CSS, Vercel, Convex, and Clerk.
20 - OpenAI Gpts
Little Voices Big World
I create engaging homeschool curricula for preschool to 2nd grade, focusing on inclusivity and interactive learning.
Confident Communicator
Generates, elevates, and transforms all types of communications, empowering you to effortlessly create messages in your style, invent new voices, or tap into its collection of learned tones.



Voice Memo
Record your thoughts with ChatGPT Voice Conversations 💡. Get started by clicking the 🎧 icon right to the chat input. Available on mobile only. Ask 'how do you work?' to learn more.
Bring Your Writing Voice to Every Task
This GPT will help you recreate your writing voice across multiple tasks. All you need is a prior writing sample (email, blog, article, tweet) and a new task.
Vedic Voice
A scholar in Hindu literature providing positive, brief insights against negativity.
Commerce Cloud Guru
Professional voice for SFCC B2C Commerce Cloud expertise. 🔒 Unlock the full potential of B2C Commerce Cloud

The Master in Brand Identity - GetMax
Guiding startups to creating unique brand/product voice & tone for content marketing.
Content Creator Pro with Video AI & SEO
Expert in content design and voiceovers, now with link-viewing capabilities.
Transcript to Social Post
Transforms transcripts (from Whatsapp voice memos) into engaging social media content.
Text Playground
Best AI-powered Text Playground!! I am your go-to assistant for text-to other media conversions. Flawelessly convert any text to voice, image, or video!! I am here to help. Ask me anything!!