Best AI tools for< Create Audio Scripts >
20 - AI tool Sites

Speakperfect
Speakperfect is an AI tool that enables users to create flawless audio effortlessly. It allows users to transform their speech into perfect scripts and audio with ease. The tool offers features such as creating great flow, removing filler words, selecting appropriate words, outputting to multiple languages, and generating indistinguishable voice clones. Users can record or upload content, transform it, and generate professional voice-overs. Speakperfect is praised for its simplicity, usefulness, and potential in various areas like work communication, marketing, and content creation.
Audyo
Audyo is an AI tool that allows users to create human-quality AI voices easily by simply typing text. With over 100 voices to choose from, users can select speakers in various languages, accents, and even celebrity impersonators. The tool enables users to edit words, not waveforms, and export audio for use in videos, podcasts, presentations, and more. Audyo also offers features like creating conversations, mixing and matching languages, customizing pronunciations, and utilizing an AI assistant for script tweaking. Users can enjoy 15 minutes of audio generation with a free account and earn additional time by inviting friends. Audyo empowers creators to unleash their imagination and enhance their content with lifelike AI voices.
Epicly.ai
Epicly.ai is an AI-powered tool designed to help businesses, startups, and individuals create high-quality audio ads with unprecedented speed. The tool features a simple guided process for ideation, script structuring, voiceover generation, and script editing. It eliminates the need for manual scriptwriting by providing flexible exports to various file formats. With an intuitive AI scriptwriting interface and a range of built-in voices, Epicly.ai streamlines the content creation process for marketing professionals, small business owners, and startup founders.
RE:Create
RE:Create is an AI-powered app that provides endless content ideas and recreates any Instagram/Tiktok video in your style, tone, language, and even your voice! Our application streamlines the content creation process, eliminating the need for extensive planning and strategy. Save time and effort while achieving effective results. No need to hire a separate voiceover artist. Our application offers customizable voice options, ensuring your videos have the perfect audio to complement the visuals. No need to hire a professional scriptwriter. Our platform assists in creating engaging video scripts, guiding you through the process and ensuring your content flows seamlessly.
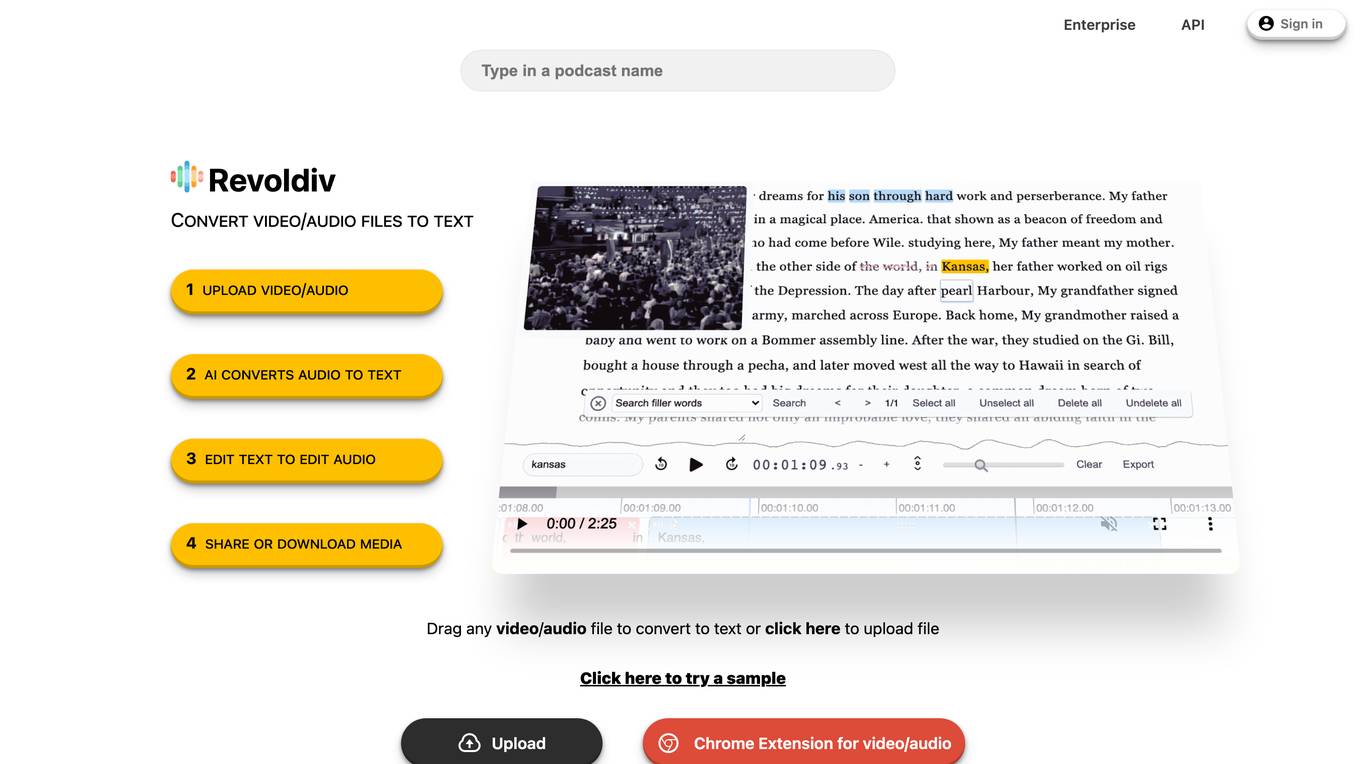
Revoldiv
Revoldiv is an online tool that allows users to convert video and audio files into text. It uses artificial intelligence to transcribe the audio, and users can then edit the text to remove filler words, create audiograms, and export the files in a variety of formats. Revoldiv is a valuable tool for anyone who needs to transcribe audio or video files, and it is easy to use and affordable.
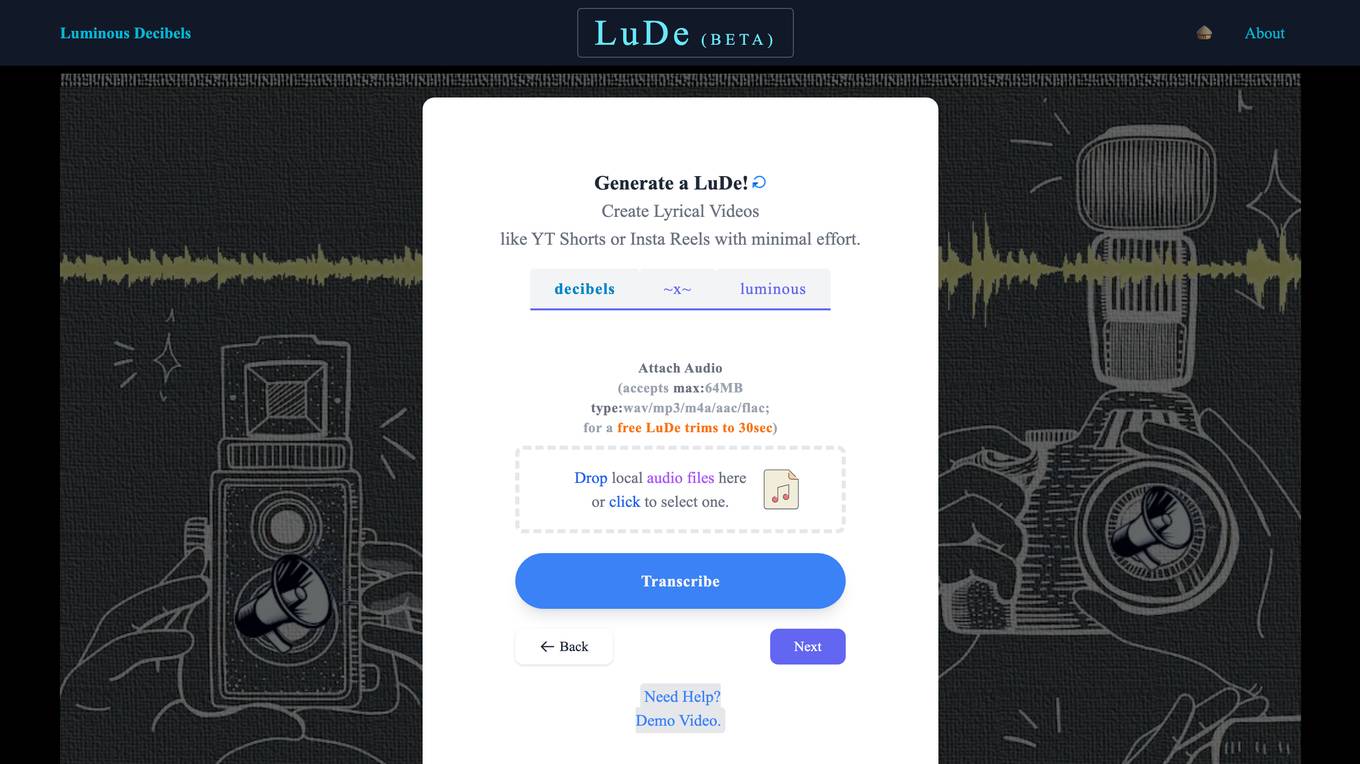
LuDe
LuDe is an AI-powered video creator application that allows users to generate lyrical videos like YouTube Shorts or Instagram Reels with minimal effort. Users can attach audio files in various formats and transcribe scripts to customize their videos. The application offers different video background options and requires users to 'Luminate' before the final video creation. LuDe leverages AI technology to create engaging video content based on the provided audio or text input.
Write Label
Write Label is a creative workflow platform that combines the expertise of human creatives with the power of AI to deliver innovative and high-quality creative solutions. The platform offers tools for copywriting, synthetic voiceover, audio production, and more, helping users save time, increase sales, and scale their businesses. With Write Label, users can access a custom approach to campaign success, exciting prospects and clients with compelling content. The platform also provides opportunities for professional creatives to join the community, work on projects, earn money, and improve their creative skills with feedback and resources.
HappyScribe
HappyScribe is an AI transcription tool that converts audio and video files into text with high accuracy. It offers a seamless and efficient way to transcribe various types of content, saving time and effort for users. The tool is equipped with advanced AI technology to ensure precise transcription results. HappyScribe is trusted by professionals, students, and content creators for its reliability and user-friendly interface.
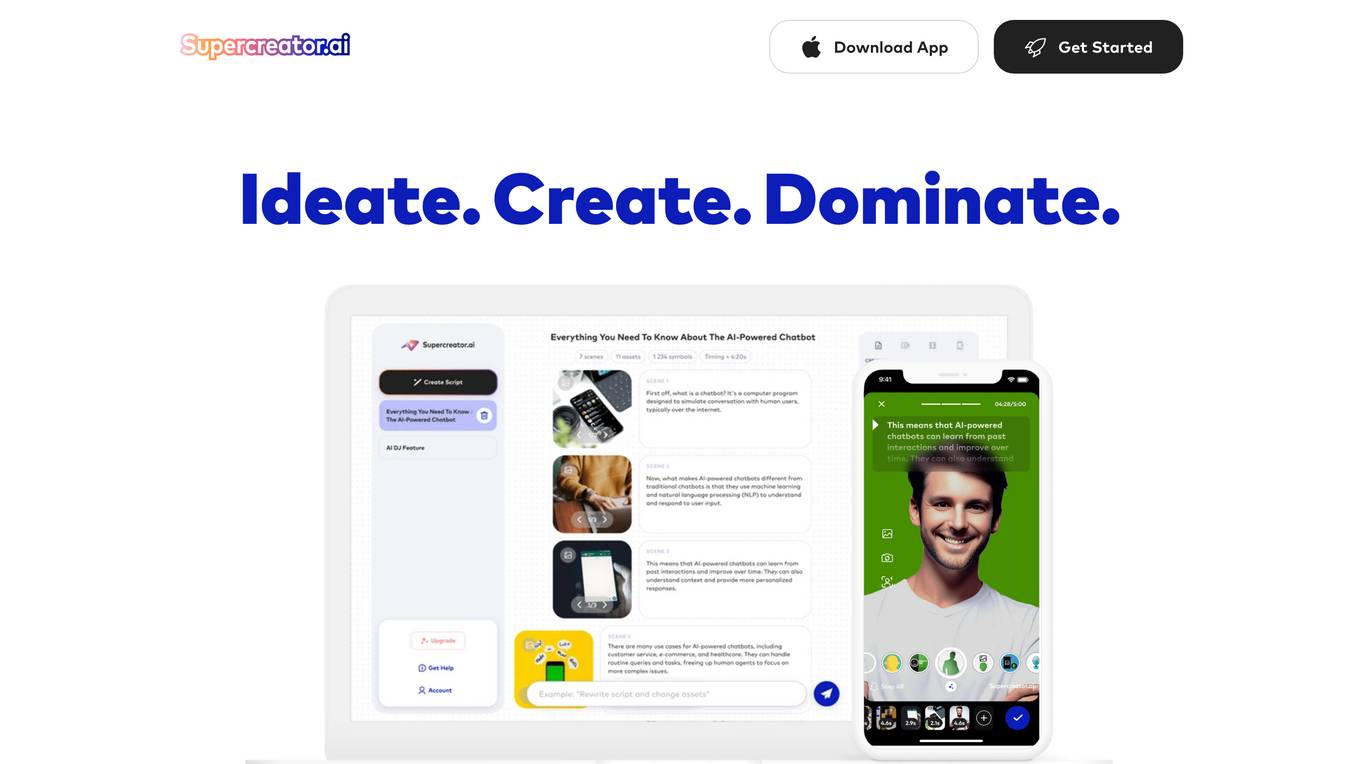
Supercreator
Supercreator is an AI-powered video creation platform that helps users create short-form videos quickly and easily. With a range of features to guide users through every stage of video creation, Supercreator simplifies tasks and makes video creation accessible to everyone. The platform offers features such as converting articles, Twitter threads, and YouTube videos to scripts, as well as providing natural text to script, importing scripts, and creating scripts from scratch. Supercreator also includes advanced editing capabilities such as advanced captions, auto-placement of relevant titles, smart trimming of empty pauses, super editing, adding overlay images and texts, and using fully customizable templates. Additionally, the platform provides a dynamic green screen, AR filters, text-to-filter, voice-controlled camera, HD recording, and audio-only recording options. Supercreator also assists with posting videos by exporting them in various formats to popular platforms and automatically tailoring hashtags, captions, catchy titles, and long posts to improve algorithm performance.

SRVO
SRVO is a voice over service that provides high-quality, professional voice overs for a variety of purposes, including commercials, e-learning, and audiobooks. With a team of experienced voice actors and a state-of-the-art recording studio, SRVO can create custom voice overs that meet the specific needs of each client. SRVO also offers a variety of additional services, such as scriptwriting, audio editing, and mixing.

VO3 AI
VO3 AI is an innovative AI video generator powered by Veo3 AI technology. It transforms scripts, ideas, or prompts into immersive videos with high-fidelity motion and storytelling. Users can create cinematic videos in minutes, customize visuals, and download finished clips in popular formats. The platform offers advanced features like high-fidelity visuals, multi-style rendering, dynamic scene understanding, and fine-grained controls. VO3 AI caters to various industries such as marketing, education, and entertainment, providing a user-centric interface for both creatives and non-technical users.
Steve.AI
Steve.AI is an AI video generator tool that allows users to create videos using text. It goes beyond simple text-to-video conversion by offering a wide range of video styles and features. With over 2,000,000 users, Steve AI is the go-to AI video maker for communicating effectively with a global audience. The tool enables users to generate various video outputs, including animations, GenAI, and live training videos, by converting text, scripts, and audio into engaging visual content. Steve AI also features an advanced AI video editor with over 40 video editing tools and a vast collection of hybrid assets, making it a comprehensive solution for creating professional videos.
DreamShorts
DreamShorts is an AI-powered toolkit for video and audio content creation. It offers a range of features to help users create original, unique, copyright-free scripts and video content. These features include a script generator, video content generator, AI narrator, social media integrations, and auto-captioning. DreamShorts is designed to be easy to use and affordable, making it a great option for content creators of all levels.
LazyBird
LazyBird is an AI Voice-Over Generator that provides realistic voices with natural intonations, offering the best AI voice-over experience to captivate your audience. Users can easily create voice-overs by uploading scripts, selecting voices, editing timing, and exporting the final result. With a wide range of characters, accents, and tones to choose from, LazyBird allows users to find the perfect voice for their content. Additionally, users can sync their video and audio files with AI-generated voice-overs, access a rich library of stock videos and images, and enjoy features like granular word-level control, 60+ natural-sounding voices, 100+ languages and accents, advanced audio timeline, and more.
Boolvideo
Boolvideo is an AI video generator application that allows users to turn various content such as product URLs, blog URLs, images, and text into high-quality videos with dynamic AI voices and engaging audio-visual elements. It offers a user-friendly interface and a range of features to create captivating videos effortlessly. Users can customize videos with AI co-pilots, choose from professional templates, and make advanced edits with a lightweight editor. Boolvideo caters to a wide range of use cases, including e-commerce, content creation, marketing, design, photography, and more.
BIGVU
BIGVU is a comprehensive video creation platform that offers a wide range of AI-powered tools to help users create professional-looking videos quickly and easily. With BIGVU, users can create engaging video scripts, use a teleprompter with beauty filters, add captions and edit videos, and automate posting to social media accounts. BIGVU is designed to be user-friendly and accessible to users of all skill levels, making it an ideal tool for businesses, marketers, educators, and anyone looking to create high-quality videos.
Guide.AI
Guide.AI is a platform that allows users to create and publish audio guides quickly and easily, using advanced AI text-to-speech and translation technology. Users can develop and distribute audio guides in multiple languages without the need for audio recordings or specialist equipment. The platform aims to enhance audience experience, boost income, accessibility, inclusivity, and engagement for guide authors and users alike.

ScriptMe
ScriptMe is a web-based platform that provides automated transcription and subtitling services. It uses artificial intelligence (AI) to convert audio and video files into text, and then allows users to edit and export the transcripts in a variety of formats. ScriptMe is designed to be fast, accurate, and easy to use, and it can be used for a variety of purposes, including: * Transcribing interviews, lectures, and meetings * Creating subtitles for videos * Generating transcripts for podcasts and webinars * Providing closed captions for videos * Translating audio and video files into different languages
Firebay Studios
Firebay Studios is an AI-powered platform that enables users to create high-quality radio ads in seconds. The tool helps companies and organizations of all sizes to automate production processes, streamline ad creation, and ultimately boost revenue. With features like AI & Cloned Voices, Editing & Production, Script Writing, SFX & Music, and support for 29 languages, Firebay Studios offers a comprehensive solution for creating captivating audio-based advertisements effortlessly.
MakeFilm.AI
MakeFilm.AI is the ultimate all-in-one AI video platform that transforms your ideas into captivating video content. With no specialized knowledge required, it maximizes your creativity by converting your concepts and stories into videos in just three simple steps. The platform offers three video models (V2, V3, V4) with V4 being the industry-leading model, multilingual support, AI voice generation, high-precision subtitle removal, and a user-friendly interface with tutorials and templates for beginners. MakeFilm.AI caters to various users including social media creators, business professionals, educators, and professional creators, enabling them to create high-quality videos effortlessly.
0 - Open Source AI Tools
20 - OpenAI Gpts
SpeechGPT User Guide
A guide for using SpeechGPT, focusing on its features, setup, and usage.
MUSIC + AI = MUSI.CAI
MUSIC + AI: Your key to original AI music creation. Create hits, explore genres, and tap into global trends. The ultimate tool for artists and producers.


ReaperGPT
Expert for the Reaper DAW with extensive knowledge on Reapack Packages, ReaScript, EEL, Lua, Python, general commands, and audio workflows.

Transcript GPT
Give me an audio transcript and I'll give you summarization, insights and actionable plan.
Mike Russell
Virtual Mike Russell from Music Radio Creative. Ask me your audio, podcasting and AI questions!

JollyDays: Your Festive Daily Adventure
Experience daily Christmas joy! Fun coloring, crafts, recipes, cultural insights with audio guides, and curated videos - perfect for festive creativity with your loved ones!
Able-Nature's Echo.
Guides users through beautiful landscapes with spatial audio for immersion.
ArtGPT
Doing art design and research, including fine arts, audio arts and video arts, designed by Prof. Dr. Fred Y. Ye (Ying Ye)


Ableton Live Mentor
Your personal Ableton Live mentor. Ask me anything about using Live for music production or live performance.