Best AI tools for< Create Audio Files >
20 - AI tool Sites
Voicemaker
Voicemaker is a text-to-speech converter that allows users to create audio files for commercial use. It offers a variety of features, including the ability to select from a range of AI-powered voices, adjust the speed, pitch, and volume of the audio, and add background music. Voicemaker's audio files can be shared on any platform worldwide and are trusted by over 1000 well-known brands.
Audyo
Audyo is a text-to-speech tool that allows users to create realistic-sounding audio from text. With over 100 voices to choose from, users can create audio in a variety of languages and accents. Audyo is easy to use, simply type in your text and select a voice. You can then download your audio file or embed it on your website or blog. Audyo is a great tool for creating voiceovers for videos, podcasts, audiobooks, and more.
CloneMyVoice
CloneMyVoice is an AI tool that specializes in creating AI audio voiceovers for long-form content such as podcasts, presentations, and social media. Users can save up to 80% compared to competitors and 99% compared to human voice actors. The platform allows users to upload source audio files and text, provide voice samples, and receive processed audio files within one hour. CloneMyVoice offers the ability to create audio presentations, social media content, podcasts, and audio books effortlessly. The AI can generate flawless English voices with British or American accents, capturing the tone and essence of the original voice.
Voice Embed
Voice Embed is an AI tool that allows users to convert any text into audio using AI technology. Users can easily embed the generated audio into their websites, making the content more engaging and interactive. Voice Embed provides a one-click solution to create and share audio from articles, with free cloud storage for all generated audio files. The tool simplifies the process of adding audio to blogs and websites, offering a user-friendly experience for content creators.
Woord
Woord is an online text-to-speech (TTS) tool that allows users to convert text into natural-sounding speech. It offers a wide range of voices in over 34 languages, including regional variations. Woord also provides advanced features such as SSML editing, OCR support, and API access. With its user-friendly interface and affordable pricing, Woord is a great choice for individuals and businesses looking to add speech capabilities to their applications.
imagetomp3.com
imagetomp3.com is a website that allows users to convert images to MP3 files. Users can upload an image, and the website will convert it into an audio file. The site provides a simple and convenient way to create audio files from images, which can be useful for various purposes such as creating audio versions of visual content or generating unique sound effects. imagetomp3.com offers a user-friendly interface and quick conversion process, making it a handy tool for those looking to convert images to audio effortlessly.
Nemesys Labs
Nemesys Labs is a free AI-powered text-to-speech platform that utilizes artificial intelligence technology to convert written text into spoken words. Users can easily generate high-quality audio files from any text input, making it a valuable tool for content creators, educators, and individuals seeking accessible content. The platform offers a user-friendly interface and a range of customization options to tailor the voice, tone, and speed of the generated speech. Nemesys Labs aims to enhance communication and accessibility by providing a seamless text-to-speech solution for various applications.
AI Music Generator (AMG)
AI Music Generator (AMG) is an AI tool that allows users to generate audio clips up to 30 seconds long by describing them with words. It utilizes Stable Diffusion for audio generation and is powered by Meta's AudioCraft. Users can create new audio clips at a cost of $0.008 per second, with a trial period of 60 seconds. Signing up or logging in is required to start generating, with new accounts being auto-created if necessary.
Sound of Text
Sound of Text is a free online text-to-speech converter that uses AI technology to convert written text into spoken words. It supports over 840 different voices in more than 135 languages, and allows users to download the resulting audio files in a variety of formats. Sound of Text is easy to use and can be used for a variety of purposes, such as creating audiobooks, podcasts, and presentations.
FakeYou
FakeYou is a free online tool that allows you to create realistic text-to-speech audio files. With FakeYou, you can choose from a variety of voices, languages, and accents to create custom audio files that sound like real people. FakeYou is perfect for creating voiceovers for videos, presentations, or other projects.
Lovevoice AI Voice Generator
Lovevoice is an AI Voice Generator that transforms text into natural-sounding speech using AI technology. It offers over 70 languages and nearly 300 AI voices, customizable voice settings, file transcription support, and MP3 download capabilities. Lovevoice's advanced AI ensures generated voiceovers are human-like, making it ideal for various applications such as videos, podcasts, audiobooks, and personalized audio messages. Users can quickly convert text into high-quality audio files with multilingual global support.
AudioForgeAI
AudioForgeAI is an AI-powered online platform that offers advanced audio editing and enhancement tools. Users can easily upload their audio files and apply various editing techniques to improve the quality and clarity of the sound. The platform is designed to be user-friendly and intuitive, making it suitable for both beginners and experienced audio professionals. With AudioForgeAI, users can enhance audio recordings, remove background noise, adjust volume levels, and apply various effects to create high-quality audio content.
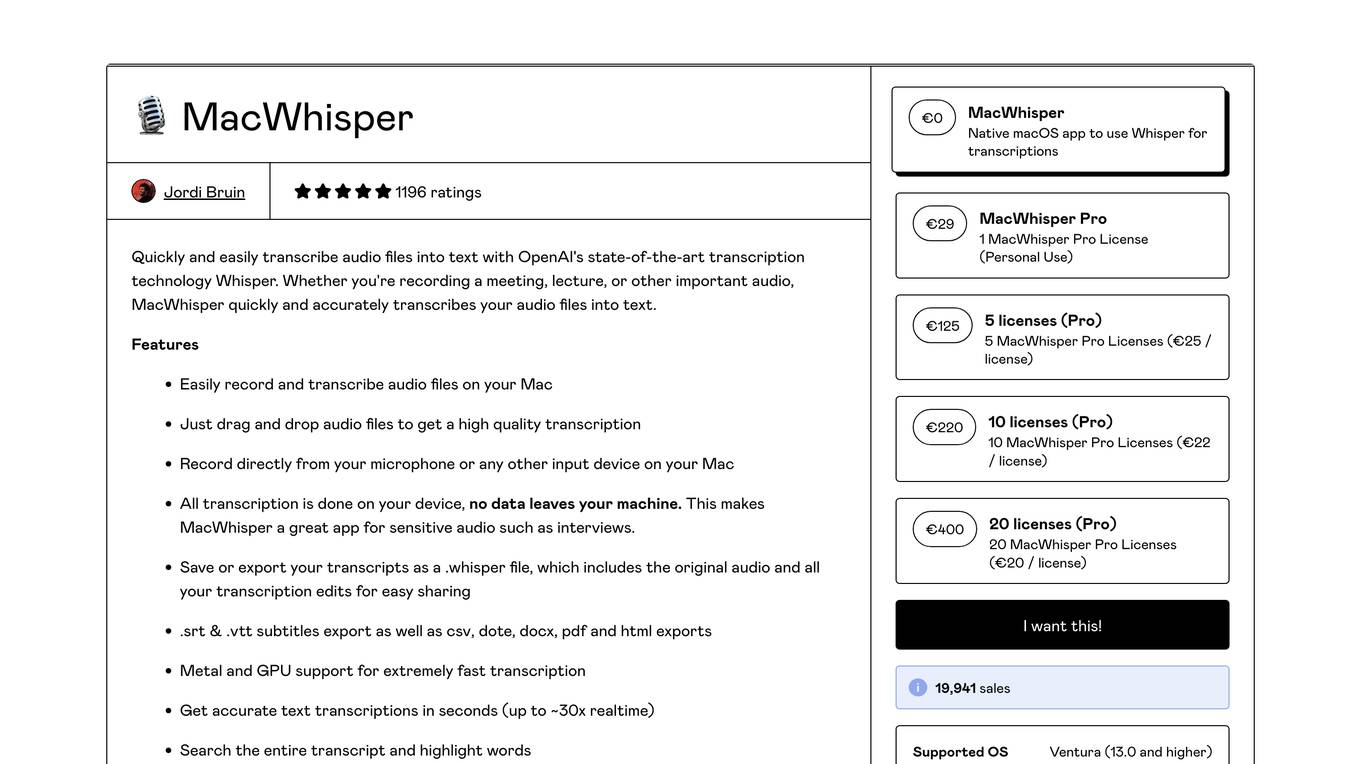
MacWhisper
MacWhisper is a native macOS application that utilizes OpenAI's Whisper technology for transcribing audio files into text. It offers a user-friendly interface for recording, transcribing, and editing audio, making it suitable for various use cases such as transcribing meetings, lectures, interviews, and podcasts. The application is designed to protect user privacy by performing all transcriptions locally on the device, ensuring that no data leaves the user's machine.
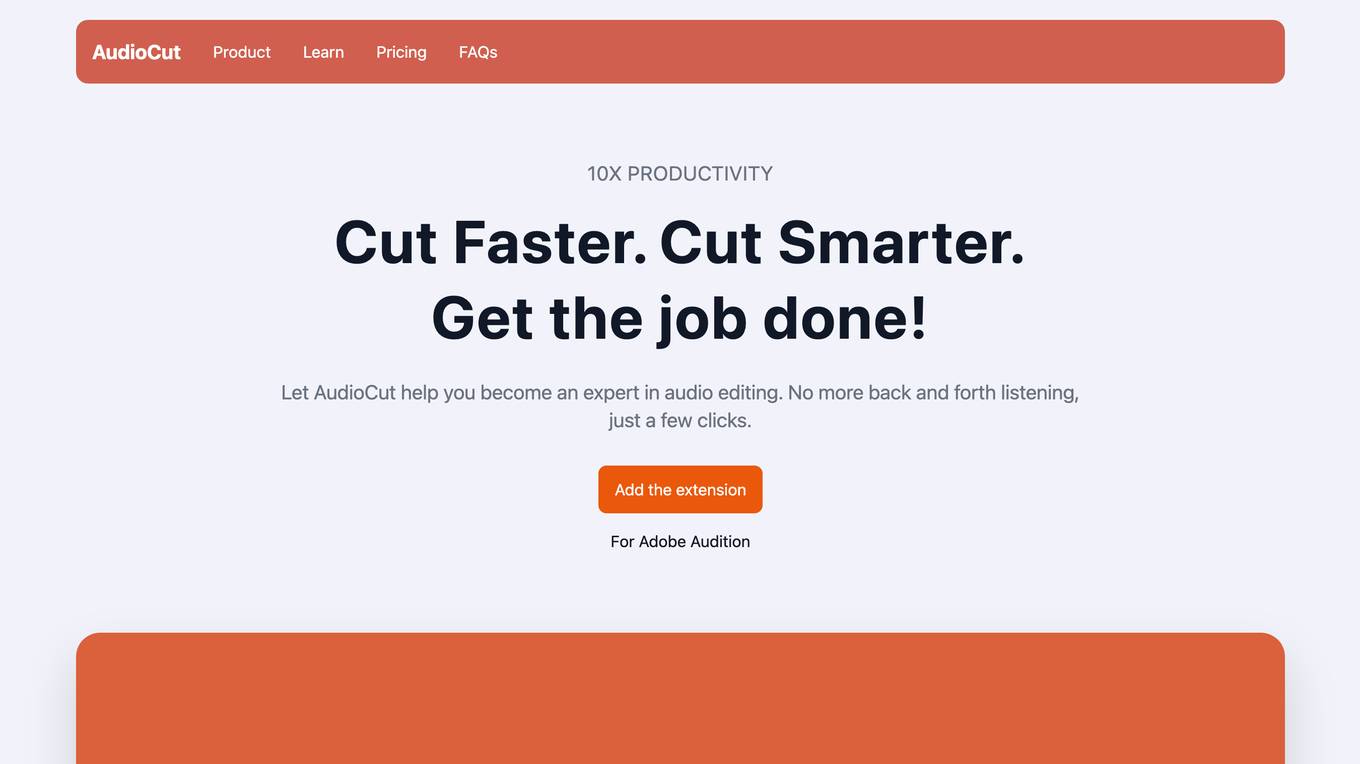
AudioCut
AudioCut is a web-based application that allows users to easily edit and trim audio files online. With AudioCut, users can upload their audio files, make precise cuts, adjust volume levels, and download the edited files in various formats. The intuitive interface and simple tools make it a convenient choice for anyone looking to edit audio files without the need for complex software installations.
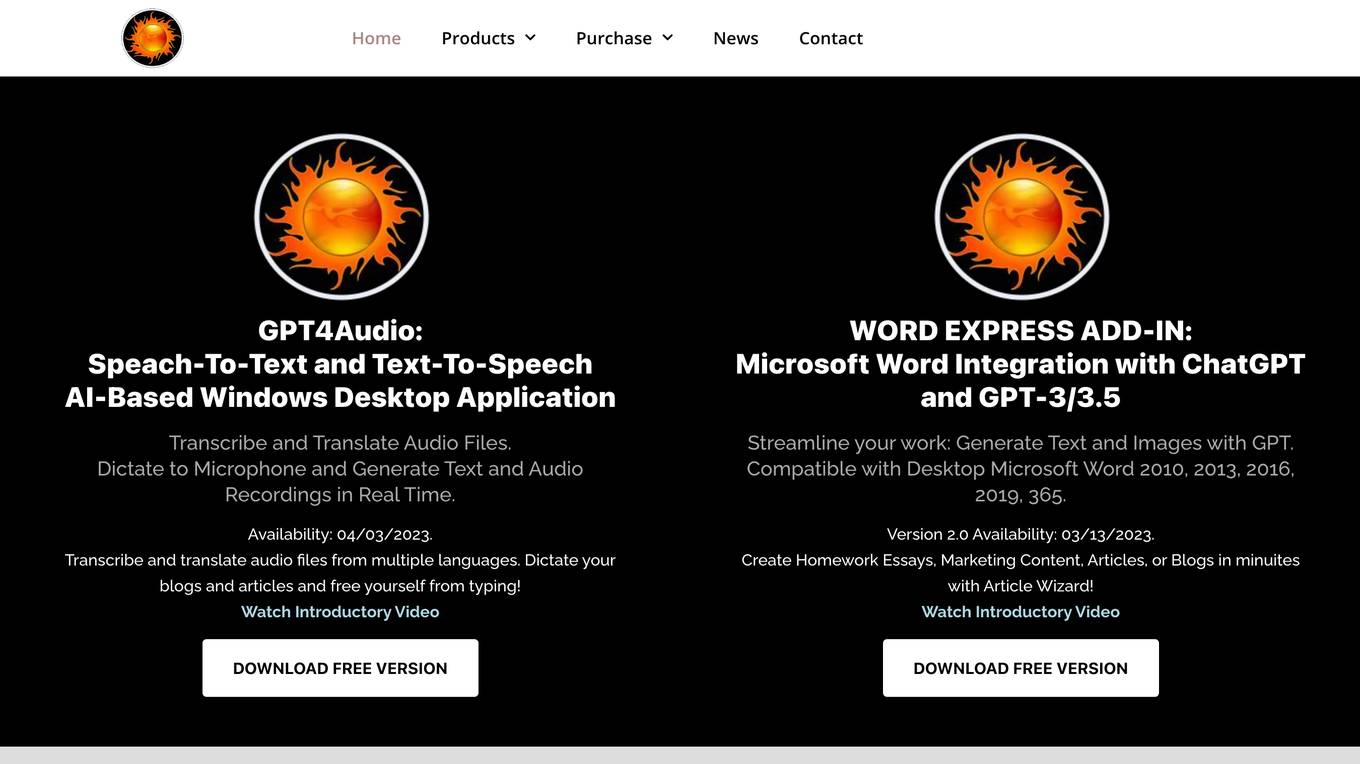
GPT4Audio
GPT4Audio is an AI-based desktop application that offers speech-to-text and text-to-speech capabilities. It allows users to transcribe and translate audio files from multiple languages, as well as dictate text and generate audio recordings in real time. The application also includes an Article Wizard feature that can help users create homework essays, marketing content, articles, or blogs quickly and easily.
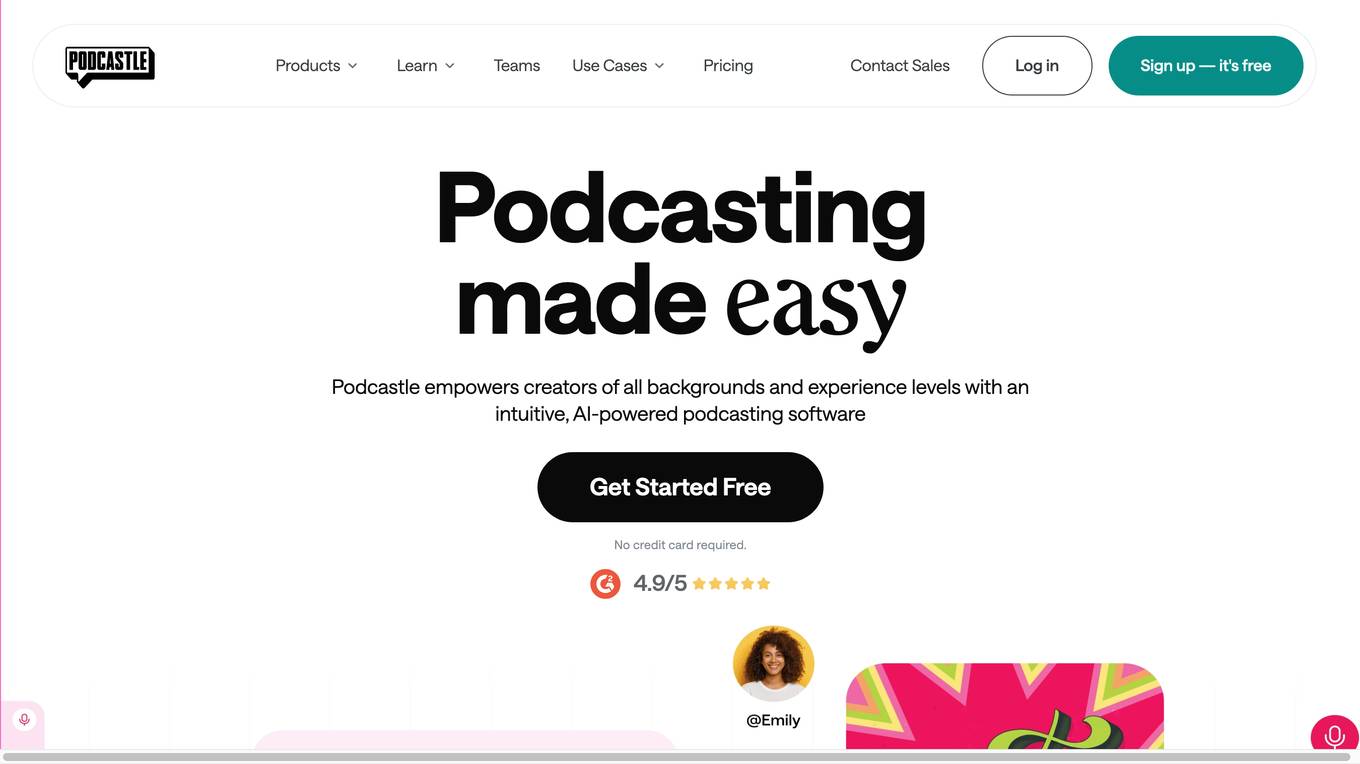
Podcastle
Podcastle is an all-in-one podcasting software that empowers creators of all backgrounds and experience levels with an intuitive, AI-powered platform. It offers a wide range of features, including a recording studio, audio editor, video editor, AI-generated voices, and hosting hub, making it easy to create, edit, and publish high-quality podcasts and videos. Podcastle is designed to be user-friendly and accessible, with no prior experience or technical expertise required.
Transcriptmate
Transcriptmate is an AI-powered audio to text transcription tool that offers automatic transcription with high accuracy. Users can easily convert audio files to text in just 2 clicks, with the option to add features like diarization and AI content crafting. The tool supports multiple languages, provides transcriptions in various formats, and ensures safe payments. Transcriptmate is recommended by customers for its efficiency, accuracy, and user-friendly interface.
WhisperUI
WhisperUI is an affordable Speech to Text application powered by OpenAI Whisper. It allows users to easily convert audio files into text and SRT files with high accuracy. The application is trusted by members of leading organizations and universities. Users can upload various audio file formats and benefit from premium features such as uploading multiple files at once and unlimited daily file uploads. WhisperUI supports multiple languages and is known for its robustness in transcribing speech in the presence of accents, background noise, and technical language.
SpeechGen.io
SpeechGen.io is a realistic text-to-speech converter and AI voice generator that allows users to convert text into speech using cutting-edge AI voices with an American English accent. With SpeechGen.io, users can create realistic voiceovers for videos, e-learning materials, advertising, public announcements, podcasts, mobile apps, presentations, and more. The platform offers a wide range of features, including the ability to download converted audio files in MP3, WAV, and OGG formats, support for long texts, commercial use of generated audio, multi-voice editing, custom voice settings, SSML support, and more. SpeechGen.io is accessible in any browser and offers an intuitive interface suitable for beginners. The platform also provides powerful support and is compatible with various editing programs.
TTSMaker
TTSMaker is a free online text-to-speech tool that allows users to convert text into natural-sounding speech. It supports multiple languages and voices, and the resulting audio files can be downloaded for free and used for commercial purposes. TTSMaker is a valuable tool for creating audiobooks, dubbing videos, and other projects that require high-quality voiceovers.
0 - Open Source AI Tools
20 - OpenAI Gpts
MUSIC + AI = MUSI.CAI
MUSIC + AI: Your key to original AI music creation. Create hits, explore genres, and tap into global trends. The ultimate tool for artists and producers.


ReaperGPT
Expert for the Reaper DAW with extensive knowledge on Reapack Packages, ReaScript, EEL, Lua, Python, general commands, and audio workflows.

Transcript GPT
Give me an audio transcript and I'll give you summarization, insights and actionable plan.
Mike Russell
Virtual Mike Russell from Music Radio Creative. Ask me your audio, podcasting and AI questions!

JollyDays: Your Festive Daily Adventure
Experience daily Christmas joy! Fun coloring, crafts, recipes, cultural insights with audio guides, and curated videos - perfect for festive creativity with your loved ones!
Able-Nature's Echo.
Guides users through beautiful landscapes with spatial audio for immersion.
ArtGPT
Doing art design and research, including fine arts, audio arts and video arts, designed by Prof. Dr. Fred Y. Ye (Ying Ye)


Ableton Live Mentor
Your personal Ableton Live mentor. Ask me anything about using Live for music production or live performance.
