Best AI tools for< Convert To Audiobook >
20 - AI tool Sites
Myreader AI
Myreader AI is an AI-powered reading assistant that allows users to upload any PDF, EPUB, document, article, or YouTube link. Users can ask questions, receive instant answers, jump to specific pages, convert content to audiobooks, and more. The application leverages AI technology to save users time by summarizing and extracting key information from various types of content, making it easier for users to consume and interact with information. Myreader AI offers cloud storage, affordable pricing plans, accurate citations, text-to-speech functionality, and supports multiple languages.
AnyToSpeech
AnyToSpeech is an AI text-to-speech and PDF to Audiobook solution that offers a clean and simple way to convert text, PDFs, documents, scans, and images to speech. It provides a variety of realistic voices in multiple languages for users to choose from. The platform also allows users to convert URLs to speech and offers a library to save and access their generated audio files at any time.
Authors' Voice
Authors' Voice is a cutting-edge AI tool designed to convert text-based books into high-quality audiobooks efficiently and quickly. The platform utilizes state-of-the-art AI-based text-to-speech technology to provide clear and natural-sounding narration with varied pacing and inflection. Authors' Voice aims to cater to content creators, independent authors, and publishers by offering affordable and profitable solutions to tap into the fast-growing audiobook market.
Voice AI Note
Voice AI Note is a web-based application that allows users to quickly and easily create voice notes using advanced AI. With Voice AI Note, you can create voice notes that are fluent, accurate, and sound natural. The application is easy to use and requires no prior experience with AI or voice recording. Simply enter the text you want to convert to speech, and Voice AI Note will do the rest.
TTS Generator AI
TTS Generator AI is a free online text-to-speech tool that leverages cutting-edge AI technology to convert written text into high-quality, natural-sounding audio. This tool is invaluable for a variety of users, including students who need auditory learning materials, researchers who want to listen to long documents, and professionals seeking to make their written content more accessible. One of the standout features of TTS Tool is its ability to support a range of text formats, from simple text files to complex PDFs, making it incredibly versatile.
TEXTTOSPEECH.IM
TEXTTOSPEECH.IM is an advanced text to speech tool that utilizes artificial intelligence to convert text to lifelike audio. Users can easily generate and download high-quality speech in multiple languages and voice styles. The tool supports enhanced accessibility, cost-effective content creation, a wide range of voices, convenient offline use, high accuracy in speech synthesis, and cross-device compatibility for maximum flexibility.
ElevenLabs
ElevenLabs is a text-to-speech (TTS) platform that uses artificial intelligence (AI) to generate realistic human-like voices. With ElevenLabs, you can convert any text into high-quality spoken audio in over 29 languages and 120 voices. The platform is easy to use and offers a variety of features, including the ability to adjust the voice's pitch, speed, and volume. You can also use ElevenLabs to create custom voices and clone your own voice. ElevenLabs is a powerful tool for content creators, businesses, and anyone who wants to create realistic spoken audio.
TTSMaker
TTSMaker is a free online text-to-speech tool that allows users to convert text into natural-sounding speech. It supports multiple languages and voices, and the resulting audio files can be downloaded for free and used for commercial purposes. TTSMaker is a valuable tool for creating audiobooks, dubbing videos, and other projects that require high-quality voiceovers.
BeyondWords
BeyondWords is a text-to-speech (TTS) platform that enables users to convert written text into natural-sounding speech. With advanced AI algorithms, BeyondWords provides a wide range of voices, languages, and customization options to create realistic and engaging audio content. The platform is designed to be user-friendly and accessible, making it suitable for various applications, including e-learning, audiobooks, podcasts, and marketing materials.
Beepbooply
Beepbooply is a text-to-speech tool that uses artificial intelligence to generate realistic and natural-sounding speech. With over 900 voices to choose from, you can create audio content for any purpose, including videos, podcasts, and customer service. Beepbooply is easy to use and affordable, making it a great option for anyone who needs to create high-quality audio content.
PlayAI
PlayAI is a leading AI voice generator and text-to-speech platform that offers a wide range of features to create high-quality audio content. With over 206 natural-sounding voices in 30+ languages, users can generate multi-speaker AI voices indistinguishable from humans. The platform allows users to enhance audio with speech styles, pronunciations, and SSML tags, making it ideal for audiobooks, YouTube videos, podcasts, and more. PlayAI's AI voice generator works by converting written text into natural-sounding speech through advanced text-to-speech technology, with real-time conversion and customizability options. The platform also supports voice cloning, API integration, and industry-leading AI voice products for various applications.
ElevenLabs
ElevenLabs is an AI voice generator and text-to-speech application that allows users to convert text into natural-sounding AI voices in various languages. The platform offers high-quality spoken audio with human intonation and inflections, suitable for video creators, developers, and businesses. Users can create lifelike voices for videos, gaming, audiobooks, chatbots, and more. ElevenLabs supports 29 languages and diverse accents, providing advanced AI text-to-speech technology for generating audio content.
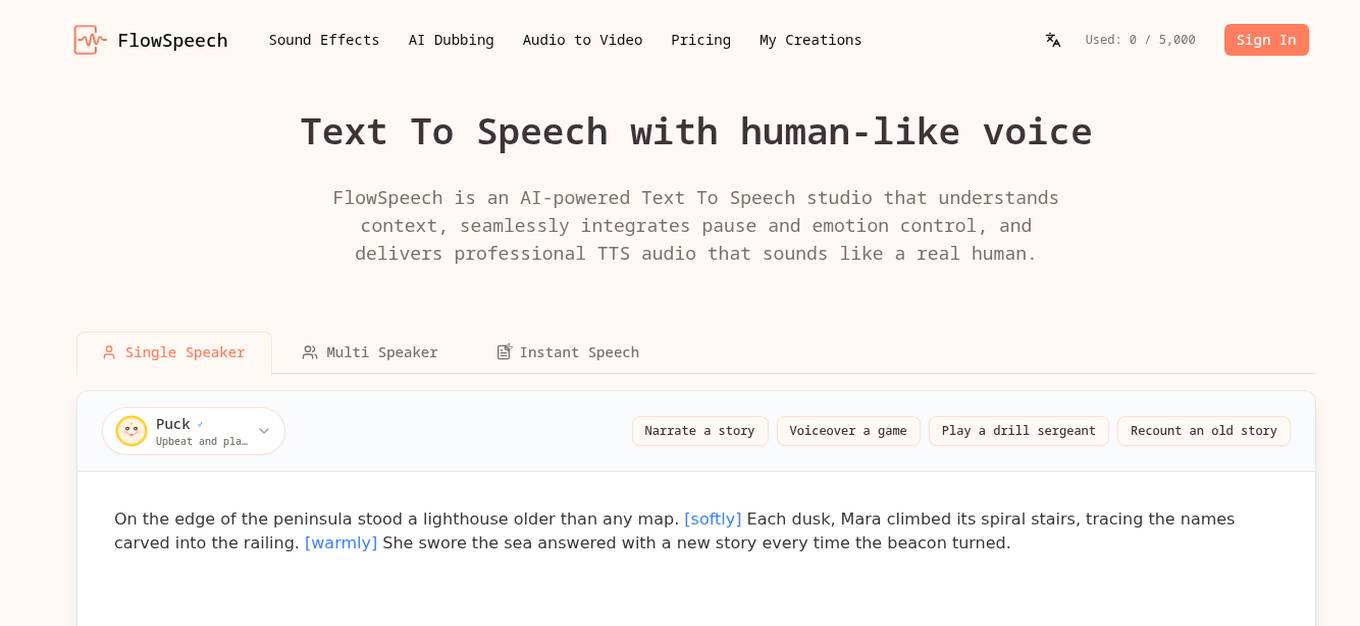
FlowSpeech
FlowSpeech is an AI-powered Text To Speech studio that offers lifelike human voices, emotion and pause control, and seamless multi-speaker casting for professional audio generation. It understands context, integrates pause and emotion control, and delivers TTS audio that sounds like a real human. The AI-driven engine analyzes sentiment, timing, and nuance of scripts, allowing for precise emotion delivery. Users can add custom emotions and accents, control pauses, and select from 30 distinct voices across different styles. With support for 70+ languages and the ability to process up to 200k characters per render, FlowSpeech is a versatile tool for content creators, marketers, and educators.
SpeechEasy
SpeechEasy is a high-quality text-to-speech tool that harnesses the power of AI and machine learning to convert text into natural-sounding audio. With SpeechEasy, you can generate studio-grade synthetic voices that are easy to understand and consume, making it perfect for on-the-go listening, home or office use, and e-learning content.
Speechki
Speechki is an AI Realistic Voice Generator and Text-to-Speech Solution offering over 1,100 voices in 80+ languages. It provides a user-friendly platform for converting text into engaging audio with AI-powered voices. The application is designed to cater to various needs such as audiobook production, content creation, podcasting, and more. With features like real-time proof-listening, chapter-like formatting, streamlined role management, precision pause control, and nuanced speech control, Speechki aims to enhance the user experience and deliver lifelike audio output. The tool also offers global reach with multicast and multilanguage support, making it suitable for a diverse audience.
Create AI Voiceovers
Create AI Voiceovers is an online text-to-speech generator that allows users to convert text into realistic-sounding AI voices. With over 530 AI voices available in 220+ languages and dialects, users can create voiceovers for various purposes, including marketing, eLearning, explainer videos, and animations. The platform offers a range of features, including the ability to adjust voice attributes such as pitch, emphasis, and speed, as well as add background music and sound effects. Create AI Voiceovers also provides a library of pre-recorded sound effects and music that users can incorporate into their voiceovers.
Lovevoice AI Voice Generator
Lovevoice is an AI Voice Generator that transforms text into natural-sounding speech using AI technology. It offers over 70 languages and nearly 300 AI voices, customizable voice settings, file transcription support, and MP3 download capabilities. Lovevoice's advanced AI ensures generated voiceovers are human-like, making it ideal for various applications such as videos, podcasts, audiobooks, and personalized audio messages. Users can quickly convert text into high-quality audio files with multilingual global support.
Sound of Text
Sound of Text is a free online text-to-speech converter that uses AI technology to convert written text into spoken words. It supports over 840 different voices in more than 135 languages, and allows users to download the resulting audio files in a variety of formats. Sound of Text is easy to use and can be used for a variety of purposes, such as creating audiobooks, podcasts, and presentations.
Audyo
Audyo is a text-to-speech tool that allows users to create realistic-sounding audio from text. With over 100 voices to choose from, users can create audio in a variety of languages and accents. Audyo is easy to use, simply type in your text and select a voice. You can then download your audio file or embed it on your website or blog. Audyo is a great tool for creating voiceovers for videos, podcasts, audiobooks, and more.
VoiceGen
VoiceGen is an AI audio platform that enables users to create realistic speech using the best technology from leading providers like OpenAI, Google, AWS, and Azure. It offers natural, high-quality voices with support for multiple languages and unrestricted commercial use. VoiceGen prioritizes simplicity, transparency, and innovation, providing an accessible and affordable solution for voice generation needs. The platform ensures security and privacy of user data, offering a pay-as-you-go pricing model with fair and transparent costs.
0 - Open Source AI Tools
20 - OpenAI Gpts

Photo Multiverse
Upload your photo to create an AI persona, then change 🏞️ background, convert to ✏️ cartoon, or edit character styles. Try with selfies, items or pet images!
Automated Knowledge Distillation
For strategic knowledge distillation, upload the document you need to analyze and use !start. ENSURE the uploaded file shows DOCUMENT and NOT PDF. This workflow requires leveraging RAG to operate. Only a small amount of PDFs are supported, convert to txt or doc. For timeout, refresh & !continue
JSON Outputter
Takes all input into consideration and creates a JSON-appropriate response. Also useful for creating templates.
Text to DB Schema
Convert application descriptions to consumable DB schemas or create-table SQL statements
Screenshot To Code GPT
Upload a screenshot of a website and convert it to clean HTML/Tailwind/JS code.

Table to JSON
我們經常在看 REST API 參考文件,文件中呈現 Request/Response 參數通常都是用表格的形式,開發人員都要手動轉換成 JSON 結構,有點小麻煩,但透過這個 GPT 只要上傳截圖就可以自動產生 JSON 範例與 JSON Schema 結構。
Screen Shot to Code
This simple app converts a screenshot to code (HTML/Tailwind CSS, or React or Vue or Bootstrap). Upload your image, provide any additional instructions and say "Make it real!"
Text Playground
Best AI-powered Text Playground!! I am your go-to assistant for text-to other media conversions. Flawelessly convert any text to voice, image, or video!! I am here to help. Ask me anything!!
LaTeX Picture & Document Transcriber
Convert into usable LaTeX code any pictures of your handwritten notes, documents in any format. Start by uploading what you need to convert.
Make your words bad
Hi! I'll convert your words into poor language. first, try to type "hamburger"


Türkçeleştir
Converts Turkish text in English script to Turkish characters and fixes grammar.