Best AI tools for< Convert Pdf To Image >
20 - AI tool Sites
AnyToSpeech
AnyToSpeech is an AI text-to-speech and PDF to Audiobook solution that offers a clean and simple way to convert text, PDFs, documents, scans, and images to speech. It provides a variety of realistic voices in multiple languages for users to choose from. The platform also allows users to convert URLs to speech and offers a library to save and access their generated audio files at any time.
LightPDF
LightPDF is an AI-powered, free online PDF editor, converter, and reader. It offers a wide range of PDF tools, including the ability to convert PDFs to and from other formats, edit PDFs, add watermarks, split and merge PDFs, rotate PDFs, annotate PDFs, optimize PDFs, compress PDFs, perform OCR on PDFs, and protect PDFs. LightPDF also offers a variety of AI-powered features, such as an AI chatbot that can answer questions about documents and an AI-powered OCR engine that can convert scanned PDFs and images to text.
PDF.ai
PDF.ai is a powerful AI-powered tool that allows you to chat with your PDF documents. With PDF.ai, you can ask questions about your PDF, get summaries, translate text, and more. PDF.ai is the perfect tool for anyone who works with PDFs on a regular basis.
SlidesPilot
SlidesPilot is an AI-powered presentation tool that helps users create, convert, and edit PowerPoint presentations quickly and easily. With its advanced AI capabilities, SlidesPilot can generate informative and professional presentations from scratch, add relevant images, convert PDF and Word documents to PPT, and provide real-time assistance through its built-in AI co-pilot. The tool offers a wide range of features, including customizable templates, automatic slide creation, text rewriting, grammar correction, and image generation. SlidesPilot is designed for both business professionals and educators, and it supports multiple languages, making it accessible to users worldwide.
Scanner Go
Scanner Go is a free PDF tool that offers easy-to-use features for high-quality scanning and conversion of various documents into PDF format. With powerful OCR technology, it allows users to extract text from PDFs and images, making it convenient to edit and share documents. The tool also provides options for managing, editing, printing, and sharing documents, enhancing productivity. Additionally, Scanner Go offers a range of popular tools for converting, optimizing, and securing PDF files, catering to diverse user needs.

PDF Translator & Editor
PDF Translator & Editor is a powerful AI-driven tool that offers multilingual document translation with format and layout preservation. It supports translating native PDFs, scanned PDFs, Word, Excel, PowerPoint, and image files to 136 languages. The tool also provides versatile PDF conversion and editing capabilities, allowing users to convert PDFs to images and vice versa, as well as edit PDF text, scan to PDF, and split PDF files. With AI technology from Google and Microsoft, it ensures accurate translations and supports automatic language detection. Trusted by users worldwide, PDF Translator & Editor offers unlimited access with no file size or page limits, making it a convenient solution for global communication.
TinyWow
TinyWow is a free online tool that offers a variety of PDF, video, image, and other tools to make your life easier. With TinyWow, you can easily edit PDFs, convert files, compress images, and more. All of our tools are free to use, with no sign-up required.
TheToolBus.ai
TheToolBus.ai is an AI-powered platform that offers a wide range of free digital tools to simplify various tasks. From age calculation to file conversion, image editing, text formatting, and more, TheToolBus.ai provides efficient solutions for everyday needs. Users can access tools like PDF converters, image background remover, audio to text converter, and even AI test generators. The platform aims to enhance productivity and efficiency by providing user-friendly tools for different digital tasks.
Zenpai
Zenpai is an AI file operations software designed to automate routine tasks and enhance productivity by performing repetitive and boring tasks using natural language prompts. It allows users to convert images to pdf, png files to jpg, resize images, compress multiple images and pdfs, all automatically. Zenpai caters to a wide range of users including developers, freelancers, and students, offering different pricing plans to suit varying needs. The company behind Zenpai is committed to continuous improvement and welcomes feedback to enhance the user experience.
Beebzi.AI
Beebzi.AI is an all-in-one AI content creation platform that offers a wide array of tools for generating various types of content such as articles, blogs, emails, images, voiceovers, and more. The platform utilizes advanced AI technology and behavioral science to empower businesses and individuals in their marketing and sales endeavors. With features like AI Article Wizard, AI Room Designer, AI Landing Page Generator, and AI Code Generation, Beebzi.AI revolutionizes content creation by providing customizable templates, multiple language support, and real-time data insights. The platform also offers various subscription plans tailored for individual entrepreneurs, teams, and businesses, with flexible pricing models based on word count allocations. Beebzi.AI aims to streamline content creation processes, enhance productivity, and drive organic traffic through SEO-optimized content.
ColoringBook.AI
ColoringBook.AI is a free AI coloring pages generator that allows users to upload photos or enter text to create personalized coloring pages. With powerful generative AI tools, users can convert any picture or text into coloring pages instantly. The website offers a wide variety of free printable coloring pages in PDF and PNG formats for download, along with AI tools for image-to-image and text-to-image generation.
HiPDF
HiPDF is a free online PDF solution that offers a wide range of tools for editing, converting, compressing, and organizing PDFs. It also includes AI-powered tools such as Chat with PDF and AI Detector. With HiPDF, you can easily edit PDFs in your browser, convert PDFs to and from other formats, compress PDFs to reduce their size, and merge, split, and extract images from PDFs. You can also protect your PDFs with passwords and redact sensitive information. HiPDF is a convenient and easy-to-use tool that can help you with all your PDF needs.

**万兴科技**
**万兴科技** is an AI-powered tool that helps users create and edit PDF documents. It offers a wide range of features, including the ability to convert PDFs to other formats, edit text and images, and add annotations. **万兴科技** is a valuable tool for anyone who needs to work with PDFs on a regular basis.
Vectorizer.AI
Vectorizer.AI is an online tool that allows users to convert PNG and JPG images to SVG vectors quickly and easily using artificial intelligence. The application utilizes deep learning networks and classical algorithms to analyze, process, and convert images from pixels to geometric shapes. With features such as full shape fitting, curve support, clean corners, and high performance, Vectorizer.AI provides users with high-quality vector images that can be scaled to any resolution without losing clarity. The tool supports various output formats including SVG, PDF, EPS, DXF, and PNG, making it versatile for different design needs.
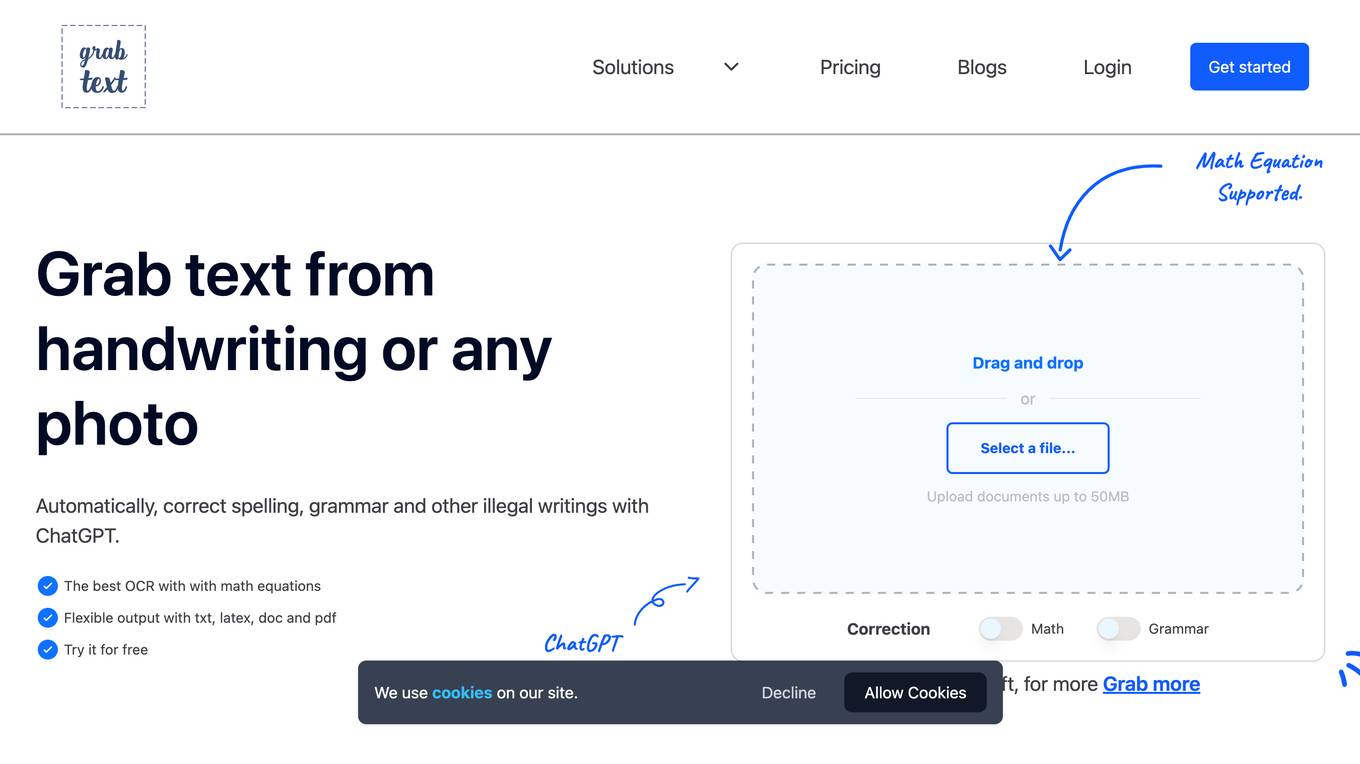
GrabText
GrabText is an online OCR tool that allows users to convert handwritten or printed text from photos, graphics, or documents into editable text. It uses ChatGPT to automatically correct spelling, grammar, and other illegal writings. The tool also supports math equations and offers flexible output options such as txt, latex, doc, and pdf.
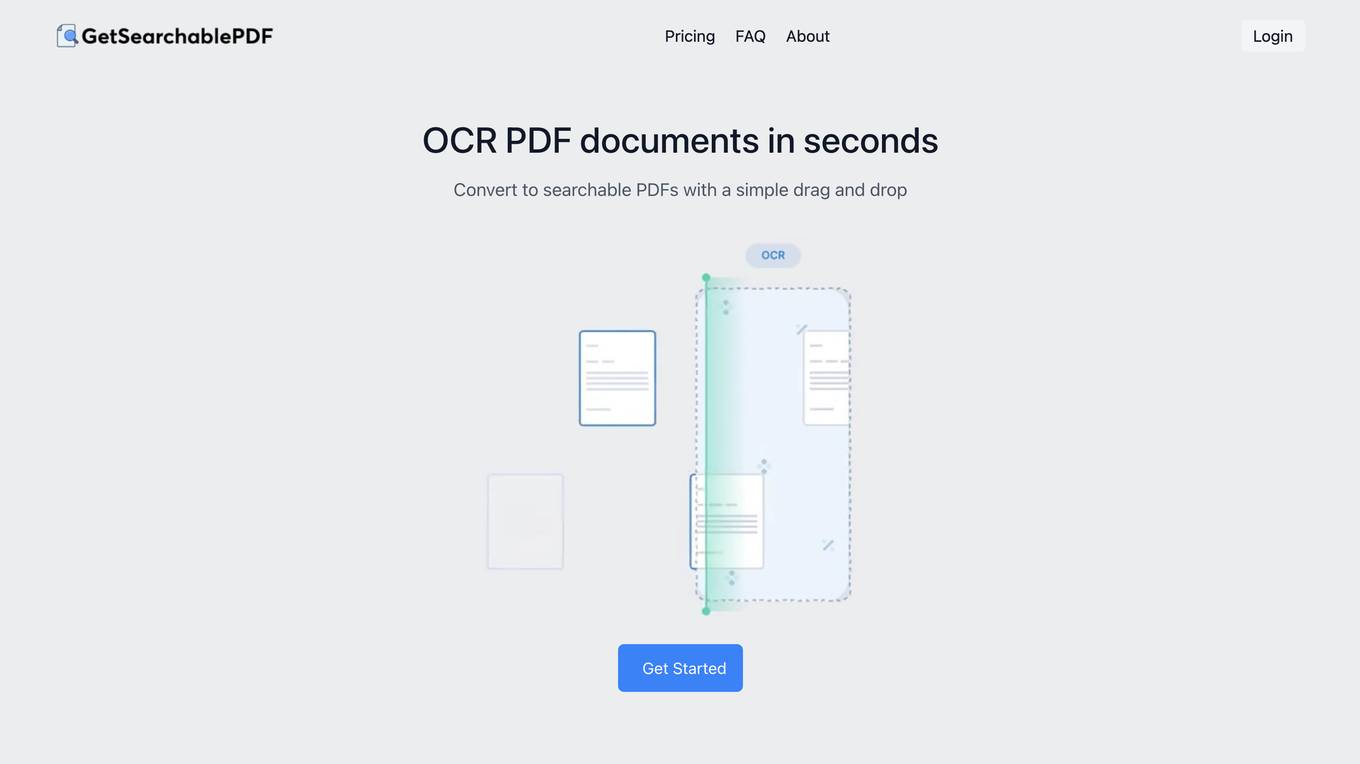
GetSearchablePDF
GetSearchablePDF is an online tool that allows users to convert scanned or image-based PDF documents into searchable PDFs. With its advanced OCR (Optical Character Recognition) technology, the tool accurately extracts text from images, making the resulting PDFs easy to search, edit, and share. The process is simple and straightforward: users simply connect their Dropbox or OneDrive account, drag and drop their PDF files into the designated folder, and the tool automatically converts them into searchable PDFs.
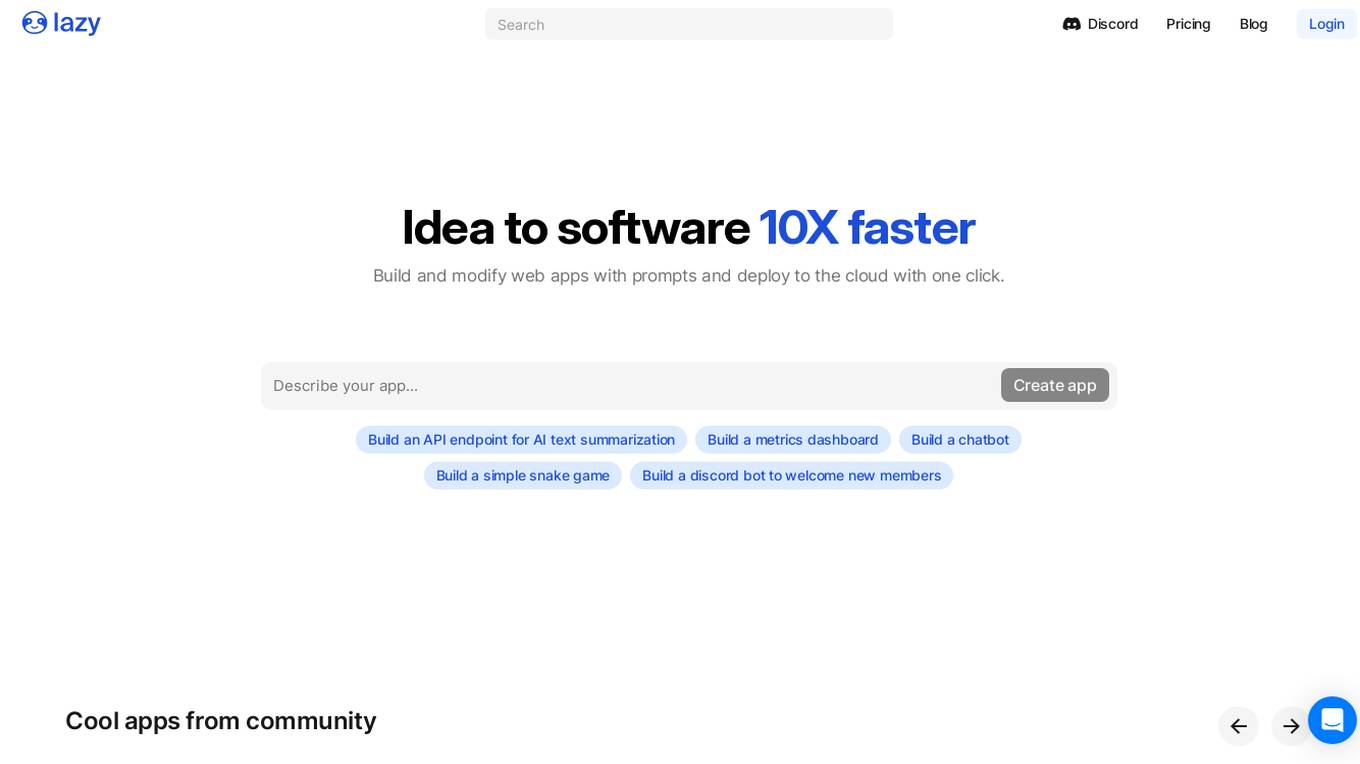
Lazy AI
Lazy AI is a platform that enables users to build full stack web applications 10 times faster by utilizing AI technology. Users can create and modify web apps with prompts and deploy them to the cloud with just one click. The platform offers a variety of features including AI Component Builder, eCommerce store creation, Crypto Arbitrage Scraper, Text to Speech Converter, Lazy Image to Video generation, PDF Chatbot, and more. Lazy AI aims to streamline the app development process and empower users to leverage AI for various tasks.
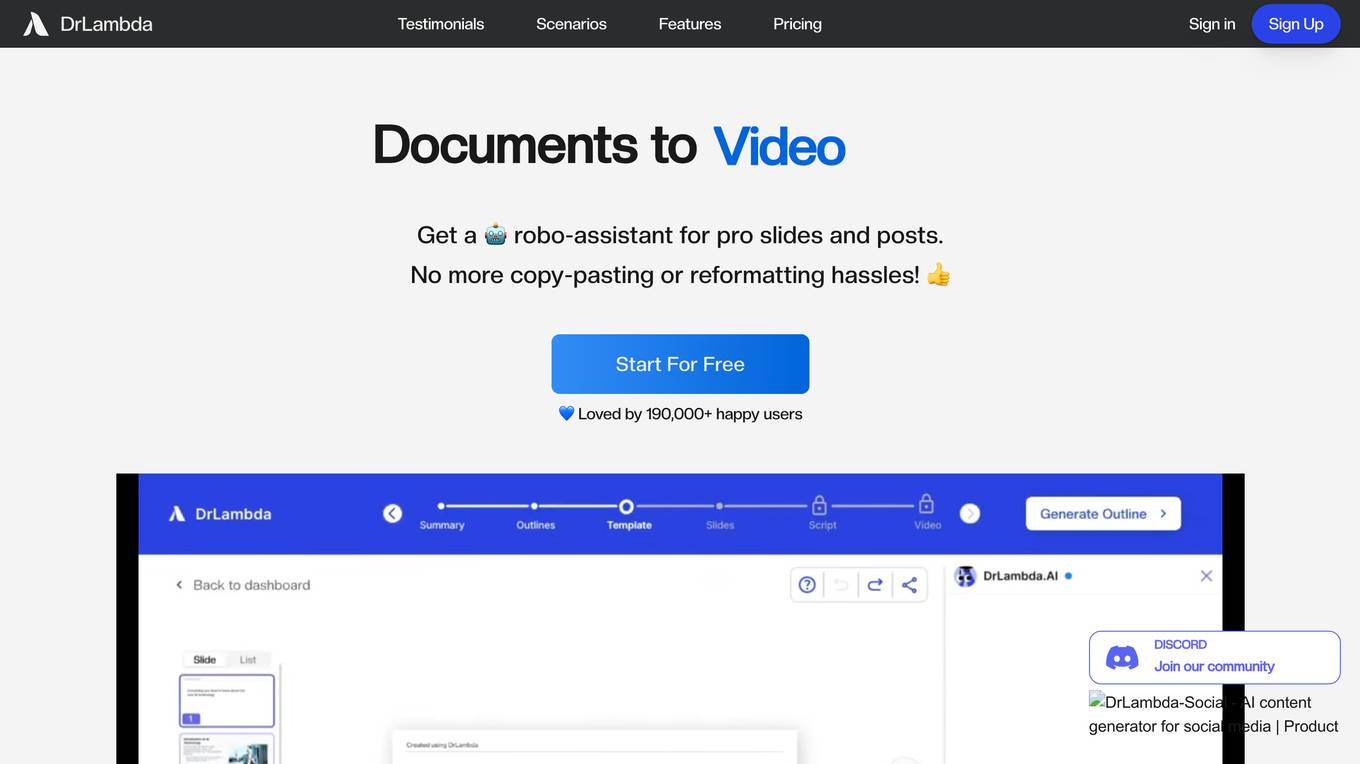
DrLambda
DrLambda is an AI-powered tool that helps users create professional-looking slides quickly and easily. With DrLambda, you can choose from a variety of templates and themes, and then add your own text, images, and videos. DrLambda will automatically format your slides and ensure that they look polished and professional.
Text to Handwriting
This is a free online tool that converts Text into an image or pdf that appears handwritten. This is the best Text to Handwriting converter available, and the best part is you can also upload your handwriting font file as well. Creating handwritten assignments is super easy with this utility, and you can download your handwritten assignment in pdf or image.

Kingshiper
Kingshiper is a versatile multimedia tool offering a wide range of audio, photo, and video editing solutions. It provides users with tools for screen recording, video editing, audio conversion, image compression, and more. With a focus on user-friendly interfaces and efficient processing, Kingshiper aims to enhance creativity and productivity in multimedia tasks. The platform also offers utilities for office tasks, system tools, data solutions, and video production, catering to diverse user needs across various domains.
0 - Open Source AI Tools
20 - OpenAI Gpts
LaTeX Picture & Document Transcriber
Convert into usable LaTeX code any pictures of your handwritten notes, documents in any format. Start by uploading what you need to convert.
Automated Knowledge Distillation
For strategic knowledge distillation, upload the document you need to analyze and use !start. ENSURE the uploaded file shows DOCUMENT and NOT PDF. This workflow requires leveraging RAG to operate. Only a small amount of PDFs are supported, convert to txt or doc. For timeout, refresh & !continue
PDF Ninja
I extract data and tables from PDFs to CSV, focusing on data privacy and precision.

CondenserPRO: 1-page condensed papers
Convert 20-page articles/ reports/ white-papers to a 1 pager with maximum information fidelity. Summaries so good, you'll never want to read the original first! Upload your PDF and say 'GO'.

Text to DB Schema
Convert application descriptions to consumable DB schemas or create-table SQL statements
Size Wizard
Find the right size clothes. I convert your measurements into sizes of different standards. Say “hello” in your language to start.
Malevich GPT - Emoji to Art 🤯 -> 🎨
Convert emotions and feelings to evocative abstract art. Share you daily mood with text or emoji and I help you to create masterpiece .