Best AI tools for< Convert Image Format >
20 - AI tool Sites
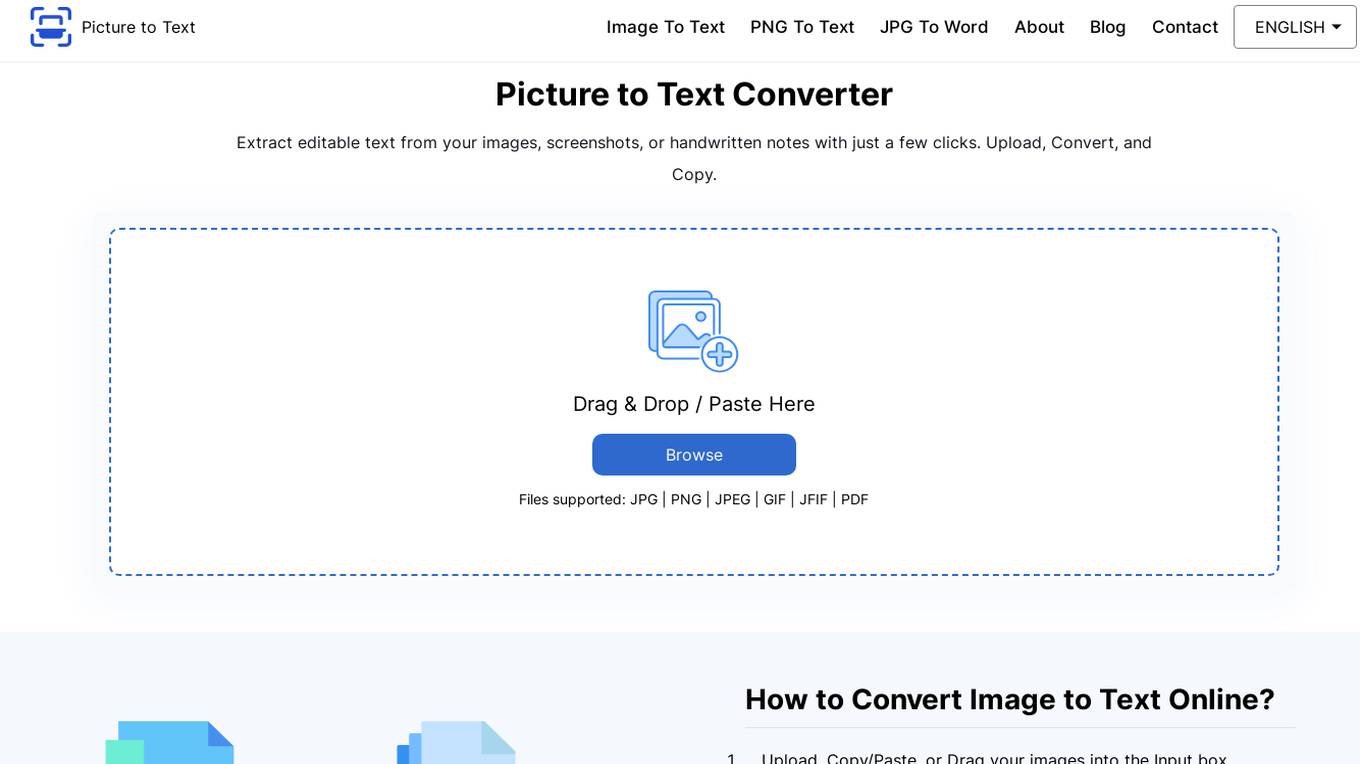
Picture to Text Converter
Picture to Text Converter is an online tool that uses Optical Character Recognition (OCR) technology to extract text from images. It can process various image formats like JPG, PNG, GIF, scanned documents (PDFs), and even photos taken with your phone's camera. The extracted text can be copied to the clipboard or downloaded as a TXT file. Picture to Text Converter is free to use and does not require any registration or installation. It is a convenient and efficient way to convert images into editable text.
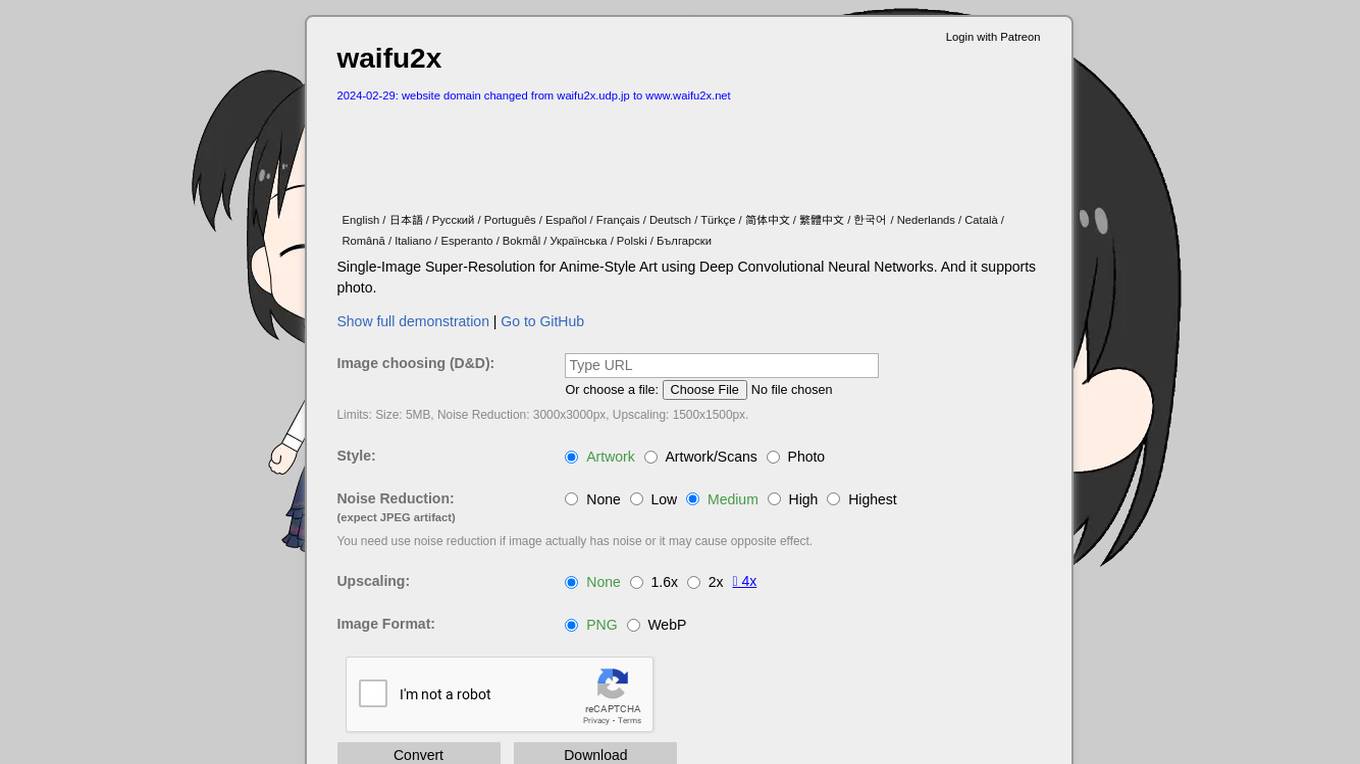
Waifu2x
Waifu2x is a website that offers Single-Image Super-Resolution for Anime-Style Art using Deep Convolutional Neural Networks. Users can enhance the quality of their images by upscaling and reducing noise. The site supports various languages and provides detailed instructions on image processing. It also offers options for noise reduction and upscaling, with limits on file size and dimensions. Additionally, users can choose different styles for their images and save them in different formats like PNG and WebP.
SVGMaker
SVGMaker is an AI-powered text to SVG generator, editor, and converter that allows users to create stunning vector graphics effortlessly. With advanced AI models, users can generate, convert, and edit SVGs using natural language commands, making it ideal for designers, creators, and digital sellers worldwide. SVGMaker offers powerful features such as AI-Powered SVG Studio, Editor Beta, Share & Collaboration, Image Format Converter, AI Prompt Enhancement, SVG Styles customization, API integration, and more. Users can effortlessly create visuals for website design, illustrations, presentations, icon design, logos, merchandise designs, raster to SVG conversion, SVG editing, and enhancement. SVGMaker is trusted by 80,000+ creators and designers globally for its precision controls, modern interface, and high-quality vector outputs.
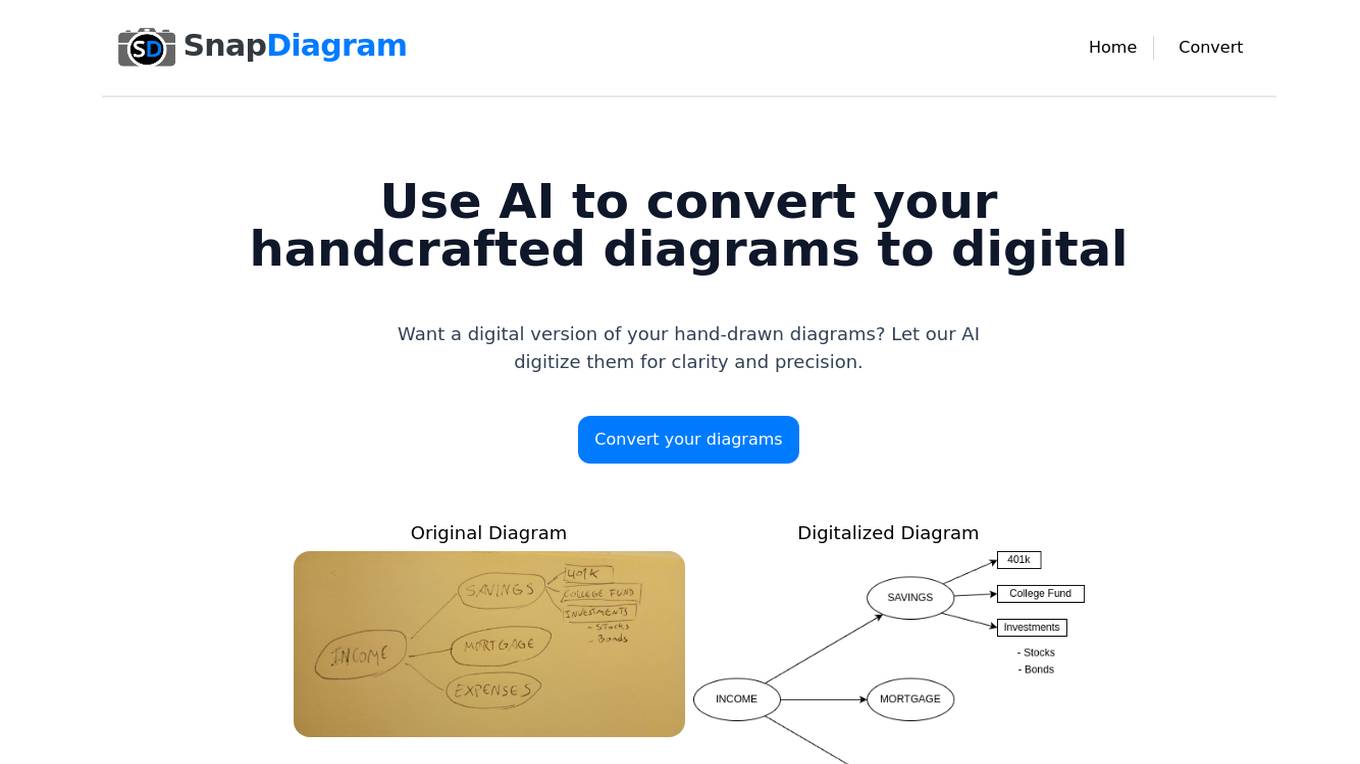
SnapDiagram
SnapDiagram is an AI tool that allows users to easily convert their hand-drawn diagrams into digital format. By leveraging artificial intelligence technology, SnapDiagram provides a convenient solution for individuals looking to digitize their sketches with clarity and precision. Users can watch a video demonstration to understand how the tool works and can receive their digital diagrams in various image formats, including PNG and JPG. Additionally, SnapDiagram offers the option to obtain an editable file of the digital diagram, making it versatile for different purposes. With a user-friendly interface and efficient AI capabilities, SnapDiagram simplifies the process of transforming handcrafted diagrams into digital assets.
SharkFoto
SharkFoto is an AI-powered online tool that offers a range of powerful and easy-to-use photo editing features. Users can remove image backgrounds, colorize black and white photos, enhance image quality, resize, crop, flip, rotate images, and more. The tool utilizes AI technology to automate and simplify the editing process, making it accessible to both professionals and amateurs. With over 100 million trained and processed images, SharkFoto boasts a 95% satisfaction rate from customers and an average customer rating of 4.5 out of 5.00.

PicNotes
PicNotes is a web-based image-to-text converter that can convert messy images into summaries, text, or explanations. It supports handwritten papers, medical reports, and other types of images. The tool is easy to use: simply upload an image and choose the desired output format. PicNotes will then process the image and return the results within seconds.
AI Image Translator
AI Image Translator is an advanced tool that utilizes AI-powered OCR technology to translate images while retaining original text formats. It supports over 130 languages and offers features such as format preservation, background restoration, multi-language translation, intelligent text placement, and high-quality image export. The tool is ideal for tasks like e-commerce product image translation, app and software screenshot translation, marketing and advertisement translation, technical document translation, and educational content translation.

Photes.io
Photes.io is a photo-to-notes application that utilizes AI technology to convert your photos into organized notes. It allows you to capture, convert, and store notes from various sources such as slides, meetups, classes, and whiteboards. The app offers features like easy integration with popular apps, tagging and categorizing notes for better organization, real-time sync across devices, secure and private data storage, and customizable templates for formatting notes.
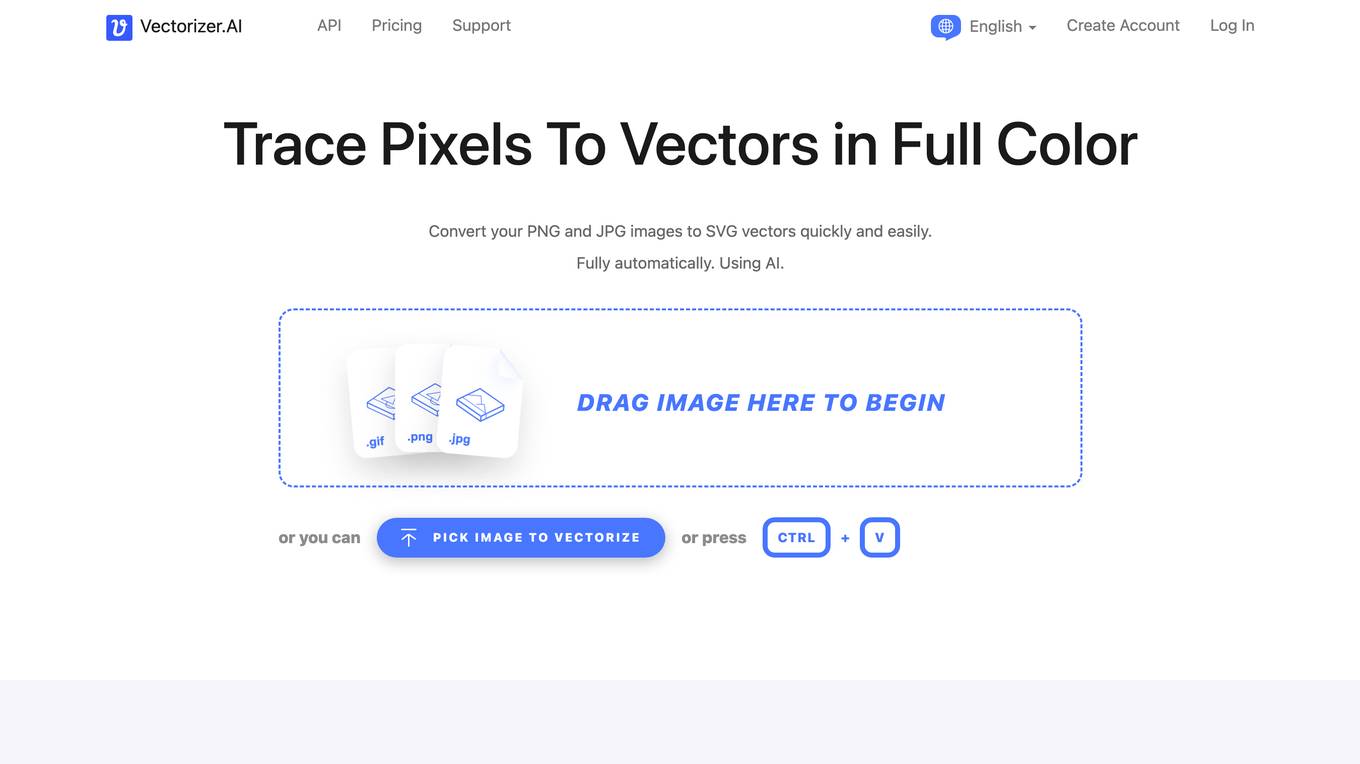
Vectorizer.AI
Vectorizer.AI is an online tool that allows users to convert PNG and JPG images to SVG vectors quickly and easily using AI technology. The application offers a fully automatic process that analyzes, processes, and converts images from pixels to geometric shapes. It provides a range of features such as full shape fitting, curve support, clean corners, symmetry modeling, and adaptive simplification. Vectorizer.AI supports various output formats including SVG, PDF, EPS, DXF, and PNG, and is designed to produce high-quality vector images suitable for printing, cutting, embroidering, and more.
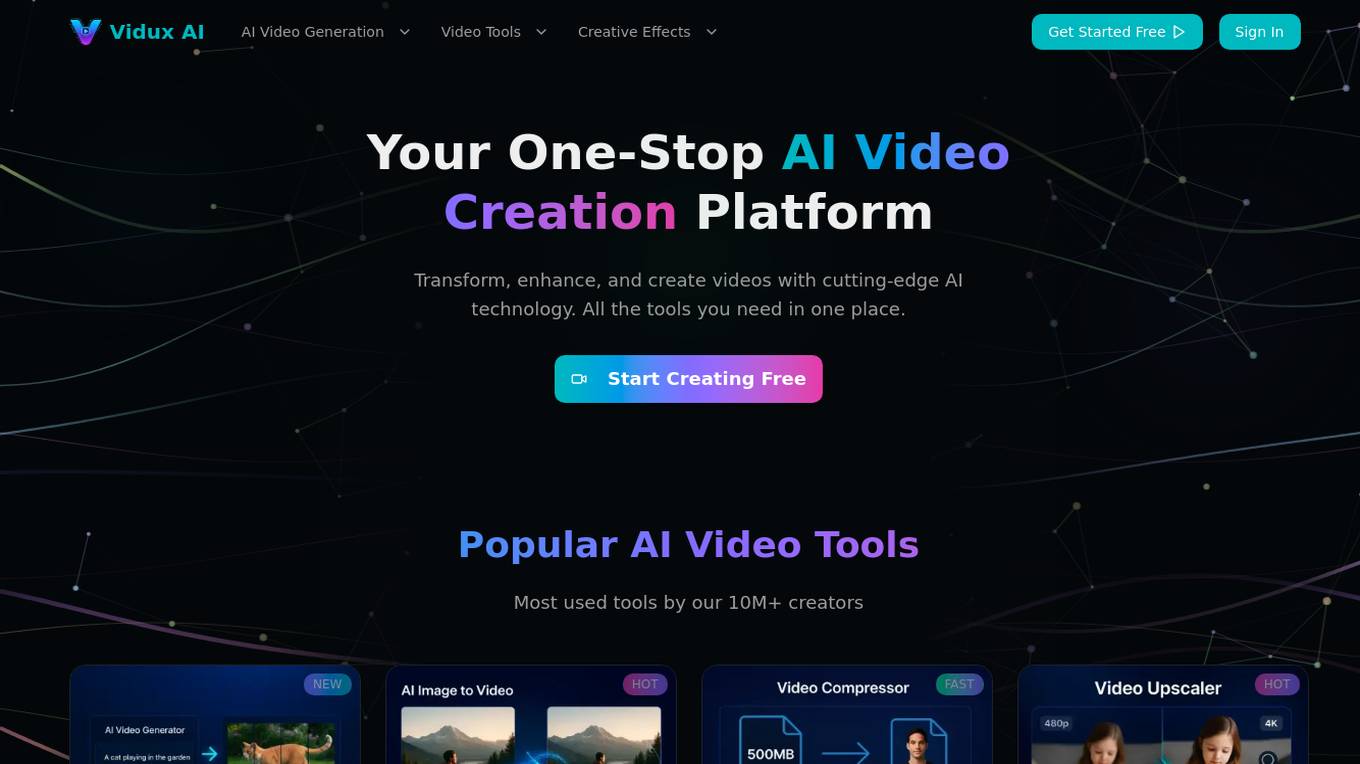
Vidux AI
Vidux AI is a professional AI video generation and processing platform that offers cutting-edge tools to transform, enhance, and create videos using advanced deep learning models. With features like AI video generation, image to video conversion, video compression, upscaling, and enhancement, Vidux AI provides a one-stop solution for all video creation needs. The platform caters to both individual creators and businesses, offering a wide range of tools and features to streamline the video production process.
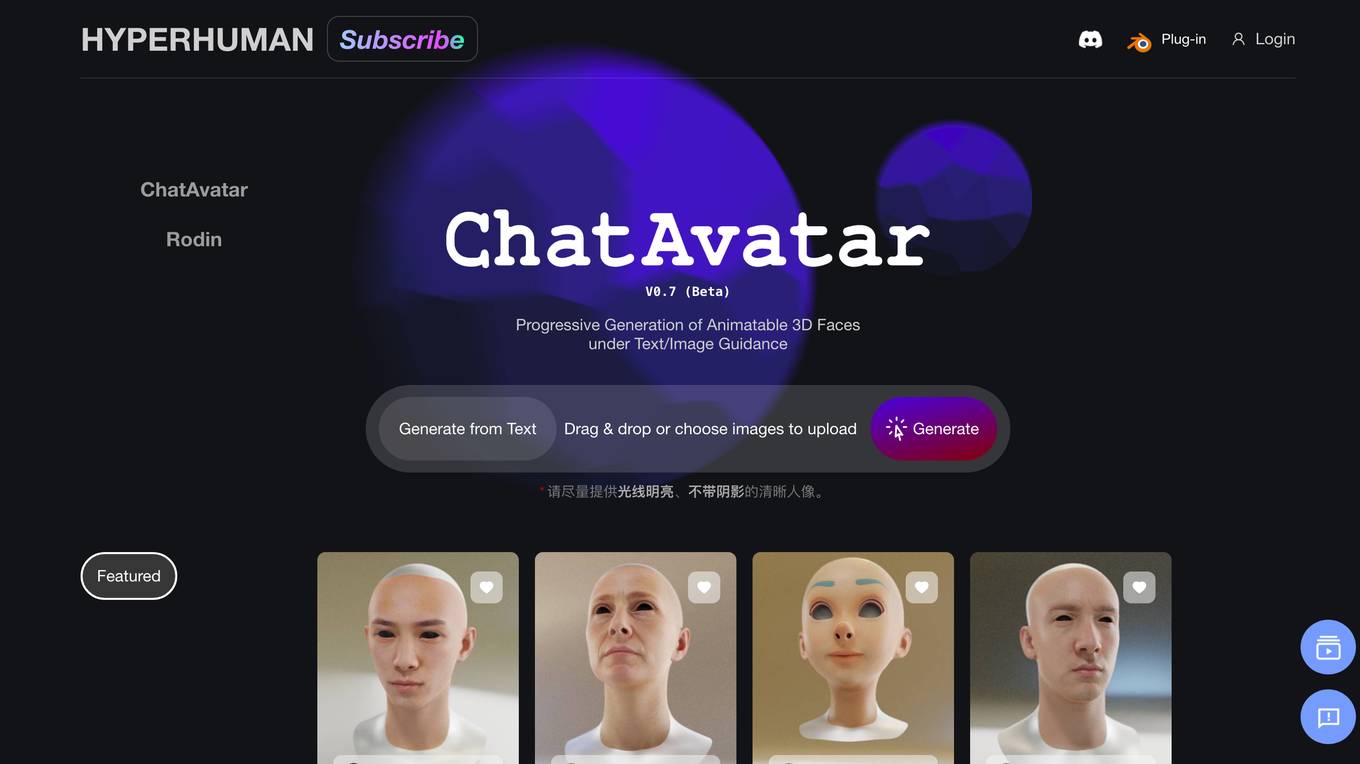
Rodin
Rodin is a free AI 3D model generator that allows users to effortlessly create 3D models from images. It offers various plans for creators, businesses, and educators, with features like image enhancement, style customization, texture generation, and API integration. Users can generate high-quality 3D assets, transform images into 3D cartoons, and create 3D avatars. Rodin supports multiple languages and provides tools for HDRI generation, mesh editing, and format conversion.
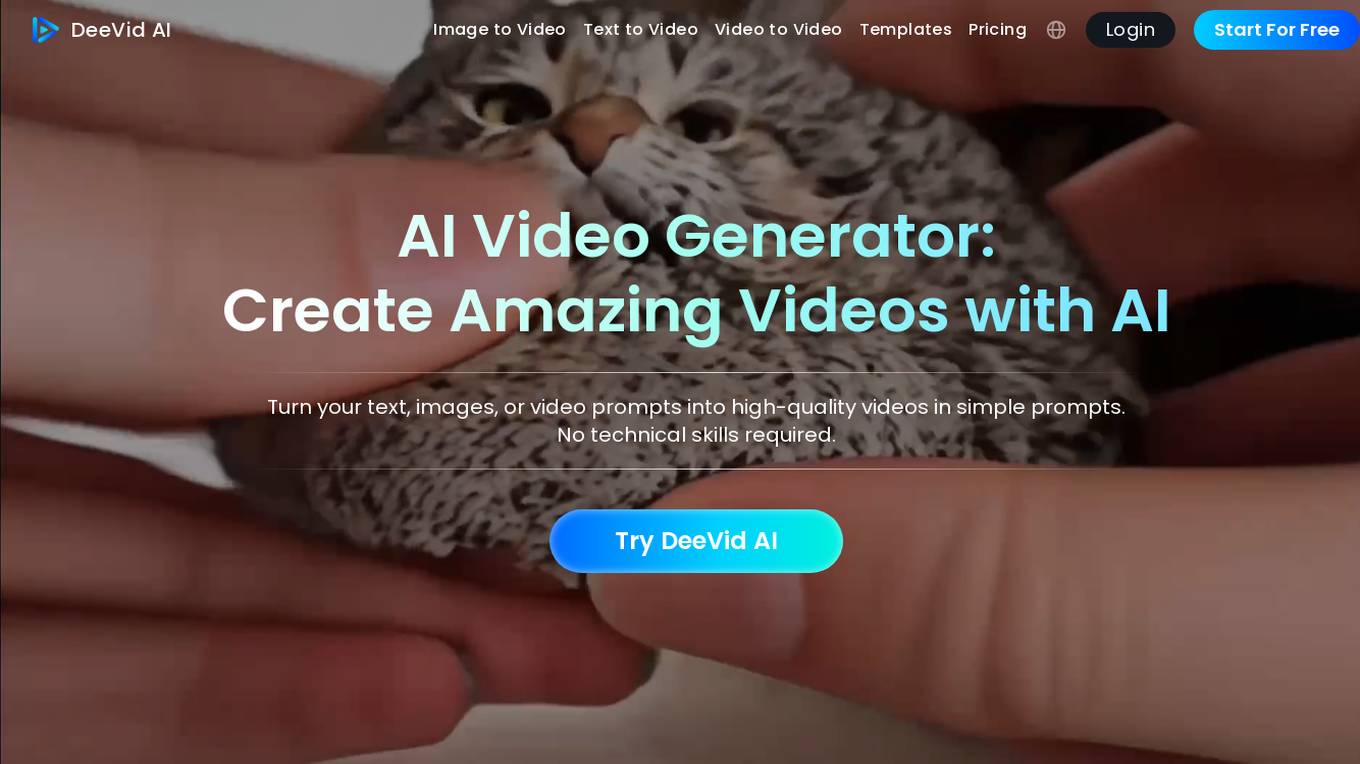
DeeVid AI Video Generator
DeeVid AI Video Generator is an innovative AI tool that allows users to create amazing videos effortlessly. It offers features like transforming text, images, and video prompts into high-quality videos, converting still images into animated video clips, and easily modifying existing videos into new styles. With user-friendly interface and advanced algorithms, DeeVid AI ensures fast video generation with high-quality output while prioritizing data privacy and safe content creation.
AIConvert
AIConvert is a web-based application that allows users to convert various types of files into different formats. It supports a wide range of file formats, including documents, images, videos, and audio files. AIConvert is easy to use and does not require any software installation. Users simply need to upload the file they want to convert and select the desired output format. AIConvert will then automatically convert the file and provide a download link.
AI Describe Picture
AI Describe Picture is a free online tool that offers image description services, image-to-text conversion, and code conversion. The AI-powered platform allows users to easily describe photos, convert images to detailed descriptions, extract text from images, and convert screenshots into HTML, CSS, or JavaScript code. It also provides content extraction in Markdown format and personalized content creation. With features like intelligent image recognition, single-click code copying, and efficient text extraction, AI Describe Picture aims to enhance users' productivity and creativity in image processing tasks.
ColoringBook.AI
ColoringBook.AI is a free AI coloring pages generator that allows users to upload photos or enter text to create personalized coloring pages. With powerful generative AI tools, users can convert any picture or text into coloring pages instantly. The website offers a wide variety of free printable coloring pages in PDF and PNG formats for download, along with AI tools for image-to-image and text-to-image generation.

PDF Translator & Editor
PDF Translator & Editor is a powerful AI-driven tool that offers multilingual document translation with format and layout preservation. It supports translating native PDFs, scanned PDFs, Word, Excel, PowerPoint, and image files to 136 languages. The tool also provides versatile PDF conversion and editing capabilities, allowing users to convert PDFs to images and vice versa, as well as edit PDF text, scan to PDF, and split PDF files. With AI technology from Google and Microsoft, it ensures accurate translations and supports automatic language detection. Trusted by users worldwide, PDF Translator & Editor offers unlimited access with no file size or page limits, making it a convenient solution for global communication.
TheToolBus.ai
TheToolBus.ai is an AI-powered platform that offers a wide range of free digital tools to simplify various tasks. From age calculation to file conversion, image editing, text formatting, and more, TheToolBus.ai provides efficient solutions for everyday needs. Users can access tools like PDF converters, image background remover, audio to text converter, and even AI test generators. The platform aims to enhance productivity and efficiency by providing user-friendly tools for different digital tasks.
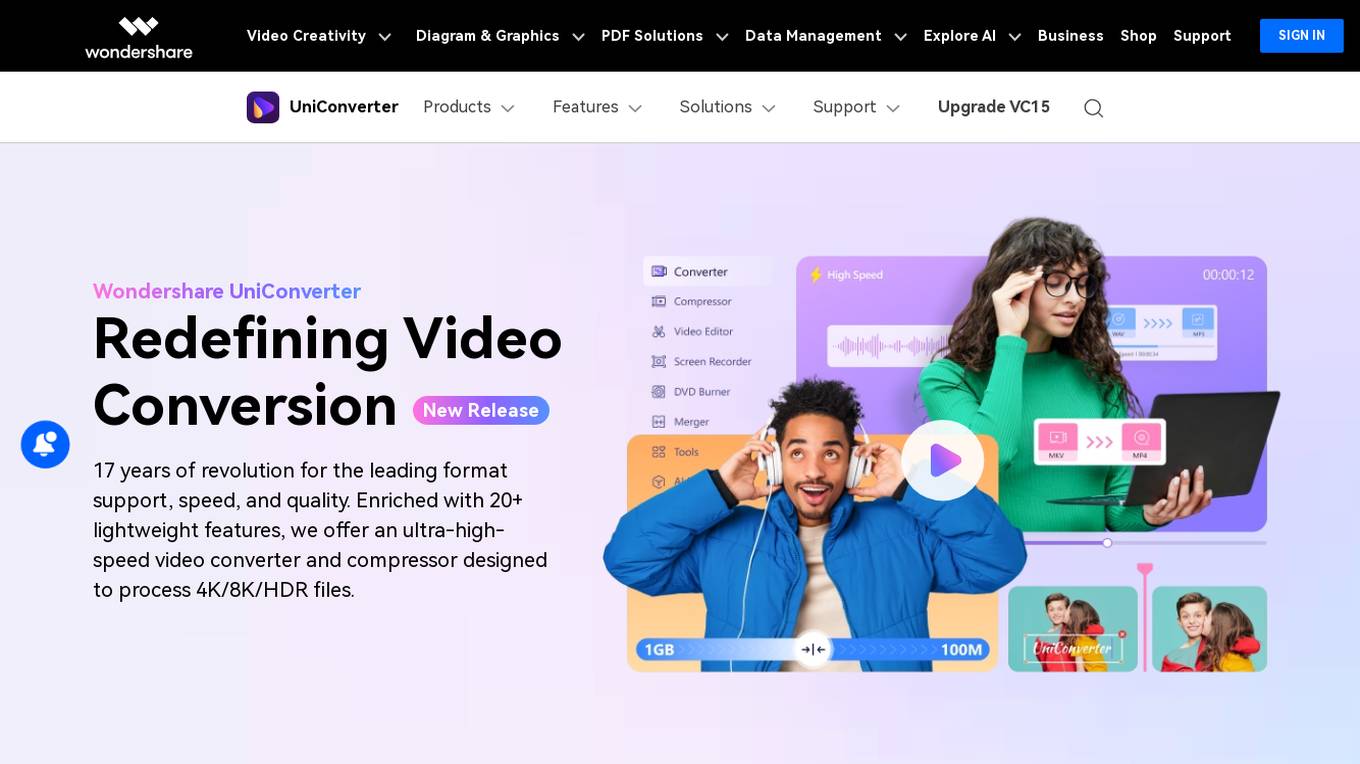
Wondershare UniConverter
Wondershare UniConverter is a powerful and versatile video converter and compressor that supports over 1000 formats, including popular audio and video formats like MP4, MOV, MKV, WMV, MP3, and more. It also enables alpha channel video output in MP4 and WEBM formats. UniConverter is designed to process 4K/8K/HDR files with ease, and it offers a range of features to help you convert, compress, and edit your videos. These features include: * **High-speed conversion:** UniConverter is the fastest video converter on the market, with conversion speeds of up to 130X. This is thanks to its GPU-accelerated conversion engine, which takes advantage of the latest hardware to deliver lightning-fast performance. * **Lossless HD processing:** UniConverter preserves the quality of your videos during conversion, even when converting between different formats. This is thanks to its advanced video processing algorithms, which ensure that your videos look their best on any device. * **AI-powered enhancement:** UniConverter uses AI to enhance your videos, making them look and sound their best. This includes features like AI noise reduction, AI image enhancement, and AI scene detection. * **Extensive formats support:** UniConverter supports over 1000 audio and video formats, including MOV, AV1, MP4, etc., providing comprehensive coverage for all your file conversion needs.
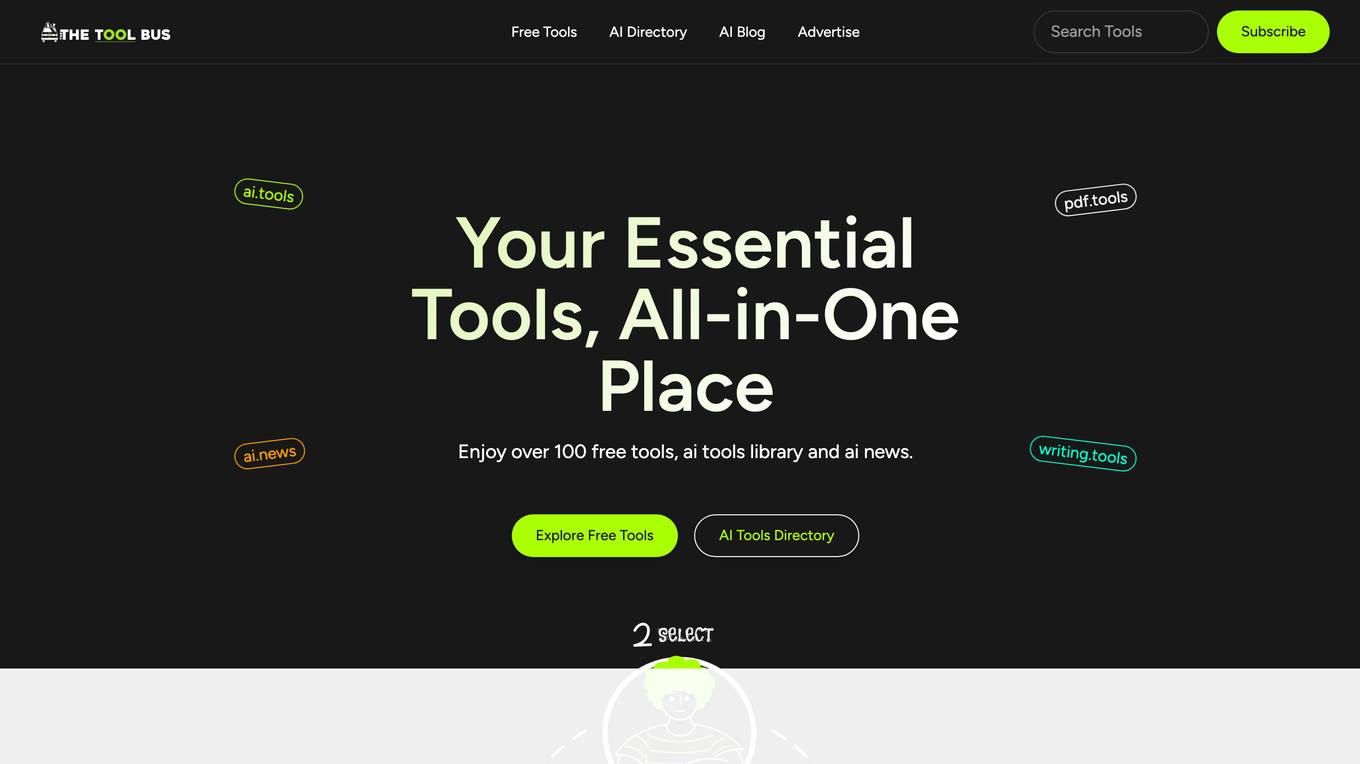
TheToolBus.ai
TheToolBus.ai is an AI-powered platform offering a wide range of free digital tools to streamline various tasks. From age calculation to file conversion, image editing, text formatting, and more, users can access a diverse set of tools to enhance productivity and efficiency in their daily digital activities. The platform also features AI-generated content creation tools, such as cover letter generator, quiz generator, and text-to-emoji converter, catering to different user needs. With regular updates and a community-driven approach, TheToolBus.ai aims to provide users with innovative solutions to simplify their digital workflows.
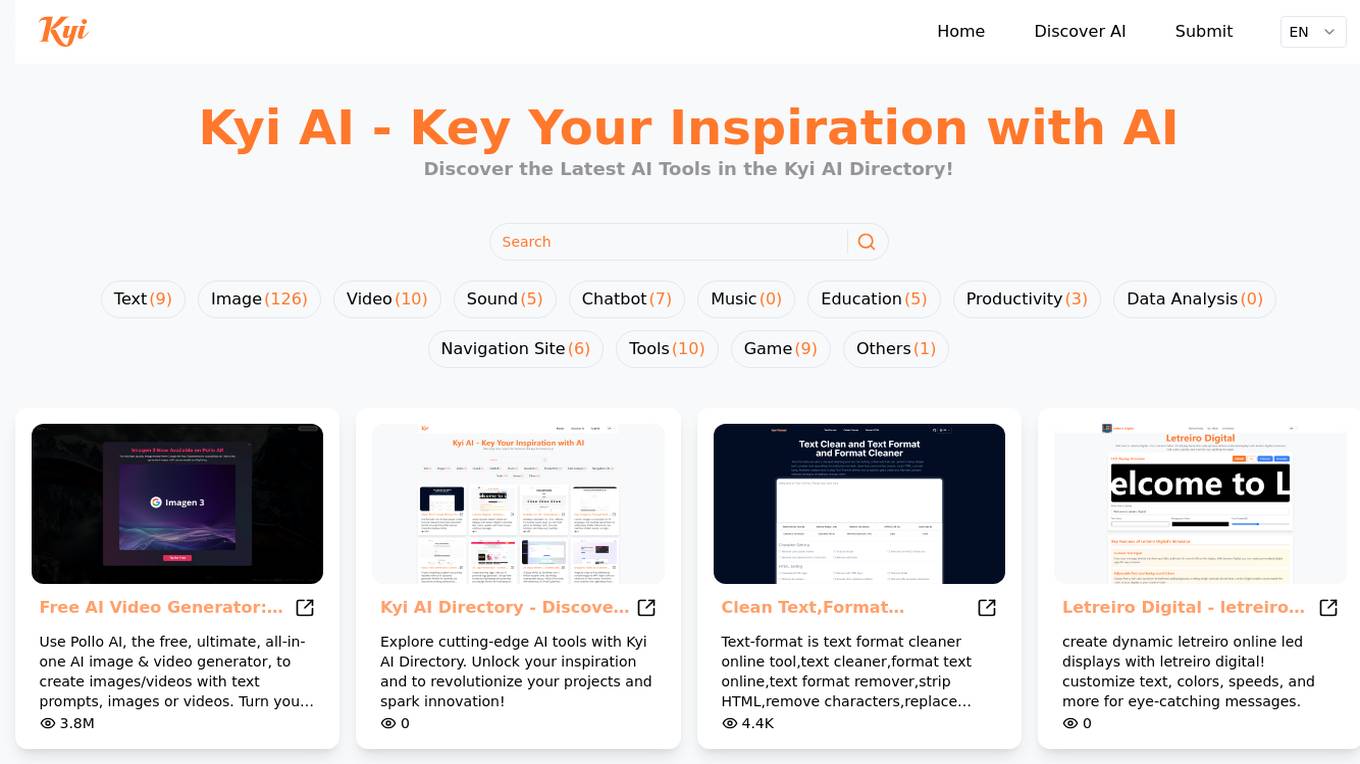
Kyi AI Directory
Kyi AI Directory is a platform dedicated to discovering cutting-edge AI tools and inspiring innovation. Users can explore a wide range of AI tools across various categories such as Text, Image, Video, Sound, Chatbot, Music, Education, Productivity, Data Analysis, Navigation Site, Tools, Game, and more. The platform aims to unlock users' inspiration, revolutionize projects, and spark innovation by providing access to the latest AI tools. With features like a Free AI Video Generator, Text Format Cleaner, AI Logo Generator, AI Essay Writer, and Image to Video AI Converter, Kyi AI Directory offers a diverse set of tools to cater to different user needs.
0 - Open Source AI Tools
20 - OpenAI Gpts


Reverse Engineer Icons - ThePromptfather
Specialist in reverse engineering icons to your specifications. Upload an image of the icons you want - ThePromptfather
Pymage
Enginyer de Python per a la creació i manipulació d'imatges i arxius.Fàcil,clar i Català.
LaTeX Picture & Document Transcriber
Convert into usable LaTeX code any pictures of your handwritten notes, documents in any format. Start by uploading what you need to convert.
MarkDown変換くん
入力した文章をMarkdown形式にコードとして正しく変換してくれます。文章を入力するだけでOKです!更に、読み手が読みやすいようにレイアウトも考えてくれます!途中で止まっても「続けてください」といえば大丈夫です。
Jenson Type Designer
Design your own fonts from text or image inspiration with this adaptive typography mastermind. Share a text description or image and get a proof of concept, full font character sheet, and marketing promo image for the new typeface, step by step.

Favicon Wizard
Upload your brand logo or other favorite brand image asset and we'll create a favicon for you!