Best AI tools for< Convert Audio Files >
20 - AI tool Sites
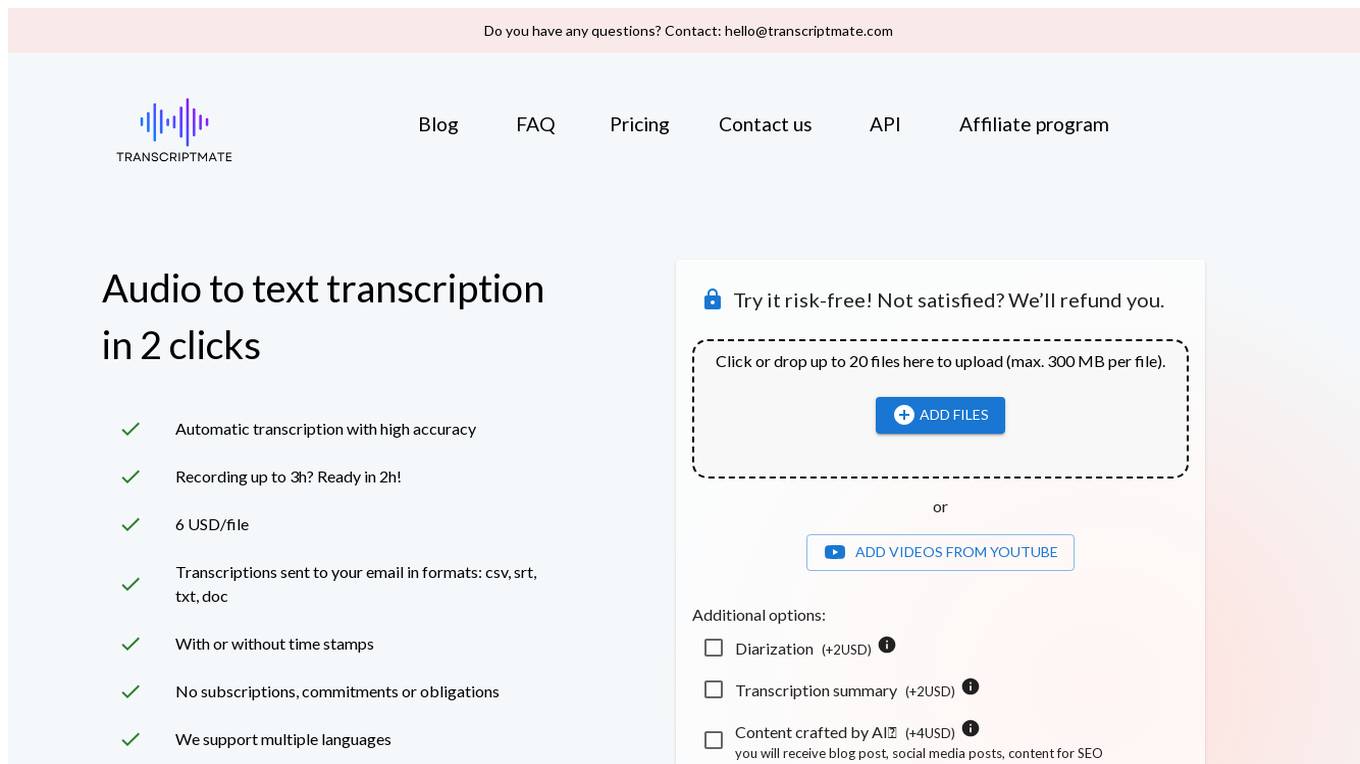
Transcriptmate
Transcriptmate is an AI-powered audio to text transcription tool that offers automatic transcription with high accuracy. Users can easily convert audio files to text in just 2 clicks, with the option to add features like diarization and AI content crafting. The tool supports multiple languages, provides transcriptions in various formats, and ensures safe payments. Transcriptmate is recommended by customers for its efficiency, accuracy, and user-friendly interface.
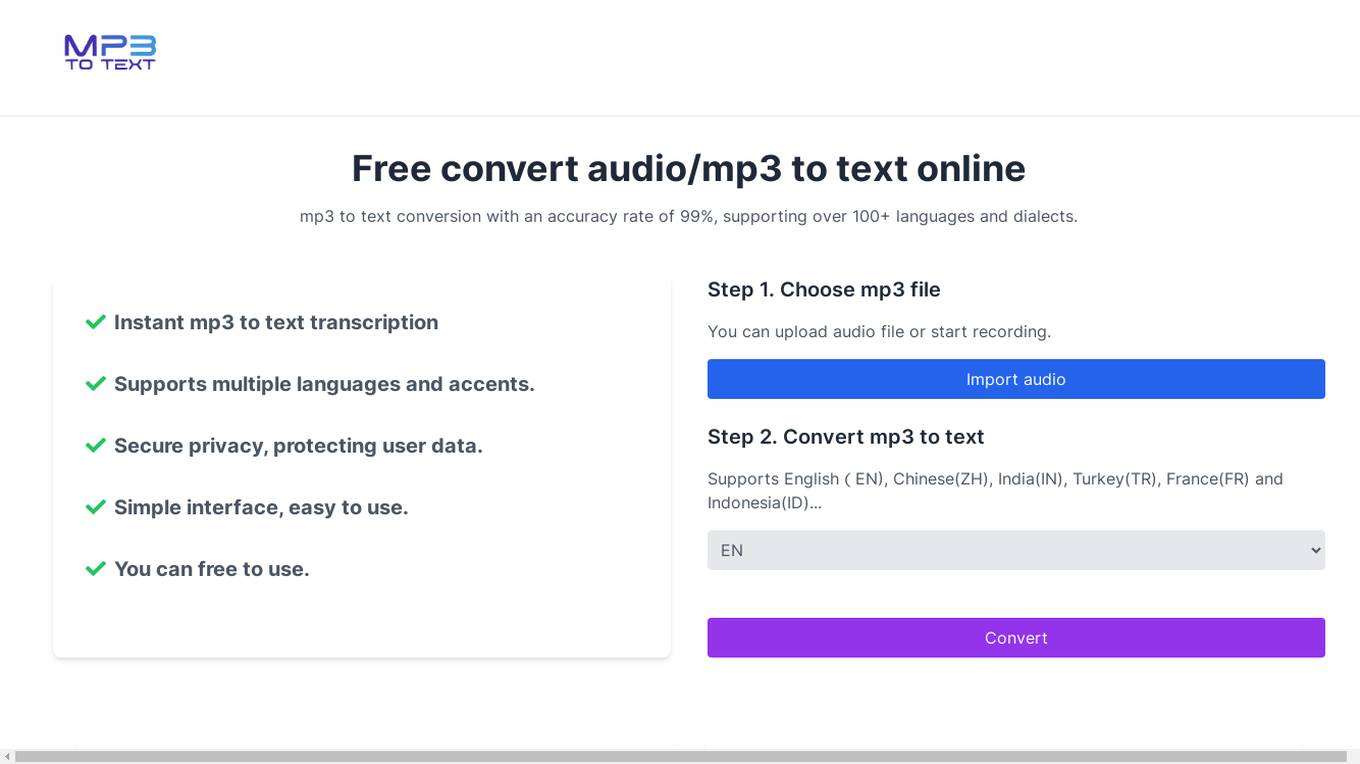
Woy AI Tools
Woy AI Tools is an online tool that offers free audio to text conversion services with an accuracy rate of 99%. Users can convert MP3 audio files into written text in over 100+ languages and dialects. The tool provides instant transcription, supports multiple languages and accents, ensures secure privacy for user data, and offers a simple interface for easy usage.
AIConvert
AIConvert is a web-based application that allows users to convert various types of files into different formats. It supports a wide range of file formats, including documents, images, videos, and audio files. AIConvert is easy to use and does not require any software installation. Users simply need to upload the file they want to convert and select the desired output format. AIConvert will then automatically convert the file and provide a download link.
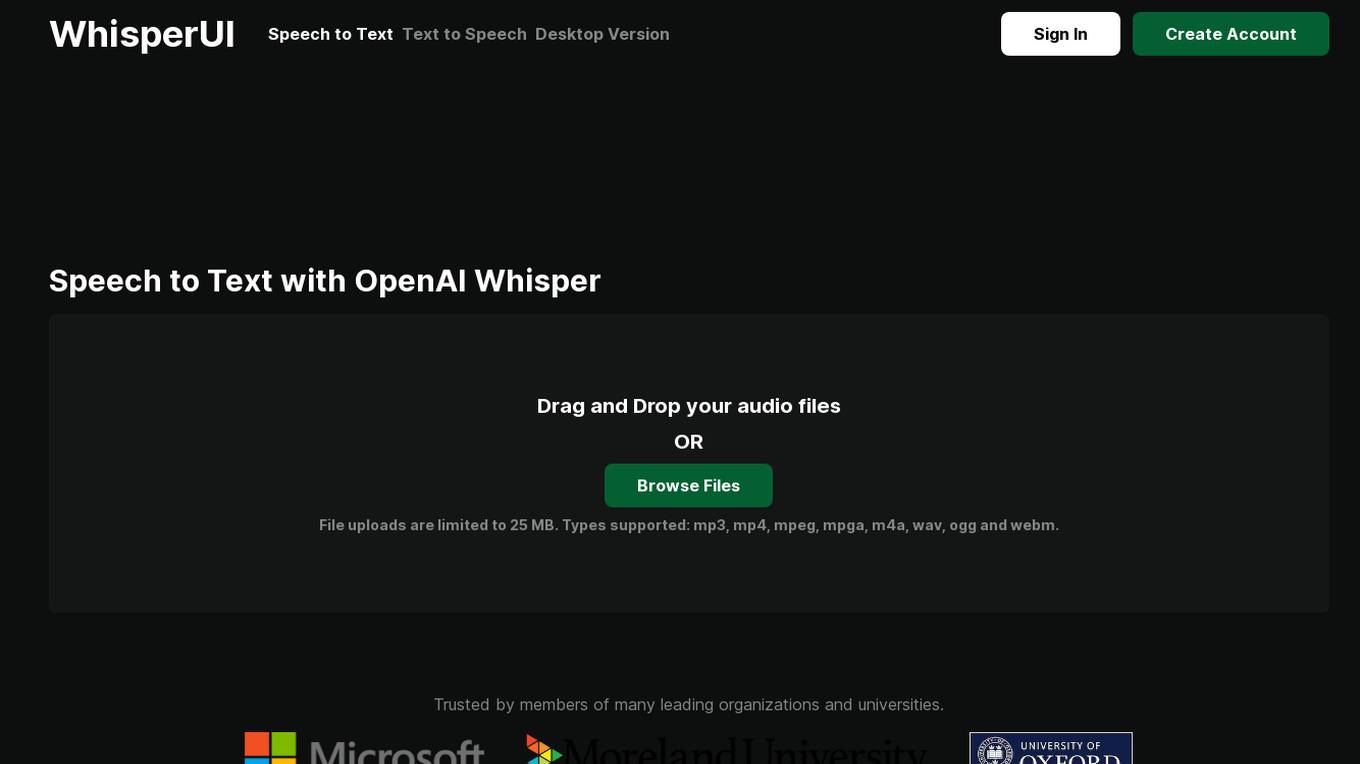
WhisperUI
WhisperUI is an affordable Speech to Text application powered by OpenAI Whisper. It allows users to easily convert audio files into text and SRT files with high accuracy. The application is trusted by members of leading organizations and universities. Users can upload various audio file formats and benefit from premium features such as uploading multiple files at once and unlimited daily file uploads. WhisperUI supports multiple languages and is known for its robustness in transcribing speech in the presence of accents, background noise, and technical language.
Ragobble
Ragobble is an audio to LLM data tool that allows you to easily convert audio files into text data that can be used to train large language models (LLMs). With Ragobble, you can quickly and easily create high-quality training data for your LLM projects.
Free Audio to Text Converter
The Free Audio to Text Converter is an AI-powered tool that allows users to quickly and accurately transcribe audio files into text. It supports various audio formats and offers features like multi-speaker identification, multiple export formats, and precise timestamps. The tool is designed to enhance productivity by providing high-quality transcriptions for a wide range of needs, from content creation to academic research and sales analysis. Users can trust the tool's accuracy and efficiency to save time and improve workflow.
Mp3Converter AI
Mp3Converter AI is an online audio converter tool powered by AI technology. It allows users to convert various audio formats such as WAV, FLAC, and AAC to MP3 effortlessly. The tool provides high-quality audio conversions quickly and efficiently, making it a versatile solution for all audio conversion needs. With a user-friendly interface and batch conversion feature, Mp3Converter AI ensures a seamless experience for converting music files to MP3 format.
BlogMyVideo
BlogMyVideo is a web-based application that converts videos and audio files into written blog posts using artificial intelligence (AI) technology. It allows users to easily transform their video content into engaging and search engine optimized blog posts, making it more accessible to a wider audience and improving discoverability. The application features seamless YouTube integration, allowing users to sync their YouTube videos for automatic conversion. Additionally, it supports uploading audio files and podcasts for conversion, providing a versatile solution for content creators. BlogMyVideo offers editing capabilities, enabling users to customize the generated text to match their style and preferences. The platform also includes SEO optimization features such as optimized meta tags, canonical links, and structured Schema markup to enhance search engine visibility and performance.
Scribewave
Scribewave is an AI-powered online transcription tool that allows users to automatically transcribe audio and video files into text. It supports over 90 languages and dialects, offers accurate transcription with speaker recognition, and provides features like subtitles generation, audio-to-video conversion, and translations to multiple languages. Scribewave is designed to simplify content conversion, saving users time and enabling them to focus on more critical tasks.
TranscribeAudio
TranscribeAudio is an AI-powered transcription tool that enables users to convert audio files into text quickly and accurately. It offers features like speaker identification, insights generation, and secure file handling. The tool is user-friendly, with a simple editor for reviewing and refining transcripts. TranscribeAudio provides a subscription-based service with a generous free tier and simple pricing. It is constantly updated with new features to enhance user experience.
OneAudio
OneAudio is an AI-powered tool that allows users to summarize, transcribe, and convert audio files into notes. With features like recording, summarization, and language selection, OneAudio helps users organize and transform their ideas efficiently. The tool leverages OpenAI GPT-4 and GPT-4o models to provide accurate transcriptions and summaries. Users can choose from different pricing plans based on their needs, from a free tier to a premium plan with unlimited features. OneAudio is designed to streamline the process of converting audio content into written notes, making it ideal for students, professionals, and anyone looking to enhance their productivity.
Music Demixer
Music Demixer is an AI-powered online tool that allows users to convert audio files into readable sheet music, MIDI files, and stems. It offers features like separating vocals and instruments, multi-track MIDI conversion, lead and backing vocals split, drum kit breakdown, and more. With a user-friendly interface, Music Demixer caters to musicians and music producers looking to transcribe music, remix tracks, or practice specific instruments. The tool ensures privacy by running most processing tasks in the user's browser and offers a 3-day free trial for users to explore its capabilities.
Vocaldo
Vocaldo is a revolutionary speech-to-text application that utilizes cutting-edge AI technology to transcribe speech into text in over 100 languages. It offers accurate, fast, and easy-to-use transcription services, allowing users to effortlessly convert audio or video files into text with high precision. Vocaldo supports multiple speakers, various accents, and background noise, making it a versatile tool for content creators, journalists, and businesses worldwide.
AnthemScore
AnthemScore is an automatic music transcription software that uses AI to convert audio files like MP3 and WAV into sheet music. It offers features like automatic note detection, easy correction, time-saving tools, customization for different instruments, and advanced editing options. Users can transcribe songs, view, save, and print sheet music, and choose from different editions based on their needs. AnthemScore is available for Windows, Mac, and Linux, with a free trial option and various pricing plans for Lite, Professional, and Studio editions.
Sonix
Sonix is a powerful and easy-to-use online audio and video transcription service. It uses advanced artificial intelligence (AI) to convert speech to text quickly and accurately. Sonix supports over 38 languages and offers a variety of features, including automatic transcription, translation, subtitling, and summarization. It is a valuable tool for journalists, researchers, students, businesses, and anyone who needs to transcribe audio or video content.
Transgate
Transgate is an AI-powered speech-to-text conversion tool that allows users to convert audio/video files to text with high accuracy and efficiency. It offers a pay-as-you-go model, supports over 50 languages, and guarantees 98%+ accuracy. Transgate is designed to boost productivity by minimizing costs and eliminating manual transcription tasks, catering to industries like AI/ML, medical, legal, education, consulting, and market research.
Transcripo
Transcripo is a free online transcription AI tool that converts audio and video files into text or subtitles. It offers a user-friendly interface for users to easily transcribe their content in over 100 languages. With features like drag & drop file upload, quick transcription turnaround, and AI summaries, Transcripo simplifies the transcription process for various purposes such as creating subtitles for videos, summarizing interviews, and more. The tool also provides affordable pricing plans with a free trial option, making it accessible to individuals and businesses alike.
Article.Audio
Article.Audio is a web application that allows users to convert articles into audio files, enabling them to listen to the content instead of reading it. Users can easily convert text documents, PDFs, and web links into audio format, with the option to choose from a variety of languages and speaking styles. The application is powered by Thundercontent and offers a user-friendly interface for a seamless experience. With features like natural-sounding human voices, unlimited listening, and audio management with tags, Article.Audio aims to enhance accessibility and convenience for users who prefer audio content consumption.
Podcastle
Podcastle is an all-in-one podcasting software that empowers creators of all backgrounds and experience levels with an intuitive, AI-powered platform. It offers a wide range of features, including a recording studio, audio editor, video editor, AI-generated voices, and hosting hub, making it easy to create, edit, and publish high-quality podcasts and videos. Podcastle is designed to be user-friendly and accessible, with no prior experience or technical expertise required.
Transkriptor
Transkriptor is an AI-powered tool that allows users to convert audio or video files into text with high accuracy and efficiency. It supports over 100 languages and offers features like automatic transcription, translation, rich export options, and collaboration tools. With state-of-the-art AI technology, Transkriptor simplifies the transcription process for various purposes such as meetings, interviews, lectures, and more. The platform ensures fast, accurate, and affordable transcription services, making it a valuable tool for professionals and students across different industries.
0 - Open Source AI Tools
20 - OpenAI Gpts
All Purpose Audio Format Converter
Expert in audio format conversion, guiding through simple steps.
ConvertAnything
The ultimate tool for converting files, whether they are images, audio, video, documents, or other types. It can process single files or multiple files in bulk, accepts ZIP files, and offers a download link [Updated version].


Guitar Melody Harmonizer
Harmonizes ABC-notation melodies for guitar and assists with mp3 to MIDI conversion, MIDI to ABC-notation, and more.

DocuScan and Scribe
Scans and transcribes images into documents, offers downloadable copies in a document and offers to translate into different languages
Text to DB Schema
Convert application descriptions to consumable DB schemas or create-table SQL statements
Size Wizard
Find the right size clothes. I convert your measurements into sizes of different standards. Say “hello” in your language to start.
Malevich GPT - Emoji to Art 🤯 -> 🎨
Convert emotions and feelings to evocative abstract art. Share you daily mood with text or emoji and I help you to create masterpiece .
Global Salary Converter (PPP adjusted)
Convert salaries across countries, adjusted for Purchasing Power Parity (PPP)

Quotes CloudArt
I can convert your favorite quotes into a word cloud with a specified shape.
Athena Notes AI
I convert transcripts into detailed meeting notes with insights, summaries, and action items, plus a downloadable MS Word file.
Screenshot To Code GPT
Upload a screenshot of a website and convert it to clean HTML/Tailwind/JS code.
CondenserPRO: 1-page condensed papers
Convert 20-page articles/ reports/ white-papers to a 1 pager with maximum information fidelity. Summaries so good, you'll never want to read the original first! Upload your PDF and say 'GO'.
LaTeX Picture & Document Transcriber
Convert into usable LaTeX code any pictures of your handwritten notes, documents in any format. Start by uploading what you need to convert.