Best AI tools for< Control Audio >
20 - AI tool Sites
Google DeepMind
Google DeepMind is an AI research lab that focuses on developing advanced artificial intelligence systems to benefit humanity. The lab explores various AI models and applications, such as image generation, audio control, video production, music generation, and interactive world exploration. Google DeepMind also works on responsible AI development and safety measures to address evolving threats. The lab's breakthroughs include advancements in protein structure prediction, genetics decoding, weather forecasting, and interactive world modeling.
Generador de Voz
Generadordevoz.com is an online tool that allows users to generate voices for any text in seconds using over 409 realistic voices in more than 129 languages and dialects. Users can choose the language, voice, and paste their text to generate voices online. The tool offers advanced features such as extended character limit for audio generation, access to generated audio history, audio control settings, realistic breathing pauses, SSML support for audio customization, and priority support. Users can participate by creating articles or videos showcasing the tool's usage to gain access to the Advanced Panel with premium features. The tool can be used for various purposes such as advertisements, corporate training, IVR greetings, product promotions, podcasts, YouTube monetization, audiobooks, social media videos, news delivery, university lectures, accessibility for people with disabilities, and more.
VoiceCanvas
VoiceCanvas is an advanced AI-powered multilingual voice synthesis and voice cloning platform that offers instant text-to-speech in over 40 languages. It utilizes cutting-edge AI technology to provide high-quality voice synthesis with natural intonation and rhythm, along with personalized voice cloning for more human-like AI speech. Users can upload voice samples, have AI analyze voice features, generate personalized AI voice models, input text for conversion, and apply the cloned AI voice model to generate natural voice speech. VoiceCanvas is highly praised by language learners, content creators, teachers, business owners, voice actors, and educators for its exceptional voice quality, multiple language support, and ease of use in creating voiceovers, learning materials, and podcast content.
Seedance2 Pro
Seedance2 Pro is an unofficial AI video generator that allows users to create cinematic clips using text, images, videos, and audio references. It offers full API access and features like multimodal inputs, director control, and clip generation within the range of 4-15 seconds. Users can mix various references to maintain consistency, mimic camera moves, and enhance storytelling. The platform provides affordable access to AI video generation without the need for a Chinese phone number or local account.
Seedance 2.0
Seedance 2.0 is an AI video generator platform that allows users to create stunning videos from text or images. It leverages advanced multimodal AI technology to transform creative ideas into professional-quality content. The platform is free to start and caters to both beginners and professionals in video creation. Seedance 2.0 offers features such as text to video conversion, image to video conversion, and a showcase of professional work. Users can access resources, help center, blog, and API documentation on the website.
InfiniteTalk AI
InfiniteTalk AI is an advanced AI tool for audio-driven video generation, offering features such as sparse-frame dubbing and infinite-length video creation. It provides razor-accurate lip sync, expressive full-body motion, and rock-solid identity preservation powered by next-gen technology. Users can upload videos or images and dub them with speech or dialogue, generating lip-synced animated videos with smooth motion. The application supports both video-to-video dubbing and image-to-video generation, maintaining consistency in face, posture, lighting, and background throughout the video. InfiniteTalk AI offers stability, realism, and various resolution options for exporting videos.
Transgate
Transgate is an AI-powered speech-to-text conversion tool that allows users to convert audio/video files to text with high accuracy and efficiency. It offers a pay-as-you-go model, supports over 50 languages, and guarantees 98%+ accuracy. Transgate is designed to boost productivity by minimizing costs and eliminating manual transcription tasks, catering to industries like AI/ML, medical, legal, education, consulting, and market research.
FlowSpeech
FlowSpeech is an AI-powered Text To Speech studio that offers lifelike human voices, emotion and pause control, and seamless multi-speaker casting for professional audio generation. It understands context, integrates pause and emotion control, and delivers TTS audio that sounds like a real human. The AI-driven engine analyzes sentiment, timing, and nuance of scripts, allowing for precise emotion delivery. Users can add custom emotions and accents, control pauses, and select from 30 distinct voices across different styles. With support for 70+ languages and the ability to process up to 200k characters per render, FlowSpeech is a versatile tool for content creators, marketers, and educators.
Seedance 2.0
Seedance 2.0 is a multi-modal AI video generator that allows users to create, extend, and edit cinematic videos using text, images, video, and audio references. It offers precise creative control and structured input methods to ensure predictable and production-ready outputs. With features like multi-modal input, shot-level control, high-fidelity image guidance, video motion transfer, and native audio-driven video generation, Seedance 2.0 empowers users to produce high-quality videos efficiently. The application supports targeted edits, extension of existing video clips, and maintains character and scene consistency across multiple shots. Seedance 2.0 is designed to streamline the video creation process and provide users with a tool for fast and reliable video production.
Samplab
Samplab is an AI-powered audio editing tool that allows users to manipulate audio samples with advanced features such as note editing, chord detection, stem separation, audio to MIDI conversion, and audio warping. It offers a seamless integration with digital audio workstations (DAWs) as a plugin or desktop app, enabling producers to enhance their music production workflow. Samplab's AI technology revolutionizes the way users interact with audio samples, providing unprecedented control over notes, chords, and melodies.
Speechki
Speechki is an AI Realistic Voice Generator and Text-to-Speech Solution offering over 1,100 voices in 80+ languages. It provides a user-friendly platform for converting text into engaging audio with AI-powered voices. The application is designed to cater to various needs such as audiobook production, content creation, podcasting, and more. With features like real-time proof-listening, chapter-like formatting, streamlined role management, precision pause control, and nuanced speech control, Speechki aims to enhance the user experience and deliver lifelike audio output. The tool also offers global reach with multicast and multilanguage support, making it suitable for a diverse audience.
PolygrAI
PolygrAI is a digital polygraph powered by AI technology that provides real-time risk assessment and sentiment analysis. The platform meticulously analyzes facial micro-expressions, body language, vocal attributes, and linguistic cues to detect behavioral fluctuations and signs of deception. By combining well-established psychology practices with advanced AI and computer vision detection, PolygrAI offers users actionable insights for decision-making processes across various applications.
Zonos TTS
Zonos TTS is an advanced multilingual text-to-speech tool that utilizes high-quality AI technology to deliver natural and expressive voice generation. With features like zero-shot voice cloning, multilingual support, and emotion control, Zonos TTS offers users the ability to create lifelike speech with customizable settings. The tool is suitable for various applications, from content creation to virtual assistants, audiobooks, gaming, e-learning, and more. Zonos TTS provides fast real-time processing and a user-friendly interface for seamless speech synthesis.
Seedance 2.0
Seedance 2.0 is an AI-powered video generation platform that transforms text and images into high-quality cinematic videos with native audio. It offers features such as text-to-video conversion, image animation, native audio synthesis, and persistent character identity. The platform provides up to 2K resolution output with multiple aspect ratios and advanced motion control for professional video creation.
ChatTTS
ChatTTS is a text-to-speech tool optimized for natural, conversational scenarios. It supports both Chinese and English languages, trained on approximately 100,000 hours of data. With features like multi-language support, large data training, dialog task compatibility, open-source plans, control, security, and ease of use, ChatTTS provides high-quality and natural-sounding voice synthesis. It is designed for conversational tasks, dialogue speech generation, video introductions, educational content synthesis, and more. Users can integrate ChatTTS into their applications using provided API and SDKs for a seamless text-to-speech experience.
Evolphin
Evolphin is a leading AI-powered platform for Digital Asset Management (DAM) and Media Asset Management (MAM) that caters to creatives, sports professionals, marketers, and IT teams. It offers advanced AI capabilities for fast search, robust version control, and Adobe plugins. Evolphin's AI automation streamlines video workflows, identifies objects, faces, logos, and scenes in media, generates speech-to-text for search and closed captioning, and enables automations based on AI engine identification. The platform allows for editing videos with AI, creating rough cuts instantly. Evolphin's cloud solutions facilitate remote media production pipelines, ensuring speed, security, and simplicity in managing creative assets.
VIDIZMO.AI
VIDIZMO.AI is a data intelligence platform designed for highly regulated industries, offering solutions for video content management, digital evidence management, and redaction. The platform provides granular control over unstructured data types like videos, audio, documents, and images, with features such as AI-powered analytics, multimodal data handling, and HIPAA-compliant data intelligence. VIDIZMO.AI is a government-trusted platform that can be deployed on-premises, in private cloud, or in a hybrid environment, ensuring data privacy and security. The platform is suitable for organizations in government, law enforcement, healthcare, legal, financial services, and insurance sectors, helping them automate workflows, analyze data, and meet regulatory requirements.
Seedance 2.0
Seedance 2.0 is a multi-modal AI video generator developed by ByteDance. It allows users to create broadcast-ready 2K videos with native voiceover in 8 languages in under 60 seconds. The tool offers features like multi-modal input, audio-native generation, multi-shot narrative, and director-level control, making it a versatile solution for video production across various industries. With comprehensive tools for creators, educators, marketers, and professionals, Seedance 2.0 streamlines the video creation process, reducing production costs and time significantly.
Seeddance
Seeddance is an all-in-one AI creative platform that offers a unified multi-modal 4-input system for generating videos, images, and music. It brings together powerful AI models like Seedance 2, Sora 2, Veo 3, Flux Kontext, SeeDream 4, Nano Banana, and Suno. Users can upload images, videos, audio, and text prompts to create stunning multimedia content with precise control over camera movements, audio synchronization, and visual consistency. Seeddance revolutionizes the creative workflow by providing features like multi-modal video creation, visual consistency, camera replication, built-in stereo audio, and one-take continuity.
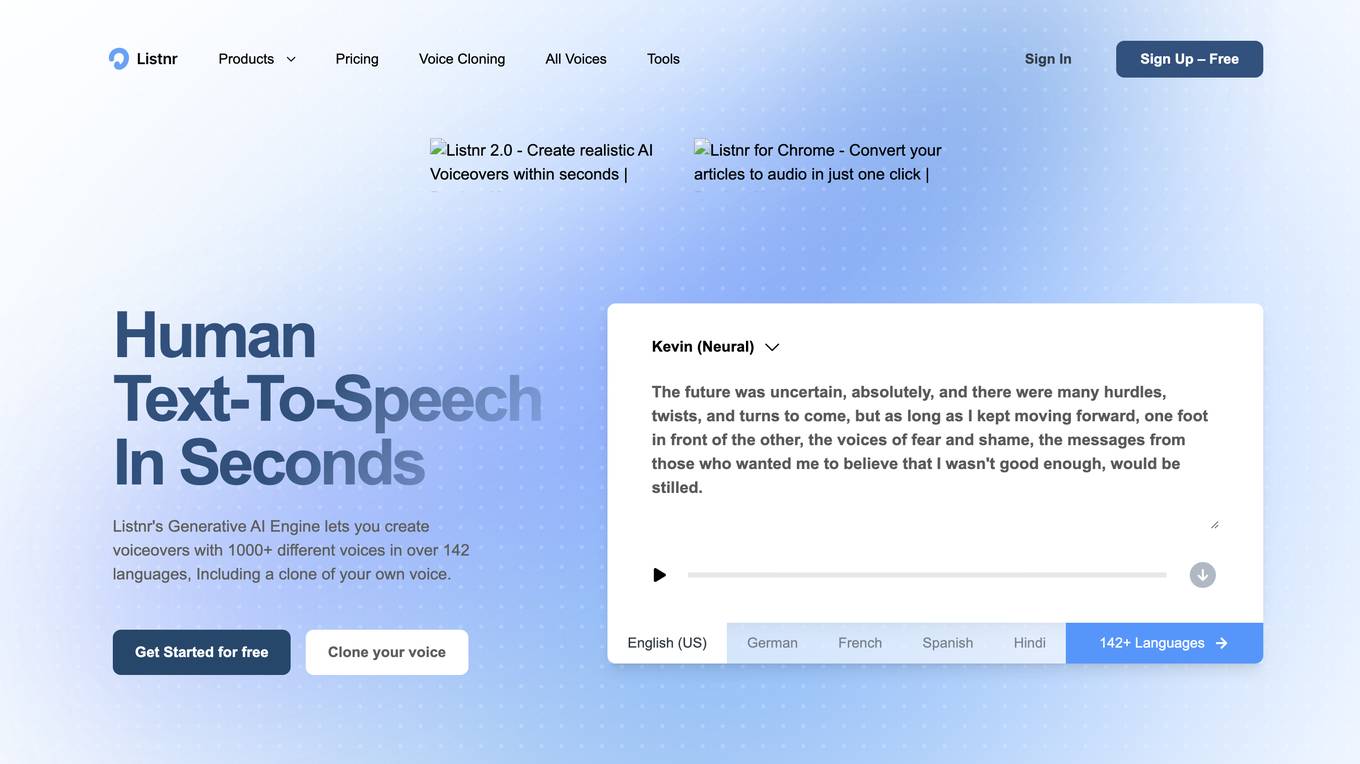
Listnr AI
Listnr AI is a leading AI voice generator tool that offers ultra-realistic AI voices indistinguishable from humans. With over 1000 different voices in more than 142 languages, including voice cloning capabilities, Listnr AI is trusted by 2,500,000+ users worldwide. The tool allows users to create voiceovers for various content types such as shorts, TikToks, YouTube videos, gaming, podcasts, sales, social media, and audiobooks. Listnr AI's state-of-the-art generative AI technology ensures that the voiceovers sound extremely natural, providing a seamless experience for content creators. Additionally, Listnr AI offers features like emotion fine-tuning, punctuations, pauses, and a wide range of multi-lingual voices to cater to diverse content needs.
1 - Open Source AI Tools
addon-airsonos
AirSonos is a Home Assistant Community Add-on that provides AirPlay capabilities for Sonos (and UPnP) players. It bridges the compatibility gap between Apple devices using AirPlay and Sonos players by creating virtual AirPlay devices for Sonos players in the network. The add-on may also work for other UPnP players like newer Samsung televisions. It is based on the AirConnect project, offering a solution for streaming audio to Sonos devices.
20 - OpenAI Gpts

AcousticsAdvisor
An expert in acoustics, providing advice on sound management and noise control.
Internal Auditor Advisor 👩💼
Expert on internal audit standards, 📝 specializing in IFACI norms and IIA resources. Norms, procedures, practices, compliance, ...Powered by Breebs (www.breebs.com)
Corporate Governance Audit Advisor
Ensures corporate compliance through meticulous governance audits.
Sanitize
Expert on sanitation practices and disinfection methods with a focus on hygiene and cleanliness.

高级体系工程师 IATF16949 Senior system Engineer
制定和实施质量管理体系;审核和改进质量管理体系;培训和指导员;处理质量问题;与其他部门协调;持续改进

🤖 SmartLink Integrator 🌎
Your AI bridge to the Internet of Things! Easily connect, control, and automate your smart devices with voice or text commands. 🏠💎