Best AI tools for< Compile Kernels >
20 - AI tool Sites
Roadmapped.ai
Roadmapped.ai is an AI-powered platform designed to help users learn various topics efficiently and quickly. By providing a structured roadmap generated in seconds, the platform eliminates the need to navigate through scattered online resources aimlessly. Users can input a topic they want to learn, and the AI will generate a personalized roadmap with curated resources. The platform also offers features like AI-powered YouTube search, saving roadmaps, priority support, and access to a private Discord community.

SoraPrompt
SoraPrompt is an AI model that can create realistic and imaginative scenes from text instructions. It is the latest text-to-video technology from the OpenAI development team. Users can compile text prompts to generate video query summaries for efficient content analysis. SoraPrompt also allows users to share their interests and ideas with others.
Rargus
Rargus is a generative AI tool that specializes in turning customer feedback into actionable insights for businesses. By collecting feedback from various channels and utilizing custom AI analysis, Rargus helps businesses understand customer needs and improve product development. The tool enables users to compile and analyze feedback efficiently, leading to data-driven decision-making and successful product launches. Rargus also offers solutions for consumer insights, product management, and product marketing, helping businesses enhance customer satisfaction and drive growth.
AI Document Creator
AI Document Creator is an innovative tool that leverages artificial intelligence to assist users in generating various types of documents efficiently. The application utilizes advanced algorithms to analyze input data and create well-structured documents tailored to the user's needs. With AI Document Creator, users can save time and effort in document creation, ensuring accuracy and consistency in their outputs. The tool is user-friendly and accessible, making it suitable for individuals and businesses seeking to streamline their document creation process.
Dokkio
Dokkio is an AI-powered platform that helps users find, organize, and understand all of their online files. By leveraging AI technology, Dokkio enables users to work with their cloud files efficiently and collaboratively. The platform offers tools for managing multiple activities, finding documents and files, compiling research materials, and organizing a content library. Dokkio aims to streamline the process of accessing and utilizing online content, regardless of where it is stored.
Papnox ERP
Papnox ERP is an AI-powered ERP software designed specifically for paper distributors. It offers cloud-based accounting, invoicing, and inventory management solutions. The platform includes modules for CRM, payroll management, website building, and report generation. Papnox ERP is known for its early adoption of disruptive technologies and provides unique insights into the paper distribution industry. The software aims to streamline business operations and enhance efficiency for paper distributors.
Smarty
Smarty is an AI-powered productivity tool that acts as an execution engine for businesses. It combines AI technology with human experts to help users manage tasks, events, scheduling, and productivity. Smarty offers features like natural-language-based console, unified view of tasks and calendar, automatic prioritization, brain dumping, automation shortcuts, and personalized interactions. It helps users work smarter, stay organized, and save time by streamlining workflows and enhancing productivity. Smarty is designed to be a versatile task organizer app suitable for professionals looking to optimize daily planning and task management.
Notis
Notis is an AI voice-powered copilot designed for Notion users. It allows users to break free from their desks by turning their phones into a Notion copilot. Users can capture thoughts, organize them, and get answers from their workspace using voice commands. Notis offers features like transcribing voice notes, managing tasks, writing meeting minutes, content creation for social media, managing customer relationships, tracking expenses, drafting documents, compiling knowledge bases, and more. It integrates seamlessly with Notion, providing a second brain system to manage both professional and personal life efficiently.
PLEASEDONTCODE
PLEASEDONTCODE is an AI Code Generator designed for Arduino and ESP32 embedded systems. It simplifies coding processes, automates code generation, and helps users overcome common obstacles in software development for electronic boards. The platform offers a guided interface with six steps to create error-free, syntactically correct, and logically sound code, enabling users to focus on their projects rather than troubleshooting.

Extractify.co
Extractify.co is a website that offers a variety of tools and services for extracting information from different sources. The platform provides users with the ability to extract data from websites, documents, and other sources in a quick and efficient manner. With a user-friendly interface, Extractify.co aims to simplify the process of data extraction for individuals and businesses alike. Whether you need to extract text, images, or other types of data, Extractify.co has the tools to help you get the job done. The platform is designed to be intuitive and easy to use, making it accessible to users of all skill levels.
aiebooks.app
aiebooks.app is an AI application that allows users to generate personalized eBooks quickly and effortlessly. Powered by OpenAI's GPT-3.5, this tool is designed to transform ideas into reality by compiling clear and concise content on any topic of choice. Whether you are a student, professional, or simply curious, aiebooks.app simplifies complex subjects for convenient and in-depth learning.
Lex Machina
Lex Machina is a Legal Analytics platform that provides comprehensive insights into litigation track records of parties across the United States. It offers accurate and transparent analytic data, exclusive outcome analytics, and valuable insights to help law firms and companies craft successful strategies, assess cases, and set litigation strategies. The platform uses a unique combination of machine learning and in-house legal experts to compile, clean, and enhance data, providing unmatched insights on courts, judges, lawyers, law firms, and parties.
IronClaw
IronClaw is a secure, open-source alternative to OpenClaw that operates in encrypted enclaves on NEAR AI Cloud. It provides defense-in-depth security, 1-click cloud deployment, and ensures that your credentials are never exposed to the AI. IronClaw offers simple setup, built-in security, and the ability to deploy secure agents quickly. It runs inside a Trusted Execution Environment, encrypting data from boot to shutdown. The application is built on Rust and enforces memory safety at compile time. IronClaw also features encrypted vaults, sandboxed tools, leak detection, and network allowlisting to control data flow.
Replexica
Replexica is an AI-powered i18n compiler for React that is JSON-free and LLM-backed. It is designed for shipping multi-language frontends fast.
ThinkRoot
ThinkRoot is an AI Compiler that empowers users to transform their ideas into fully functional applications within minutes. By leveraging advanced artificial intelligence algorithms, ThinkRoot streamlines the app development process, eliminating the need for extensive coding knowledge. With a user-friendly interface and intuitive design, ThinkRoot caters to both novice and experienced developers, offering a seamless experience from concept to deployment. Whether you're a startup looking to prototype quickly or an individual with a creative vision, ThinkRoot provides the tools and resources to bring your ideas to life effortlessly.
Replit
Replit is a software creation platform that provides an integrated development environment (IDE), artificial intelligence (AI) assistance, and deployment services. It allows users to build, test, and deploy software projects directly from their browser, without the need for local setup or configuration. Replit offers real-time collaboration, code generation, debugging, and autocompletion features powered by AI. It supports multiple programming languages and frameworks, making it suitable for a wide range of development projects.
Coddy
Coddy is an AI-powered coding assistant that helps developers write better code faster. It provides real-time feedback, code completion, and error detection, making it the perfect tool for both beginners and experienced developers. Coddy also integrates with popular development tools like Visual Studio Code and GitHub, making it easy to use in your existing workflow.
BugFree.ai
BugFree.ai is an AI-powered platform designed to help users practice system design and behavior interviews, similar to Leetcode. The platform offers a range of features to assist users in preparing for technical interviews, including mock interviews, real-time feedback, and personalized study plans. With BugFree.ai, users can improve their problem-solving skills and gain confidence in tackling complex interview questions.
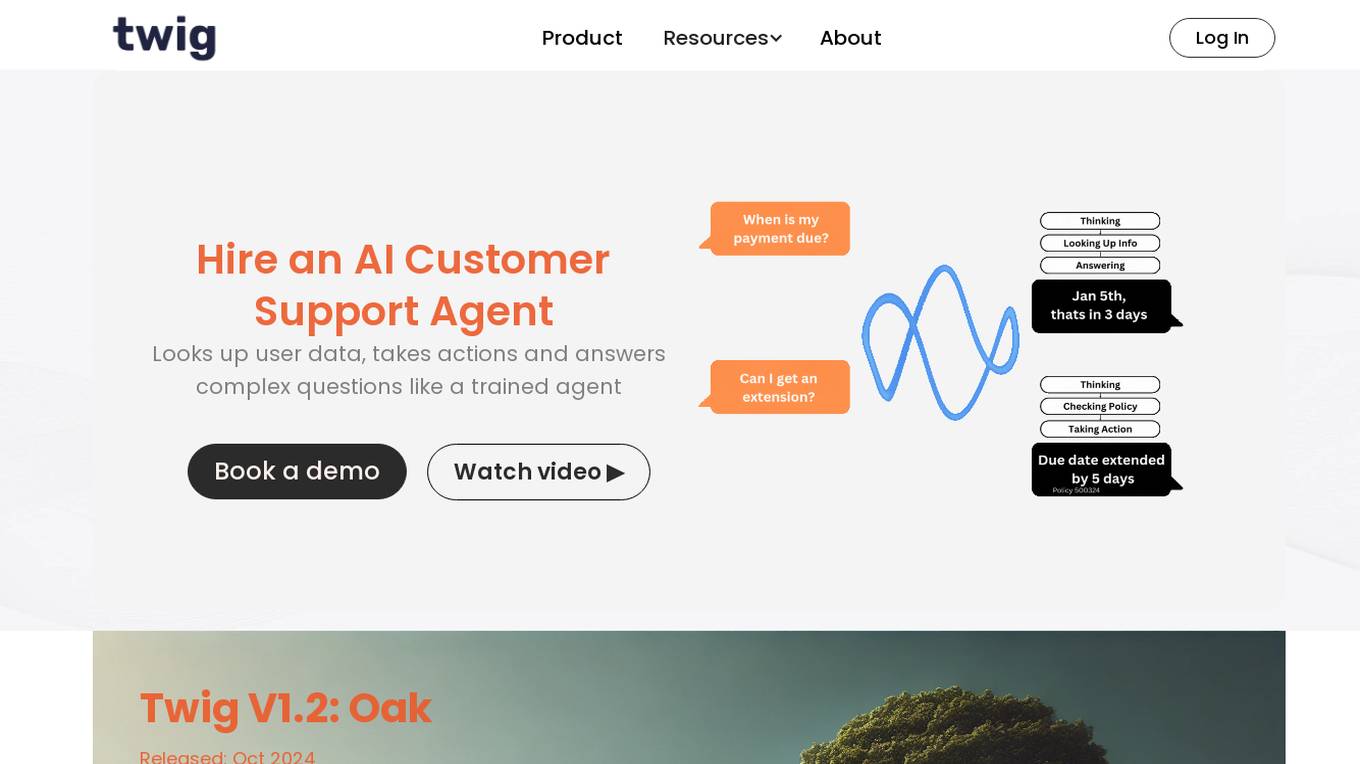
Twig AI
Twig AI is an AI tool designed for Customer Experience, offering an AI assistant that resolves customer issues instantly, supporting both users and support agents 24/7. It provides features like converting user requests into API calls, instant responses for user questions, and factual answers cited with trustworthy sources. Twig simplifies data retrieval from external sources, offers personalization options, and includes a built-in knowledge base. The tool aims to drive agent productivity, provide insights to monitor customer experience, and offers various application interfaces for different user roles.
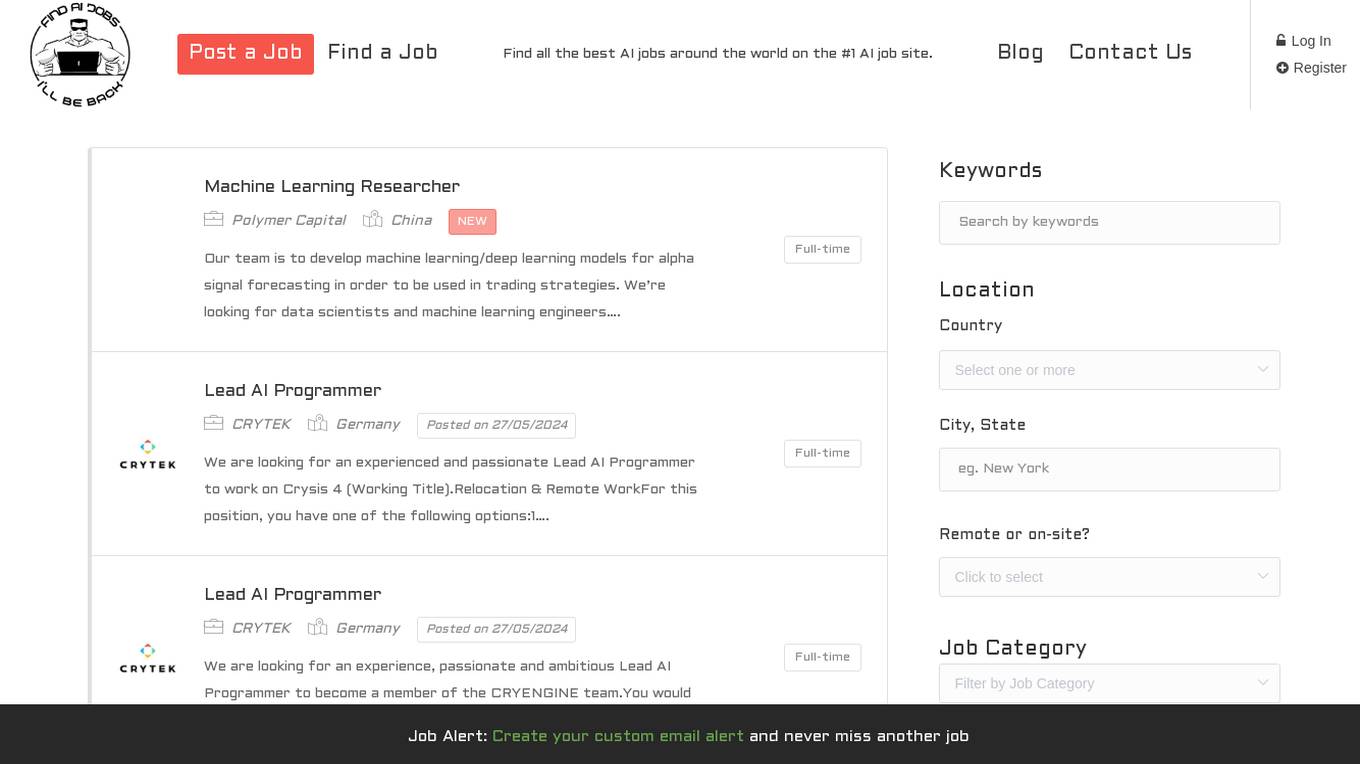
illbeback.ai
illbeback.ai is the #1 site for AI jobs around the world. It provides a platform for both job seekers and employers to connect in the field of Artificial Intelligence. The website features a wide range of AI job listings from top companies, offering opportunities for professionals in the AI industry to advance their careers. With a user-friendly interface, illbeback.ai simplifies the job search process for AI enthusiasts and provides valuable resources for companies looking to hire AI talent.
0 - Open Source AI Tools
20 - OpenAI Gpts


Linux Kernel Expert
Formal and professional Linux Kernel Expert, adept in technical jargon.
Lead Scout
I compile and enrich precise company and professional profiles. Simply provide any name, email address, or company and I'll generate a complete profile.

BioinformaticsManual
Compile instructions from the web and github for bioinformatics applications. Receive line-by-line instructions and commands to get started

FlutterCraft
FlutterCraft is an AI-powered assistant that streamlines Flutter app development. It interprets user-provided descriptions to generate and compile Flutter app code, providing ready-to-install APK and iOS files. Ideal for rapid prototyping, FlutterCraft makes app development accessible and efficient.
Melange Mentor
I'm a tutor for JavaScript and Melange, a compiler for OCaml that targets JavaScript.

ReScript
Write ReScript code. Trained with versions 10 & 11. Documentation github.com/guillempuche/gpt-rescript
Coloring Book Generator
Crafts full coloring books with a cover and compiled into a downloadable document.


Gandi IDE Shader Helper
Helps you code a shader for Gandi IDE project in GLSL. https://getgandi.com/extensions/glsl-in-gandi-ide

A Remedy for Everything
Natural remedies for over 220 Ailments Compiled from 5 Years of Extensive Research.