Best AI tools for< Compare Model Scores >
20 - AI tool Sites
How Attractive Am I
How Attractive Am I is an AI-powered tool that analyzes facial features to calculate an attractiveness score. By evaluating symmetry and proportions, the tool provides personalized beauty scores. Users can upload a photo to discover their true beauty potential. The tool ensures accuracy by providing guidelines for taking photos and offers a fun and insightful way to understand facial appeal.

LLM Pulse
LLM Pulse is an AI search visibility tracker designed for the AI chatbot world. It provides real-time monitoring of your brand's presence across various AI search engines, allowing you to track key prompts, analyze citations, understand visibility scores, and dive into detailed responses. The platform offers insights effortlessly, suggesting relevant prompts, comparing your brand against competitors, and soon analyzing brand sentiment. With different pricing plans catering to individuals, growing businesses, large organizations, and enterprises, LLM Pulse aims to help users make strategic decisions in the age of AI.
AI Content Detector
The AI Content Detector is an online tool that helps users determine the similarity score of AI-generated content and whether it was written by a human or an AI tool. It utilizes advanced algorithms and natural language processing to analyze text, providing a percentage-based authenticity result. Users can input text for analysis and receive accurate results regarding the likelihood of AI authorship. The tool compares syntax, vocabulary, and semantics with AI and human models, offering high accuracy in identifying paraphrased content.
Plumb
Plumb is a no-code, node-based builder that empowers product, design, and engineering teams to create AI features together. It enables users to build, test, and deploy AI features with confidence, fostering collaboration across different disciplines. With Plumb, teams can ship prototypes directly to production, ensuring that the best prompts from the playground are the exact versions that go to production. It goes beyond automation, allowing users to build complex multi-tenant pipelines, transform data, and leverage validated JSON schema to create reliable, high-quality AI features that deliver real value to users. Plumb also makes it easy to compare prompt and model performance, enabling users to spot degradations, debug them, and ship fixes quickly. It is designed for SaaS teams, helping ambitious product teams collaborate to deliver state-of-the-art AI-powered experiences to their users at scale.

Flux LoRA Model Library
Flux LoRA Model Library is an AI tool that provides a platform for finding and using Flux LoRA models suitable for various projects. Users can browse a catalog of popular Flux LoRA models and learn about FLUX models and LoRA (Low-Rank Adaptation) technology. The platform offers resources for fine-tuning models and ensuring responsible use of generated images.
LLMWise
LLMWise is a multi-model LLM API tool that allows users to compare, blend, and route AI models simultaneously. It offers 5 modes - Chat, Compare, Blend, Judge, and Failover - to help users make informed decisions based on model outputs. With 31+ available models, LLMWise provides a user-friendly platform for orchestrating AI models, ensuring reliability, and optimizing costs. The tool is designed to streamline the integration of various AI models through one API call, offering features like real-time responses, per-model metrics, and failover routing.
xeditai
xeditai is an AI-powered studio that provides a comprehensive workspace for creating content using various AI models. It offers a range of features such as rich-text editing, cloud persistence, templates & tones, parallel mode, strategy mode, export & share functionalities, and seamless switching between AI models. xeditai is designed for individuals and teams who need to iterate on ideas, draft, compare, refine, and structure content until the thinking is clear. It aims to facilitate the creation of finished, structured output without relying on chat prompts, providing a platform for real creation and serious work.
Weights & Biases
Weights & Biases is an AI tool that offers documentation, guides, tutorials, and support for using AI models in applications. The platform provides two main products: W&B Weave for integrating AI models into code and W&B Models for building custom AI models. Users can access features such as tracing, output evaluation, cost estimates, hyperparameter sweeps, model registry, and more. Weights & Biases aims to simplify the process of working with AI models and improving model reproducibility.

Neptune
Neptune is an MLOps stack component for experiment tracking. It allows users to track, compare, and share their models in one place. Neptune is used by scaling ML teams to skip days of debugging disorganized models, avoid long and messy model handovers, and start logging for free.
Gemini vs ChatGPT
Gemini is a multi-modal AI model, developed by Google. It is designed to understand and generate human language, and can be used for a variety of tasks, including question answering, translation, and dialogue generation. ChatGPT is a large language model, developed by OpenAI. It is also designed to understand and generate human language, and can be used for a variety of tasks, including question answering, translation, and dialogue generation.
Prompt Octopus
Prompt Octopus is a free tool that allows you to compare multiple prompts side-by-side. You can add as many prompts as you need and view the responses in real-time. This can be helpful for fine-tuning your prompts and getting the best possible results from your AI model.

thisorthis.ai
thisorthis.ai is an AI tool that allows users to compare generative AI models and AI model responses. It helps users analyze and evaluate different AI models to make informed decisions. The tool requires JavaScript to be enabled for optimal functionality.

Rawbot
Rawbot is an AI model comparison tool that simplifies the process of selecting the best AI models for projects and applications. It allows users to compare various AI models side-by-side, providing insights into their performance, strengths, weaknesses, and suitability. Rawbot helps users make informed decisions by identifying the most suitable AI models based on specific requirements, leading to optimal results in research, development, and business applications.
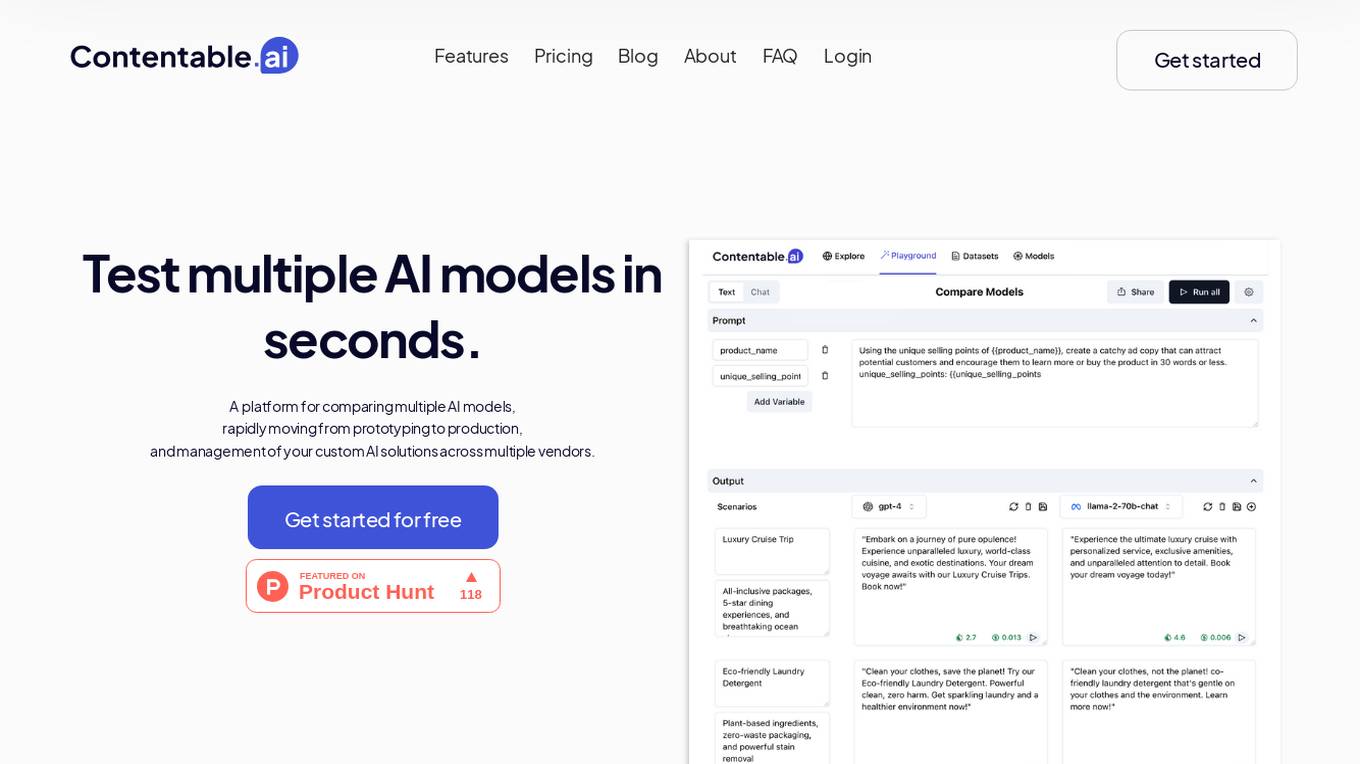
Contentable.ai
Contentable.ai is a platform for comparing multiple AI models, rapidly moving from prototyping to production, and management of your custom AI solutions across multiple vendors. It allows users to test multiple AI models in seconds, compare models side-by-side across top AI providers, collaborate on AI models with their team seamlessly, design complex AI workflows without coding, and pay as they go.
SpeechMap.AI
SpeechMap.AI is a public research project that explores the boundaries of AI-generated speech. It focuses on testing how language models respond to sensitive and controversial prompts across different providers, countries, and topics. The platform aims to reveal the invisible boundaries of AI speech by analyzing what models avoid, refuse, or shut down. By measuring and comparing AI models' responses, SpeechMap.AI sheds light on the evolving landscape of AI-generated speech and its impact on public expression.
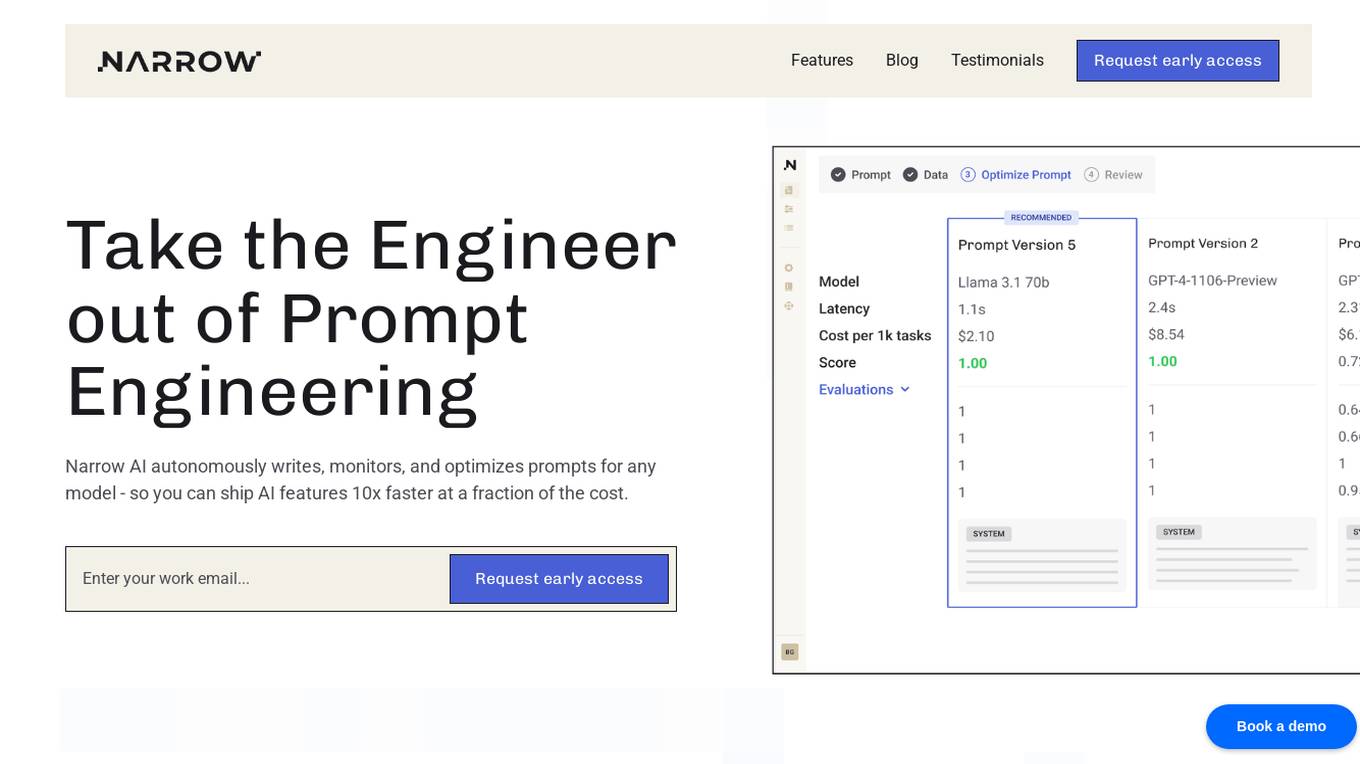
Narrow AI
Narrow AI is an AI application that autonomously writes, monitors, and optimizes prompts for any model, enabling users to ship AI features 10x faster at a fraction of the cost. It streamlines the workflow by allowing users to test new models in minutes, compare prompt performance, and deploy on the optimal model for their use case. Narrow AI helps users maximize efficiency by generating expert-level prompts, adapting prompts to new models, and optimizing prompts for quality, cost, and speed.
MindpoolAI
MindpoolAI is a tool that allows users to access multiple leading AI models with a single query. This means that users can get the answers they are looking for, spark ideas, and fuel their work, creativity, and curiosity. MindpoolAI is easy to use and does not require any technical expertise. Users simply need to enter their prompt and select the AI models they want to compare. MindpoolAI will then send the query to the selected models and present the results in an easy-to-understand format.
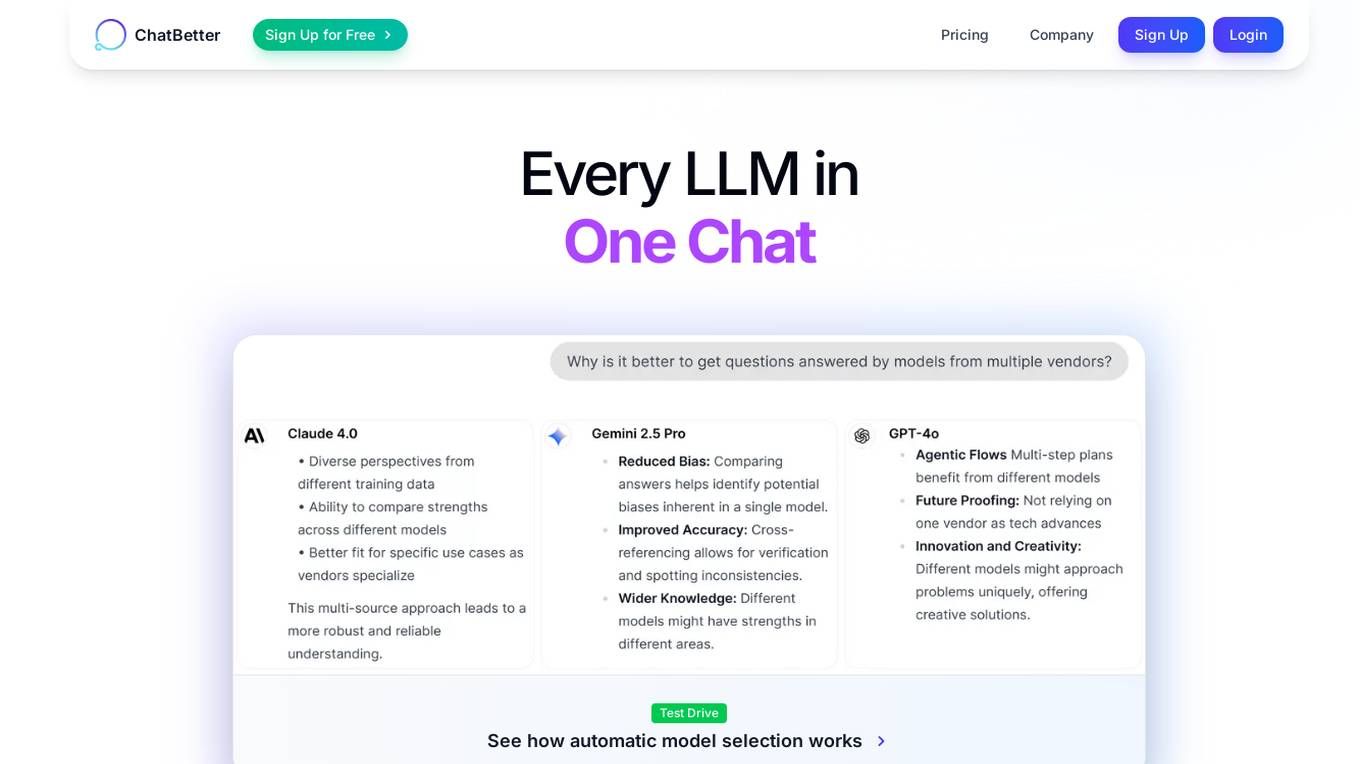
ChatBetter
ChatBetter is an AI tool that offers automatic model selection for users, allowing them to compare and merge responses from various language models. It simplifies the process by automatically routing questions to the best model, ensuring accurate answers every time. The platform provides access to major AI providers like OpenAI, Google, and more, enabling users to leverage a wide range of models in one interface. ChatBetter is designed for both users seeking quick and accurate responses and admins looking for team collaboration and data connections.
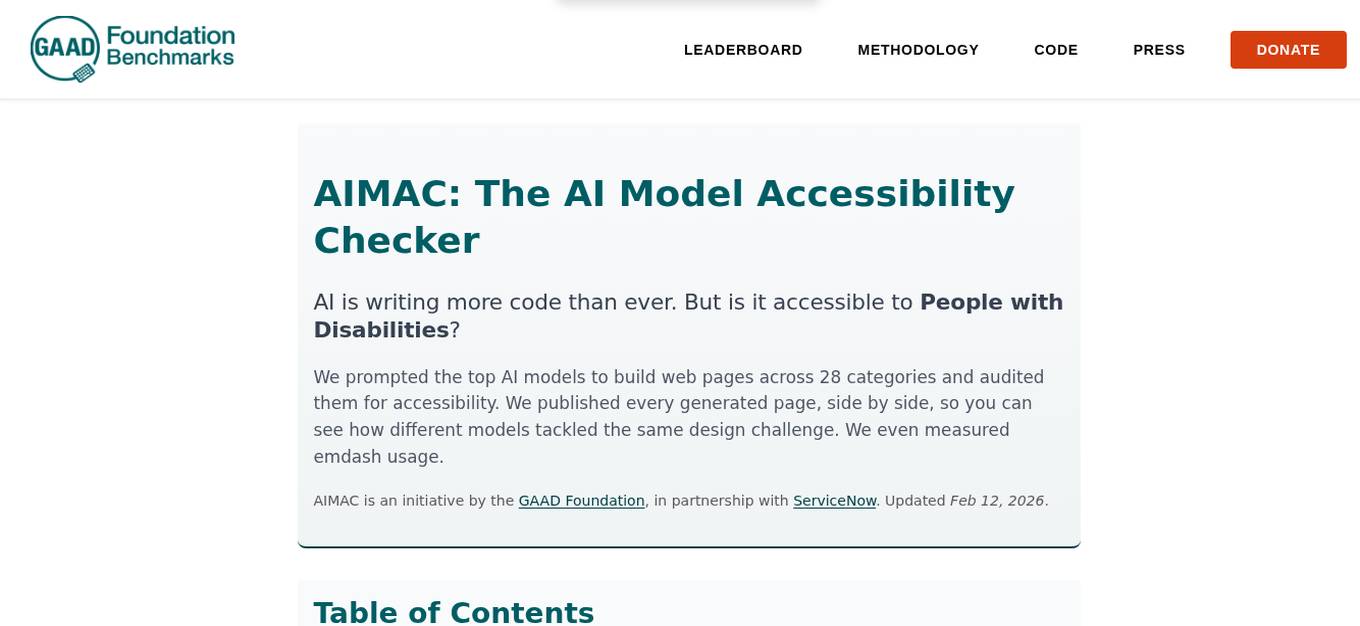
AIMAC Leaderboard
AIMAC Leaderboard is an AI Model Accessibility Checker that evaluates the accessibility of web pages generated by AI models across 28 categories. It compares top AI models side by side, auditing them for accessibility and measuring their performance. The initiative aims to ensure that AI models write accessible code by default. The project is a collaboration between the GAAD Foundation and ServiceNow, providing insights into how different models handle the same design challenges.
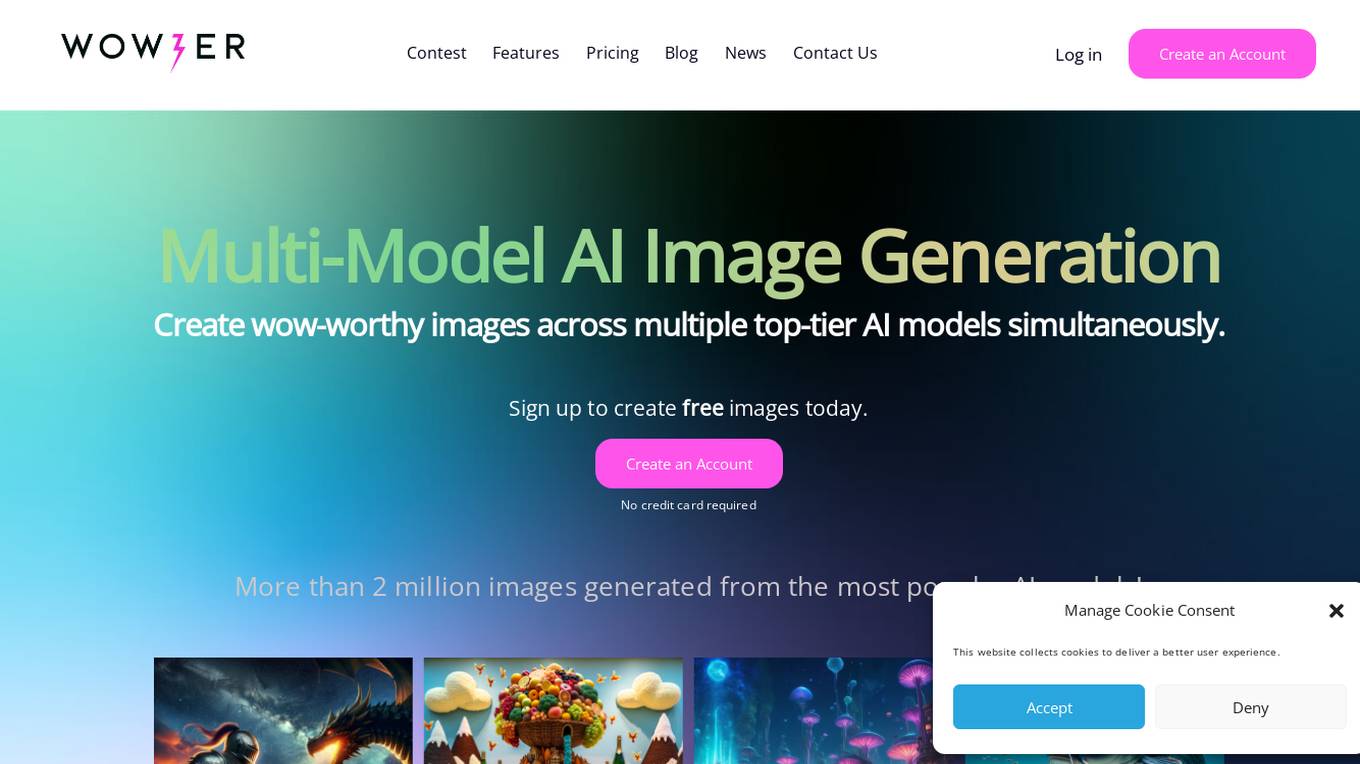
Wowzer AI
Wowzer AI is a multi-model image generation tool that allows users to create stunning images using top-tier AI models simultaneously. With more than 2 million images generated, Wowzer AI makes generative AI easy, fast, and fun. Users can explore and compare unique images from various AI models, enhancing their creative vision. The tool offers Prompt Enhancer to help users craft exceptional creations by generating results across multiple AI models at once. Wowzer AI provides a platform to perfect prompts, create unique images, and share selections at an affordable price.
1 - Open Source AI Tools

evalverse
Evalverse is an open-source project designed to support Large Language Model (LLM) evaluation needs. It provides a standardized and user-friendly solution for processing and managing LLM evaluations, catering to AI research engineers and scientists. Evalverse supports various evaluation methods, insightful reports, and no-code evaluation processes. Users can access unified evaluation with submodules, request evaluations without code via Slack bot, and obtain comprehensive reports with scores, rankings, and visuals. The tool allows for easy comparison of scores across different models and swift addition of new evaluation tools.
20 - OpenAI Gpts
Best price kuwait
A customized GPT model for price comparison would search and compare product prices on websites in Kuwait, tailored to local markets and languages.

Auto Advisor
A helpful guide for car buyers, focusing on potential issues with different car models.


Tesla Reliable Review Guide
Region-specific Tesla info in multiple languages for beginners.




TV Comparison | Comprehensive TV Database
Compare TV Devices Uncover the pros and cons of different latest TV models.