Best AI tools for< Check Json Data Formats >
20 - AI tool Sites
Essay Check
Essay Check is a free AI-powered tool that helps students, teachers, content creators, SEO specialists, and legal experts refine their writing, detect plagiarism, and identify AI-generated content. With its user-friendly interface and advanced algorithms, Essay Check analyzes text to identify grammatical errors, spelling mistakes, instances of plagiarism, and the likelihood that content was written using AI. The tool provides detailed feedback and suggestions to help users improve their writing and ensure its originality and authenticity.
Check Typo
Check Typo is an AI-powered spell-checker tool designed to assist users in eliminating typos and grammatical errors from their writing. It seamlessly integrates within various websites, supports multiple languages, and preserves the original text's style and tone. Ideal for students, professionals, and writers, Check Typo enhances the writing experience with AI-driven precision, making it perfect for error-free emails, professional networking on platforms like LinkedIn, and enhancing social media posts across different platforms.
Copyright Check AI
Copyright Check AI is a service that helps protect brands from legal disputes related to copyright violations on social media. The software automatically detects copyright infringements on social profiles, reducing the risk of costly legal action. It is used by Heads of Marketing and In-House Counsel at top brands to avoid lawsuits and potential damages. The service offers a done-for-you audit to highlight violations, deliver reports, and provide ongoing monitoring to ensure brand protection.
Double Check AI
Double Check AI is an AI homework helper designed to assist college students in completing their assignments quickly and accurately. It offers instant answers, detailed explanations, and advanced recognition capabilities for solving complex problems. The tool is undetectable and plagiarism-free, making it a valuable resource for students looking to boost their grades and save time on homework.
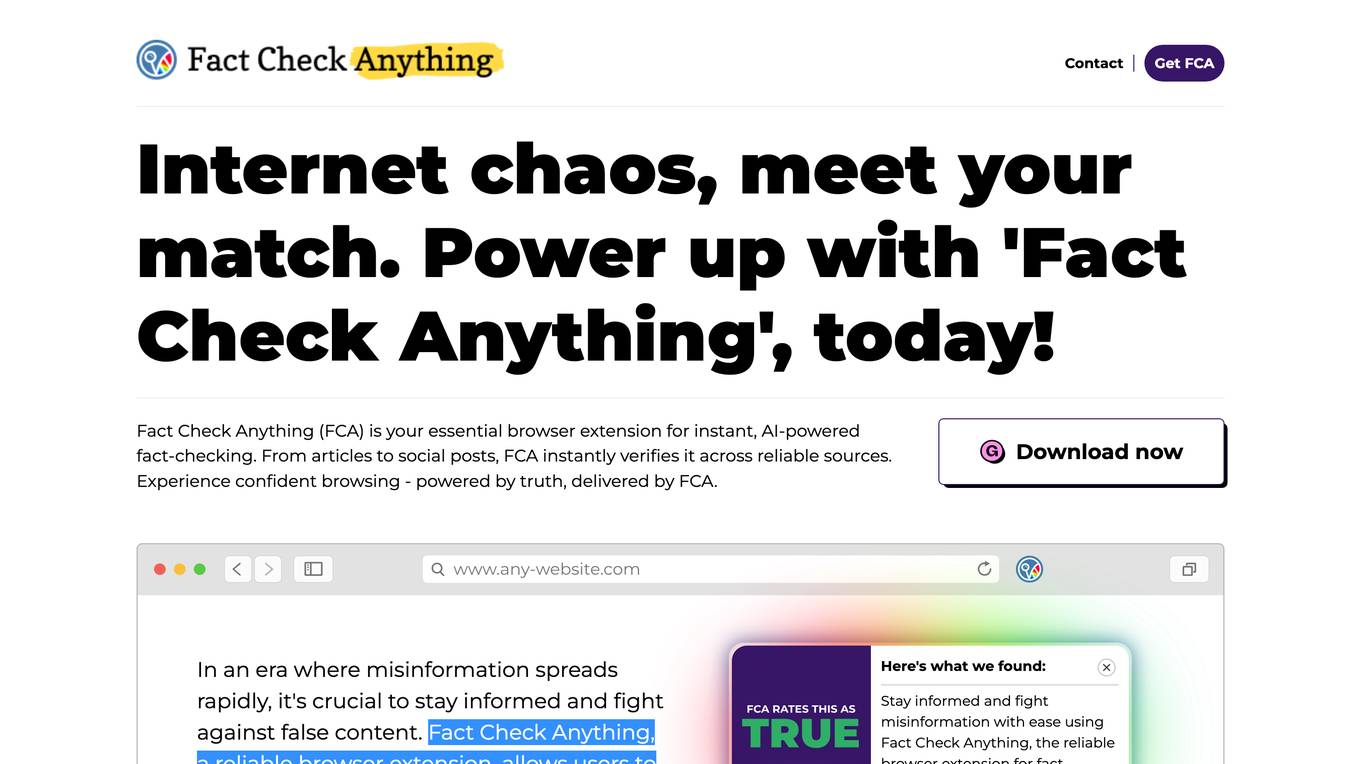
Fact Check Anything
Fact Check Anything (FCA) is a browser extension that allows users to fact-check information on the internet. It uses AI to verify statements and provide users with reliable sources. FCA is available for all browsers using the Chromium engine on Windows or MacOS. It is easy to use and can be used on any website. FCA is a valuable tool for anyone who wants to stay informed and fight against misinformation.

Rizz Check
Rizz Check is a swipe game where users can befriend AI celebrities and ask them on dates. The game is built with Rizz, a library created by boredhead00.
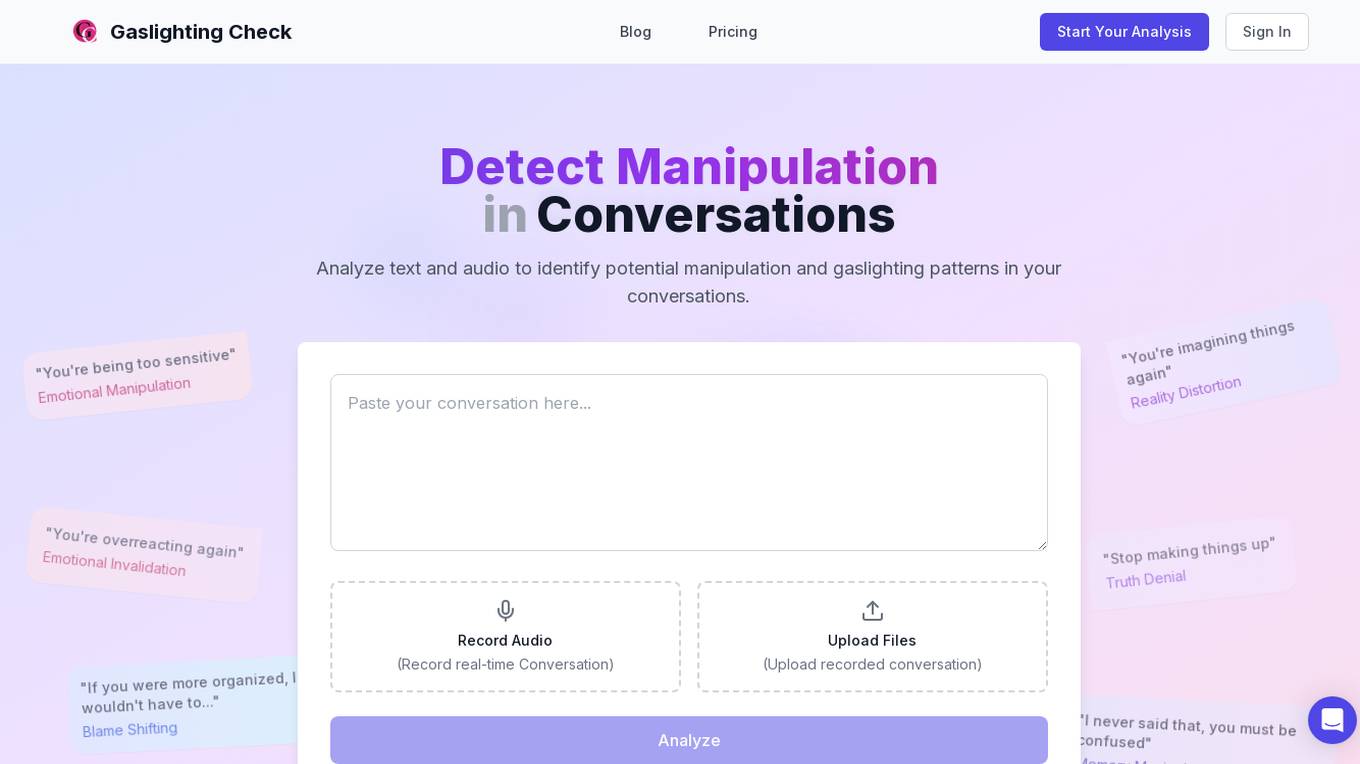
Gaslighting Check
Gaslighting Check is an AI-powered tool designed to help users identify and understand manipulation patterns, particularly gaslighting, in their conversations. The tool offers text and voice analysis capabilities to detect subtle manipulation tactics, providing users with actionable insights and recommendations. Gaslighting Check aims to empower individuals by recognizing and documenting manipulation, ultimately aiding in regaining self-confidence and setting boundaries in various relationships.
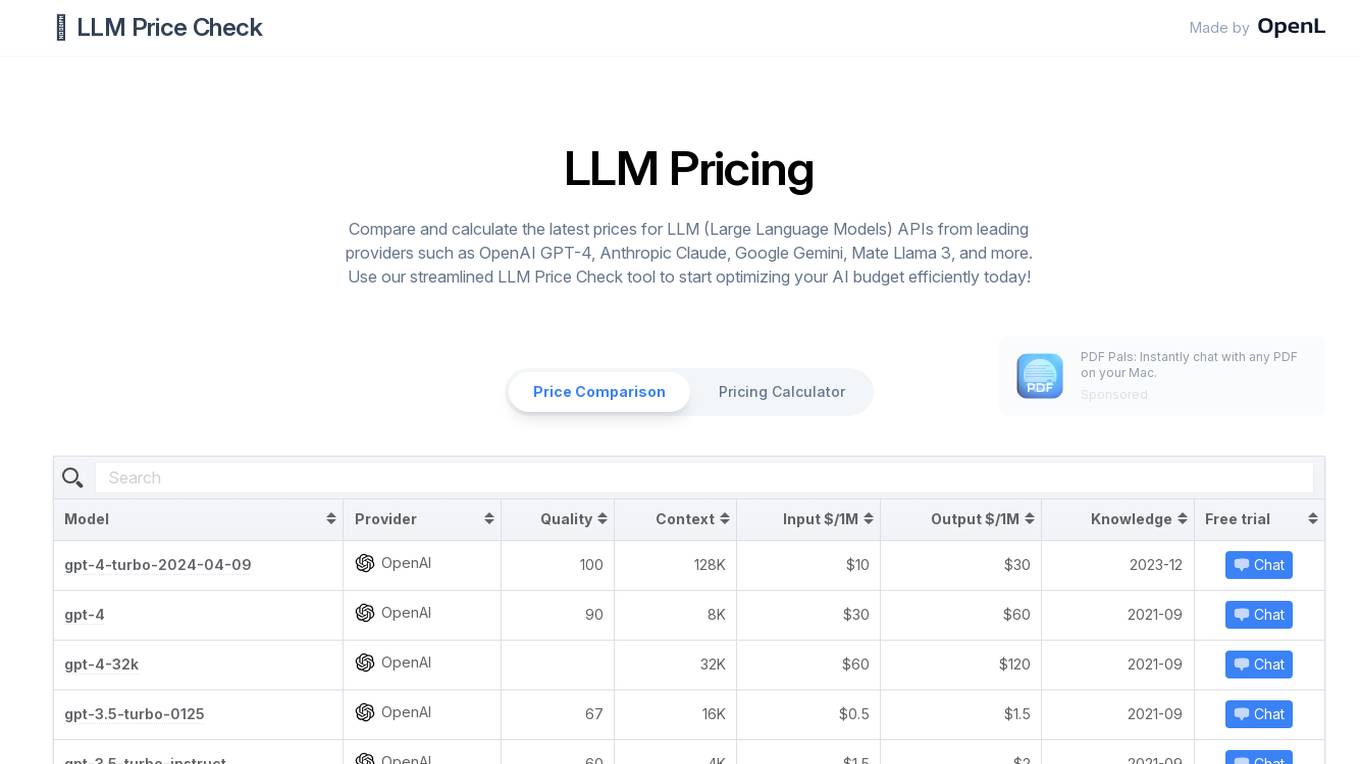
LLM Price Check
LLM Price Check is an AI tool designed to compare and calculate the latest prices for Large Language Models (LLM) APIs from leading providers such as OpenAI, Anthropic, Google, and more. Users can use the streamlined tool to optimize their AI budget efficiently by comparing pricing, sorting by various parameters, and searching for specific models. The tool provides a comprehensive overview of pricing information to help users make informed decisions when selecting an LLM API provider.
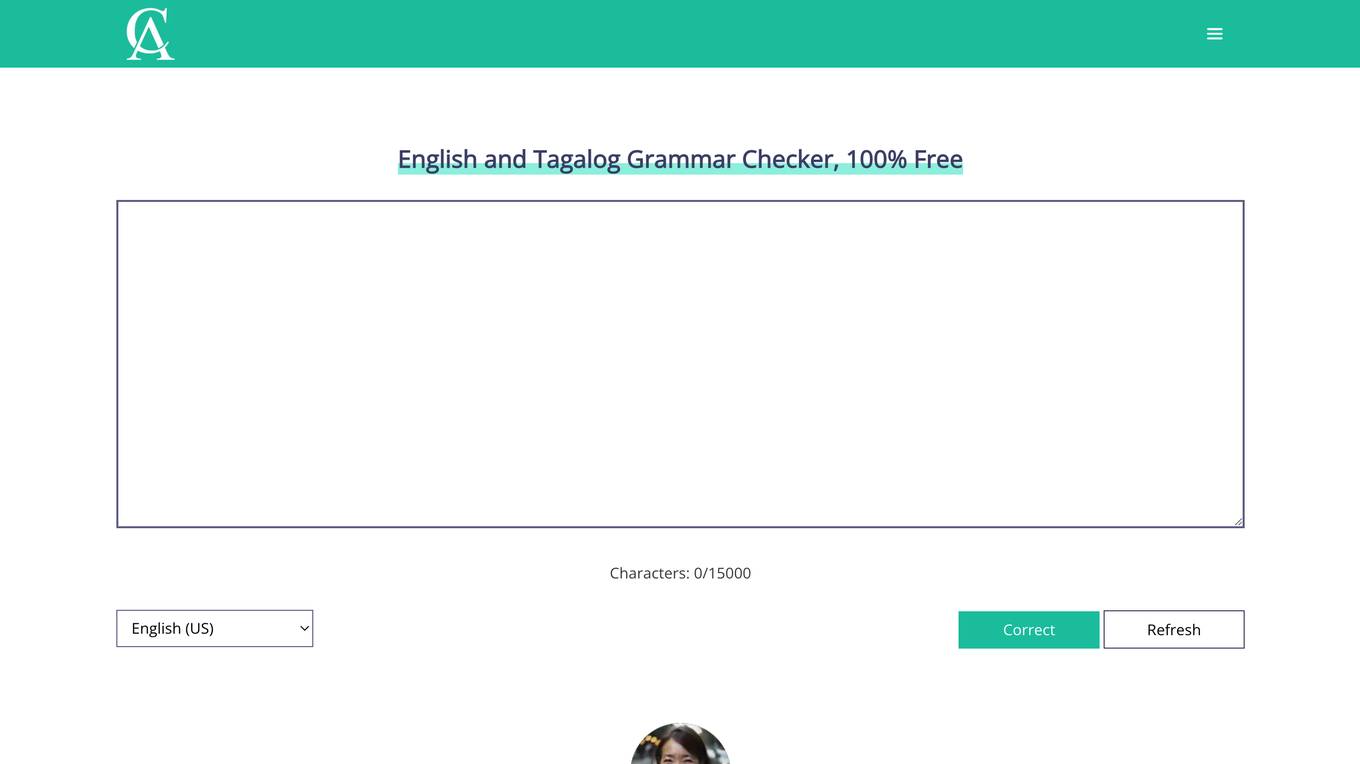
English and Tagalog Grammar Checker
English and Tagalog Grammar Checker is a free online tool that checks your grammar and spelling. It can also help you improve your writing style and avoid common mistakes. The tool is easy to use and can be used by anyone, regardless of their level of English proficiency.
Slick Write
Slick Write is a powerful, free AI application designed to help users check their writing for grammar errors, potential stylistic mistakes, and other features of interest. It goes beyond simple spell checking to teach users effective writing habits. Whether you're a blogger, novelist, SEO professional, or student, Slick Write can assist in improving your content's impact, readability, and overall quality.
Is This Image NSFW?
This website provides a tool that allows users to check if an image is safe for work (SFW) or not. The tool uses Stable Diffusion's safety checker, which can be used with arbitrary images, not just AI-generated ones. Users can upload an image or drag and drop it onto the website to check if it is SFW.
Filtir
Filtir is a fact-checking ChatGPT Plugin that helps assess the accuracy of factual claims in written text. It offers a way to verify claims by providing evidence to support or flag them as unsupported. Filtir aims to combat misinformation by leveraging AI technology to analyze text and identify verifiable facts.
PimEyes
PimEyes is an online face search engine that uses face recognition technology to find pictures containing given faces. It is a great tool to audit copyright infringement, protect your privacy, and find people.
Trinka
Trinka is an AI-powered English grammar checker and language enhancement writing assistant designed for academic and technical writing. It corrects contextual spelling mistakes and advanced grammar errors by providing writing suggestions in real-time. Trinka helps professionals and academics ensure formal, concise, and engaging writing.
PaperRater
PaperRater is a free online proofreader and plagiarism checker that uses AI to scan essays and papers for errors and assign them an automated score. It offers grammar checking, writing suggestions, and plagiarism detection. PaperRater is accessible, requiring no downloads or signups, and is used by thousands of students every day in over 140 countries.
Trinka
Trinka is an AI-powered English grammar checker and language enhancement writing assistant designed for academic and technical writing. It corrects contextual spelling mistakes and advanced grammar errors by providing writing suggestions in real-time. Trinka helps professionals and academics ensure formal, concise, and engaging writing. Trinka's Enterprise solutions come with unlimited access and great customization options to all of Trinka's powerful capabilities.
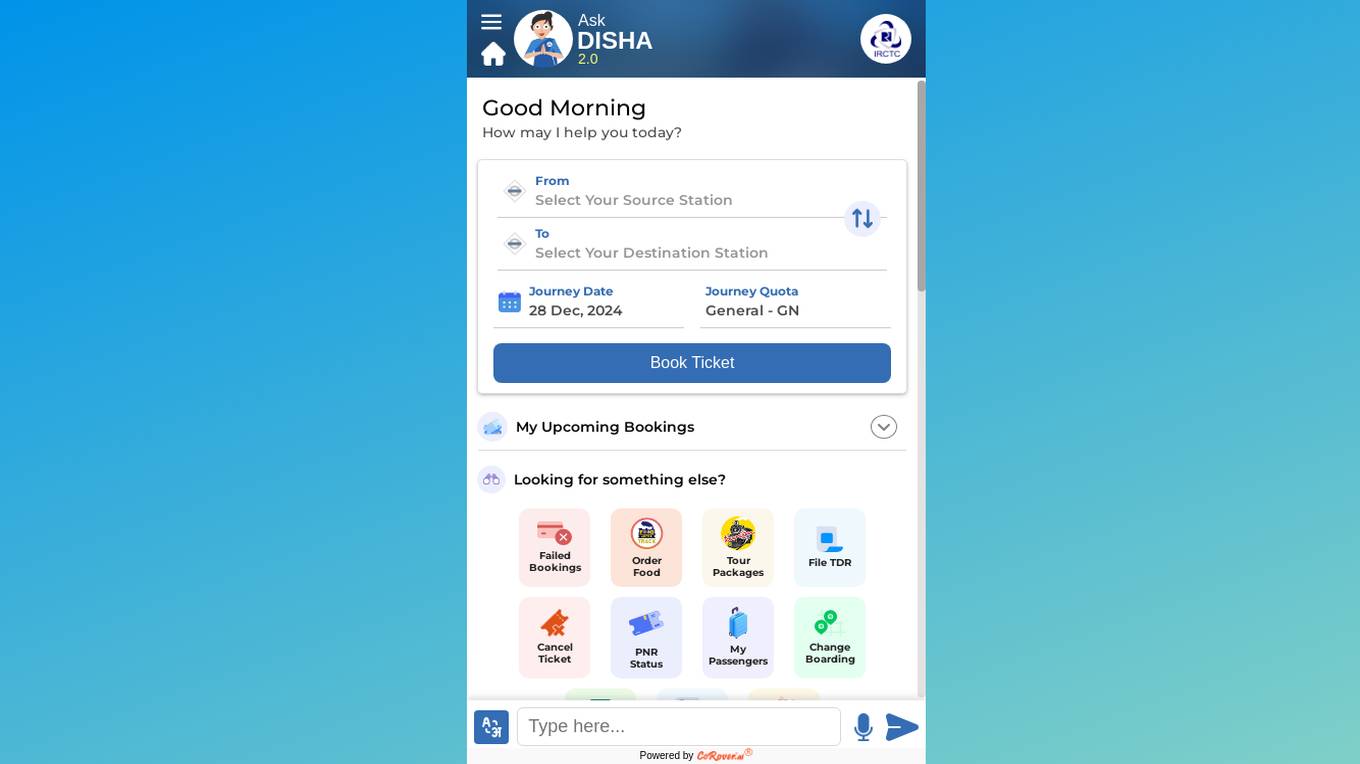
CoRover.ai
CoRover.ai is an AI-powered chatbot designed to help users book train tickets seamlessly through conversation. The chatbot, named AskDISHA, is integrated with the IRCTC platform, allowing users to inquire about train schedules, ticket availability, and make bookings effortlessly. CoRover.ai leverages artificial intelligence to provide personalized assistance and streamline the ticket booking process for users, enhancing their overall experience.
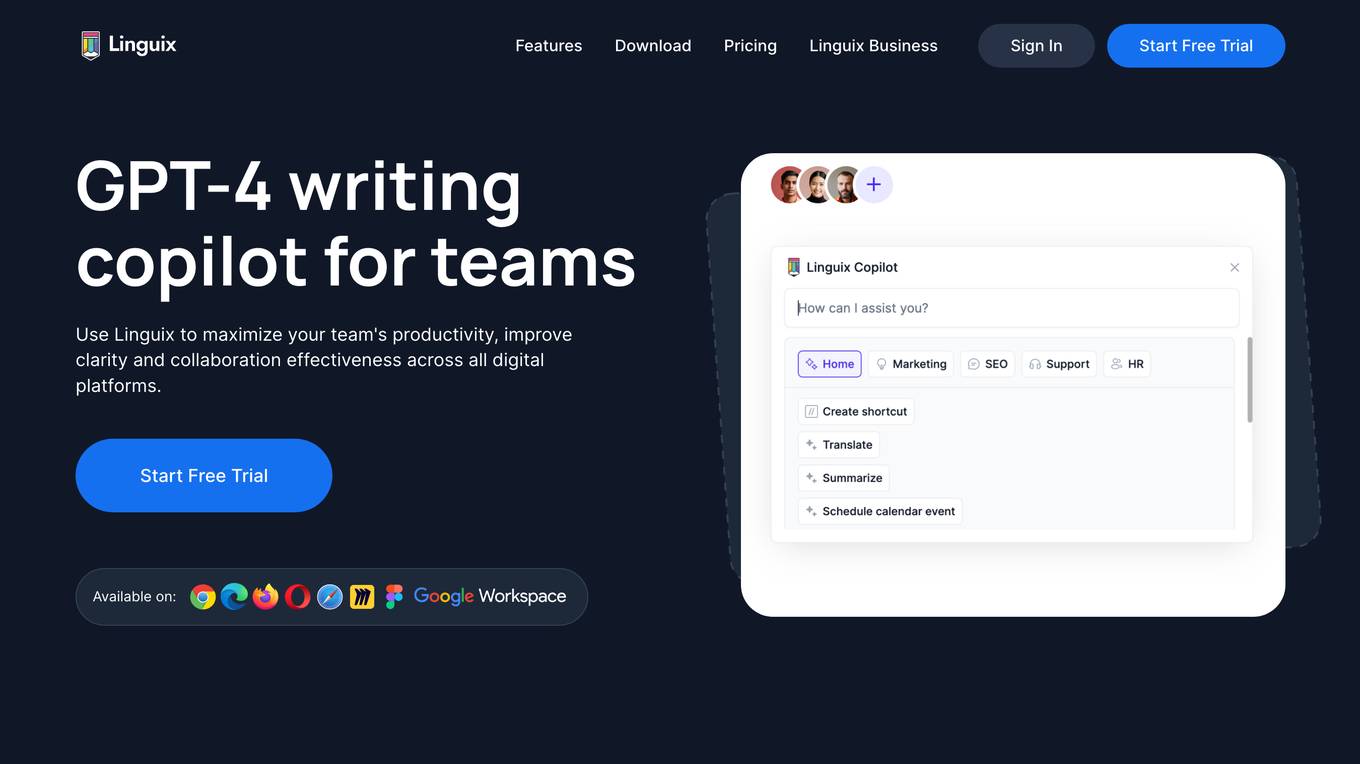
Linguix
Linguix is a GPT-4 writing and productivity copilot for teams. It uses artificial intelligence to improve grammar, spelling, and style, and to help users write more clearly and effectively. Linguix is available as a browser extension and a web editor, and it can be used with a variety of online platforms, including Gmail, Google Docs, and OpenAI. Linguix is trusted by over 310,000 users, including Google Chrome Store Featured App, Edge Store Featured App, Product Hunt Top #1 writing assistant, G2 reviews website Top proofreading tool, and Linguix for Figma Featured App.

BoldVoice Accent Oracle
BoldVoice Accent Oracle is an AI-powered application designed to help users improve their American English accent. By analyzing users' speech patterns, it can accurately guess their native language within 30 seconds. The app provides personalized training to enhance pronunciation and intonation, aiming to help users sound more like native English speakers. BoldVoice Accent Oracle is a user-friendly tool that offers a fun and interactive way to work on accent reduction and language proficiency.
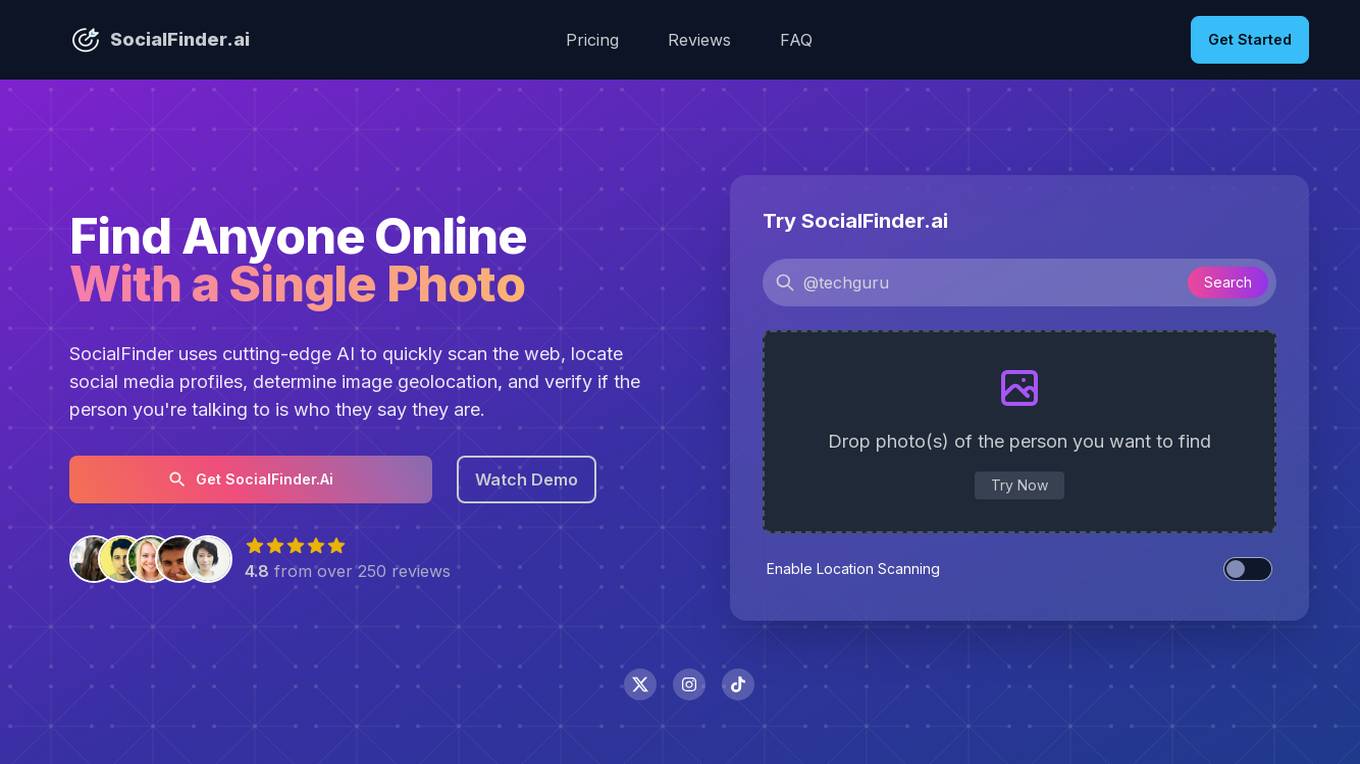
SocialFinder.ai
SocialFinder.ai is an AI-powered tool that enables users to find anyone online with a single photo. The tool uses cutting-edge AI technology to scan the web, locate social media profiles, determine image geolocation, and verify the identity of individuals. It helps users quickly and effectively find someone's digital footprint, making it a valuable resource for various fields, including investigations, background checks, and event planning.
0 - Open Source AI Tools
20 - OpenAI Gpts
Credit Score Check
Guides on checking and monitoring credit scores, with a financial and informative tone.
Backloger.ai - Requirements Health Check
Drop in any requirements ; I'll reduces ambiguity using requirement health check
Website Worth Calculator - Check Website Value
Calculate website worth by analyzing monthly revenue, using industry-standard valuation methods to provide approximate, informative value estimates.
News Bias Corrector
Balances out bias and researches live reports to give you a more balanced view (Paste in the text you want to check)

Service Rater
Helps check and provide feedback on service providers like contractors and plumbers.
Are You Weather Dependent or Not?
A mental health self-check tool assessing weather dependency. Powered by WeatherMind
AI Essay Writer
ChatGPT Essay Writer helps you to write essays with OpenAI. Generate Professional Essays with Plagiarism Check, Formatting, Cost Estimation & More.

Biblical Insights Hub & Navigator
Provides in-depth insights based on familiarity with the historical & cultural context of biblical times including an understanding of theological concepts. It's a Bible Scholar in your pocket!!! Verify Before You Trust (VBYT): Always Double-Check ChatGPT's Insights!