Best AI tools for< Check Document Quality >
20 - AI tool Sites
Rozetta AI Translation
Rozetta is a leading company in Japan specializing in AI automatic translation services. They offer a wide range of AI products tailored to specific purposes and challenges, such as document management, file translation, multilingual chat, and more. With a focus on industrial translation, Rozetta's AI technology, developed through experience in the field, aims to support business growth by providing high-quality and efficient translation solutions. Their services cater to various industries, including pharmaceuticals, manufacturing, legal, patents, and finance, offering features like automatic document generation, high-precision AI translation with strong domain-specific terminology support, and real-time transcription and translation of audio content. Rozetta's AI translation tools are designed to streamline foreign language tasks, reduce translation costs, and enhance business efficiency in a secure environment.
Paperpal
Paperpal is an AI-powered academic writing tool that provides real-time language suggestions, plagiarism detection, and translation services to help students, researchers, and publishers improve the quality of their writing. It is designed to enhance academic writing by offering subject-specific language suggestions, paraphrasing tools, and AI-powered writing assistance.
AIDP
AIDP is a comprehensive platform that helps you find and remove the fingerprints of AI in documents. It includes automatic and manual tools for revising content that was written by ChatGPT and other AI models. With AIDP, you can: * Detect and wipe the traces of AI instantly. * See what triggers AI detection. * Get suggestions for wording changes and rewrites. * Make AI sound human. * Get a tone analysis to determine how your document sounds. * Find and wipe AI from any document.
Decopy AI Content Detector
Decopy AI Content Detector is an AI tool designed to help users determine if a given text was written by a human or generated by AI. It accurately identifies AI-generated, paraphrased, and human-written content. The tool offers features such as AI content highlighting, superior detection accuracy, user-friendly interface, free AI detection, instant access without sign-up, and guaranteed privacy. Users can utilize the AI Detector for tasks like academic integrity checks, content creation, journalism verification, publishing standards maintenance, SEO content uniqueness, social media reliability checks, legal document originality verification, and corporate training material quality assurance.
Yomu AI
Yomu is an AI-powered writing assistant designed to help users with academic writing tasks such as writing essays and papers. It offers features like an intelligent Document Assistant, AI autocomplete, paper editing tools, citation tool, plagiarism checker, and more. Yomu aims to simplify the academic writing process by providing AI-powered assistance to enhance writing quality and originality.
Autodraft
Autodraft is an AI-powered writing assistant that helps you create high-quality content quickly and easily. With Autodraft, you can generate text, translate languages, summarize documents, and more. Autodraft is the perfect tool for anyone who wants to improve their writing skills or save time on content creation.
ProRes.ai
ProRes.ai is an AI-enhanced resume building tool that helps users create tailored, ATS-friendly resumes and cover letters quickly and effortlessly. By leveraging artificial intelligence, ProRes streamlines the process of generating high-quality application documents, saving time and increasing the chances of landing job interviews. The tool offers lifetime access with a one-time payment, ensuring users have unlimited use of AI content generation tools to create, download, and modify resumes and cover letters.
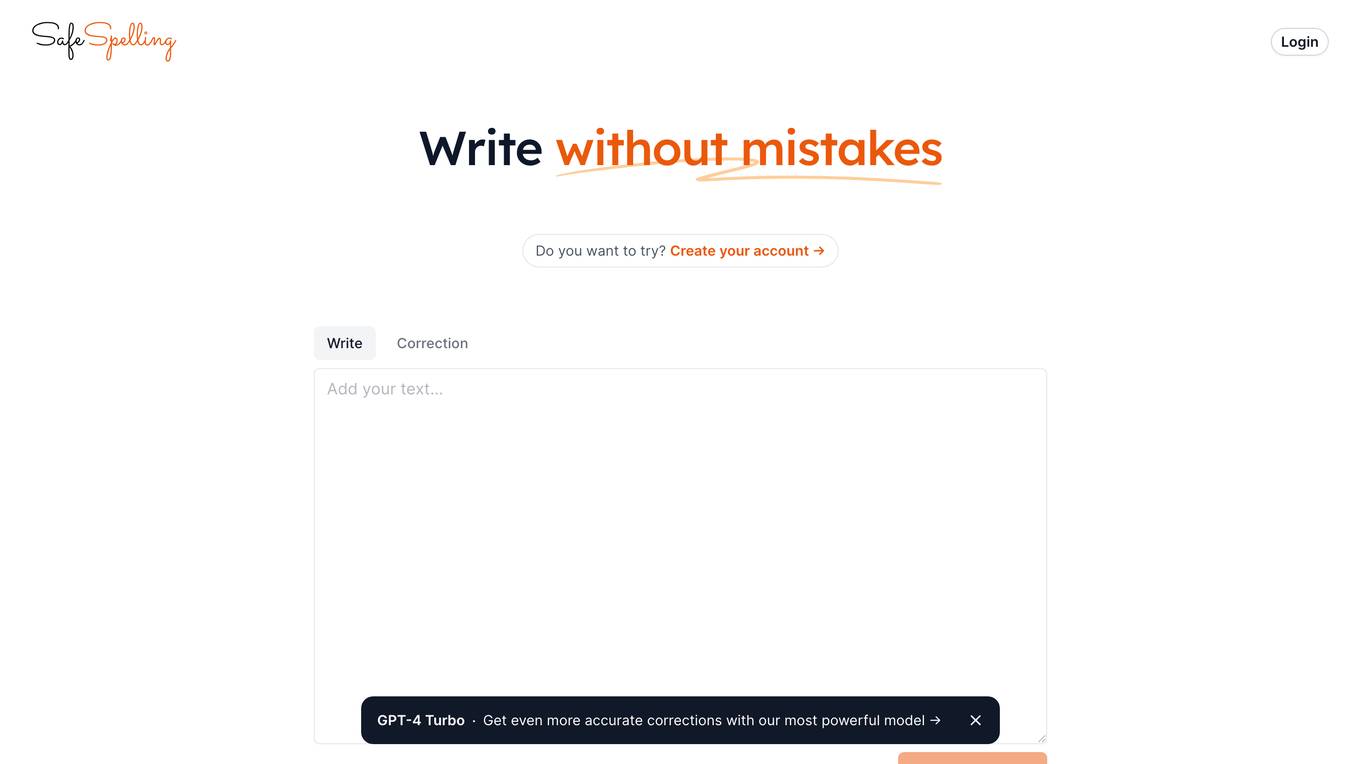
SafeSpelling
SafeSpelling is an AI-powered tool designed to help users write without mistakes. It provides users with the ability to input text and receive corrections for any spelling errors. The tool compares the original text with the corrected text, highlighting mistakes and offering suggestions for improvement. SafeSpelling aims to enhance the writing experience by ensuring that users can produce error-free content effortlessly.
HIX.AI
HIX.AI is an all-in-one AI writing copilot that provides over 120 AI writing tools to enhance your writing experience. It offers a wide range of tools for various writing tasks, including article writing, email composition, paraphrasing, summarizing, grammar checking, and more. HIX.AI is powered by advanced AI technology, including ChatGPT 3.5/4, and supports over 50 languages. It aims to help writers overcome writer's block, improve their writing quality, and save time and effort.
DocVu.AI
DocVu.AI is an intelligent mortgage document processing solution that revolutionizes the handling of intricate documents with advanced AI/ML technologies. It automates complex operational rules, streamlining business functions seamlessly. DocVu.AI offers a holistic approach to digital transformation, ensuring businesses remain agile, competitive, and ahead in the digital race. It provides tailored solutions for invoice processing, customer onboarding, loans and mortgage processing, quality checks and audit, records digitization, and insurance claim processing.
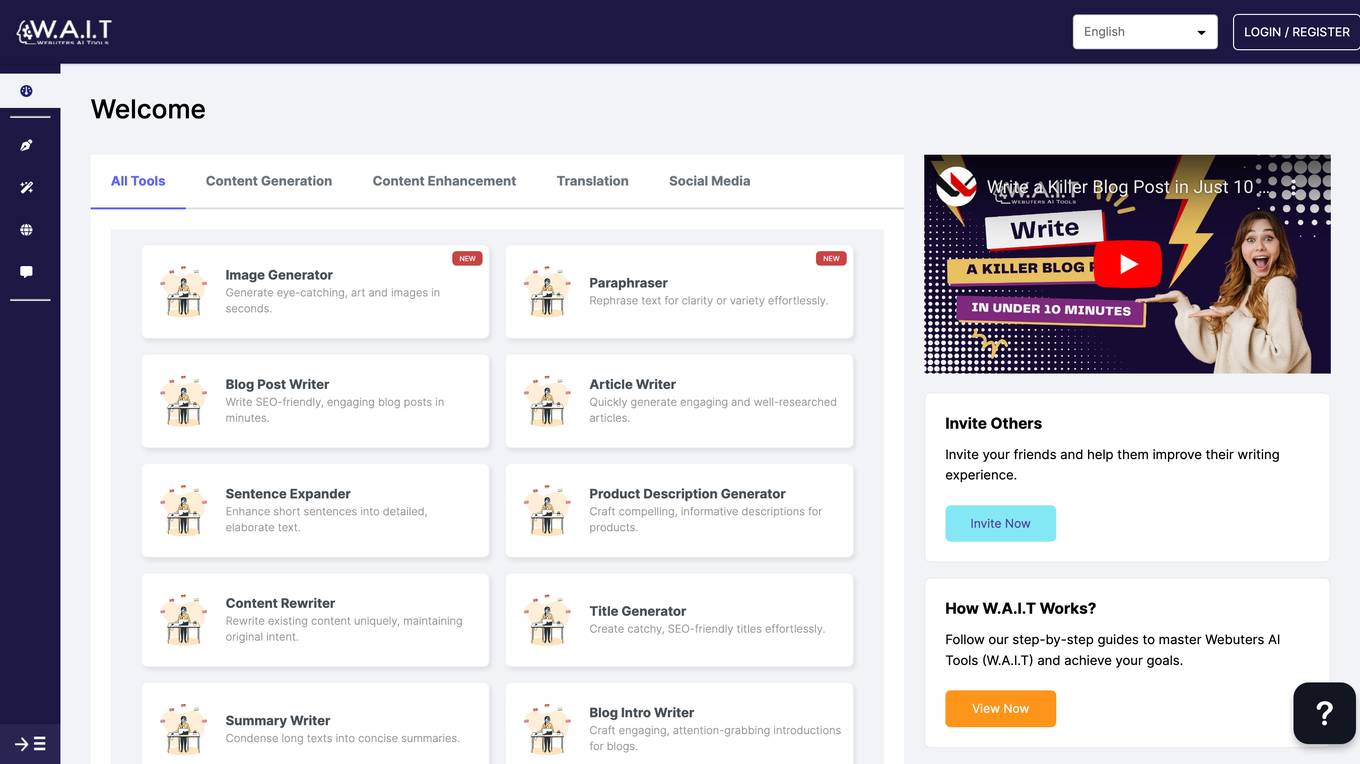
W.A.I.T
W.A.I.T is a web-based AI-powered writing assistant that helps users improve their writing skills. It offers a range of features, including content generation, content enhancement, translation, and social media assistance. W.A.I.T is designed to be user-friendly and accessible to writers of all levels.
Texthelper
Texthelper is an AI-powered text correction tool designed to assist users in identifying and correcting errors in their written content. Users can input text, which will be analyzed by the tool's AI algorithms to detect and fix mistakes. The tool aims to enhance the overall quality and accuracy of written communication by providing quick and efficient error detection and correction. Texthelper is user-friendly and suitable for individuals, students, professionals, and anyone looking to improve the correctness of their written text.
Multilings
Multilings is a neural AI-based machine learning service that provides human-like output for text translation, content writing, plagiarism detection, and voice translation. It is designed for marketers, content writers, researchers, students, and anyone who needs to create high-quality content quickly and efficiently. Multilings offers a range of tools, including a writing assistant, language translator, plagiarism checker, citation generator, and AI chatbot. These tools are powered by advanced machine learning and artificial intelligence algorithms that can generate natural-sounding text, translate languages accurately, detect plagiarism effectively, and provide helpful writing suggestions.
AI Writer
AI Writer is a free text editor tool that incorporates AI features to assist users in writing and editing content. The tool provides functionalities similar to Notion, allowing users to create and manage text-based documents efficiently. With AI Writer, users can benefit from advanced AI capabilities to enhance their writing experience, improve productivity, and generate high-quality content. The tool is designed to cater to a wide range of users, including writers, bloggers, students, and professionals, by offering intuitive features and a user-friendly interface.
Bibit AI
Bibit AI is a real estate marketing AI designed to enhance the efficiency and effectiveness of real estate marketing and sales. It can help create listings, descriptions, and property content, and offers a host of other features. Bibit AI is the world's first AI for Real Estate. We are transforming the real estate industry by boosting efficiency and simplifying tasks like listing creation and content generation.
HireFlow.net
HireFlow.net is an AI-powered platform designed to optimize resumes and enhance job prospects. The website offers a free resume checker that leverages advanced Artificial Intelligence technology to provide personalized feedback and suggestions for improving resumes. Users can also access features such as CV analysis, cover letter and resignation letter generators, and expert insights to stand out in the competitive job market.
Artsyl Technologies
Artsyl Technologies specializes in revolutionizing document processing through advanced AI-powered automation. Their flagship intelligent process automation platform, docAlpha, utilizes cutting-edge AI, RPA, and machine learning technologies to automate and optimize document workflows. By seamlessly integrating with organizations' ERP or Document Management Systems, docAlpha ensures enhanced efficiency, accuracy, and productivity across the entire business process.
MaxAI.me
MaxAI.me is a productivity tool that provides users with access to various AI models, including ChatGPT, Claude, Gemini, and Bard, through a single platform. It offers a range of AI-powered features such as AI chat, AI rewriter, AI quick reply, AI summary, AI search, AI art, and AI translator. MaxAI.me is designed to help users save time and improve their productivity by automating repetitive tasks and providing instant access to AI-generated content and insights.
Veriff
Veriff is an AI-powered identity verification platform that combines automation and human expertise to detect deepfakes, prevent fraud, and onboard verified customers globally. The platform offers various verification services such as identity & document verification, proof of address, database verification, age validation, AML screening, biometric authentication, liveness detection, age estimation, fraud protection, and fraud intelligence solutions. Veriff helps businesses restore trust on the internet by providing fast, accurate, and secure identity verification services that comply with global regulations and standards.
Plag
Plag is an AI-powered platform that focuses on academic integrity, studies, and artificial intelligence. It offers solutions for students, educators, universities, and businesses in the areas of plagiarism detection, plagiarism removal, text formatting, and proofreading. The platform utilizes multilingual artificial intelligence technology to provide users with advanced tools to enhance their academic work and ensure originality.
0 - Open Source AI Tools
20 - OpenAI Gpts
Complaint Assistant
Creates conversational, effective complaint letters, offers document formatting.

The Riggorous Guide to Structure
Irritating Northern advisor on UK building regs for structure. Based on Oliver Rigg and Approved Document A
Conveyance AI
ConveyanceAI streamlines property conveyancing, offering automated legal document handling, compliance guidance, and efficient workflow management for UK and European lawyers and conveyancers
CA Revocable Trust Wizard
Generate a CA Revocable Trust with this friendly guide, template & check lists
AR 25-50, Preparing and Managing Correspondence
Can accurately answer questions about AR 25-50 and assist in refining documents to ensure they adhere to the Army guidelines for formatting, style, and protocol.
Correcteur d'orthographe Français gratuit
Je suis spécialisé dans la correction d'orthographe et de la grammaire de vos écrits. 🔎
Readability and Accessibility Coach
Ask about your documents to see how you could make them easier to read for everyone and more accessible for people with disabilities. NOTE: It does not always get everything right on the first go. Feel free to hit the regenerate button or ask for more info if you want to get richer feedback.
French Speed Typist
Veuillez taper aussi vite que possible, ou vous pouvez coller un texte mal rédigé. Je le réviserai ensuite dans un format correctement structuré
Academic Reports Buddy
Give me the name of a student and what you want to say and I'll help you write your reports. Upload your comments and I will proof read them.