Best AI tools for< Benchmark Your Saas Product >
20 - AI tool Sites
SaaSlidator
SaaSlidator is an AI-powered application designed to help users validate their project ideas efficiently and effectively. By providing a project name and description, SaaSlidator offers valuable insights to support decision-making on whether to proceed with building and launching a minimum viable product (MVP). The platform leverages AI algorithms to analyze data, offer market demand insights, competition analysis, and assess the feasibility of project ideas. With features like rapid validation, monetization suggestions, and benchmarking data, SaaSlidator aims to streamline the idea validation process and empower users to make informed decisions for successful project development.
Junbi.ai
Junbi.ai is an AI-powered insights platform designed for YouTube advertisers. It offers AI-powered creative insights for YouTube ads, allowing users to benchmark their ads, predict performance, and test quickly and easily with fully AI-powered technology. The platform also includes expoze.io API for attention prediction on images or videos, with scientifically valid results and developer-friendly features for easy integration into software applications.
Particl
Particl is an AI-powered platform that automates competitor intelligence for modern retail businesses. It provides real-time sales, pricing, and sentiment data across various e-commerce channels. Particl's AI technology tracks sales, inventory, pricing, assortment, and sentiment to help users quickly identify profitable opportunities in the market. The platform offers features such as benchmarking performance, automated e-commerce intelligence, competitor research, product research, assortment analysis, and promotions monitoring. With easy-to-use tools and robust AI capabilities, Particl aims to elevate team workflows and capabilities in strategic planning, product launches, and market analysis.

Report Card AI
Report Card AI is an AI Writing Assistant that helps users generate high-quality, unique, and personalized report card comments. It allows users to create a quality benchmark by writing their first draft of comments with the assistance of AI technology. The tool is designed to streamline the report card writing process for teachers, ensuring error-free and eloquently written comments that meet specific character count requirements. With features like 'rephrase', 'Max Character Count', and easy exporting options, Report Card AI aims to enhance efficiency and accuracy in creating report card comments.

Waikay
Waikay is an AI tool designed to help individuals, businesses, and agencies gain transparency into what AI knows about their brand. It allows users to manage reputation risks, optimize strategic positioning, and benchmark against competitors with actionable insights. By providing a comprehensive analysis of AI mentions, citations, implied facts, and competition, Waikay ensures a 360-degree view of model understanding. Users can easily track their brand's digital footprint, compare with competitors, and monitor their brand and content across leading AI search platforms.
Am I On AI
Am I On AI is a platform designed to help businesses improve their visibility in AI responses, specifically focusing on ChatGPT. It provides personalized action plans to enhance brand visibility, track mentions, identify source websites, benchmark against competitors, and execute strategic improvements. The platform offers features such as AI brand monitoring, competitor rank analysis, sentiment analysis, citation tracking, and actionable insights. With a user-friendly interface and measurable results, Am I On AI is a valuable tool for marketers, SEO professionals, and agencies looking to optimize their AI visibility.
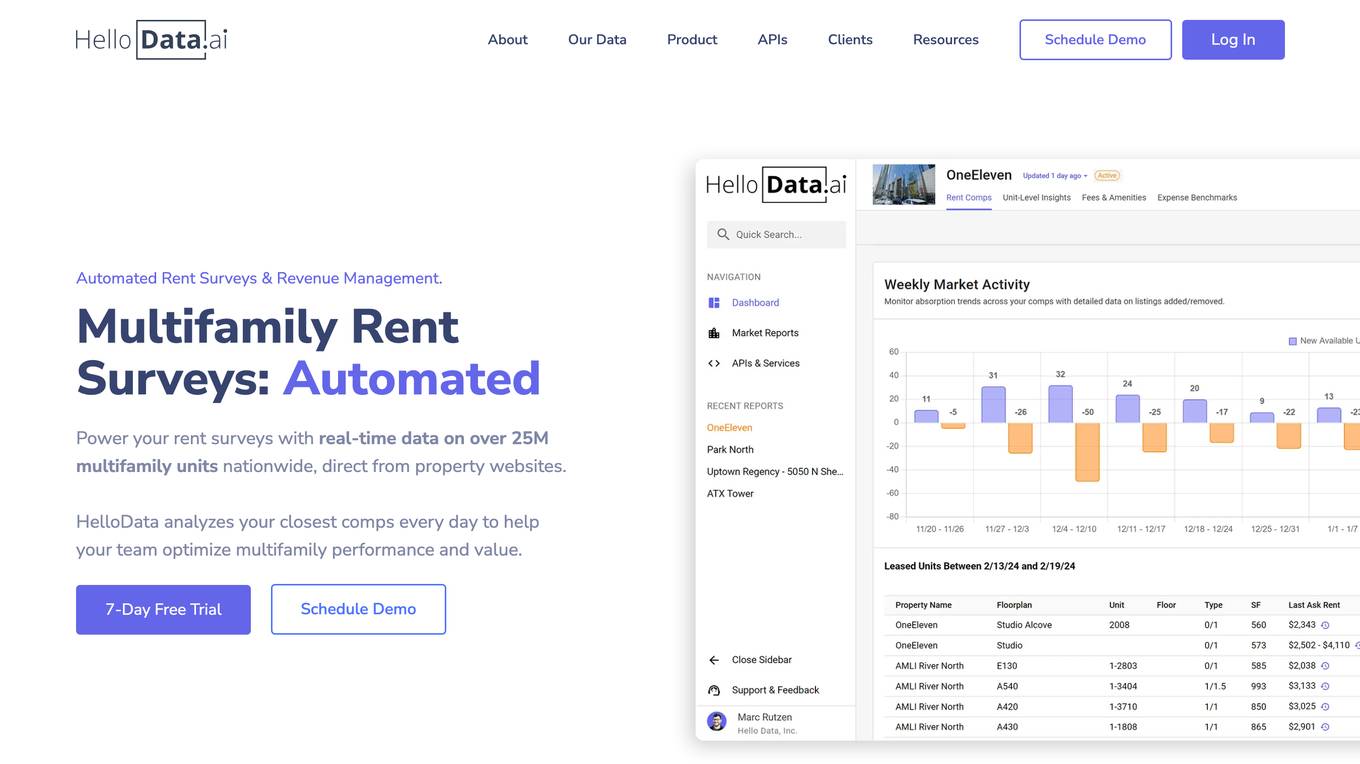
HelloData
HelloData is an AI-powered multifamily market analysis platform that automates market surveys, unit-level rent analysis, concessions monitoring, and development feasibility reports. It provides financial analysis tools to underwrite multifamily deals quickly and accurately. With custom query builders and Proptech APIs, users can analyze and download market data in bulk. HelloData is used by over 15,000 multifamily professionals to save time on market research and deal analysis, offering real-time property data and insights for operators, developers, investors, brokers, and Proptech companies.
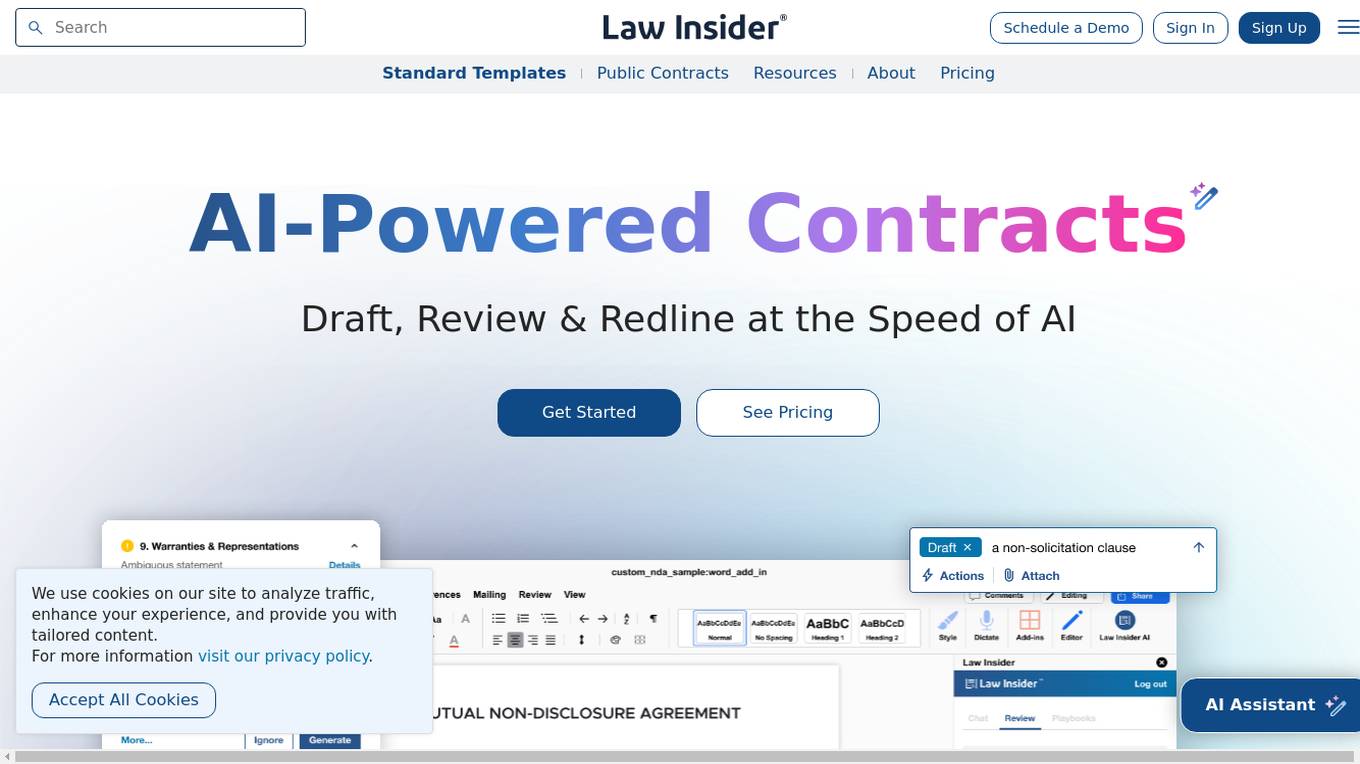
Law Insider
Law Insider is an AI-powered platform that offers contract drafting, review, and redlining services at the speed of AI. With over 10,000 customers worldwide, Law Insider provides standard templates, public contracts, and resources for legal professionals. Users can search for sample contracts and clauses using the Law Insider database or generate original drafts with the help of their AI Assistant. The platform also allows users to review and redline contracts directly in Microsoft Word, ensuring compliance with industry standards and expert playbooks. Law Insider's features include AI-powered contract review and redlining, benchmarking against the Law Insider Index, playbook builder, and upcoming AI clause drafting with trusted validation. Users can access the world's largest public contract database and watch tutorial videos to better understand the platform's capabilities.
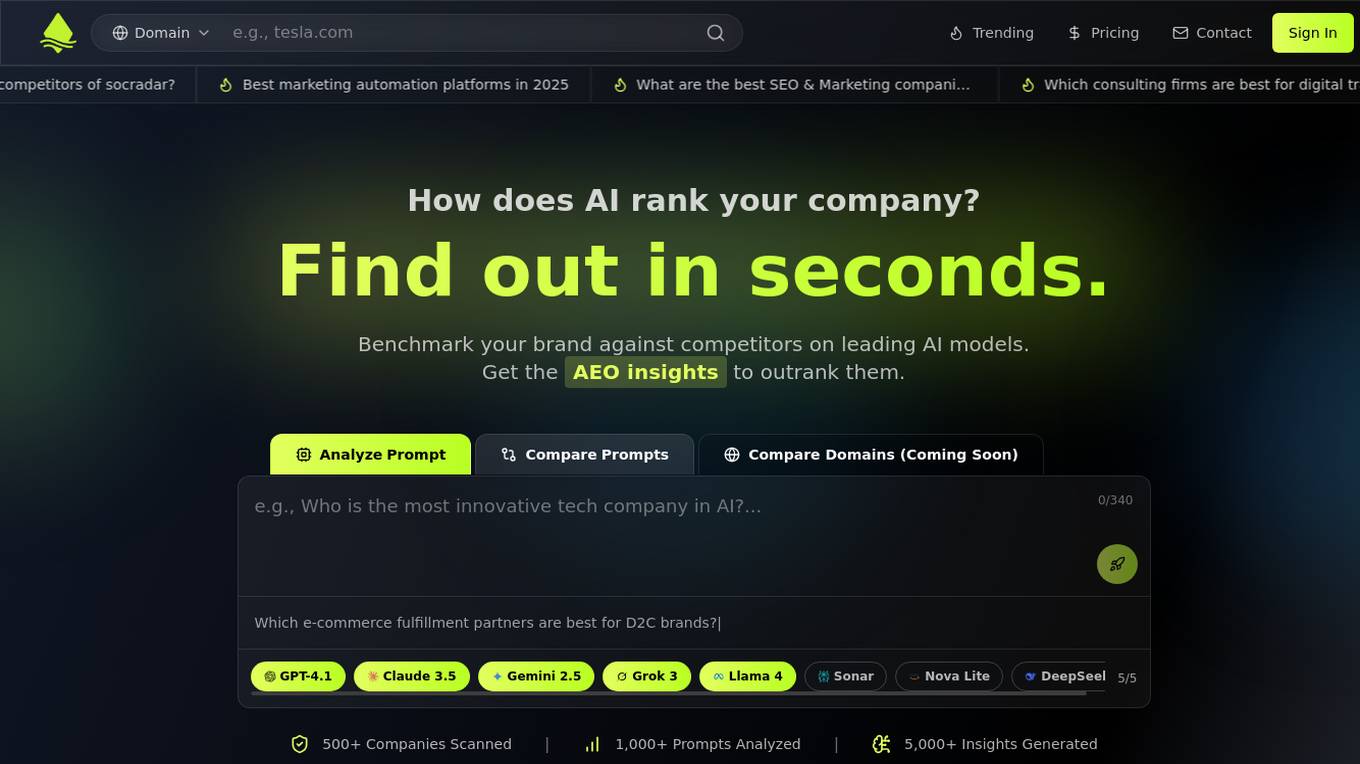
Spotrank.ai
Spotrank.ai is an AI-powered platform that provides advanced analytics and insights for businesses and individuals. It leverages artificial intelligence algorithms to analyze data and generate valuable reports to help users make informed decisions. The platform offers a user-friendly interface and customizable features to cater to diverse needs across various industries. Spotrank.ai is designed to streamline data analysis processes and enhance decision-making capabilities through cutting-edge AI technology.
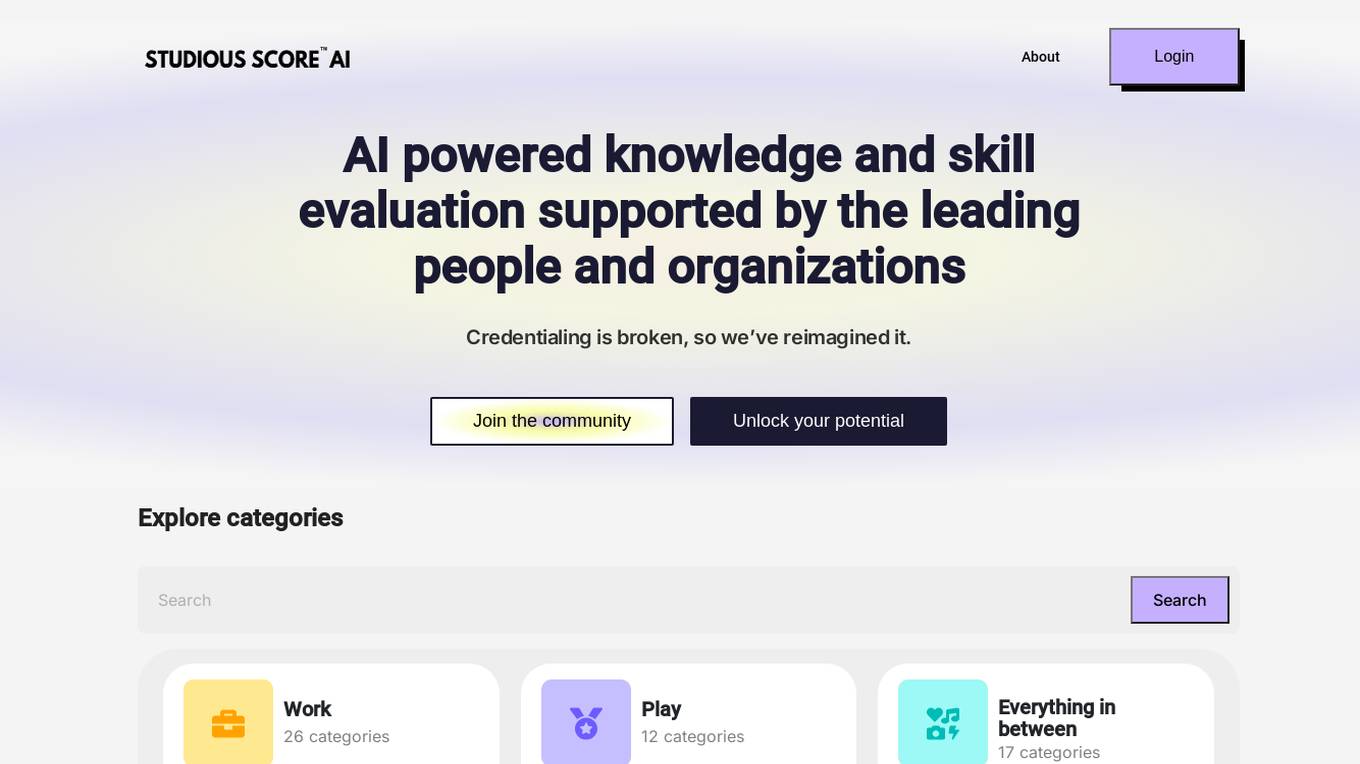
Studious Score AI
Studious Score AI is an AI-powered platform that offers knowledge and skill evaluation services supported by reputable individuals and organizations. The platform aims to revolutionize credentialing by providing a new approach. Studious Score AI is on a mission to establish itself as the global benchmark for assessing skills and knowledge in various aspects of life. Users can explore different categories and unlock their potential through the platform's innovative evaluation methods.
Weavel
Weavel is an AI tool designed to revolutionize prompt engineering for large language models (LLMs). It offers features such as tracing, dataset curation, batch testing, and evaluations to enhance the performance of LLM applications. Weavel enables users to continuously optimize prompts using real-world data, prevent performance regression with CI/CD integration, and engage in human-in-the-loop interactions for scoring and feedback. Ape, the AI prompt engineer, outperforms competitors on benchmark tests and ensures seamless integration and continuous improvement specific to each user's use case. With Weavel, users can effortlessly evaluate LLM applications without the need for pre-existing datasets, streamlining the assessment process and enhancing overall performance.
Seek AI
Seek AI is a generative AI-powered database query tool that helps businesses break through information barriers. It is the #1 most accurate model on the Yale Spider benchmark and offers a variety of features to help businesses modernize their analytics, including auto-verification with confidence estimation, natural language summary, and embedded AI data analyst.

Unify
Unify is an AI tool that offers a unified platform for accessing and comparing various Language Models (LLMs) from different providers. It allows users to combine models for faster, cheaper, and better responses, optimizing for quality, speed, and cost-efficiency. Unify simplifies the complex task of selecting the best LLM by providing transparent benchmarks, personalized routing, and performance optimization tools.
Perspect
Perspect is an AI-powered platform designed for high-performance software teams. It offers real-time insights into team contributions and impact, optimizing developer experience, and rewarding high-performers. With 50+ integrations, Perspect enables visualization of impact, benchmarking performance, and uses machine learning models to identify and eliminate blockers. The platform is deeply integrated with web3 wallets and offers built-in reward mechanisms. Managers can align resources around crucial KPIs, identify top talent, and prevent burnout. Perspect aims to enhance team productivity and employee retention through AI and ML technologies.
Aider
Aider is an AI pair programming tool that allows users to collaborate with Language Model Models (LLMs) to edit code in their local git repository. It supports popular languages like Python, JavaScript, TypeScript, PHP, HTML, and CSS. Aider can handle complex requests, automatically commit changes, and work well in larger codebases by using a map of the entire git repository. Users can edit files while chatting with Aider, add images and URLs to the chat, and even code using their voice. Aider has received positive feedback from users for its productivity-enhancing features and performance on software engineering benchmarks.
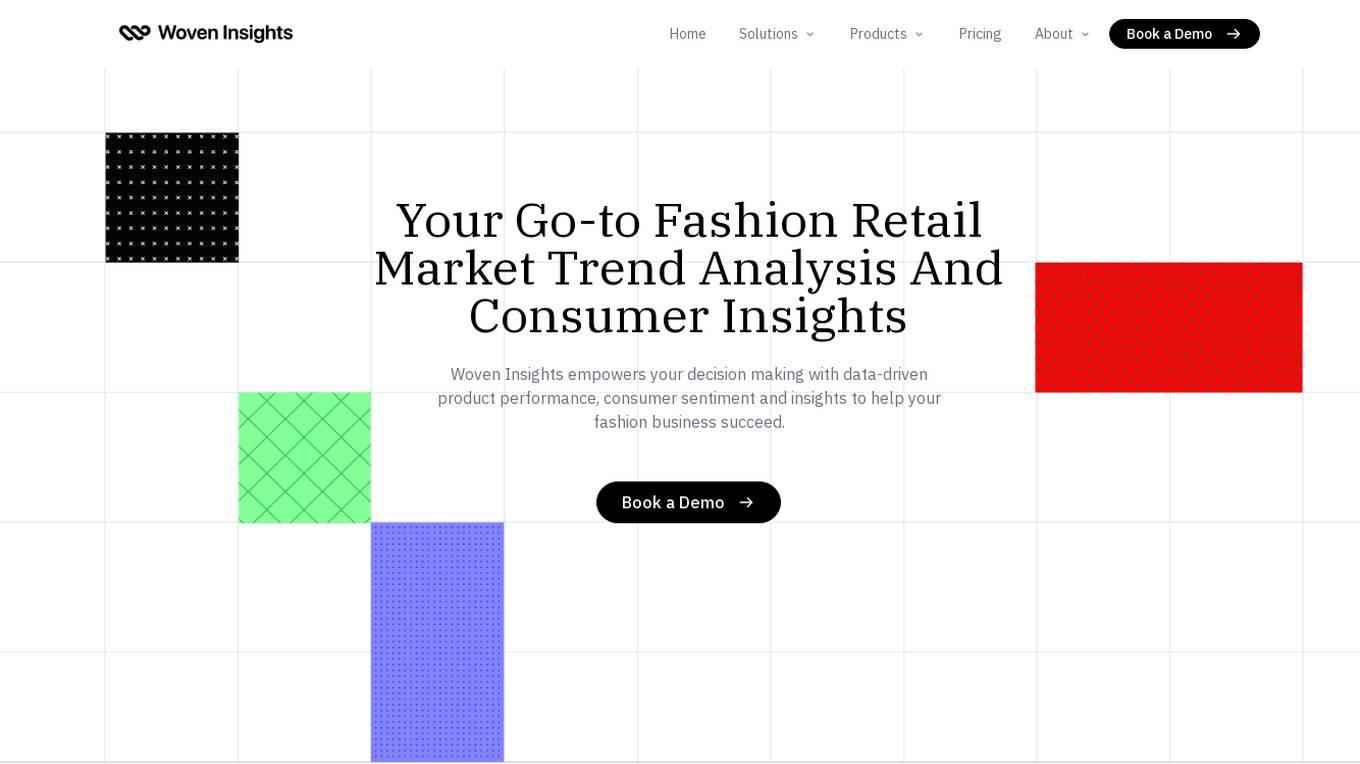
Woven Insights
Woven Insights is an AI-driven Fashion Retail Market & Consumer Insights solution that empowers fashion businesses with data-driven decision-making capabilities. It provides competitive intelligence, performance monitoring analytics, product assortment optimization, market insights, consumer insights, and pricing strategies to help businesses succeed in the retail market. With features like insights-driven competitive benchmarking, real-time market insights, product performance tracking, in-depth market analytics, and sentiment analysis, Woven Insights offers a comprehensive solution for businesses of all sizes. The application also offers bespoke data analysis, AI insights, natural language query, and easy collaboration tools to enhance decision-making processes. Woven Insights aims to democratize fashion intelligence by providing affordable pricing and accessible insights to help businesses stay ahead of the competition.

Frequently.ai
Frequently.ai is an AI-powered tool designed to provide valuable insights and analytics based on customer feedback and reviews. It helps businesses analyze and understand customer sentiments, trends, and preferences to improve their products and services. The tool utilizes advanced natural language processing and machine learning algorithms to extract meaningful data from various sources, such as online reviews and social media comments. With its user-friendly interface and customizable features, Frequently.ai offers a comprehensive solution for businesses looking to enhance their customer experience and make data-driven decisions.

EarningsCall.ai
EarningsCall.ai is an AI-powered tool that provides stock earnings call summaries and insights, saving users hours of reading transcripts. It allows users to compare competitors, analyze trends, and generate their own insights. The tool is designed for business leaders, financial professionals, consultants, and advisors to track competitor earnings, assess market trends, and optimize investment strategies.
INOP
INOP is an impact-driven professional network that uses advanced AI matching algorithms to connect professionals with like-minded individuals, job opportunities, and companies that share their values and interests. The platform offers personalized job alerts, geolocation features, and actionable compensation insights. INOP goes beyond traditional networking platforms by providing rich enterprise-level insights on company culture, values, reputation, and ESG data sets. Users can access salary benchmarks, career path insights, and skills benchmarking to make informed career decisions.
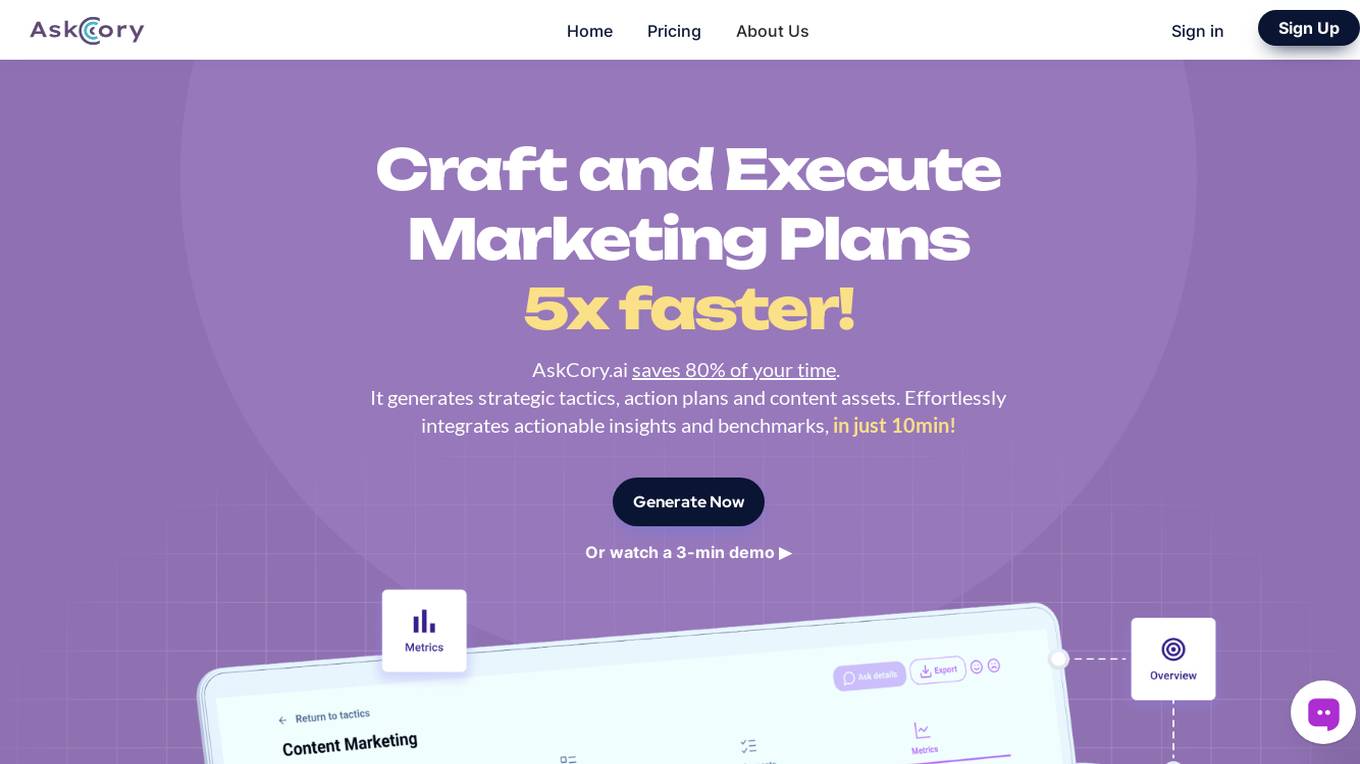
AskCory
AskCory is an AI-powered marketing assistant designed to save time by generating strategic tactics, action plans, and content assets. It effortlessly integrates actionable insights and benchmarks, offering personalized marketing strategies for businesses in just minutes. The platform helps users craft and execute marketing plans 5x faster, saving up to 80% of their time. With AskCory, users can say goodbye to blank page syndrome and generic suggestions, and instead, receive proven tactics based on industry benchmarks. The tool streamlines the task of preparing action plans, allowing users to focus on decision-making and project leadership. AskCory also provides benefits such as improved ROI, streamlined workflows, and data-driven decision-making for busy professionals.
0 - Open Source AI Tools
10 - OpenAI Gpts
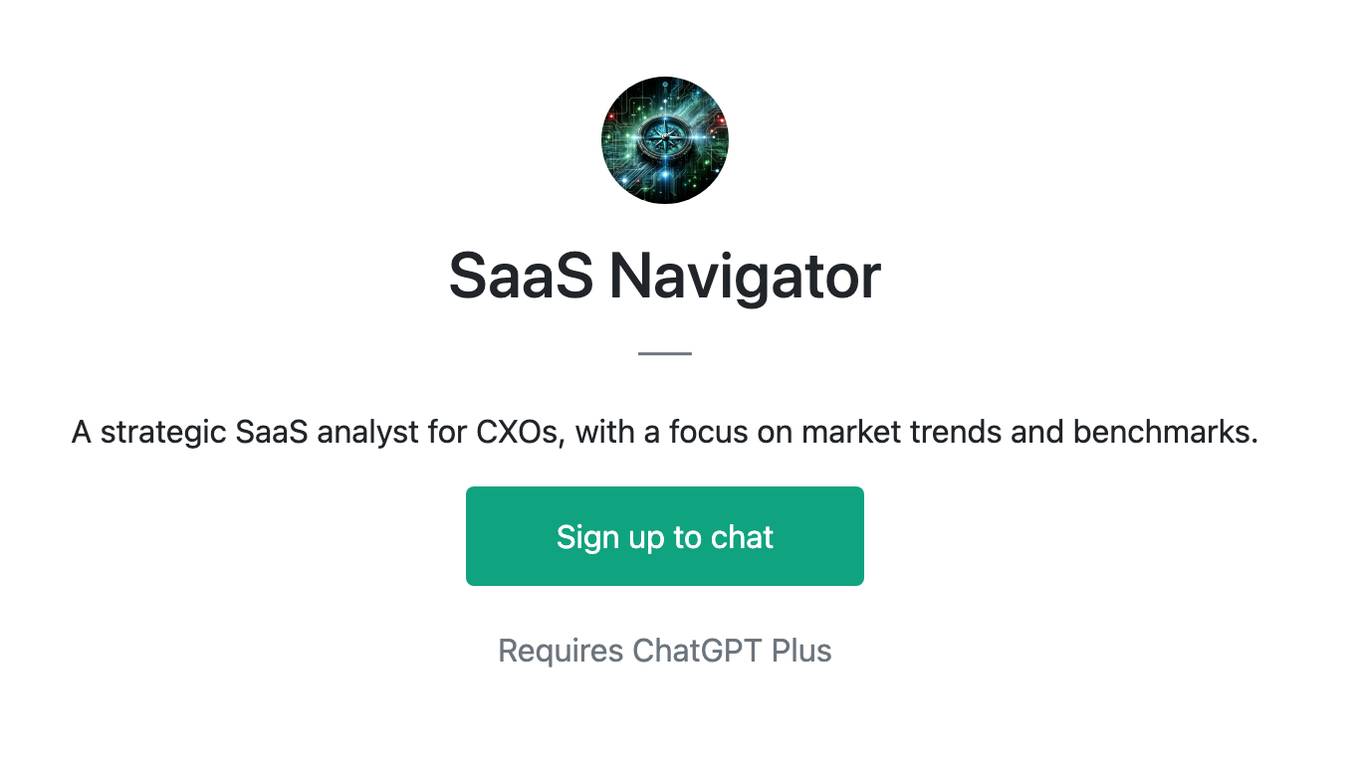
SaaS Navigator
A strategic SaaS analyst for CXOs, with a focus on market trends and benchmarks.

Transfer Pricing Advisor
Guides businesses in managing global tax liabilities efficiently.

HVAC Apex
Benchmark HVAC GPT model with unmatched expertise and forward-thinking solutions, powered by OpenAI

Salary Guides
I provide monthly salary data in euros, using a structured format for global job roles.
Performance Testing Advisor
Ensures software performance meets organizational standards and expectations.