Best AI tools for< Audio Processing >
20 - AI tool Sites
Splitter.ai
Splitter.ai is an AI-driven audio processing platform developed by a Swedish research company. It offers advanced audio processing technologies, including stem separation/extraction, reverb removal, and direct YouTube splitting. The platform is designed to assist music producers, DJs, artists, forensics engineers, audio engineers, karaoke enthusiasts, police, scientists, and more in enhancing their audio processing tasks. Splitter.ai aims to provide high-quality services through AI-driven solutions to meet the diverse needs of its users.
Podcastle
Podcastle is an all-in-one podcasting software that empowers creators of all backgrounds and experience levels with an intuitive, AI-powered platform. It offers a wide range of features, including a recording studio, audio editor, video editor, AI-generated voices, and hosting hub, making it easy to create, edit, and publish high-quality podcasts and videos. Podcastle is designed to be user-friendly and accessible, with no prior experience or technical expertise required.
Audio Muse
Audio Muse is an all-in-one online audio tool that leverages AI features to help users create unique background music effortlessly. With a wide range of genres, themes, and moods to choose from, users can generate unlimited tracks with just a few clicks. The platform caters to music fans and creators alike, offering a full suite of audio processing tools in a user-friendly interface. Whether you're looking to compose epic, happy, acoustic, romantic, or hip hop music, Audio Muse provides everything you need in one convenient place.
Music AI
Music AI is an AI audio platform that offers state-of-the-art ethical AI solutions for audio and music applications. It provides a wide range of tools and modules for tasks such as stem separation, transcription, mixing, mastering, content generation, effects, utilities, classification, enhancement, style transfer, and more. The platform aims to streamline audio processing workflows, enhance creativity, improve accuracy, increase engagement, and save time for music professionals and businesses. Music AI prioritizes data security, privacy, and customization, allowing users to build custom workflows with over 50 AI modules.
AudioShake
AudioShake is a cloud-based audio processing platform that uses artificial intelligence (AI) to separate audio into its component parts, such as vocals, music, and effects. This technology can be used for a variety of applications, including mixing and mastering, localization and captioning, interactive audio, and sync licensing.
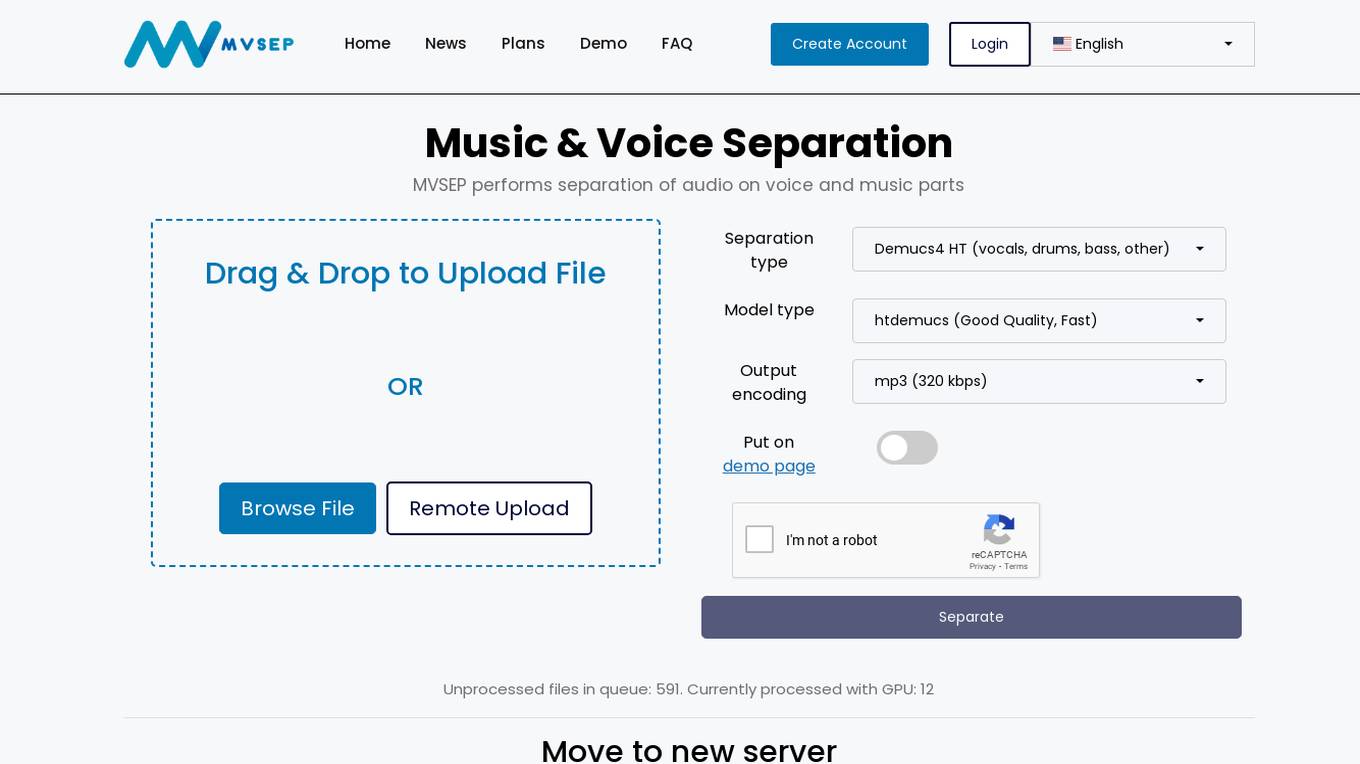
MVSEP - Music & Voice Separation
MVSEP is an AI-powered application that specializes in music and voice separation. It offers users the ability to separate audio files into voice and music parts using advanced algorithms and models. Users can easily upload files through drag and drop or remote upload features. The application provides various separation types, HQ models, and output encoding options to cater to different user needs. MVSEP aims to enhance the audio editing experience by providing high-quality results and a user-friendly interface.
Cleanvoice AI
Cleanvoice AI is an artificial intelligence that removes filler sounds, background noise, and mouth sounds from your podcast or audio recording. It can detect and remove filler sounds such as "um's", "ah's", etc. in multiple languages like German or French. The algorithm can also work with accents from other countries, such as Australian ones or Irish. Cleanvoice can also automatically enhance your audio by removing unwanted background noise, such as cafe noise, traffic sounds, white noise, or any other kind of background noise. Additionally, Cleanvoice can help you create podcast summaries and show notes, and it can even generate automated chapter markers so that listeners can skip to their favorite part.
Wan 2.5.AI
Wan 2.5.AI is a revolutionary native multimodal video generation platform that offers synchronized audio-visual generation with cinematic quality output. It features a unified framework for text, image, video, and audio processing, advanced image editing capabilities, and human preference alignment through RLHF. Wan 2.5.AI is designed to transform creative challenges, support AI research and development, enhance interactive education, and facilitate creative prototyping.
Audo Studio
Audo Studio is an AI-powered audio cleaning tool that automatically removes background noise, enhances speech, and adjusts volume levels with a single click. It offers fast and easy audio cleaning, advanced noise removal, echo reduction, and auto volume adjustment. With over 25,000 users and 300,000+ audio hours cleaned, Audo Studio is a popular choice for podcasters, YouTubers, and content creators looking to improve sound quality effortlessly.
Gradio
Gradio is a tool that allows users to quickly and easily create web-based interfaces for their machine learning models. With Gradio, users can share their models with others, allowing them to interact with and use the models remotely. Gradio is easy to use and can be integrated with any Python library. It can be used to create a variety of different types of interfaces, including those for image classification, natural language processing, and time series analysis.
fal
fal is an AI platform that offers cutting-edge AI models and tools for image and video generation, editing, and audio processing. It partners with leading AI companies to bring state-of-the-art technology to its users, enabling them to create stunning visual and audio content with ease. fal is at the forefront of the AI-driven media creation revolution, providing developers and creators with advanced tools to push the boundaries of creativity.
GoodListen
GoodListen is an AI tool designed for podcast studios. It offers a platform for both listeners and creators to discover, learn, and enjoy valuable short clips from podcasts and YouTube videos with the help of AI. GoodListen Studio utilizes generative AI technology to repurpose long podcast audio into highlights, chapters, and clips in a single click. The tool is powered by cutting-edge AI models and seamlessly integrates with platforms like Spotify and YouTube. Created by engineers and scientists from Spotify and Semrush, GoodListen is constantly improving through research and development in AI, Natural Language Processing, and audio processing.
Synthesizer V
Dreamtonics is a Tokyo-based startup company specializing in computer music and speech technologies. They build music software to suit customers' creativity needs and offer technology licensing and the creation of artificial voices as a service for corporate clients. Their flagship product is Synthesizer V, a singing synthesizer that combines a powerful audio processing engine with an intuitive user interface. With Synthesizer V, users can create their own songs by sketching out the melody and filling in the lyrics.
Vocalremover.org
Vocalremover.org is a website that offers a tool to remove vocals from music tracks. Users can upload their audio files and the tool will process them to create a version with the vocals removed. The site aims to provide a simple and efficient solution for users looking to create karaoke tracks or instrumental versions of songs. Vocalremover.org ensures security by verifying user connections and requires enabling JavaScript and cookies for smooth operation.
Moises App
Moises App is a music application powered by AI that provides musicians with a range of tools to enhance their practice and performance. With Moises App, users can separate vocals and instruments in any song, adjust the speed and pitch, and detect chords in real time. The app also includes a smart metronome and audio speed changer, making it an ideal tool for musicians of all levels. Moises App is available as a desktop application, iOS app, and web app, making it accessible to musicians on any device.
HitPaw Online
HitPaw Online is a website that provides a suite of AI-powered editing tools for photos, videos, and audio. The tools are easy to use and can be accessed online without the need to install any software. HitPaw Online's tools are powered by advanced AI algorithms that can automatically enhance the quality of your media files. For example, the Photo Enhancer tool can improve the resolution of images, remove noise, and adjust the colors. The Video Enhancer tool can upscale videos to 4K resolution, remove watermarks, and add subtitles. The Audio Enhancer tool can reduce background noise, extract audio from videos, and convert audio formats.

Activeloop
Activeloop is an AI tool that offers Deep Lake, a database for AI solutions across various industries such as agriculture, audio processing, autonomous vehicles, robotics, biomedical and healthcare, generative AI, multimedia, safety, and security. The platform provides features like fast AI search, faster data preparation, serverless DB for code assistant, and more. Activeloop aims to streamline data processing and enhance AI development for businesses and researchers.

GPT-4O
GPT-4O is a free all-in-one OpenAI tool that offers advanced AI capabilities for online solutions. It enhances productivity, creativity, and problem-solving by providing real-time text, vision, and audio processing. With features like instantaneous interaction, integrated multimodal processing, and advanced emotion detection, GPT-4O revolutionizes user experiences across various industries. Its broad accessibility democratizes access to cutting-edge AI technology, empowering users globally.
AI Music Generator
The AI Music Generator is an advanced platform powered by AI technology that allows users to create original music in any genre, style, or mood. It offers a range of features such as Text To Song, Lyrics To Song, AI Song Cover Generator, Voice Remover, Music Extension, Lyrics Generator, and more. The platform leverages deep learning models, transformer architecture, and neural networks to produce professional-quality music with voice synthesis and audio processing capabilities. Users can customize music styles, genres, and arrangements, and the tool is suitable for musicians, content creators, game developers, filmmakers, podcasters, businesses, and creative professionals.

Poly
Poly is a next-generation intelligent cloud storage platform that is built for the generative age. It offers a better cloud hosting service for your personal files, with features such as AI-enabled multimodal search, customizable layouts, dynamic collections, and one-click asset conversion. Poly is also designed to support outputs from your preferred generative AI models, including Automatic1111, ComfyUI, DALL-E, and Midjourney. With Poly, you can browse, manage, and navigate all your media generated by AI, and seamlessly connect and auto-import your files from your favorite apps.
0 - Open Source AI Tools
20 - OpenAI Gpts

Signal Processing Advisor
Provides expert guidance on signal processing in engineering projects.
ConvertAnything
The ultimate tool for converting files, whether they are images, audio, video, documents, or other types. It can process single files or multiple files in bulk, accepts ZIP files, and offers a download link [Updated version].





Professor Arup Das Ethics Coach
Supportive and engaging AI Ethics tutor, providing practical tips and career guidance.
![[AUDIO] Chinese Pronunciation Tutor Screenshot](/screenshots_gpts/g-Dr5b43UUk.jpg)
All Purpose Audio Format Converter
Expert in audio format conversion, guiding through simple steps.
DIY Audio Guru
An assistant to help audio DIY'ers of any level, and anyone curios about audio to identify issues, find information, and general assistance in their journey.

MIXING & MASTERING GPT
Your personal audio mixing and mastering engineer assistant for music production
Mike Russell
Virtual Mike Russell from Music Radio Creative. Ask me your audio, podcasting and AI questions!