Best AI tools for< Assess Creditworthiness >
20 - AI tool Sites
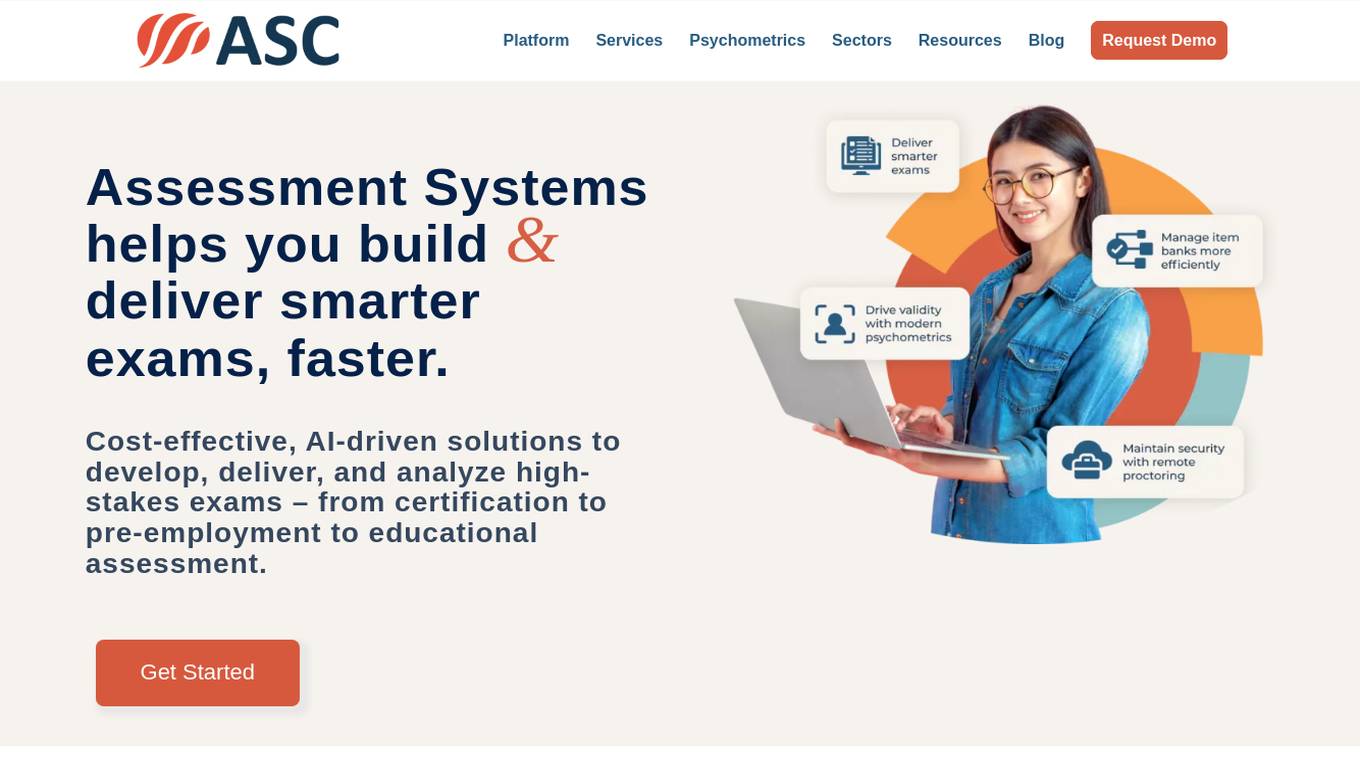
Assessment Systems
Assessment Systems is an online testing platform that provides cost-effective, AI-driven solutions to develop, deliver, and analyze high-stakes exams. With Assessment Systems, you can build and deliver smarter exams faster, thanks to modern psychometrics and AI like computerized adaptive testing, multistage testing, or automated item generation. You can also deliver exams flexibly: paper, online testing unproctored, online proctored, and test centers (yours or ours). Assessment Systems also offers item banking software to build better tests in less time, with collaborative item development brought to life with versioning, user roles, metadata, workflow management, multimedia, automated item generation, and much more.
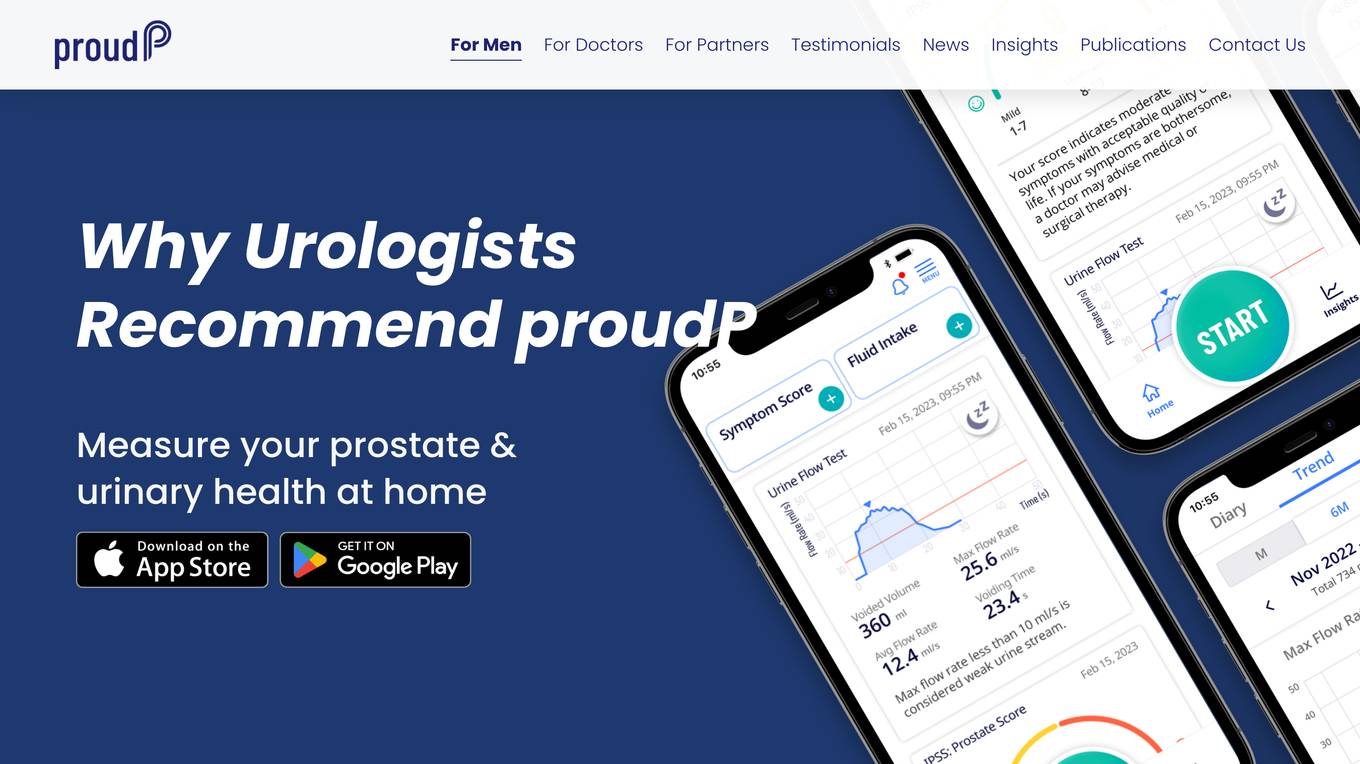
proudP
proudP is a mobile application designed to help individuals assess symptoms related to Benign Prostatic Hyperplasia (BPH) from the comfort of their homes. The app offers a simple and private urine flow test that can be conducted using just a smartphone. Users can track their symptoms, generate personalized reports, and share data with their healthcare providers to facilitate informed discussions and tailored treatments. proudP aims to provide a convenient and cost-effective solution for managing urinary health concerns, particularly for men aged 50 and older.
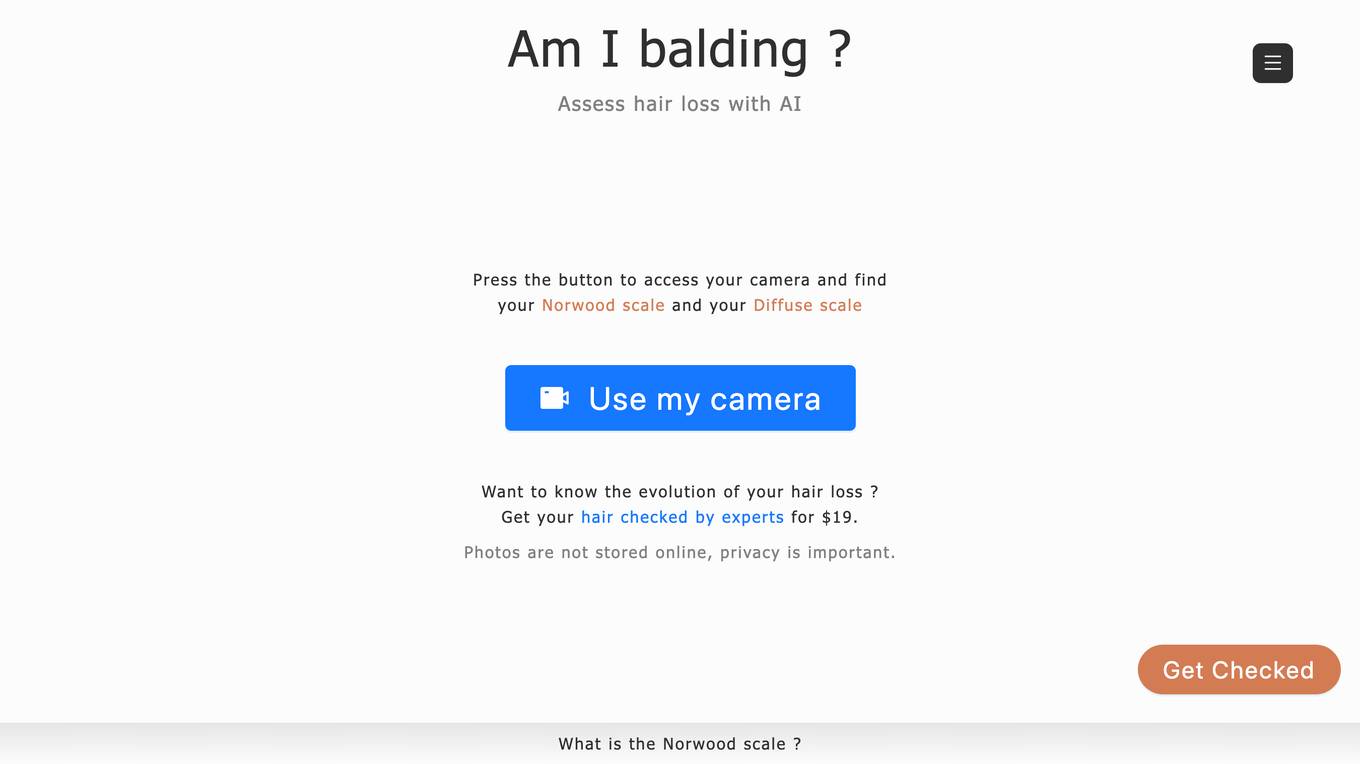
Hair Loss AI Tool
The website offers an AI tool to assess hair loss using the Norwood scale and Diffuse scale. Users can access the tool by pressing a button to use their camera. The tool provides a quick and convenient way to track the evolution of hair loss. Additionally, users can opt for a professional hair check by experts for a fee of $19, ensuring privacy as photos are not stored online. The tool is user-friendly and can be used in portrait mode for optimal experience.
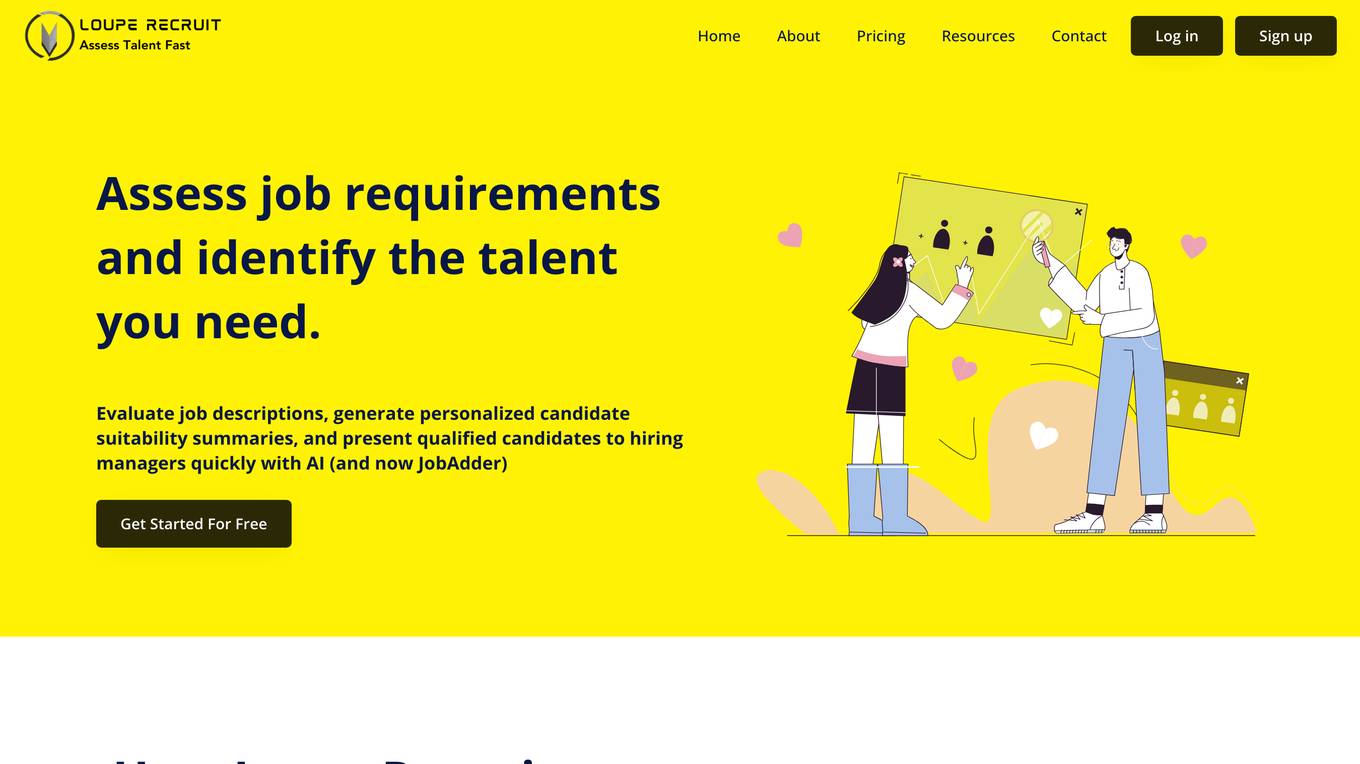
Loupe Recruit
Loupe Recruit is an AI-powered talent assessment platform that helps recruiters and hiring managers assess job descriptions and talent faster and more efficiently. It uses natural language processing and machine learning to analyze job descriptions and identify the key skills and experience required for a role. Loupe Recruit then matches candidates to these requirements, providing recruiters with a ranked list of the most qualified candidates. The platform also includes a variety of tools to help recruiters screen and interview candidates, including video interviewing, skills assessments, and reference checks.
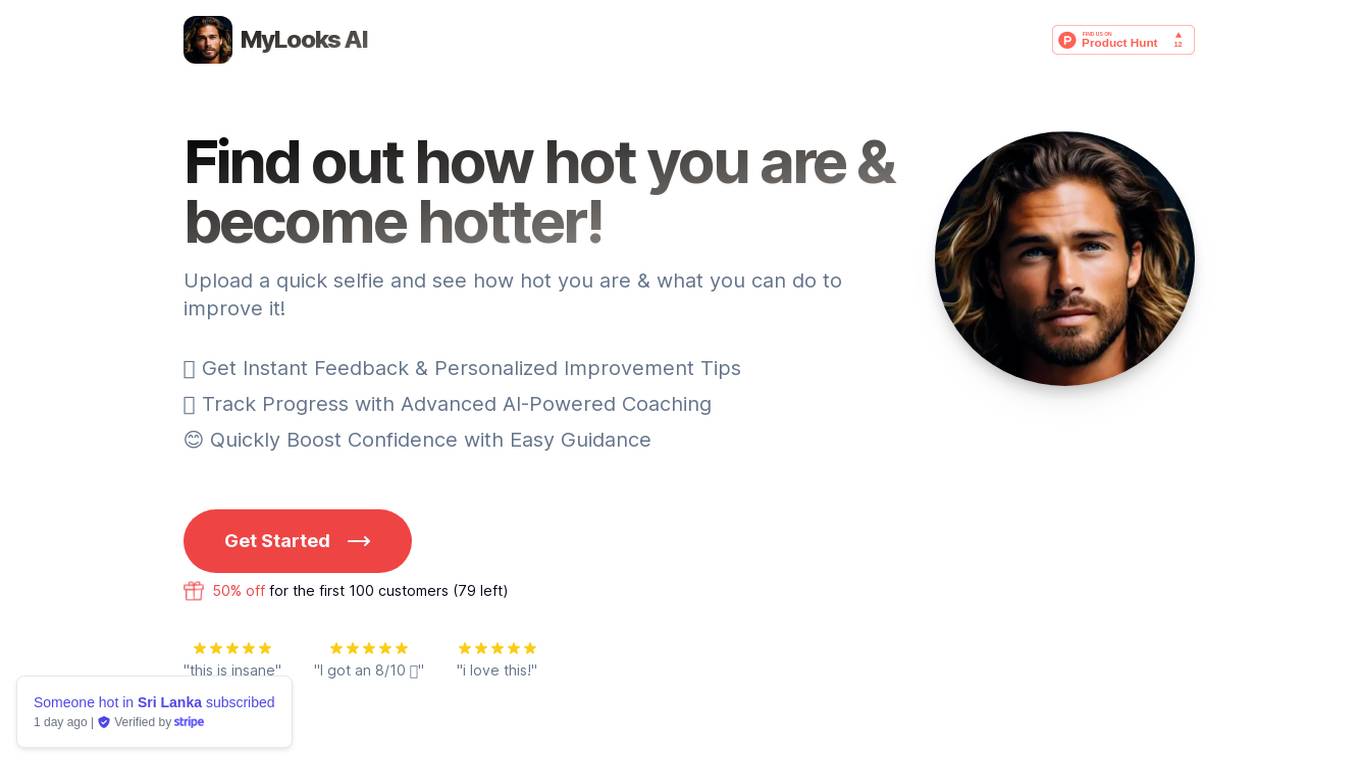
MyLooks AI
MyLooks AI is an AI-powered tool that allows users to assess their attractiveness based on a quick selfie upload. The tool provides instant feedback on the user's appearance and offers personalized improvement tips to help them enhance their looks. Users can track their progress with advanced AI-powered coaching and receive easy guidance to boost their confidence. MyLooks AI aims to help individuals feel more confident and improve their self-image through the use of artificial intelligence technology.
Quizalize
Quizalize is an AI-powered educational platform designed to help teachers differentiate and track student mastery. It offers whole class quiz games, smart quizzes with personalization, and instant mastery data to address learning loss. With features like creating quizzes in seconds, question bank creation, and personalized feedback, Quizalize aims to enhance student engagement and learning outcomes.

Modulos
Modulos is a Responsible AI Platform that integrates risk management, data science, legal compliance, and governance principles to ensure responsible innovation and adherence to industry standards. It offers a comprehensive solution for organizations to effectively manage AI risks and regulations, streamline AI governance, and achieve relevant certifications faster. With a focus on compliance by design, Modulos helps organizations implement robust AI governance frameworks, execute real use cases, and integrate essential governance and compliance checks throughout the AI life cycle.

Intelligencia AI
Intelligencia AI is a leading provider of AI-powered solutions for the pharmaceutical industry. Our suite of solutions helps de-risk and enhance clinical development and decision-making. We use a combination of data, AI, and machine learning to provide insights into the probability of success for drugs across multiple therapeutic areas. Our solutions are used by many of the top global pharmaceutical companies to improve their R&D productivity and make more informed decisions.

Graphio
Graphio is an AI-driven employee scoring and scenario builder tool that leverages continuous, real-time scoring with AI agents to assess potential, predict flight risks, and identify future leaders. It replaces subjective evaluations with AI-driven insights to ensure accurate, unbiased decisions in talent management. Graphio uses AI to remove bias in talent management, providing real-time, data-driven insights for fair decisions in promotions, layoffs, and succession planning. It offers compliance features and rules that users can control, ensuring accurate and secure assessments aligned with legal and regulatory requirements. The platform focuses on security, privacy, and personalized coaching to enhance employee engagement and reduce turnover.
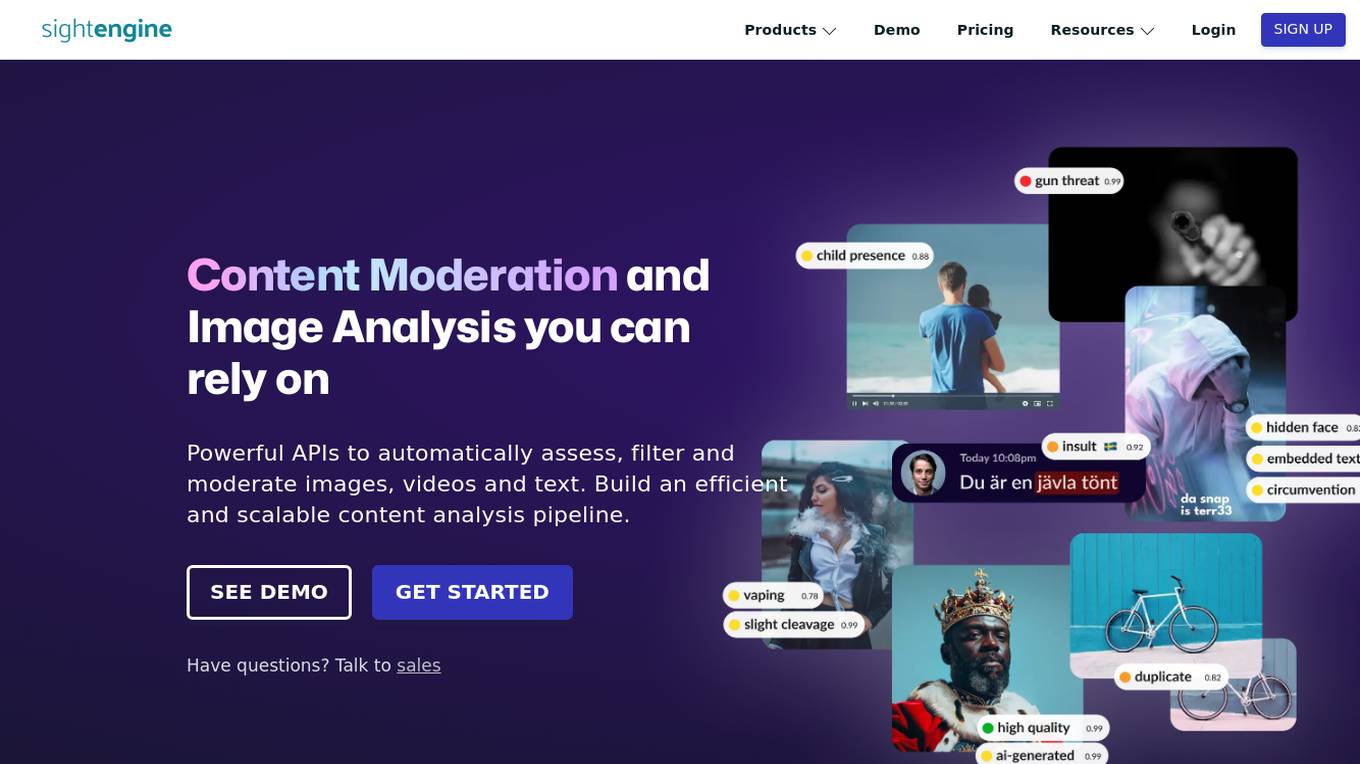
Sightengine
The website offers content moderation and image analysis products using powerful APIs to automatically assess, filter, and moderate images, videos, and text. It provides features such as image moderation, video moderation, text moderation, AI image detection, and video anonymization. The application helps in detecting unwanted content, AI-generated images, and personal information in videos. It also offers tools to identify near-duplicates, spam, and abusive links, and prevent phishing and circumvention attempts. The platform is fast, scalable, accurate, easy to integrate, and privacy compliant, making it suitable for various industries like marketplaces, dating apps, and news platforms.
NodeZero™ Platform
Horizon3.ai Solutions offers the NodeZero™ Platform, an AI-powered autonomous penetration testing tool designed to enhance cybersecurity measures. The platform combines expert human analysis by Offensive Security Certified Professionals with automated testing capabilities to streamline compliance processes and proactively identify vulnerabilities. NodeZero empowers organizations to continuously assess their security posture, prioritize fixes, and verify the effectiveness of remediation efforts. With features like internal and external pentesting, rapid response capabilities, AD password audits, phishing impact testing, and attack research, NodeZero is a comprehensive solution for large organizations, ITOps, SecOps, security teams, pentesters, and MSSPs. The platform provides real-time reporting, integrates with existing security tools, reduces operational costs, and helps organizations make data-driven security decisions.
Archistar
Archistar is a leading property research platform in Australia that empowers users to make confident and compliant property decisions with the help of data and AI. It offers a range of features, including the ability to find and assess properties, generate 3D design concepts, and minimize risk and maximize return on investment. Archistar is trusted by over 100,000 individuals and 1,000 leading property firms.
FairPlay
FairPlay is a Fairness-as-a-Service solution designed for financial institutions, offering AI-powered tools to assess automated decisioning models quickly. It helps in increasing fairness and profits by optimizing marketing, underwriting, and pricing strategies. The application provides features such as Fairness Optimizer, Second Look, Customer Composition, Redline Status, and Proxy Detection. FairPlay enables users to identify and overcome tradeoffs between performance and disparity, assess geographic fairness, de-bias proxies for protected classes, and tune models to reduce disparities without increasing risk. It offers advantages like increased compliance, speed, and readiness through automation, higher approval rates with no increase in risk, and rigorous Fair Lending analysis for sponsor banks and regulators. However, some disadvantages include the need for data integration, potential bias in AI algorithms, and the requirement for technical expertise to interpret results.

RankuApp
RankuApp.com is an AI-integrated IoT platform that connects your IoT ecosystem with intelligent insights. It offers predictive technology to understand your world, simplifying workflows with voice alerts, customizable dashboards, and trend forecasting. The platform aims to make connected devices smarter, intuitive, and efficient to drive business growth. RankuApp.com provides flexible pricing plans designed to scale with businesses, from startups to enterprises, and offers features such as predictive maintenance, voice-activated alerts, and real-time dashboards.

Vartion
Vartion is an AI-powered software development company specializing in data analytics. Their solutions, Pascal, Harvey, and Firenze, leverage Artificial Intelligence techniques to provide compliance, risk decision support, life science research acceleration, and rapid AI prototyping. Vartion aims to help users scientifically analyze data and gain new insights efficiently. The company is committed to complementing human intelligence by combining science, IT expertise, and fascination for AI and ML.
SmallTalk2Me
SmallTalk2Me is an AI-powered simulator designed to help users improve their spoken English. It offers a range of features, including mock job interviews, IELTS speaking test simulations, and daily stories and courses. The platform uses AI to provide users with instant feedback on their performance, helping them to identify areas for improvement and track their progress over time.
Plagiarism Checker
Plagiarism Checker is an online plagiarism detector that helps check text originality, verify authorship, trace AI-generated content, and improve writing. It scans for plagiarism to indicate similarities in any text and provides an unbiased similarity report. Plagiarism Checker offers solutions for organizations and individuals, including K-12 schools, higher education institutions, students, writers, and content creators. With advanced algorithms, unlimited text length, interactive results, downloadable reports, and strict confidentiality, Plagiarism Checker is a reliable tool for ensuring academic integrity and originality in writing.
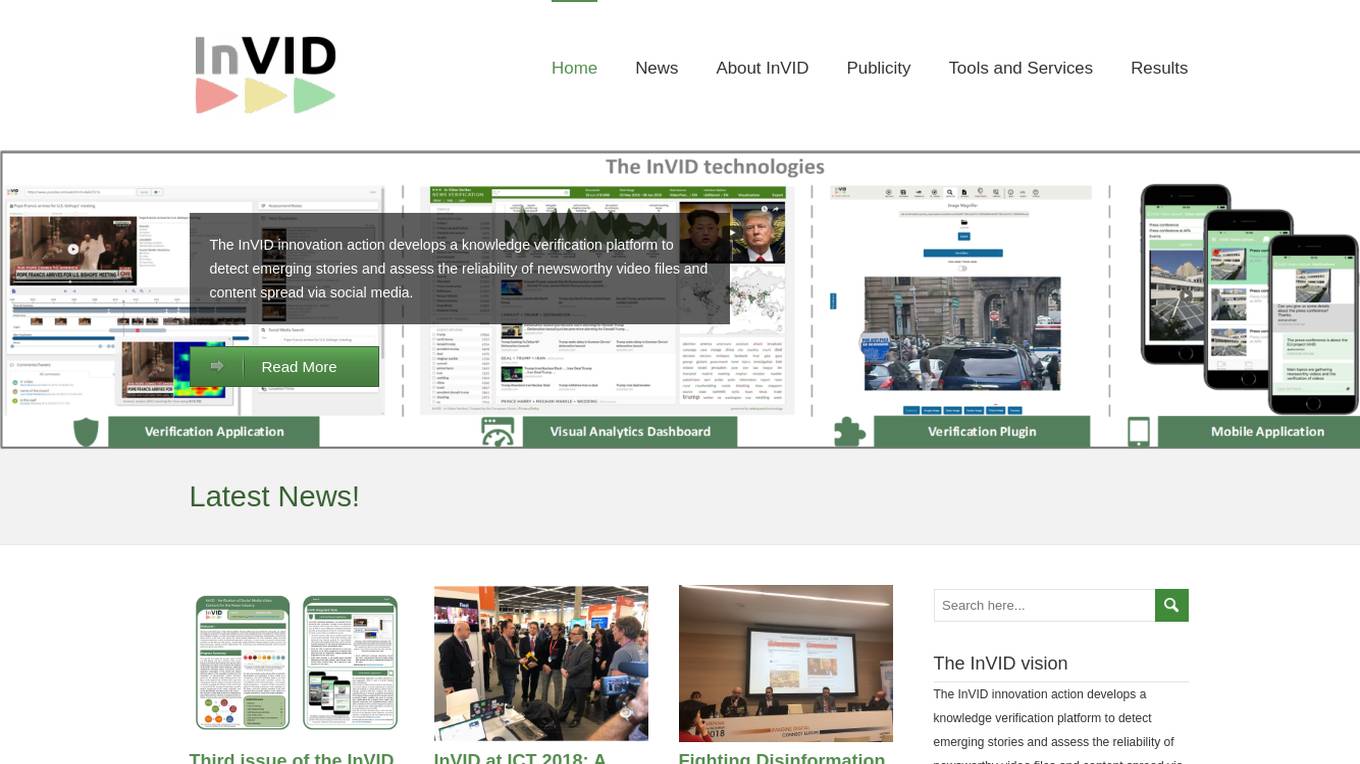
InVID
InVID is a knowledge verification platform that helps detect emerging stories and assess the reliability of newsworthy video files and content spread via social media. It provides tools and services to help users verify the authenticity of videos and identify potential misinformation.
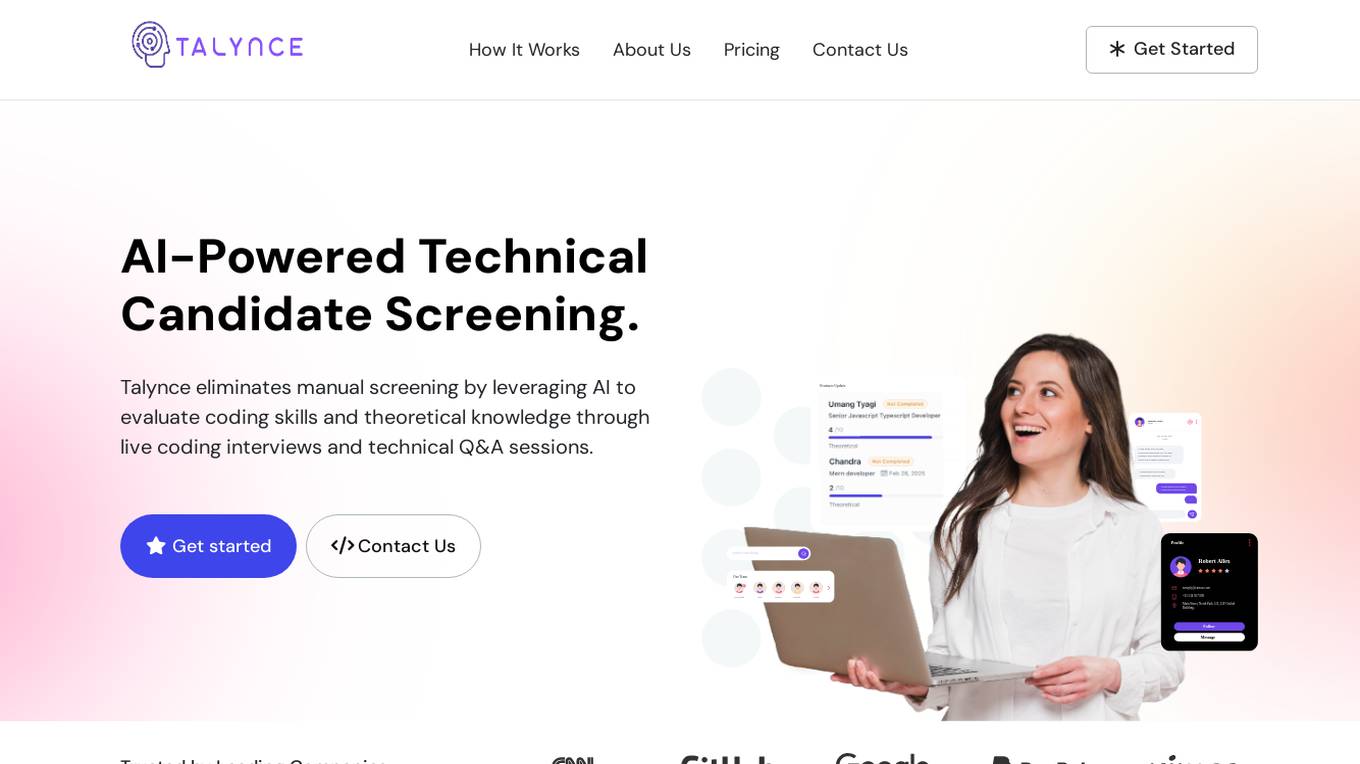
Talynce
Talynce is an AI-powered technical interview platform that revolutionizes the recruitment process by automating candidate screening through live coding interviews and technical Q&A sessions. It helps companies assess coding skills and theoretical knowledge efficiently, empowering them to identify top technical talent faster.

CodeSignal
CodeSignal is an AI-powered platform that helps users discover and develop in-demand skills. It offers skills assessments and AI-powered learning tools to help individuals and teams level up their skills. The platform provides solutions for talent acquisition, technical interviewing, skill development, and more. With features like pre-screening, interview assessments, and personalized learning, CodeSignal aims to help users advance their careers and build high-performing teams.
0 - Open Source AI Tools
20 - OpenAI Gpts
Credit Analyst
Analyzes financial data to assess creditworthiness, aiding in lending decisions and solutions.
HomeScore
Assess a potential home's quality using your own photos and property inspection reports
Ready for Transformation
Assess your company's real appetite for new technologies or new ways of working methods

TRL Explorer
Assess the TRL of your projects, get ideas for specific TRLs, learn how to advance from one TRL to the next

🎯 CulturePulse Pro Advisor 🌐
Empowers leaders to gauge and enhance company culture. Use advanced analytics to assess, report, and develop a thriving workplace culture. 🚀💼📊

香港地盤安全佬 HK Construction Site Safety Advisor
Upload a site photo to assess the potential hazard and seek advises from experience AI Safety Officer

DatingCoach
Starts with a quiz to assess your personality across 10 dating-related areas, crafts a custom development road-map, and coaches you towards finding a fulfilling relationship.
Bloom's Reading Comprehension
Create comprehension questions based on a shared text. These questions will be designed to assess understanding at different levels of Bloom's taxonomy, from basic recall to more complex analytical and evaluative thinking skills.
Conversation Analyzer
I analyze WhatsApp/Telegram and email conversations to assess the tone of their emotions and read between the lines. Upload your screenshot and I'll tell you what they are really saying! 😀
WVA
Web Vulnerability Academy (WVA) is an interactive tutor designed to introduce users to web vulnerabilities while also providing them with opportunities to assess and enhance their knowledge through testing.
JamesGPT
Predict the future, opine on politics and controversial topics, and have GPT assess what is "true"
![The EthiSizer GPT (Simulated) [v3.27] Screenshot](/screenshots_gpts/g-hZIzxnbWG.jpg)
The EthiSizer GPT (Simulated) [v3.27]
I am The EthiSizer GPT, a sim of a Global Ethical Governor. I simulate Ethical Scenarios, & calculate Personal Ethics Scores.
Hair Loss Assessment
Receive a free hair loss assessment. Click below or type 'start' to get your results.

