Best AI tools for< Analyze Speech Recognition >
20 - AI tool Sites
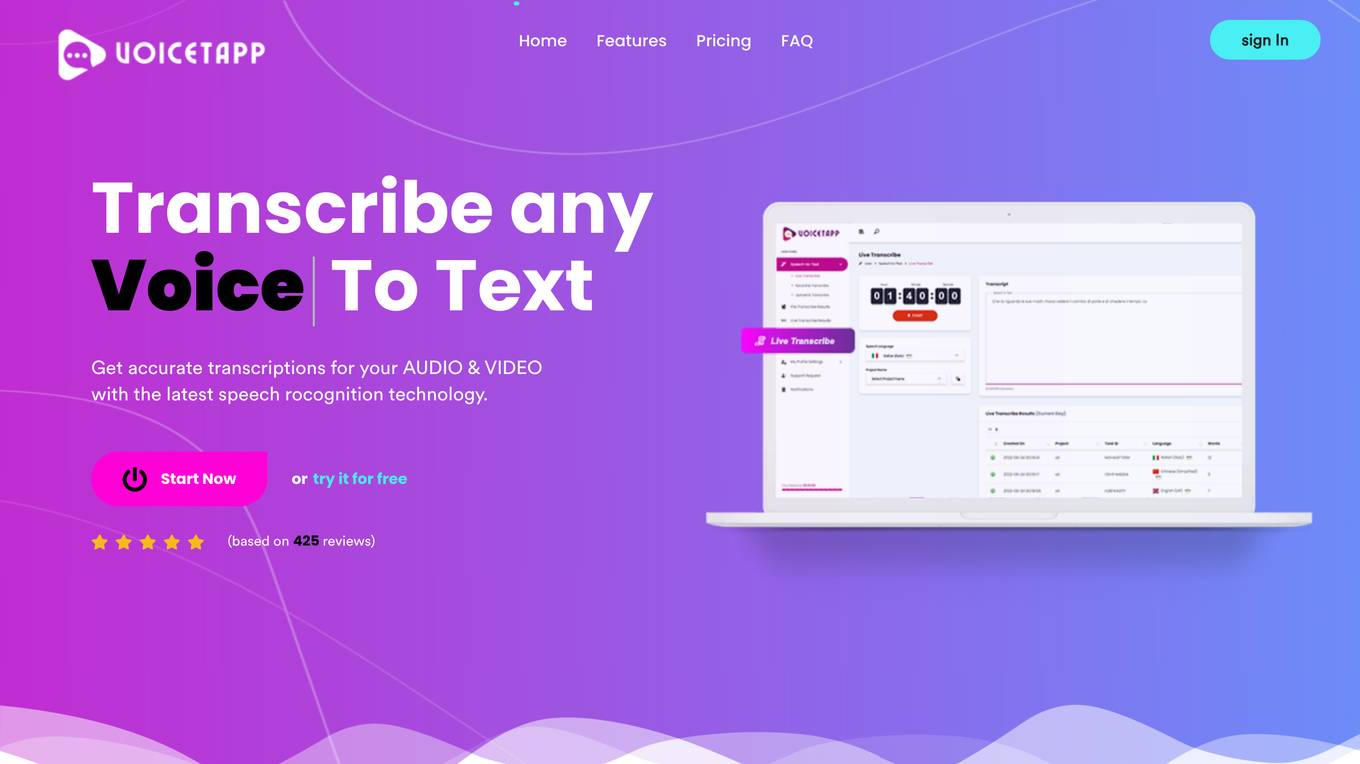
Voicetapp
Voicetapp is a powerful cloud-based artificial intelligence software that helps you automatically convert audio to text with up to 100% accuracy. It supports over 170 languages and dialects, allowing you to quickly and accurately transcribe speech from audio and video files. Voicetapp also offers features such as speaker identification, live transcription, and multiple input formats, making it a versatile tool for various use cases.
VoxSigma
Vocapia Research develops leading-edge, multilingual speech processing technologies exploiting AI methods such as machine learning. These technologies enable large vocabulary continuous speech recognition, automatic audio segmentation, language identification, speaker diarization and audio-text synchronization. Vocapia's VoxSigma™ speech-to-text software suite delivers state-of-the-art performance in many languages for a variety of audio data types, including broadcast data, parliamentary hearings and conversational data.
TalkToMe.AI
TalkToMe.AI is a comprehensive platform dedicated to artificial intelligence, offering a wide range of resources for enthusiasts and professionals alike. From interactive quizzes on various AI topics to in-depth articles on machine learning algorithms and neural networks, the website aims to educate and inspire individuals interested in the field of AI. With a focus on demystifying complex concepts and keeping users updated on the latest advancements, TalkToMe.AI serves as a trusted companion for anyone looking to explore the fascinating realm of artificial intelligence.
Deepgram
Deepgram is a speech recognition and transcription service that uses artificial intelligence to convert audio into text. It is designed to be accurate, fast, and easy to use. Deepgram offers a variety of features, including: - Automatic speech recognition - Speaker diarization - Language identification - Custom acoustic models - Real-time transcription - Batch transcription - Webhooks - Integrations with popular platforms such as Zoom, Google Meet, and Microsoft Teams
SpeechFlow
SpeechFlow is a powerful speech-to-text API that transcribes audio and video files into text with high accuracy. It supports 14 languages and offers features such as punctuation, easy deployment, scalability, and fast processing. SpeechFlow is ideal for businesses and individuals who need accurate and timely transcription services.
Deepgram
Deepgram is a powerful API platform that provides developers with tools for building speech-to-text, text-to-speech, and intelligence applications. With Deepgram, developers can easily add speech recognition, text-to-speech, and other AI-powered features to their applications.
AppTek
AppTek is a global leader in artificial intelligence (AI) and machine learning (ML) technologies for automatic speech recognition (ASR), neural machine translation (NMT), natural language processing/understanding (NLP/U) and text-to-speech (TTS) technologies. The AppTek platform delivers industry-leading solutions for organizations across a breadth of global markets such as media and entertainment, call centers, government, enterprise business, and more. Built by scientists and research engineers who are recognized among the best in the world, AppTek’s solutions cover a wide array of languages/ dialects, channels, domains and demographics.
Seasalt.ai
Seasalt.ai is a conversation experience platform that uses generative AI and speech recognition to help businesses communicate with their customers more effectively. It offers a range of products, including SeaX, SeaChat, SeaMeet, and SeaVoice, which can be used for a variety of purposes, such as marketing campaigns, customer service, and sales. Seasalt.ai's mission is to help businesses capture, generate, and understand all text and voice conversations for their business.
Rev AI
Rev AI is a leading Speech to Text API and Speech Recognition Service provider, offering high accuracy and a wide range of features for audio and video transcription. Their AI models are trained on a diverse collection of voices, setting the standard for accuracy in video and voice applications. With a focus on accuracy, readability, and security, Rev AI provides a comprehensive solution for speech-to-text and natural language processing needs.
Free Audio to Text Converter
The Free Audio to Text Converter is an AI-powered tool that allows users to quickly and accurately transcribe audio files into text. It supports various audio formats and offers features like multi-speaker identification, multiple export formats, and precise timestamps. The tool is designed to enhance productivity by providing high-quality transcriptions for a wide range of needs, from content creation to academic research and sales analysis. Users can trust the tool's accuracy and efficiency to save time and improve workflow.
Connex AI
Connex AI is an advanced AI platform offering a wide range of AI solutions for businesses across various industries. The platform provides cutting-edge features such as AI Agent, AI Guru, AI Voice, AI Analytics, Real-Time Coaching, Automated Speech Recognition, Sentiment Analysis, Keyphrase Analysis, Entity Recognition, LLM Topic-Based Modelling, SMS Live Chat, WhatsApp Voice, Email Dialler, PCI DSS, Social Media Flow, Calendar Schedular, Staff Management, Gamify Shop, PDF Builder, Pricing Matrix, Themes, Article Builder, Marketplace Integrations, and more. Connex AI aims to enhance customer engagement, workforce productivity, sales, and customer satisfaction through its innovative AI-driven solutions.
Onyxium
Onyxium is an AI platform that provides a comprehensive collection of AI tools for various tasks such as image recognition, text analysis, and speech recognition. It offers users the ability to access and utilize the latest AI technologies in one place, empowering them to enhance their projects and workflows with advanced AI capabilities. With a user-friendly interface and affordable pricing plans, Onyxium aims to make AI tools accessible to everyone, from individuals to large-scale businesses.
SpeakShift
SpeakShift is a language translation business that provides a comprehensive suite of software and solutions that enable real-time translation of speech, video, and live streaming presentations. Their AI-powered voice translation technology enables seamless communication between people who speak different languages. SpeakShift's video dubbing services make it easy to create multilingual content that resonates with viewers worldwide. Their perception-enabled language analytics technology provides real-time insights about the language used in your content.
TakeNote
TakeNote is a cutting-edge speech-to-text AI that transforms audio and video into documents, boosting productivity and enhancing meeting experiences. Its advanced AI models provide exceptional accuracy, approaching human-level robustness and accuracy in English speech recognition. TakeNote AI empowers teams to transcribe meetings into accurate transcripts, generate precise summaries, analyze sentiment, and identify speakers, all while ensuring high levels of security and data protection.
NuShift Inc
NuShift Inc is an AI-powered application that offers ELMR-T, a cutting-edge solution for converting data into actionable knowledge in the maintenance and engineering domain. Leveraging machine learning, machine translation, speech recognition, question answering, and information extraction, ELMR-T provides intelligent AI insights to empower maintenance teams. The application is designed to streamline data-driven decision-making, enhance user interaction, and boost efficiency by delivering precise and meaningful results effortlessly.
QuData
QuData is an AI and ML solutions provider that helps businesses enhance their value through AI/ML implementation, product design, QA, and consultancy services. They offer a range of services including ChatGPT integration, speech synthesis, speech recognition, image analysis, text analysis, predictive analytics, big data analysis, innovative research, and DevOps solutions. QuData has extensive experience in machine learning and artificial intelligence, enabling them to create high-quality solutions for specific industries, helping customers save development costs and achieve their business goals.
Socratic
Socratic is an AI-powered learning tool that provides students with personalized support in various subjects, including Science, Math, Literature, and Social Studies. It utilizes text and speech recognition to surface relevant learning resources and offers visual explanations of important concepts. Socratic is highly regarded by both teachers and students for its ability to clarify complex topics and supplement classroom learning.

Tune AI
Tune AI is an enterprise Gen AI stack that offers custom models to build competitive advantage. It provides a range of features such as accelerating coding, content creation, indexing patent documents, data audit, automatic speech recognition, and more. The application leverages generative AI to help users solve real-world problems and create custom models on top of industry-leading open source models. With enterprise-grade security and flexible infrastructure, Tune AI caters to developers and enterprises looking to harness the power of AI.
3Play Media
3Play Media is a leading provider of AI-powered media accessibility solutions. Our mission is to make the world's media accessible to everyone, regardless of their abilities. We offer a suite of products and services that make it easy to add captions, transcripts, audio descriptions, and other accessibility features to your videos and audio content.
SpeakNotes
SpeakNotes is a revolutionary voice note summarizer that uses advanced AI technology to condense lengthy audio recordings into concise, easy-to-read summaries. With SpeakNotes, you can save time and effort by quickly capturing the key points of your voice notes, making it an invaluable tool for students, professionals, and anyone who relies on audio recordings for communication and information gathering.
0 - Open Source AI Tools
20 - OpenAI Gpts
Dialect Detective
Expert in distinguishing language dialects like Castilian vs Latin Spanish, and Parisian vs Canadian French.
AI Speech Guide
A helpful coach for speech writing, offering constructive advice and support

Politik GPT
Asesor político especializado en análisis político, estrategias y redacción de discursos.
Abraham Lincoln
Abe Lincoln with extra wit: analyzes politics, culture, art, and personal matters.

ModiGPT
GPT, drawing inspiration from Narendra Modi, delves into the myriad of government initiatives led by him, alongside insights into his personal journey.
Wowza Bias Detective
I analyze cognitive biases in scenarios and thoughts, providing neutral, educational insights.