Best AI tools for< Assess Cases >
20 - AI tool Sites
Lex Machina
Lex Machina is a Legal Analytics platform that provides comprehensive insights into litigation track records of parties across the United States. It offers accurate and transparent analytic data, exclusive outcome analytics, and valuable insights to help law firms and companies craft successful strategies, assess cases, and set litigation strategies. The platform uses a unique combination of machine learning and in-house legal experts to compile, clean, and enhance data, providing unmatched insights on courts, judges, lawyers, law firms, and parties.
LawBotica
LawBotica is an AI-powered platform that revolutionizes legal work by automating deposition summaries, crafting case timelines, offering comprehensive due diligence, document review, interactive chats, and collaborative workspaces. It transforms legal practice, turning months of work into minutes of efficiency. LawBotica empowers legal teams with AI-powered modules for document review, summarization, chat, repository management, and case assessment. It provides personalized solutions for legal practices, versatile deployment options, and a flexible API for custom integration.

Potis
Potis is an AI-powered hiring copilot that automates the screening process and evaluates candidates' real-world skills through behavioral interviews. It provides clear and bias-free talent scoring, customized feedback, and helps recruiters save time and costs while improving the quality of hires.
Darrow
Darrow is an AI-powered justice intelligence platform that helps lawyers discover high-value, impactful cases. It uses AI to sift through publicly available information and connect relevant data points to detect legal violations, predict their outcomes, and assess their financial impact. This helps lawyers streamline business development and focus on what they do best: fight for justice.

Modulos
Modulos is a Responsible AI Platform that integrates risk management, data science, legal compliance, and governance principles to ensure responsible innovation and adherence to industry standards. It offers a comprehensive solution for organizations to effectively manage AI risks and regulations, streamline AI governance, and achieve relevant certifications faster. With a focus on compliance by design, Modulos helps organizations implement robust AI governance frameworks, execute real use cases, and integrate essential governance and compliance checks throughout the AI life cycle.
FPOV
FPOV is an AI application that helps businesses transform into digital leaders by providing services in leadership, technology operations, people/culture, and artificial intelligence. The application offers workshops, strategies, analysis, support, and advisory services to help organizations succeed in the digital age. FPOV aims to be world-class thought leaders in navigating the constantly changing digital dynamics that impact organizations and people.
Flagright Solutions
Flagright Solutions is an AI-native AML Compliance & Risk Management platform that offers real-time transaction monitoring, automated case management, AI forensics for screening, customer risk assessment, and sanctions screening. Trusted by financial institutions worldwide, Flagright's platform streamlines compliance workflows, reduces manual tasks, and enhances fraud detection accuracy. The platform provides end-to-end solutions for financial crime compliance, empowering operational teams to collaborate effectively and make reliable decisions. With advanced AI algorithms and real-time processing, Flagright ensures instant detection of suspicious activities, reducing false positives and enhancing risk detection capabilities.
Clarity AI
Clarity AI is an AI-powered technology platform that offers a Sustainability Tech Kit for sustainable investing, shopping, reporting, and benchmarking. The platform provides built-in sustainability technology with customizable solutions for various needs related to data, methodologies, and tools. It seamlessly integrates into workflows, offering scalable and flexible end-to-end SaaS tools to address sustainability use cases. Clarity AI leverages powerful AI and machine learning to analyze vast amounts of data points, ensuring reliable and transparent data coverage. The platform is designed to empower users to assess, analyze, and report on sustainability aspects efficiently and confidently.
K2 AI
K2 AI is an AI consulting company that offers a range of services from ideation to impact, focusing on AI strategy, implementation, operation, and research. They support and invest in emerging start-ups and push knowledge boundaries in AI. The company helps executives assess organizational strengths, prioritize AI use cases, develop sustainable AI strategies, and continuously monitor and improve AI solutions. K2 AI also provides executive briefings, model development, and deployment services to catalyze AI initiatives. The company aims to deliver business value through rapid, user-centric, and data-driven AI development.
Pixcap
The website is a marketplace offering editable animated 3D assets such as mockups, icons, characters, and illustrations. Users can create high-quality animated designs directly in their web browser. The platform allows for customization of animated mockups, 3D elements, and characters for various industries and use cases. It also provides tools for enhancing presentations, websites, and mobile apps with engaging 3D content. Users can download content in popular file formats like GLB, MP4, GIF, and PNG for seamless integration with their favorite software applications.
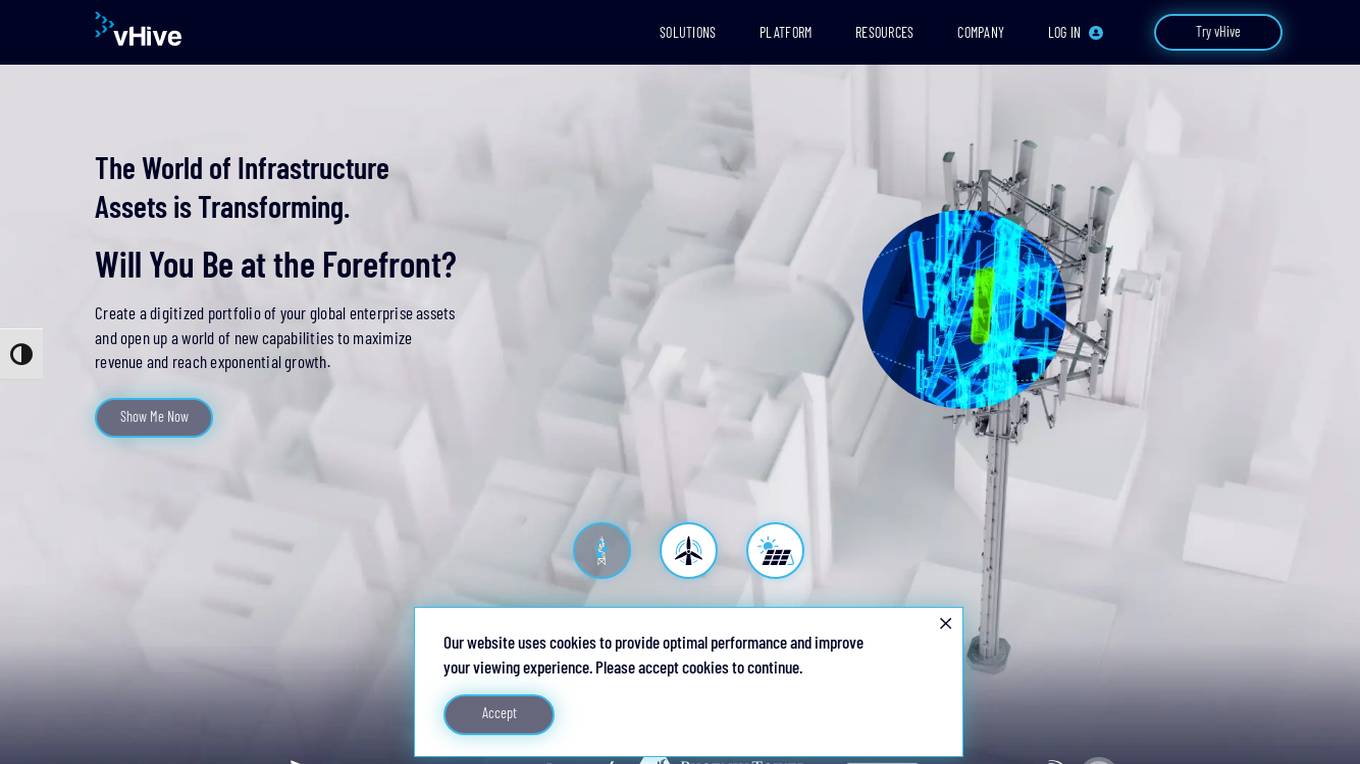
vHive
vHive is an autonomous digital twin software that enables users to create a digitized portfolio of global enterprise assets. The platform offers advanced AI analytics and insights to maximize revenue and facilitate exponential growth. With vHive, users can improve operational efficiency, rapidly digitize assets worldwide, ensure security and compliance, and scale their asset portfolio through end-to-end automation. Trusted by leading enterprises, vHive provides a user-friendly platform for collecting data and insights across various use cases, ultimately driving organizational efficiency and innovation.
Criya AI
Criya AI is an Intelligent Content System that helps boost buyer engagement by providing AI-powered tools such as Content Builder, Slide Generator, Visual Design, and more. It offers features like Company knowledge management, Engagement Analytics, Secure Sharing, and Team Collaboration. Criya AI caters to various use cases like Account Based Prospecting, Lead Capture, and Deal Execution, benefiting roles such as BDR/SDR, Account Executive, and Sales Trainer. The application is designed to accelerate revenue generation by producing client-ready assets quickly and efficiently.
Kittl
Kittl is a collaborative design platform that offers intuitive design tools and AI companion features to enhance workflow efficiency. With an infinite canvas and a vast library of design assets, Kittl allows teams to collaborate in real-time and create high-quality mockups for various use cases. The platform provides over 1,400 free fonts, one-click text effects, and exclusive templates for designing merchandise, marketing materials, branding assets, and more. Additionally, Kittl integrates AI tools such as image generation, vectorization, background removal, upscaling, and text generation to streamline the design process. Users can join the Kittl community, access tutorials, and post jobs to work on collaborative projects.
Breakout Learning
Breakout Learning is an AI-powered educational platform that transforms traditional case studies into engaging, multifaceted experiences. It empowers professors with AI insights into small-group discussions, enabling them to customize lectures and foster deeper student comprehension. Students benefit from rich content, peer-led discussions, and AI assessment that provides personalized feedback and tracks their progress.
Bench
Bench is an AI tool designed to automate hardware documentation for Hardware Engineers. It helps users document less and create more by utilizing AI for documentation writing, management, and discoverability. The tool offers features such as adapting to specific use cases, AI documentation writing, single source of truth, data-rich asset pages, highlighting compliance gaps, automated reports, and physical asset logging. Bench is advantageous for increasing productivity, improving documentation accuracy, streamlining workflows, enhancing compliance, and enabling seamless integrations. However, it may have limitations in customization options, initial learning curve, and potential dependency on AI accuracy. The tool is suitable for Hardware Engineers, Technical Writers, Documentation Specialists, Compliance Officers, and Quality Assurance Engineers. Users can find Bench using keywords like AI documentation, hardware documentation automation, AI writing tool, documentation management tool, and asset logging AI. Tasks users can perform with Bench include automate documentation, manage assets, write AI documentation, generate reports, and log physical assets.
Quantifind
Quantifind is an AI-powered financial crimes automation platform that specializes in Anti-Money Laundering (AML) and Know Your Customer (KYC) solutions. It offers end-to-end automation impact, best-in-class accuracy, and powerful APIs and applications for risk screening, investigations, and compliance in the financial services and public sector industries. Quantifind's Graphyte platform leverages AI and external data to streamline AML-KYC processes, providing comprehensive data coverage, dynamic risk typologies, and seamless integrations with case management systems.
Applied AI Institute
Applied AI Institute is an educational platform that provides AI education to business and IT professionals. They offer a variety of instructor-led webinars, tailored courses, guided hackathons, and solution development services. The institute focuses on enhancing learners' competencies and attitudes for success by offering customized courses with real-world client projects. Additionally, they provide consultation services to create solution assets for specific use cases, ensuring optimal results.
Brandity.ai
Brandity.ai is an AI-powered brand identity tool that helps users generate complete visual identities quickly and efficiently. The tool utilizes advanced algorithms to adapt to users' brand needs and preferences, maintaining a consistent style across all brand assets. Brandity's AI-driven identity generation ensures coherence and uniqueness in brand identities, from color schemes to art styles, tailored to fit each brand's unique requirements. The tool offers a range of pricing plans suitable for individuals, SMEs, agencies, and high-conversion entities, providing flexibility and scalability in generating logo, scenes, props, and patterns. With Brandity, users can kickstart their brand identity in less than 5 minutes, saving time and ensuring a compelling brand image across various applications.
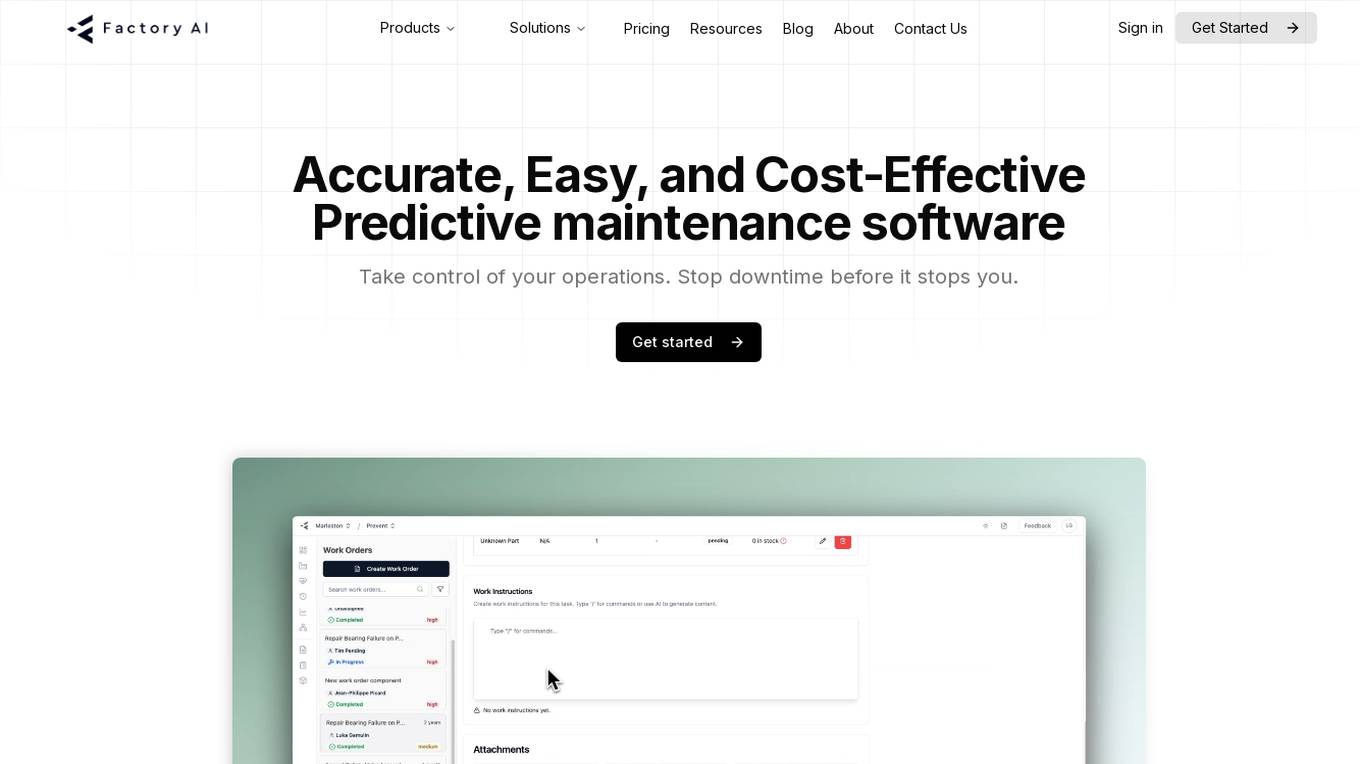
Factory AI
Factory AI is a predictive maintenance and AI-powered CMMS software application that helps businesses take control of their operations by providing accurate, easy, and cost-effective solutions. The platform enables users to analyze, diagnose, and improve asset availability by leveraging advanced machine learning techniques. With features such as anomaly detection, in-depth monitoring, and predictive maintenance, Factory AI empowers teams to proactively tackle asset issues and prevent unplanned downtime. The application is designed to streamline maintenance operations, generate work orders, manage assets, and optimize maintenance schedules for various industries.
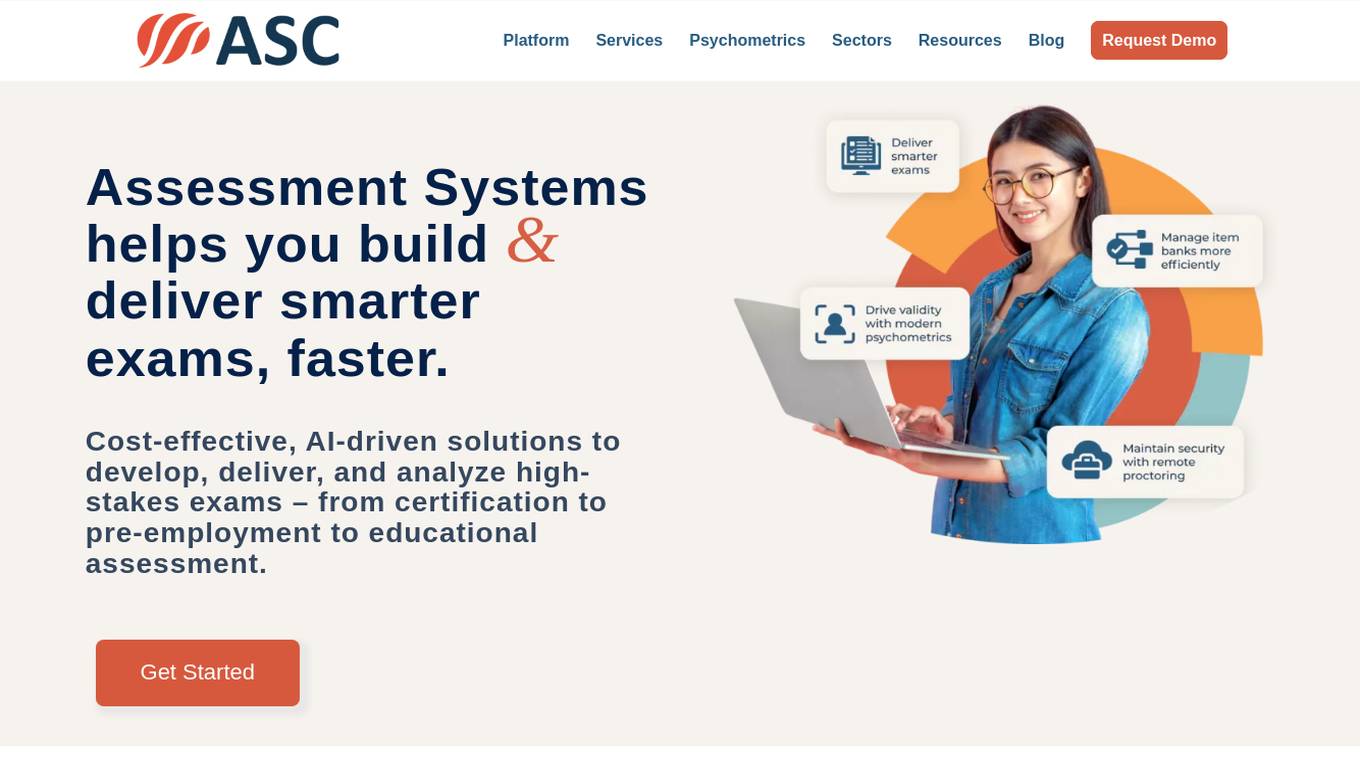
Assessment Systems
Assessment Systems is an online testing platform that provides cost-effective, AI-driven solutions to develop, deliver, and analyze high-stakes exams. With Assessment Systems, you can build and deliver smarter exams faster, thanks to modern psychometrics and AI like computerized adaptive testing, multistage testing, or automated item generation. You can also deliver exams flexibly: paper, online testing unproctored, online proctored, and test centers (yours or ours). Assessment Systems also offers item banking software to build better tests in less time, with collaborative item development brought to life with versioning, user roles, metadata, workflow management, multimedia, automated item generation, and much more.
0 - Open Source AI Tools
20 - OpenAI Gpts
Lupus Kidney Assistant
Interprets lupus nephritis cases, assessing remission status and recommending treatments.
Multidimensional Bipolar Test
Multidimensional Bipolar Test: Self-assessment for bipolar disorder.
TLICS Score Assistant
Thoracolumbar Injury Classification and Severity (TLICS) system calculator
HomeScore
Assess a potential home's quality using your own photos and property inspection reports
Ready for Transformation
Assess your company's real appetite for new technologies or new ways of working methods

TRL Explorer
Assess the TRL of your projects, get ideas for specific TRLs, learn how to advance from one TRL to the next

🎯 CulturePulse Pro Advisor 🌐
Empowers leaders to gauge and enhance company culture. Use advanced analytics to assess, report, and develop a thriving workplace culture. 🚀💼📊

香港地盤安全佬 HK Construction Site Safety Advisor
Upload a site photo to assess the potential hazard and seek advises from experience AI Safety Officer
Credit Analyst
Analyzes financial data to assess creditworthiness, aiding in lending decisions and solutions.

DatingCoach
Starts with a quiz to assess your personality across 10 dating-related areas, crafts a custom development road-map, and coaches you towards finding a fulfilling relationship.
Bloom's Reading Comprehension
Create comprehension questions based on a shared text. These questions will be designed to assess understanding at different levels of Bloom's taxonomy, from basic recall to more complex analytical and evaluative thinking skills.
Conversation Analyzer
I analyze WhatsApp/Telegram and email conversations to assess the tone of their emotions and read between the lines. Upload your screenshot and I'll tell you what they are really saying! 😀
WVA
Web Vulnerability Academy (WVA) is an interactive tutor designed to introduce users to web vulnerabilities while also providing them with opportunities to assess and enhance their knowledge through testing.
JamesGPT
Predict the future, opine on politics and controversial topics, and have GPT assess what is "true"
![The EthiSizer GPT (Simulated) [v3.27] Screenshot](/screenshots_gpts/g-hZIzxnbWG.jpg)
The EthiSizer GPT (Simulated) [v3.27]
I am The EthiSizer GPT, a sim of a Global Ethical Governor. I simulate Ethical Scenarios, & calculate Personal Ethics Scores.